学习目标:
学习内容:
提示:这里可以添加要学的内容
- 从GitHub中下载代码,配置好环境,按照readme中的提示即可跑通代码
- 论文中用到的是基于BN层中γ的L1范数的剪枝:
利用BN层中的比例因子。批处理规范化[19]已被大多数现代CNNs作为标准方法来实现快速收敛和更好的泛化性能。BN规范化激活的方法激励我们设计一个简单高效的方法合并信道比例因子。特别是,BN层使用小批量统计来规范内部激活。设z in和z out为BN层的输入和输出,B表示当前的小批量,BN层执行以下转换:
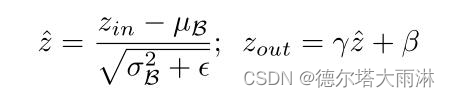
其中,µB和σB是B上输入激活的平均值和标准差值,γ和β是可训练的仿射变换参数(尺度和位移),它提供了将归一化激活线性转换回任何尺度的可能性。
通常的做法是在卷积层之后插入一个BN层,并带有信道方向的缩放/移位参数。因此,我们可以直接利用BN层中的γ参数作为网络精简所需的缩放因子。它的最大优点是不会给网络带来任何开销。事实上,这也许也是我们学习信道修剪的最有效的方法。1) 如果我们在没有BN层的CNN中添加缩放层,则由于卷积层和缩放层都是线性变换,因此缩放因子的值对于评估信道的重要性没有意义。通过减小比例因子值,同时放大卷积层中的权重,可以获得相同的结果。2) 如果在BN层之前插入一个标度层,则标度层的标度效应将被BN中的归一化过程完全消除。3) ,如果我们在BN层之后插入缩放层,则每个通道有两个连续的缩放因子。 - 关键代码
def updateBN():
for m in model.modules():
if isinstance(m, nn.BatchNorm2d):
m.weight.grad.data.add_(args.s*torch.sign(m.weight.data)) # L1