摘要
在本文中,我们提出了深度连接注意力网络(DCANet),这是一种新的设计,它在不改变CNN模型内部结构的情况下,增强了CNN模型中的注意力模块。(原文写到,所有代码和模型都是公开的.)
Introduction
DCANet从前一个注意力模块中收集信息并将其传递给下一个注意力块,使注意力块之间相互协作,从而提高注意力的学习能力.在不修改内部结构的情况下,DCANet在注意块之间引入了一系列连接.它可以应用于各种自我注意模块,例如SENet,CBAM,SKNet等,而不考虑基础架构的选择.DCANet结合了注意力块之间的注意连接,这与卷积块之间的残差连接不同.
Related Work
Self-attention mechanisms
为了研究通道之间的相互依赖性,SENet,GENet和SGENet利用自注意进行上下文建模.对于全局上下文信息,NLNet和GCNet引入了自注意来捕获非本地操作中的远程依赖关系.BAM和CBAM同时考虑了通道和空间.除了对通道和空间的关注,SKNet还对内核大小的选择进行了自我关注.
Residual connections
文中提到的FishNet和DLA没有见过,记录一下,日后查一下.
Connected Attention
创新点:在注意力块中建立联系.
Deep Connected Attention
我们通过参数化加法将先前提取的注意力特征与当前提取的特征进行合并,保证了所有注意力块之间的信息前馈流动,避免了注意力信息在每一步变化较大.
下图为本文方法的总体流水线
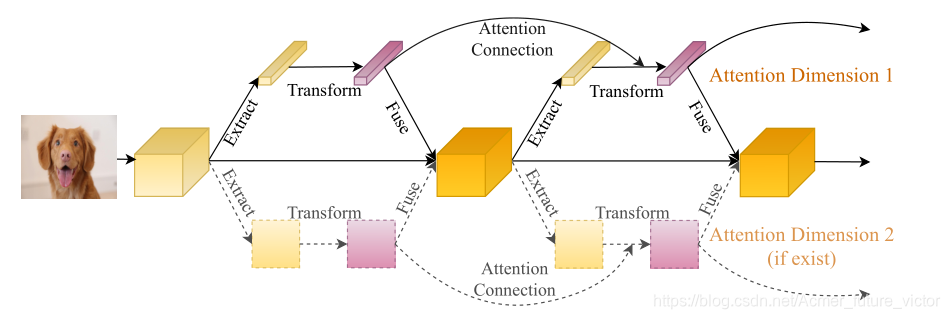
注意块由三个部分组成:特征提取,转换和融合.
Revisiting Self-attention Block
我们首先回顾几个流行的注意模块来分析其内部结构。作为一种常见的做法,我们通过横向添加额外的关注块来提升CNN的基础架构。然而,不同的注意力块是为不同的目的量身定做的,实现方式也是多种多样的。例如,SE块由两个全连通的层组成,而GC块包括若干卷积层。因此,要直接提供一个通用到足以覆盖大多数关注点的标准连接模式并不容易。为了解决这个问题,我们研究了最新的注意块,并总结了它们的处理过程和组成。
受最近的研究工作[41,7,11]提出的注意模块及其组件的启发(主要针对SENET和NLnet),我们研究了各种注意模块,并提出了一个通用的注意框架,其中一个注意块由三个组件组成:上下文提取、转换和融合。提取作为一个简单的特征提取器,变换将提取的特征转换到一个新的非线性注意力空间,而融合则融合注意力和原始特征。这些组件是通用的,并不局限于特定的关注点。图3举例说明了四个众所周知的注意块及其使用这三个组件的建模。
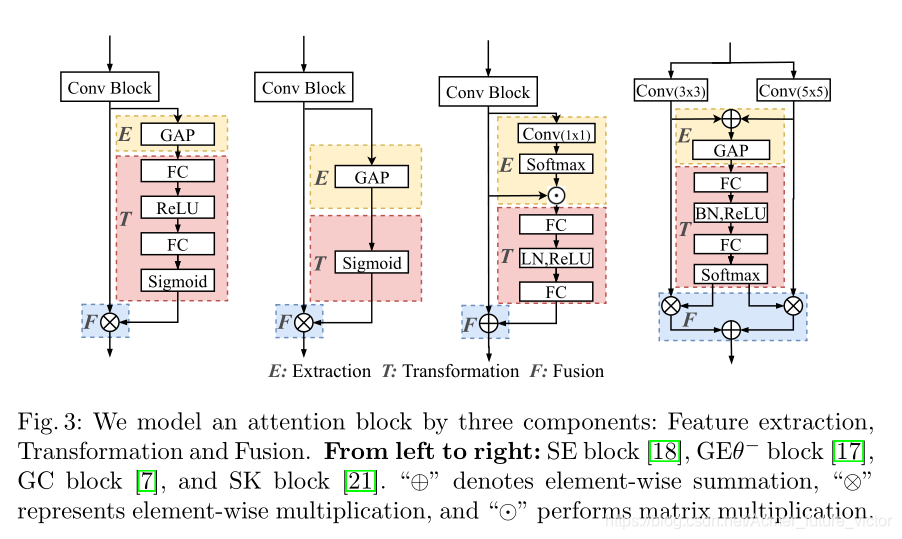
**Extraction:**通过提取器g从X中提取参数,G=g(X, Wg),其中Wg是参数,用于提取操作,G是输出.G的灵活性使G根据提取操作的不同而呈现不同的形状.例如,SENET和GCNET将特征地图X收集为一个向量(一维),而CBAM中的空间注意模块将特征地图收集为一个张量(三维)。
**Transformation:**变换处理从提取中收集到的特征,并将其转换为非线性注意空间,形式化地将t定义为特征变换运算,关注块地输出可以表示为T=t(G,Wt).这里Wt表示变换操作中使用的参数,t表示提取模块的输出.
**Fusion:**融合将注意图和原始卷积块的输出相结合.
i 是特征映射图中的索引,中间符号表示融合函数,当设计是按比例缩放的点积注意时,融合函数执行逐个元素的乘法,否则执行求和.其中,T是转换输出,X是原始卷积块的卷积输出.
Attention Connection
接下来,我们利用前面的注意力成分提出了一种广义的注意力连接模式。不管实现细节如何,注意块都可以建模为
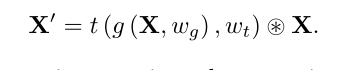
正如上一节所解释的,转换组件生成的注意力图对于注意力学习至关重要。为了构建关联注意力,我们将先前的关注图提供给当前转换组件,该组件合并了之前的转换输出和当前提取输出。这种连接设计确保当前转换模块从提取的特征和先前的注意信息中学习。由此产生的注意力障碍可以描述为:
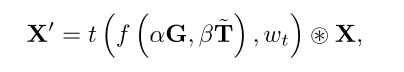
其中f(·)表示连接函数,α和β是可学习参数,˜T是由前一个注意块生成的注意图。在某些情况下(例如,SE块和GE块),˜T被缩放到(0,1)的范围。对于那些关注块,我们将˜T乘以˜E以匹配尺度,其中˜E是前一个关注块中提取组件的输出。我们还注意到,如果α设置为1,β设置为0,则不使用注意连接,并且DCA增强注意块减少为普通注意块。
连接函数的两种不同连接模式:
**Direct Connection:**我们通过直接将这两项相加来实例化f(),连接功能可以表示为:

其中,i是要素的索引.
Weighted Connection: 直接连接可以通过使用加权和来增强.连接函数表示为:
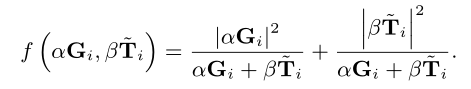
消融研究的实验结果表明,实验结果对连接模式不敏感,这表明性能的提高更多地来自注意块之间的连接,而不是连接函数的具体形式.因此,默认情况下,我们在方法中使用直接连接.
Size Matching
也就是匹配通道数和匹配特征图大小.
在CNN模型的不同阶段制作的特征图可能有不同的大小。因此,相应注意图的大小也可能不同,这种不匹配使得我们的DCANet不可能在这两个阶段之间应用。为了解决这一问题,我们自适应地匹配通道和空间维度上的注意图形状。
对于通道,我们使用完全连接层(随后是层归一化layer nomalization[2]和RELU激活)匹配大小,以将C’通道转换为C通道,其中C’和C分别表示先前和当前通道的数量。为了清楚起见,为通道大小匹配引入的参数为C’×C。为了进一步减轻注意连接中的参数负担,我们用两个轻量级全连接层重新构造了直接全连接层;输出大小分别为C/r和C,其中r为缩减率。这一修改大大减少了引入的参数数量。通道大小匹配策略的影响见表2E。在我们的所有实验中,除非另有说明,否则我们使用r=16的两个完全连接的层来匹配通道大小。
为了匹配空间分辨率,一种简单而有效的策略是采用平均池化图层(Average-Pooling Layer)。我们将步幅和接受场大小设置为分辨率降低的尺度。Max-Pooling在我们的方法中也很有效,但它只考虑了部分信息,而不是整个注意力信息。除了合并运算之外,另一种解决方案是可学习的卷积运算。然而,我们认为它不适合我们的目的,因为它引入了许多参数,不能很好地推广。关于空间分辨率尺寸匹配的详细消融实验可以在表2c中找到。
Multi-dimentional attention connection
我们注意到一些注意力块集中在不止一个注意力维度上。例如,BAM[26]和CBAM[39]沿着通道和空间维度推断注意图。受Xception[10]和MobileNet[16,29]的启发,我们一次为一个注意维度设计注意连接。为了建立多维注意力区块,我们将注意力地图与每个维度连接起来,并确保不同维度的连接彼此独立(如图2所示)。注意连接的这种解耦带来了两个优点:1)减少了参数数量和计算开销;2)每个维度都可以专注于它的内在属性。

Experiments
Classification on ImageNet
训练参数:epoches:300, batch_size:256, image_size:224x224, 优化器:带有Nesterov momentum=0.9,weight decay=0.0001的同步的SGD,初始lr=0.1,每30轮降低十倍.对于像MnasNet和MobileNetV2这样的轻量级模型,我们采用余弦衰减法[25]来调整学习率,并对150个epoch的模型进行训练,每个GPU有64幅图像。
实验结果:
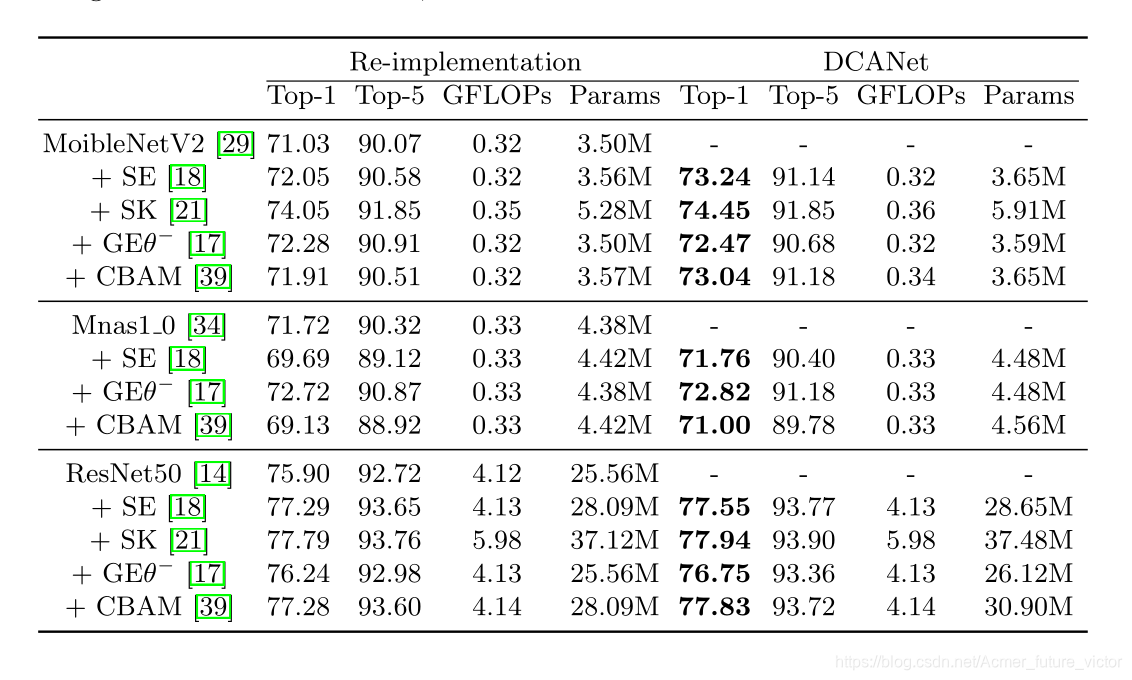
消融实验结果:
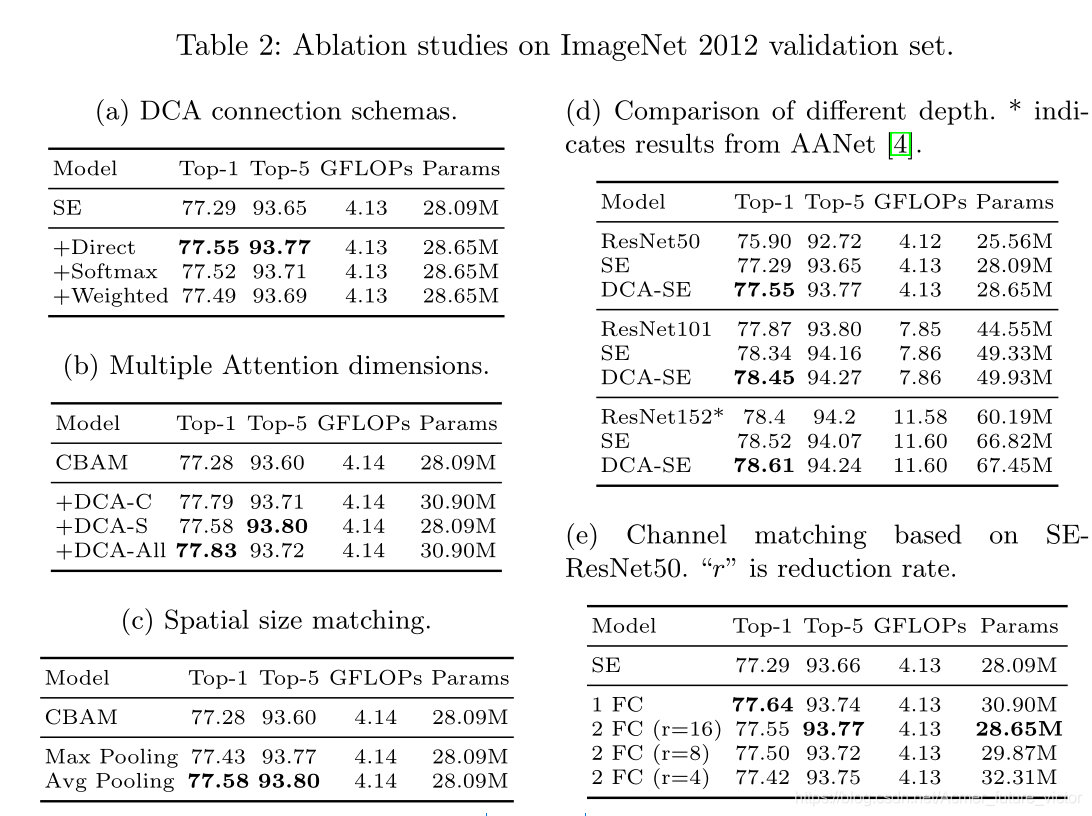
由表d可知,在三种网络中,DCA-SE-ResNet的性能总是优于SE-ResNet和ResNet.并且,对着深度的增加,性能增益变小.因此将注意力模块应用于深层网络会导致比应用于浅层网络的性能提升更少.
表a,c,d,e综合评估了DCANet在单一注意力维度上的表现.表b将描述注意力模块的应用,这些模块考虑了两个或多个注意力维度.为了说明,我们使用CBAM-ResNet50作为基线,因为CBAM模块同时考虑了通道和空间关注度。我们先将DCANet与各个关注维度分别集成,然后再将它们并行集成。我们使用DCA-C/DCA-S来呈现DCANet在通道/空间注意上的应用,DCA-ALL表明我们在CBAM-ResNet50的两个注意维度上都应用了DCA模块。
Object detection on MS COCO
未完待续…