本文代码优化改进于博文复制粘贴数据增强。
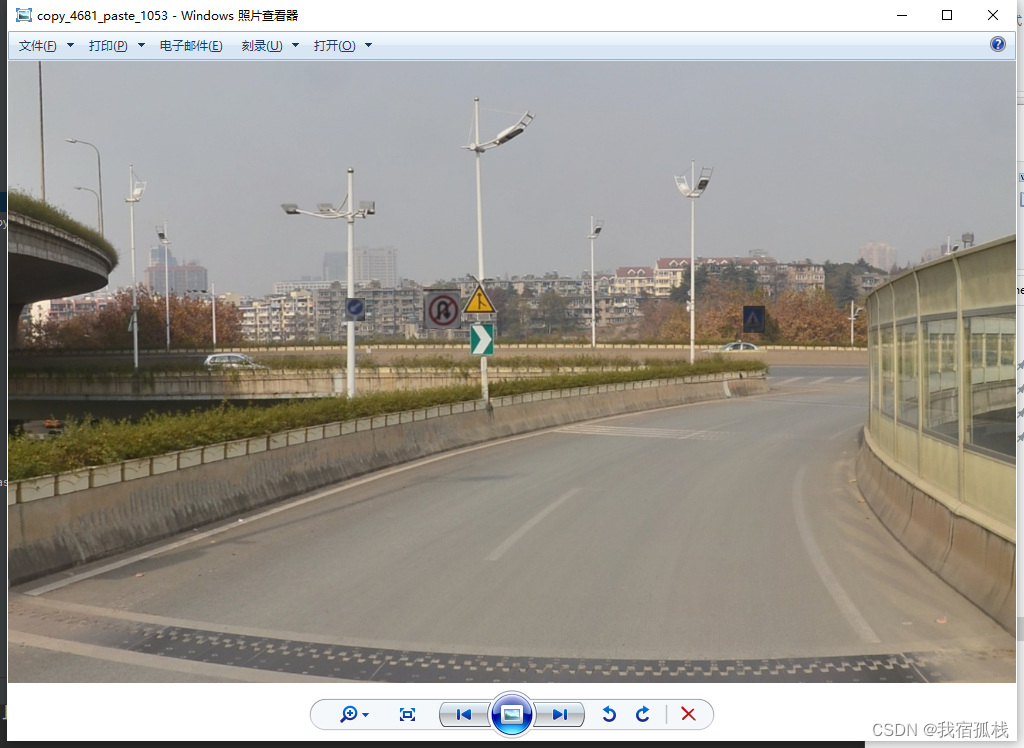
数据增强后结果图:
图C
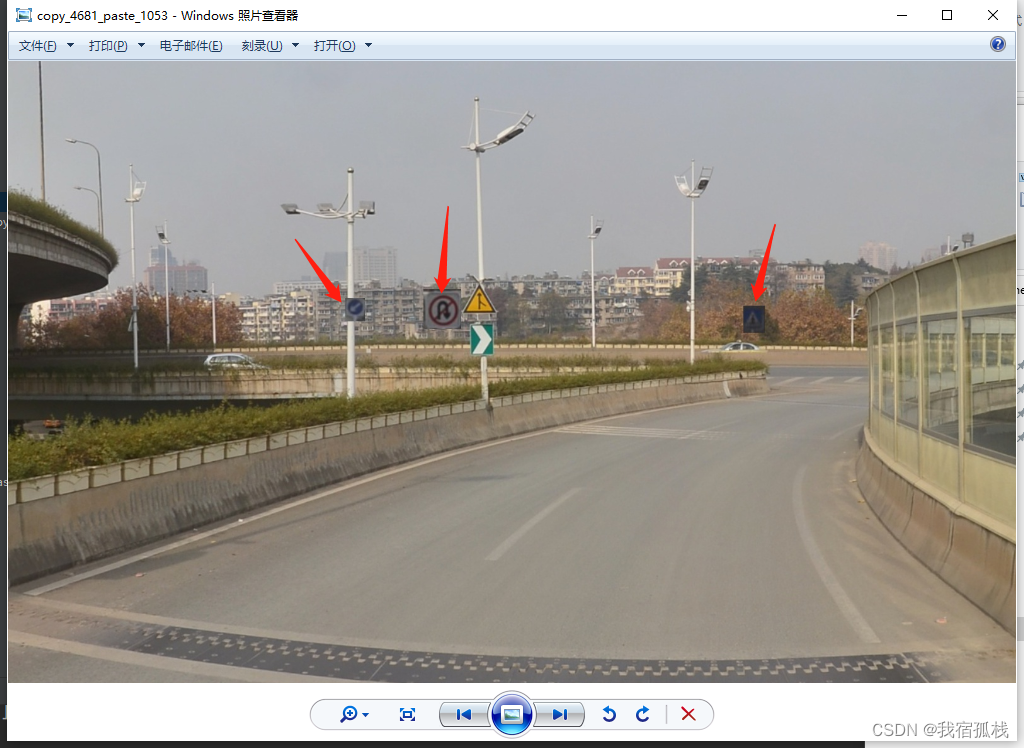
输入图:
图A

图B

实现过程:结果图C中箭头所指三个标志牌即截取图A中的标志牌经过翻转抖动等操作复制粘贴到图B中得到图C。
原文的输入标签格式为
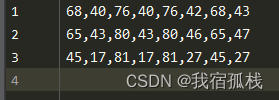
如图8个个数,分别代表BOX的四个点,而YOLO格式的标签格式为:

图中5个数值分别表示label_index,cx,cy,w,h,
label_index :为标签名称在标签数组中的索引,下标从 0 开始。
cx:标记框中心点的 x 坐标,数值是原始中心点 x 坐标除以 图宽 后的结果。
cy:标记框中心点的 y 坐标,数值是原始中心点 y 坐标除以 图高 后的结果。
w:标记框的 宽,数值为 原始标记框的 宽 除以 图宽 后的结果。
h:标记框的 高,数值为 原始标记框的 高 除以 图高 后的结果。
改进的代码可以直接将YOLO格式的标签作为输入。
import numpy as np
import cv2
import os
import tqdm
import argparse
from skimage.draw import polygon
import random
def random_flip_horizontal(img, box, p=0.5):
'''
对img和mask随机进行水平翻转。box为二维np.array。
https://blog.csdn.net/weixin_41735859/article/details/106468551
img[:,:,::-1] gbr-->bgr、img[:,::-1,:] 水平翻转、img[::-1,:,:] 上下翻转
'''
if np.random.random() < p:
w = img.shape[1]
img = img[:, ::-1, :]
box[:, [0, 2, 4, 6]] = w - box[:, [2, 0, 6, 4]] # 仅针对4个点变换
return img, box
def Large_Scale_Jittering(img, box, min_scale=0.1, max_scale=2.0):
'''
对img和box进行0.1-2.0的大尺度抖动,并变回h*w的大小。
'''
rescale_ratio = np.random.uniform(min_scale, max_scale)
h, w, _ = img.shape
# rescale
h_new, w_new = int(h * rescale_ratio), int(w * rescale_ratio)
img = cv2.resize(img, (w_new, h_new), interpolation=cv2.INTER_LINEAR)
# crop or padding
# x,y是随机选择左上角的一个点,让小图片在这个位置,或者让大图片从这个位置开始裁剪
x, y = int(np.random.uniform(0, abs(w_new - w))), int(np.random.uniform(0, abs(h_new - h)))
# 如果图像缩小了,那么其余部分要填充为像素168大小
if rescale_ratio <= 1.0: # padding
img_pad = np.ones((h, w, 3), dtype=np.uint8) * 168
img_pad[y:y + h_new, x:x + w_new, :] = img
box[:, [0, 2, 4, 6]] = box[:, [0, 2, 4, 6]] * w_new / w + x # x坐标
box[:, [0, 2, 4, 6]] = box[:, [0, 2, 4, 6]] * w_new / w + x
box[:, [1, 3, 5, 7]] = box[:, [1, 3, 5, 7]] * h_new / h + y # y坐标
return img_pad, box
# 如果图像放大了,那么要裁剪成h*w的大小
else: # crop
img_crop = img[y:y + h, x:x + w, :]
box[:, [0, 2, 4, 6]] = box[:, [0, 2, 4, 6]] * w_new / w - x
box[:, [1, 3, 5, 7]] = box[:, [1, 3, 5, 7]] * h_new / h - y
return img_crop, box
def img_add(img_src, img_main, mask_src, box_src):
'''
将src加到main图像中,结果图还是main图像的大小。
'''
if len(img_main.shape) == 3:
h, w, c = img_main.shape
elif len(img_main.shape) == 2:
h, w = img_main.shape
src_h, src_w = img_src.shape[0], img_src.shape[1]
mask = np.asarray(mask_src, dtype=np.uint8)
# mask是二值图片,对src进行局部遮挡,即只露出目标物体的像素。
sub_img01 = cv2.add(img_src, np.zeros(np.shape(img_src), dtype=np.uint8), mask=mask) # 报错深度不一致
mask_02 = cv2.resize(mask, (w, h), interpolation=cv2.INTER_NEAREST)
mask_02 = np.asarray(mask_02, dtype=np.uint8)
sub_img02 = cv2.add(img_main, np.zeros(np.shape(img_main), dtype=np.uint8),
mask=mask_02) # 在main图像上对应位置挖了一块
# main图像减去要粘贴的部分的图,然后加上复制过来的图
img_main = img_main - sub_img02 + cv2.resize(sub_img01, (w, h),
interpolation=cv2.INTER_NEAREST)
box_src[:, [0, 2, 4, 6]] = box_src[:, [0, 2, 4, 6]] * w / src_w
box_src[:, [1, 3, 5, 7]] = box_src[:, [1, 3, 5, 7]] * h / src_h
return img_main, box_src
def normal_(jpg_path, txt_path="", box=None):
"""
根据txt获得box或者根据box获得mask。
:param jpg_path: 图片路径
:param txt_path: x1,y1,x2,y2 x3,y3,x4,y4...
:param box: 如果有box,则为根据box生成mask
:return: 图像,box 或 掩码
"""
if isinstance(jpg_path, str): # 如果是路径就读取图片
jpg_path = cv2.imread(jpg_path)
print(jpg_path)
# jpg_path = cv2.imread(jpg_path)
img = jpg_path.copy()
if box is None: # 一定有txt_path
lines = open(txt_path).readlines()
box = []
for line in lines:
ceils = line.strip("\n").split(' ')
xy = []
for ceil in ceils:
xy.append(round(float(ceil)))
x = xy[1]
y = xy[2]
w = xy[3] / 2
h = xy[4] / 2
xy = [x - w, y + h, x + w, y + h, x - w, y - h, x + w, y - h]
box.append(np.array(xy))
return np.array(img), np.array(box)
else: # 获得mask
h, w = img.shape[:2]
mask = np.zeros((h, w), dtype=np.float32)
for xy in box: # 对每个框
xy = np.array(xy).reshape(-1, 2)
cv2.fillPoly(mask, [xy.astype(np.int32)], 1)
return np.array(mask)
def is_coincide(polygon_1, polygon_2):
'''
判断2个四边形是否重合
:param polygon_1: [x1, y1,...,x4, y4]
:param polygon_2:
:return: bool,1表示重合
'''
rr1, cc1 = polygon([polygon_1[i] for i in range(0, len(polygon_1), 2)],
[polygon_1[i] for i in range(1, len(polygon_1), 2)])
rr2, cc2 = polygon([polygon_2[i] for i in range(0, len(polygon_2), 2)],
[polygon_2[i] for i in range(1, len(polygon_2), 2)])
try: # 能包含2个四边形的最小矩形长宽
r_max = max(rr1.max(), rr2.max()) + 1
c_max = max(cc1.max(), cc2.max()) + 1
except:
return 0
# 相当于canvas是包含了2个多边形的一个画布,有2个多边形的位置像素为1,重合位置像素为2
canvas = np.zeros((r_max, c_max))
canvas[rr1, cc1] += 1
canvas[rr2, cc2] += 1
intersection = np.sum(canvas == 2)
return 1 if intersection != 0 else 0
def copy_paste(img_main_path, img_src_path, txt_main_path, txt_src_path, coincide=False, muti_obj=True):
'''
整个复制粘贴操作,输入2张图的图片和坐标路径,返回其融合后的图像和坐标结果。
1. 传入随机选择的main图像和src图像的img和txt路径;
2. 对其进行随机水平翻转;
3. 对其进行随机抖动;
4. 获得src变换完后对应的mask;
5. 将src的结果加到main中,返回对应main_new的img和src图的box.
'''
# 读取图像和坐标
img_main, box_main = normal_(img_main_path, txt_main_path)
img_src, box_src = normal_(img_src_path, txt_src_path)
# 随机水平翻转
img_main, box_main = random_flip_horizontal(img_main, box_main)
img_src, box_src = random_flip_horizontal(img_src, box_src)
# LSJ, Large_Scale_Jittering 大尺度抖动,并变回h*w大小
img_main, box_main = Large_Scale_Jittering(img_main, box_main)
img_src, box_src = Large_Scale_Jittering(img_src, box_src)
if not muti_obj or box_src.ndim == 1: # 只复制粘贴一个目标
id = random.randint(0, len(box_src) - 1)
box_src = box_src[id]
box_src = box_src[np.newaxis, :] # 增加一维
# 获得一系列变换后的img_src的mask
mask_src = normal_(img_src_path, box=box_src)
# 将src结果加到main图像中,返回main图像的大小的叠加图
img, box_src = img_add(img_src, img_main, mask_src, box_src)
# 判断融合后的区域是否重合
if not coincide:
for point_main in box_main:
for point_src in box_src:
if is_coincide(point_main, point_src):
return None, None
box = np.vstack((box_main, box_src))
return img, box
def save_res(img, img_path, box, txt_path):
'''
保存图片和txt坐标结果。
'''
cv2.imwrite(img_path, img)
h, w = img.shape[:2]
with open(txt_path, 'w+') as ftxt:
for point in box: # [x1,y1,...x4,,y4]
strxy = ""
for i, p in enumerate(point):
if i % 2 == 0: # x坐标
p = np.clip(p, 0, w - 1)
else: # y坐标
p = np.clip(p, 0, h - 1)
strxy = strxy + str(p) + ','
strxy = strxy[:-1] # 去掉最后一个逗号
ftxt.writelines(strxy + "\n")
def main(args):
# 图像和坐标txt文件输入路径
JPEGs = os.path.join(args.input_dir, 'images')
BOXes = os.path.join(args.input_dir, 'labels')
# 输出路径
os.makedirs(args.output_dir, exist_ok=True)
os.makedirs(os.path.join(args.output_dir, 'cpAug_jpg'), exist_ok=True)
os.makedirs(os.path.join(args.output_dir, 'cpAug_txt'), exist_ok=True)
# 参与数据增强的图片名称,不含后缀
imgs_list = open(args.aug_txt, 'r').read().splitlines()
flag = '.jpg' # 图像的后缀名 .jpg ,png
tbar = tqdm.tqdm(imgs_list, ncols=100) # 进度条显示
for src_name in tbar:
# src图像
img_src_path = os.path.join(JPEGs, src_name + flag)
txt_src_path = os.path.join(BOXes, src_name + '.txt')
# 随机选择main图像
main_name = np.random.choice(imgs_list)
img_main_path = os.path.join(JPEGs, main_name + flag)
txt_main_path = os.path.join(BOXes, main_name + '.txt')
# 数据增强
print(img_main_path)
print(img_src_path)
img, box = copy_paste(img_main_path, img_src_path, txt_main_path, txt_src_path,
args.coincide, args.muti_obj)
if img is None:
continue
# 保存结果
img_name = "copy_" + src_name + "_paste_" + main_name
print(os.path.join(args.output_dir, 'cpAug_jpg', img_name + flag))
save_res(img, os.path.join(args.output_dir, 'cpAug_jpg', img_name + flag),
box, os.path.join(args.output_dir, 'cpAug_txt', img_name + '.txt'))
def get_args():
parser = argparse.ArgumentParser()
parser.add_argument("--input_dir", default="D:/dataTest/oImage", type=str,
help="要进行数据增强的图像路径,路径结构下应有jpg和txt文件夹")
parser.add_argument("--output_dir", default="D:/dataTest/newImage", type=str,
help="保存数据增强结果的路径")
parser.add_argument("--aug_txt", default="D:/dataTest/oImage/test.txt",
type=str, help="要进行数据增强的图像的名字,不包含后缀")
parser.add_argument("--coincide", default=False, type=bool,
help="True表示允许数据增强后的图像目标出现重合,默认不允许重合")
parser.add_argument("--muti_obj", default=False, type=bool,
help="True表示将src图上的所有目标都复制粘贴,False表示只随机粘贴一个目标")
return parser.parse_args()
if __name__ == "__main__":
args = get_args()
main(args)