深度学习
前言
配好环境之后要做的第一件事就是采集数据集、然后标记数据集。
一、采集数据集
可以使用手机拍照或者爬虫爬取,注意图片格式要是jpg的形式
二、标记数据集
按照 PASCAL VOC 数据集格式进行存储数据,制作 VOC 格式数据集 步骤如下: ①创建文件夹,VOC 文件格式如下:
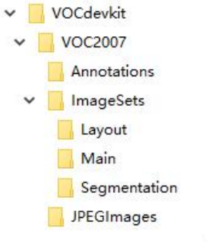
②将所有图片复制到 JPEGImage 文件夹下
③下载标注工具 labelImg。下载文件后,修改 data 文件夹下的 predefined_c lasses.txt 可以改变标签名称。 注意:软件 labelImg 的放置路径不要出现中文,否则会出现打不开软件的情 况。
④通过 Open Dir 打开图像存放的路径,即 JPEGImage 文件夹所在位置,按 w 键可以进行标注,标注完 Save 选择保存即可,生成的 xml 文件默认保存在 图片同路径下。

⑤标注完后,将标注 xml 文件,剪切存放在 Annotations 文件夹下。 ⑥将 VOCdevkit 数据集打包拷贝到训练的 Ubuntu 环境中,存放的路径是 darknet 下 scripts 文件里
这种标记方式本人非常不喜欢,我用的vott标注,可以直接导出文件,更方便一些,想了解的可以去看之前的博客,不多赘述了,其实 Make Sense更直接,可以直接导出yolo格式。在ubuntu中转换成yolo格式也只需要一行指令。
⑥在 VOC2007 目录下新建文件 test.py,把下面代码复制进去,终端运行
python test.py
生成 ImageSets/Main 文件夹下所需的训练集/测试集 txt 文件
代码:
import os
import random
trainval_percent = 0.1
train_percent = 0.9
xmlfilepath = 'Annotations'
txtsavepath = 'ImageSets\Main'
total_xml = os.listdir(xmlfilepath)
num = len(total_xml)
list = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list, tv)
train = random.sample(trainval, tr)
ftrainval = open('ImageSets/Main/val.txt', 'w')
ftest = open('ImageSets/Main/test.txt', 'w')
ftrain = open('ImageSets/Main/train.txt', 'w')
fval = open('ImageSets/Main/trainval.txt', 'w')
for i in list:
name = total_xml[i][:-4] + '\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftest.write(name)
else: fval.write(name)
else: ftrain.write(name)
⑦格式转换。VOC 格式数据集标签还不能直接用于 YOLO 训练,需要转换 成 YOLO 标签格式。在 darknet/scripts 文件夹下有 voc_label.py 文件,用于将 VOC 格式标签转换为 YOLO 格式,终端运行以下指令即可
python voc_label.py
运行前需要注意的是,需要在 voc_label.py 第九行,修改为自己的类别名称。

运行好以后,会在 VOC2007 文件下生成存放 YOLO 格式标签的 labels 文件 夹,并且在 scripts 文件夹下生成 2007_train.txt 和 2007_val.txt,后续训练时需要 引用这两个文件调出数据集。
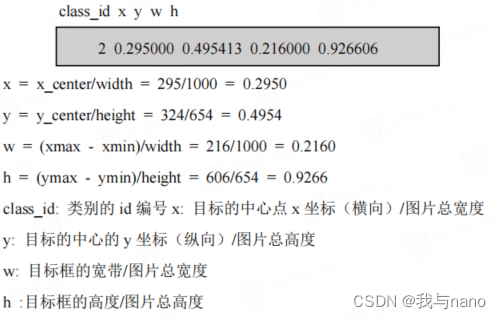
⑧介绍 VOC 格式标注和 YOLO 格式区别

图片 width =1000 、height = 654
PASCAL VOC 标注文件如下:

而成 YOLO 格式的 txt 标记文件如下: