前言
BDD100K由伯克利大学AI实验室(BAIR)发布,是目前最大规模、内容最具多样性的公开驾驶数据集。BDD100K 数据集包含10万段高清视频,每个视频约40秒,720p,30 fps 。每个视频的第10秒对关键帧进行采样,得到10万张图片(图片尺寸:1280 * 720 ),并进行标注。
数据集按Train、Valid、Test三个部分,比例按照7:2:1分配,共近10万张图片,其中训练集7万张图片,验证集1万张图片,测试集2万图片(注意:测试集test官网并未提供标注文件)。
数据集中的GT框标签共有10个类别,分别为:
bus,traffic light,traffic sign,person,bike,truck,motor,car,train,rider
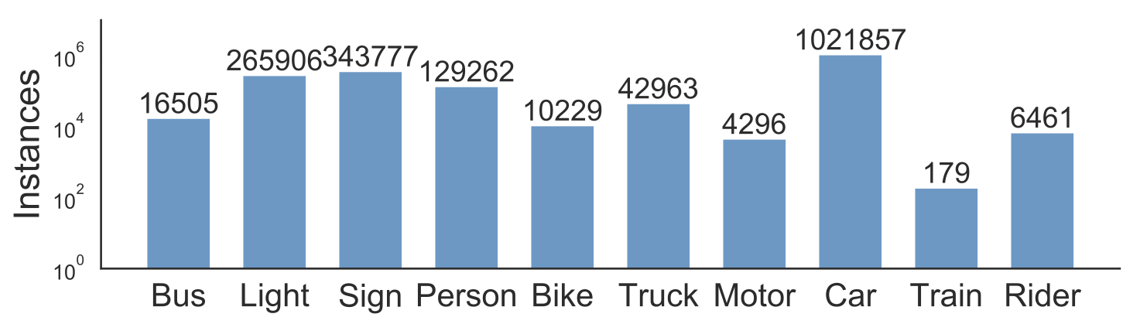
总共约有184万个标定框,不同类型目标的数目统计如图所示。
格式转换
1、将BDD100K数据集json标签格式转换为VOC的xml格式
创建bdd2voc.py,脚本如下,记得修改路径。
# -*- coding: utf8 -*-
import os
import json
import sys
from xml.etree import ElementTree
from xml.etree.ElementTree import Element, SubElement
from lxml import etree
from xml.dom.minidom import parseString
#数据集个类别
categorys = ['car', 'bus', 'person', 'bike', 'truck', 'motor', 'train', 'rider', 'traffic sign', 'traffic light']
def parseJson(jsonFile):
'''
params:
jsonFile -- BDD00K数据集的一个json标签文件
return:
返回一个列表的列表,存储了一个json文件里面的方框坐标及其所属的类,
形如:[[325, 342, 376, 384, 'car'], [245, 333, 336, 389, 'car']]
'''
objs = []
obj = []
f = open(jsonFile)
info = json.load(f)
objects = info['frames'][0]['objects']
for i in objects:
if(i['category'] in categorys):
obj.append(int(i['box2d']['x1']))
obj.append(int(i['box2d']['y1']))
obj.append(int(i['box2d']['x2']))
obj.append(int(i['box2d']['y2']))
obj.append(i['category'])
objs.append(obj)
obj = []
#print("objs",objs)
return objs
class PascalVocWriter:
def __init__(self, foldername, filename, imgSize, databaseSrc='Unknown', localImgPath=None):
'''
params:
foldername -- 要存储的xml文件的父目录
filename -- xml文件的文件名
imgSize -- 图片的尺寸
databaseSrc -- 数据库名,这里不需要,默认为Unknown
localImaPath -- xml文件里面的<path></path>标签的内容
'''
self.foldername = foldername
self.filename = filename
self.databaseSrc = databaseSrc
self.imgSize = imgSize
self.boxlist = []
self.localImgPath = localImgPath
def prettify(self, elem):
"""
params:
elem -- xml的根标签,以<annotation>开始
return:
返回一个美观输出的xml(用到minidom),本质是一个str
"""
xml = ElementTree.tostring(elem)
dom = parseString(xml)
# print(dom.toprettyxml(' '))
prettifyResult = dom.toprettyxml(' ')
return prettifyResult
def genXML(self):
"""
return:
生成一个VOC格式的xml,返回一个xml的根标签,以<annotation>开始
"""
# Check conditions
if self.filename is None or \
self.foldername is None or \
self.imgSize is None or \
len(self.boxlist) <= 0:
return None
top = Element('annotation') # 创建一个根标签<annotation>
folder = SubElement(top, 'folder') # 在根标签<annotation>下创建一个子标签<folder>
folder.text = self.foldername # 用self.foldername的数据填充子标签<folder>
filename = SubElement(top, 'filename') # 在根标签<annotation>下创建一个子标签<filename>
filename.text = self.filename # 用self.filename的数据填充子标签<filename>
localImgPath = SubElement(top, 'path') # 在根标签<annotation>下创建一个子标签<path>
localImgPath.text = self.localImgPath # 用self.localImgPath的数据填充子标签<path>
source = SubElement(top, 'source') # 在根标签<annotation>下创建一个子标签<source>
database = SubElement(source, 'database') # 在根标签<source>下创建一个子标签<database>
database.text = self.databaseSrc # 用self.databaseSrc的数据填充子标签<database>
size_part = SubElement(top, 'size') # 在根标签<annotation>下创建一个子标签<size>
width = SubElement(size_part, 'width') # 在根标签<size>下创建一个子标签<width>
height = SubElement(size_part, 'height') # 在根标签<size>下创建一个子标签<height>
depth = SubElement(size_part, 'depth') # 在根标签<size>下创建一个子标签<depth>
width.text = str(self.imgSize[1]) # 用self.imgSize[1]的数据填充子标签<width>
height.text = str(self.imgSize[0]) # 用self.imgSize[0]的数据填充子标签<height>
if len(self.imgSize) == 3: # 如果图片深度为3,则用self.imgSize[2]的数据填充子标签<height>,否则用1填充
depth.text = str(self.imgSize[2])
else:
depth.text = '1'
segmented = SubElement(top, 'segmented')
segmented.text = '0'
return top
def addBndBox(self, xmin, ymin, xmax, ymax, name):
'''
将检测对象框坐标及其对象类别作为一个字典加入到self.boxlist中
params:
xmin -- 检测框的左上角的x坐标
ymin -- 检测框的左上角的y坐标
xmax -- 检测框的右下角的x坐标
ymax -- 检测框的右下角的y坐标
name -- 检测框内的对象类别名
'''
bndbox = {
'xmin': xmin, 'ymin': ymin, 'xmax': xmax, 'ymax': ymax}
bndbox['name'] = name
self.boxlist.append(bndbox)
def appendObjects(self, top):
'''
在xml文件中加入检测框的坐标及其对象类别名
params:
top -- xml的根标签,以<annotation>开始
'''
for each_object in self.boxlist:
object_item = SubElement(top, 'object')
name = SubElement(object_item, 'name')
name.text = str(each_object['name'])
pose = SubElement(object_item, 'pose')
pose.text = "Unspecified"
truncated = SubElement(object_item, 'truncated')
truncated.text = "0"
difficult = SubElement(object_item, 'Difficult')
difficult.text = "0"
bndbox = SubElement(object_item, 'bndbox')
xmin = SubElement(bndbox, 'xmin')
xmin.text = str(each_object['xmin'])
ymin = SubElement(bndbox, 'ymin')
ymin.text = str(each_object['ymin'])
xmax = SubElement(bndbox, 'xmax')
xmax.text = str(each_object['xmax'])
ymax = SubElement(bndbox, 'ymax')
ymax.text = str(each_object['ymax'])
def save(self, targetFile=None):
'''
以美观输出的xml格式来保存xml文件
params:
targetFile -- 存储的xml文件名,不包括.xml部分
'''
root = self.genXML()
self.appendObjects(root)
out_file = None
subdir = self.foldername.split('/')[-1]
if not os.path.isdir(subdir):
os.mkdir(subdir)
if targetFile is None:
with open(self.foldername+'/'+self.filename + '.xml', 'w') as out_file:
prettifyResult = self.prettify(root)
out_file.write(prettifyResult)
out_file.close()
else:
with open(targetFile, 'w') as out_file:
prettifyResult = self.prettify(root)
out_file.write(prettifyResult)
out_file.close()
class PascalVocReader:
def __init__(self, filepath):
# shapes type:
# [labbel, [(x1,y1), (x2,y2), (x3,y3), (x4,y4)], color, color]
self.shapes = []
self.filepath = filepath
self.parseXML()
def getShapes(self):
return self.shapes
def addShape(self, label, bndbox):
xmin = int(bndbox.find('xmin').text)
ymin = int(bndbox.find('ymin').text)
xmax = int(bndbox.find('xmax').text)
ymax = int(bndbox.find('ymax').text)
points = [(xmin, ymin), (xmax, ymin), (xmax, ymax), (xmin, ymax)]
self.shapes.append((label, points, None, None))
def parseXML(self):
assert self.filepath.endswith('.xml'), "Unsupport file format"
parser = etree.XMLParser(encoding='utf-8')
xmltree = ElementTree.parse(self.filepath, parser=parser).getroot()
filename = xmltree.find('filename').text
for object_iter in xmltree.findall('object'):
bndbox = object_iter.find("bndbox")
label = object_iter.find('name').text
self.addShape(label, bndbox)
return True
def main(srcDir, dstDir):
i = 1
# os.walk()
# dirName是你所要遍历的目录的地址, 返回的是一个三元组(root,dirs,files)
# root所指的是当前正在遍历的这个文件夹的本身的地址
# dirs是一个 list ,内容是该文件夹中所有的目录的名字(不包括子目录)
# files 同样是 list , 内容是该文件夹中所有的文件(不包括子目录)
for dirpath, dirnames, filenames in os.walk(srcDir):
# print(dirpath, dirnames, filenames)
for filepath in filenames:
fileName = os.path.join(dirpath,filepath)
print(fileName)
print("processing: {}, {}".format(i, fileName))
i = i + 1
xmlFileName = filepath[:-5] # remove ".json" 5 character
# 解析该json文件,返回一个列表的列表,存储了一个json文件里面的所有方框坐标及其所属的类
objs = parseJson(str(fileName))
# 如果存在检测对象,创建一个与该json文件具有相同名的VOC格式的xml文件
if len(objs):
tmp = PascalVocWriter(dstDir, xmlFileName, (720,1280,3), fileName)
for obj in objs:
tmp.addBndBox(obj[0],obj[1],obj[2],obj[3],obj[4])
tmp.save()
else:
print(fileName)
if __name__ == '__main__':
# 这里写自己的json标签路径
# srcDir = '/bdd100k_labels/labels/100k/val' # 原json存放路径
# dstDir = '/bdd100k_labels/labels/100k/val_xml' # 转换后xml存放路径
srcDir = '/bdd100k_labels/labels/100k/train'
dstDir = '/bdd100k_labels/labels/100k/train_xml'
main(srcDir, dstDir)
运行之后,会生成新的存放xml的文件夹train_xml,再改变路径,换成val路径,转换生成val_xml,至此转换完毕。
2、将xml标签格式转换为YOLO的txt格式
创建xml_to_yolo.py
import glob
import xml.etree.ElementTree as ET
# 类名
class_names = ['car', 'bus', 'person', 'bike', 'truck', 'motor', 'train', 'rider', 'traffic sign', 'traffic light']
# 转换一个xml文件为txt
def single_xml_to_txt(xml_file):
tree = ET.parse(xml_file)
root = tree.getroot()
# 保存的txt文件路径
txt_file = xml_file.split('.')[0]+'.txt'
with open(txt_file, 'w') as txt_file:
for member in root.findall('object'):
#filename = root.find('filename').text
picture_width = int(root.find('size')[0].text)
picture_height = int(root.find('size')[1].text)
class_name = member[0].text
# 类名对应的index
class_num = class_names.index(class_name)
box_x_min = int(member[4][0].text) # 左上角横坐标
box_y_min = int(member[4][1].text) # 左上角纵坐标
box_x_max = int(member[4][2].text) # 右下角横坐标
box_y_max = int(member[4][3].text) # 右下角纵坐标
# 转成相对位置和宽高
x_center = (box_x_min + box_x_max) / (2 * picture_width)
y_center = (box_y_min + box_y_max) / (2 * picture_height)
width = (box_x_max - box_x_min) / (2 * picture_width)
height = (box_y_max - box_y_min) / (2 * picture_height)
print(class_num, x_center, y_center, width, height)
txt_file.write(str(class_num) + ' ' + str(x_center) + ' ' + str(y_center) + ' ' + str(width) + ' ' + str(height) + '\n')
# 转换文件夹下的所有xml文件为txt
def dir_xml_to_txt(path):
i=1
for xml_file in glob.glob(path + '*.xml'):
print("processing {}, {}".format(i, xml_file+'.xml'))
single_xml_to_txt(xml_file)
i += 1
def main(path):
dir_xml_to_txt(path)
if __name__ == '__main__':
# xml文件路径
path = '/bdd100k_labels/labels/100k/train_xml/' # 第一步生成的路径
#path = '/bdd100k_labels/labels/100k/val_xml/'
main(path)
运行之后,会在相同文件夹train_xml下生成txt标签文件,所以,需要自己进入train_xml文件夹下,将所有的txt文件其剪切到新的文件夹train_txt下。(不想麻烦的,可以修改代码中txt存储的路径)
最终文件夹结构如下所示:
bdd100k_labels
--labels
--100k
--train # json标签文件
--train_xml # xml标签文件
--train_txt # txt标签文件
--val
--val_xml
--val_txt
3、生成train.txt和vla.txt文件
创建bdd100k_train_val.py,生成train.txt和val.txt文件(二者包含的是训练集和验证集的所有图片的路径)
import glob
def generate_train_and_val(image_path, txt_file):
with open(txt_file, 'w') as tf:
i=1
for jpg_file in glob.glob(image_path + '*.jpg'):
print("processing {}".format(i))
tf.write(jpg_file + '\n')
i += 1
def main(path, dstpath):
generate_train_and_val(path, dstpath)
if __name__ == '__main__':
#srcpath = 'bdd100k/images/val/'
#dstpath = 'bdd100k/images/val.txt'
srcpath = 'bdd100k/images/train/' # 训练集图片所在的路径(自己设置)
dstpath = 'bdd100k/train.txt' # 新生成的txt所在路径(自己设置)
main(srcpath, dstpath)
4、调整文件结构
首先,建立images文件夹,存放的是图片;
然后,同级目录下建立labels文件夹,接着再新建两个存放训练集和验证集标签的文件夹train和val,存放的是第2步生成的txt标签文件,把txt标签文件复制过来;
最后,将第3步生成的两个train.txt和val.txt复制到同级目录下;
--images
--train
--val
--test
--labels
--train
--val # 建议直接把所有的txt直接复制到labels目录下,不要再设置文件夹
--train.txt
--val.txt
其实,按照VOCdevkit格式修改文件结构也可,本人喜欢按照VOC格式修改,这里不再多说,可以参考VOC数据集格式博文。
参考链接:
https://blog.csdn.net/qq583083658/article/details/86496563