1.数据集下载
WiderPerson: A Diverse Dataset for Dense Pedestrian Detection in the Wild
使用百度网盘下载速度慢,可以采用以下方式来加速:
首先确保自己的百度网盘已经是最新版本,可在版本升级的地方查看是否为最新版本。
之后打开设置,点击“传输”,优化速率这一栏点“去开启”
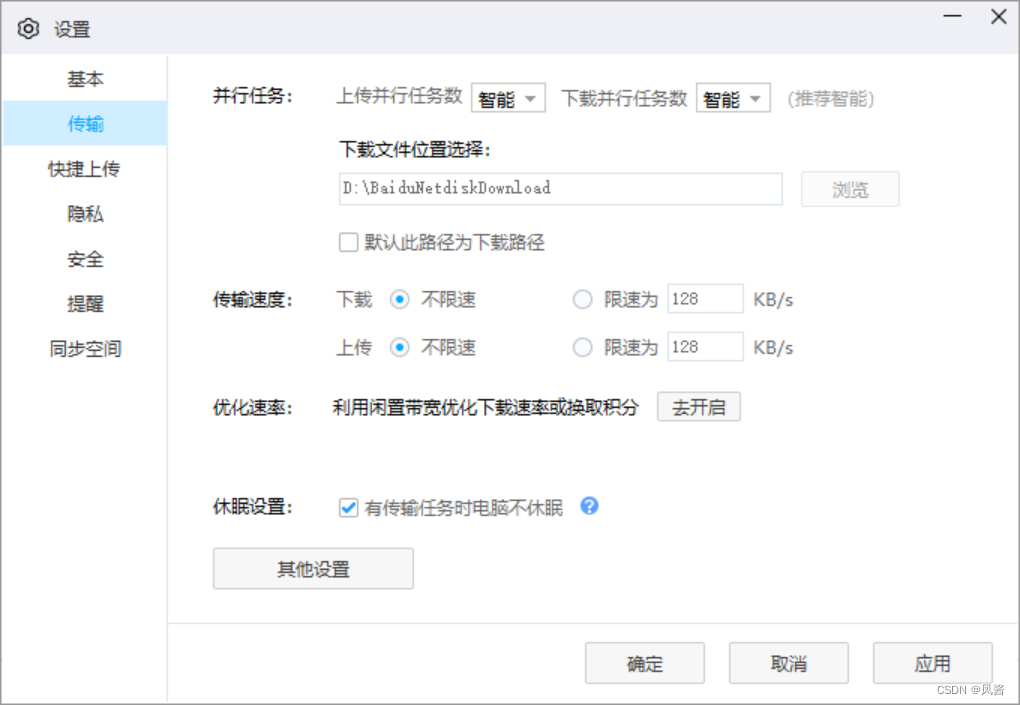
开启之后会发现下载速度明显提升。
2.生成voc2007的文件夹,提取出xml文件和jpg图片
把下面的py文件运行3遍,第一遍运行train.txt文件,第二遍运行val.txt文件,并且注释掉make_voc_dir函数的调用,自己可以根据自己的场景需要进行数据集的筛选,第三遍运行test.txt文件,并注释掉with open(label_path) as file和with open(xml_path, ‘wb’) as f里面的内容。
import os
import numpy as np
import scipy.io as sio
import shutil
from lxml.etree import Element, SubElement, tostring
from xml.dom.minidom import parseString
import cv2
def make_voc_dir():
# labels 目录若不存在,创建labels目录。若存在,则清空目录
if not os.path.exists('../VOC2007/Annotations'):
os.makedirs('../VOC2007/Annotations')
if not os.path.exists('../VOC2007/ImageSets'):
os.makedirs('../VOC2007/ImageSets')
os.makedirs('../VOC2007/ImageSets/Main')
if not os.path.exists('../VOC2007/JPEGImages'):
os.makedirs('../VOC2007/JPEGImages')
if __name__ == '__main__':
# < class_label =1: pedestrians > 行人
# < class_label =2: riders > 骑车的
# < class_label =3: partially-visible persons > 遮挡的部分行人
# < class_label =4: ignore regions > 一些假人,比如图画上的人
# < class_label =5: crowd > 拥挤人群,直接大框覆盖了
classes = {'1': 'pedestrians',
'2': 'riders',
'3': 'partially',
'4':'ignore',
'5':'crowd'
}#这里如果自己只要人,可以把1-5全标记为people,也可以根据自己场景需要筛选
VOCRoot = '../VOC2007'
widerDir = 'C:/Users/邓卓/Desktop/WiderPerson' # 数据集所在的路径
wider_path = 'C:/Users/邓卓/Desktop/WiderPerson/train.txt'#这里第一次train,第二次val,第三次test
#这个函数第一次要用,第二次和第三次使用时,需要将其注释掉,否则会报错
make_voc_dir()
with open(wider_path, 'r') as f:
imgIds = [x for x in f.read().splitlines()]
for imgId in imgIds:
objCount = 0 # 一个标志位,用来判断该img是否包含我们需要的标注
filename = imgId + '.jpg'
img_path = '../WiderPerson/images/' + filename
print('Img :%s' % img_path)
img = cv2.imread(img_path)
width = img.shape[1] # 获取图片尺寸
height = img.shape[0] # 获取图片尺寸 360
node_root = Element('annotation')
node_folder = SubElement(node_root, 'folder')
node_folder.text = 'JPEGImages'
node_filename = SubElement(node_root, 'filename')
node_filename.text = 'VOC2007/JPEGImages/%s' % filename
node_size = SubElement(node_root, 'size')
node_width = SubElement(node_size, 'width')
node_width.text = '%s' % width
node_height = SubElement(node_size, 'height')
node_height.text = '%s' % height
node_depth = SubElement(node_size, 'depth')
node_depth.text = '3'
label_path = img_path.replace('images', 'Annotations') + '.txt'
#此处内容在第三次运行时需要注释掉
with open(label_path) as file:
line = file.readline()
count = int(line.split('\n')[0]) # 里面行人个数
line = file.readline()
while line:
cls_id = line.split(' ')[0]
xmin = int(line.split(' ')[1]) + 1
ymin = int(line.split(' ')[2]) + 1
xmax = int(line.split(' ')[3]) + 1
ymax = int(line.split(' ')[4].split('\n')[0]) + 1
line = file.readline()
cls_name = classes[cls_id]
obj_width = xmax - xmin
obj_height = ymax - ymin
difficult = 0
if obj_height <= 6 or obj_width <= 6:
difficult = 1
node_object = SubElement(node_root, 'object')
node_name = SubElement(node_object, 'name')
node_name.text = cls_name
node_difficult = SubElement(node_object, 'difficult')
node_difficult.text = '%s' % difficult
node_bndbox = SubElement(node_object, 'bndbox')
node_xmin = SubElement(node_bndbox, 'xmin')
node_xmin.text = '%s' % xmin
node_ymin = SubElement(node_bndbox, 'ymin')
node_ymin.text = '%s' % ymin
node_xmax = SubElement(node_bndbox, 'xmax')
node_xmax.text = '%s' % xmax
node_ymax = SubElement(node_bndbox, 'ymax')
node_ymax.text = '%s' % ymax
node_name = SubElement(node_object, 'pose')
node_name.text = 'Unspecified'
node_name = SubElement(node_object, 'truncated')
node_name.text = '0'
image_path = VOCRoot + '/JPEGImages/' + filename
xml = tostring(node_root, pretty_print=True) # 'annotation'
dom = parseString(xml)
xml_name = filename.replace('.jpg', '.xml')
xml_path = VOCRoot + '/Annotations/' + xml_name
#此处内容在第三次运行时需要注释掉
with open(xml_path, 'wb') as f:
f.write(xml)
# widerDir = '../WiderPerson' # 数据集所在的路径
shutil.copy(img_path, '../VOC2007/JPEGImages/' + filename)
此程序运行三遍之后,会在同目录下生成VOC2007的文件夹,里面包含这三个文件夹

3.划分数据集
划分数据集,创建split_train_val.py文件,更改自己的xml和txt文件夹目录。
import random
import os
import argparse
# annotations_path and save_txt_path
def get_opt():
parser = argparse.ArgumentParser()
parser.add_argument('--xml_path', default='C:/Users/邓卓/Desktop/yolov5-master/people_data/Annotations/',
type=str, help='input xml file ')
parser.add_argument('--txt_path', default="C:/Users/邓卓/Desktop/yolov5-master/people_data/ImageSets/Main/",
type=str, help='output txt file')
opt = parser.parse_args()
return opt
opt = get_opt()
# xml_path
xml_file = opt.xml_path
# save_txt_path
save_txt_file = opt.txt_path
# 若save_txt_path不存在,则手动创建
if not os.path.exists(save_txt_file):
os.makedirs(save_txt_file)
# 迭代xml_path路径下所有的文件返回包含该目录下所有文件的list(无序)
total_xml = os.listdir(xml_file)
# 获取包含所有数据list的长度
num = len(total_xml)
# list的范围,后续用于迭代向txt文件中写入数据(image)
list_index = range(num)
# 采集的数据集中训练数据和验证数据的总占比
train_val_percent = 1
# 训练数据的占比
train_percent = 0.99
# 采集的数据集中训练数据和验证数据的数量
tv = int(num * train_val_percent)
# 训练数据的数量,int()向下取整
tr = int(tv * train_percent)
# 从总数据中随机抽取训练集和验证集数据
train_val = random.sample(list_index, tv)
# 从训练集和验证集中随机抽取训练集数据
train = random.sample(train_val, tr)
# 创建train_val.txt,train.txt,test.txt,val.txt
file_train_vale = open(save_txt_file + 'train_val.txt', 'w')
file_train = open(save_txt_file + "train.txt", 'w')
file_test = open(save_txt_file + "test.txt", 'w')
file_val = open(save_txt_file + "val.txt", 'w')
# train_val.txt将训练集和验证集数据写入
# train.txt将训练集数据写入
# test.txt将测试集数据写入
# val.txt将验证集数据写入
for i in list_index:
# [:-4]将图片格式去掉,比如.jpg
data_name = total_xml[i][:-4] + '\n'
# 若该index存在于train_val中,则写入
if i in train_val:
file_train_vale.write(data_name)
if i in train:
file_train.write(data_name)
else:
file_val.write(data_name)
else:
file_test.write(data_name)
# 文件流关闭
file_train_vale.close()
file_train.close()
file_test.close()
file_val.close()
运行完该程序之后,在VOC2007/Imagesets/Main目录下生成了如下的txt文件
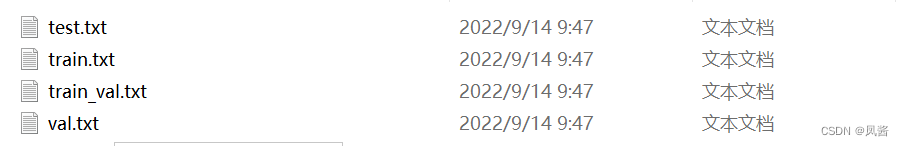
4.生成labels文件夹,里面包含yolo格式的txt文件
此处的voc_label.py一定要放在VOC2007的下一级文件当中,即和Annotations同目录的路径里,因为代码中有在该路径下生成的train.txt,test.txt,val.txt的图片路径文件,如果未放在该路径中,程序会报如下错误:no such file in xxx
# -*- coding: utf-8 -*-
import xml.etree.ElementTree as ET
import os
from os import getcwd
sets = ['train', 'val', 'test']
classes = ["pedestrians", "riders",'partially','ignore','crowd'] # 改成自己的类别
abs_path = os.getcwd()
print(abs_path)
def convert(size, box):
dw = 1. / (size[0])
dh = 1. / (size[1])
x = (box[0] + box[1]) / 2.0 - 1
y = (box[2] + box[3]) / 2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return x, y, w, h
def convert_annotation(image_id):
in_file = open('C:/Users/邓卓/Desktop/yolov5-master/people_data/Annotations/%s.xml' % (image_id), encoding='UTF-8')
out_file = open('C:/Users/邓卓/Desktop/yolov5-master/people_data/labels/%s.txt' % (image_id), 'w')
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
# difficult = obj.find('difficult').text
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
b1, b2, b3, b4 = b
# 标注越界修正
if b2 > w:
b2 = w
if b4 > h:
b4 = h
b = (b1, b2, b3, b4)
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
wd = getcwd()
for image_set in sets:
if not os.path.exists('C:/Users/邓卓/Desktop/yolov5-master/people_data/labels/'):
os.makedirs('C:/Users/邓卓/Desktop/yolov5-master/people_data/labels/')
image_ids = open('C:/Users/邓卓/Desktop/yolov5-master/people_data/ImageSets/Main/%s.txt' % (image_set)).read().strip().split()
list_file = open('people_data/%s.txt' % (image_set), 'w') #此处的意思是在VOC2007的子目录中生成图片路径的txt文件
for image_id in image_ids:
list_file.write( 'C:/Users/邓卓/Desktop/yolov5-master/people_data/JPEGImages/%s.jpg\n' % (image_id))
convert_annotation(image_id)
list_file.close()
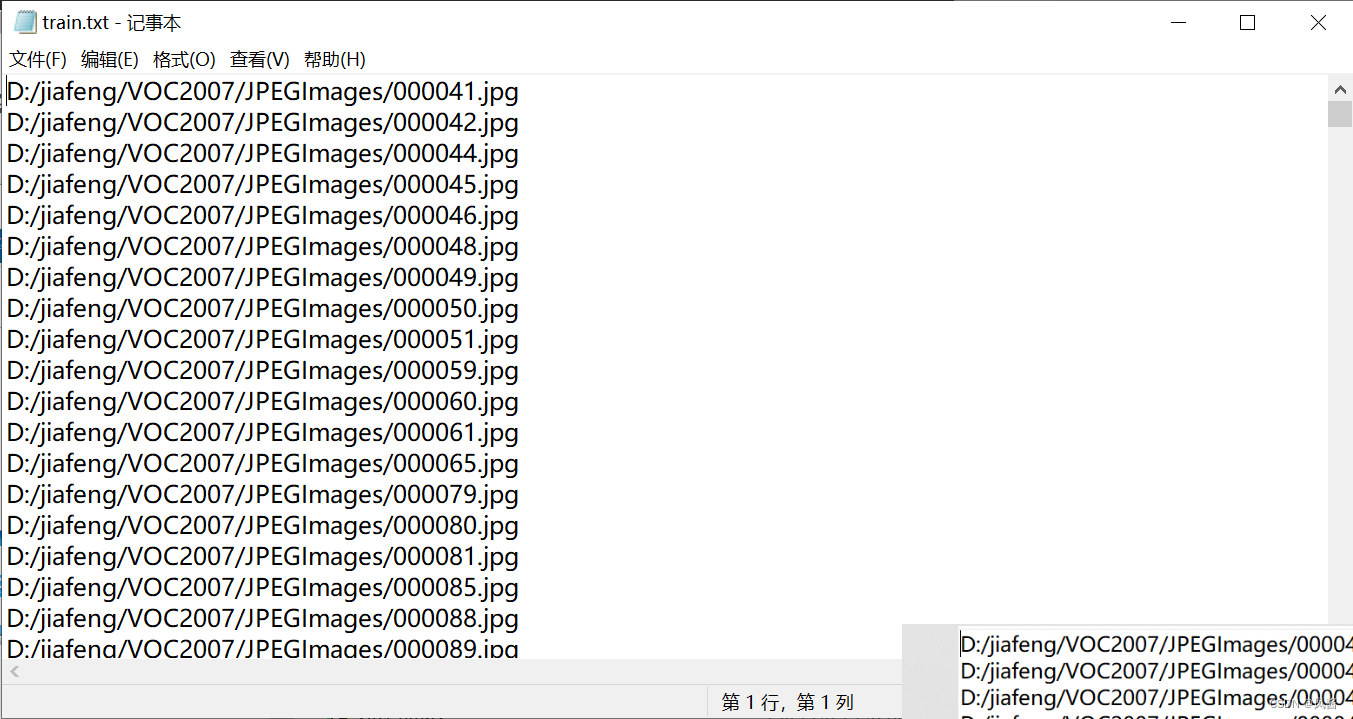
运行完该程序之后,VOC2007的文件夹里包含的文件如下,train.txt中的内容如下
5.生成标准的yolo支持的文件形式
运行makedata.py,会在VOC2007同目录下生成VOC文件夹,里面包含images,labels文件夹
#该文件我也放在VOC2007的文件夹运行的,放在其他目录下运行应该也没什么问题,不过路径需要使用绝对路径,否则会报错
import shutil
import os
file_List = ["train", "val", "test"]
for file in file_List:
if not os.path.exists('../VOC/images/%s' % file):
os.makedirs('../VOC/images/%s' % file)
if not os.path.exists('../VOC/labels/%s' % file):
os.makedirs('../VOC/labels/%s' % file)
print(os.path.exists('D:/jiafeng/VOC2007/%s.txt' % file))
f = open('D:/jiafeng/VOC2007/%s.txt' % file, 'r')
lines = f.readlines()
for line in lines:
print(line)
line = "/".join(line.split('/')[-5:]).strip()
shutil.copy(line, "../VOC/images/%s" % file)
line = line.replace('JPEGImages', 'labels')
line = line.replace('jpg', 'txt')
shutil.copy(line, "../VOC/labels/%s/" % file)在images和labels文件夹中都会有test、train、val文件夹
至此,VOC2007数据集已成功转化为yolo格式的数据集