前言
最近,在做实时性计算的东西,最初用的语义分割unet,发现它在服务器级GPU下推理的特别慢,但是精度还不错,但是我们追求的是实时性,所以我们还是用一下目标检测,最终选定yolov5
yolov5的数据集大家都知道,是需要知道每个锚框的,需要image和txt,而我的语义分割数据集有json文件
如图所示

#!/usr/bin/python

下文的8标注文件夹底下就是一些json格式的文件
json格式的样子:
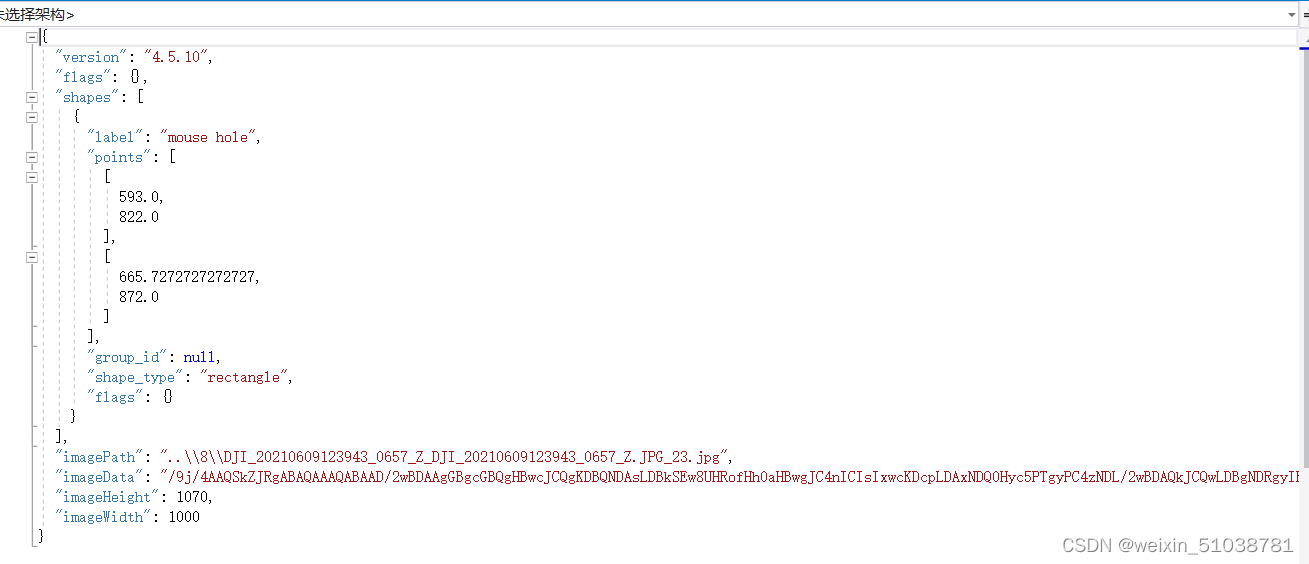
这里面是只有一类,points是当初给的图片(没有用labelme标过的)后来标的一些框的坐标,比如,我这块地有个鼠洞,我需要把他标出来,这样就生成了json格式的文件
import argparse
import json
import os
import os.path as osp
import base64
import warnings
import PIL.Image
import yaml
from labelme import utils
def main():
json_file = "D:/sd/裁切/8标注"
# freedom
list_path = os.listdir(json_file)
print('freedom =', json_file)
for i in range(0, len(list_path)):
path = os.path.join(json_file, list_path[i])
if os.path.isfile(path):
data = json.load(open(path))
img = utils.img_b64_to_arr(data['imageData'])
lbl, lbl_names = utils.labelme_shapes_to_label(img.shape, data['shapes'])
captions = ['%d: %s' % (l, name) for l, name in enumerate(lbl_names)]
lbl_viz = utils.draw_label(lbl, img, captions)
# out_dir = osp.basename(path).replace('.', '_')
out_dir = osp.basename(path).split('.json')[0]
save_file_name = out_dir
# out_dir = osp.join(osp.dirname(path), out_dir)
if not osp.exists(json_file + 'mask'):
os.mkdir(json_file + 'mask')
maskdir = json_file + 'mask'
if not osp.exists(json_file + 'mask_viz'):
os.mkdir(json_file + 'mask_viz')
maskvizdir = json_file + 'mask_viz'
out_dir1 = maskdir
# if not osp.exists(out_dir1):
# os.mkdir(out_dir1)
# PIL.Image.fromarray(img).save(out_dir1 + '\\' + save_file_name + '_img.png')
PIL.Image.fromarray(lbl).save(out_dir1 + '/' + save_file_name + '.png')
PIL.Image.fromarray(lbl_viz).save(maskvizdir + '/' + save_file_name +
'_label_viz.png')
with open(osp.join(out_dir1, 'label_names.txt'), 'w') as f:
for lbl_name in lbl_names:
f.write(lbl_name + '\n')
warnings.warn('info.yaml is being replaced by label_names.txt')
info = dict(label_names=lbl_names)
with open(osp.join(out_dir1, 'info.yaml'), 'w') as f:
yaml.safe_dump(info, f, default_flow_style=False)
print('Saved to: %s' % out_dir1)
if __name__ == '__main__':
# base64path = argv[1]
main()
转换结果:
 我们生成了与image相对应的txt文件
我们生成了与image相对应的txt文件

如100_0001_0007_1_4.jpg与上图中的txt相对应,所以我们这个做法省去了你用labelme一个一个标(如果一个一个标,估计要一年这么多要检测的物体),所以这个python脚本还是很成功的。
txt效果图:

第一个为类别,因为只有一类,以后的为每个锚框的数值
谢谢大家