RNN
一个时序单元的前向传播过程
1)正向传播
rnn的基本结构

在一个时序单元中相当于对本次输入以及上次输出进行线性加权,并用激活函数处理后输出。
2)反向传播
tanh函数求梯度
小知识
“*”运算是将两个向量中每个元素进行相乘,是数乘运算
“np.dot()”和“@”运算都可以起到矩阵乘法的作用
python乘法
矩阵求导转置问题 总结来说就是实际乘法中 涉及矩阵的行列乘法,会引起矩阵的转置
主要算法:BPTT–>此算法的主要思想:最终的损失函数是每个时间节单元求得,所以求最终函数反向传播的计算梯度 对于某一参数关于每个时间节单元求和(最后的损失函数是求和 算来的 为什么 每一步的梯度 不能用每一步的损失来计算?)确实是每步的损失对于每一步求导数 但是不同步的梯度是相加进行组合的,因为一直用的是一个参数
单词的向量编码:单词的向量编码很简单,首先定义 单词个数*单词维度个随机数据 然后指定对应单词 即可得到对应的向量编码
W = np.linspace(0, 1, num=V*D).reshape(V, D)
out = W[x, :] #W包含 V个单词的D维向量表示 将x的对应单词内容输出 得到指定单词的向量表示
#其中 x表示待编码单词 out表示编码结果
RNN计算流程
全连接得到图片分数->单词向量化->计算rnn网络得到的句子->得到对应的分数->计算损失
计算rnn网络得到的句子:单词向量化(用固定大小的向量表示每个不同的单词)
词向量模型表征的是词语与词语之间的距离和联系,词向量也叫词嵌入 word embedding
在不断地训练过程中,算法会发现要想最好地拟合训练集,就要使得一些特性相似的词汇具有相似的特征向量,从而就得到了最后的词嵌入矩阵
LSTM
1、为什么要提出LSTM?
LSTM是一种特殊的RNN 主要是为了解决长序列训练过程中梯度消失和梯度爆炸的问题,相比普通的RNN,LSTM能够在更长的序列中有更好的表现
左边(RNN) 右边(LSTM)
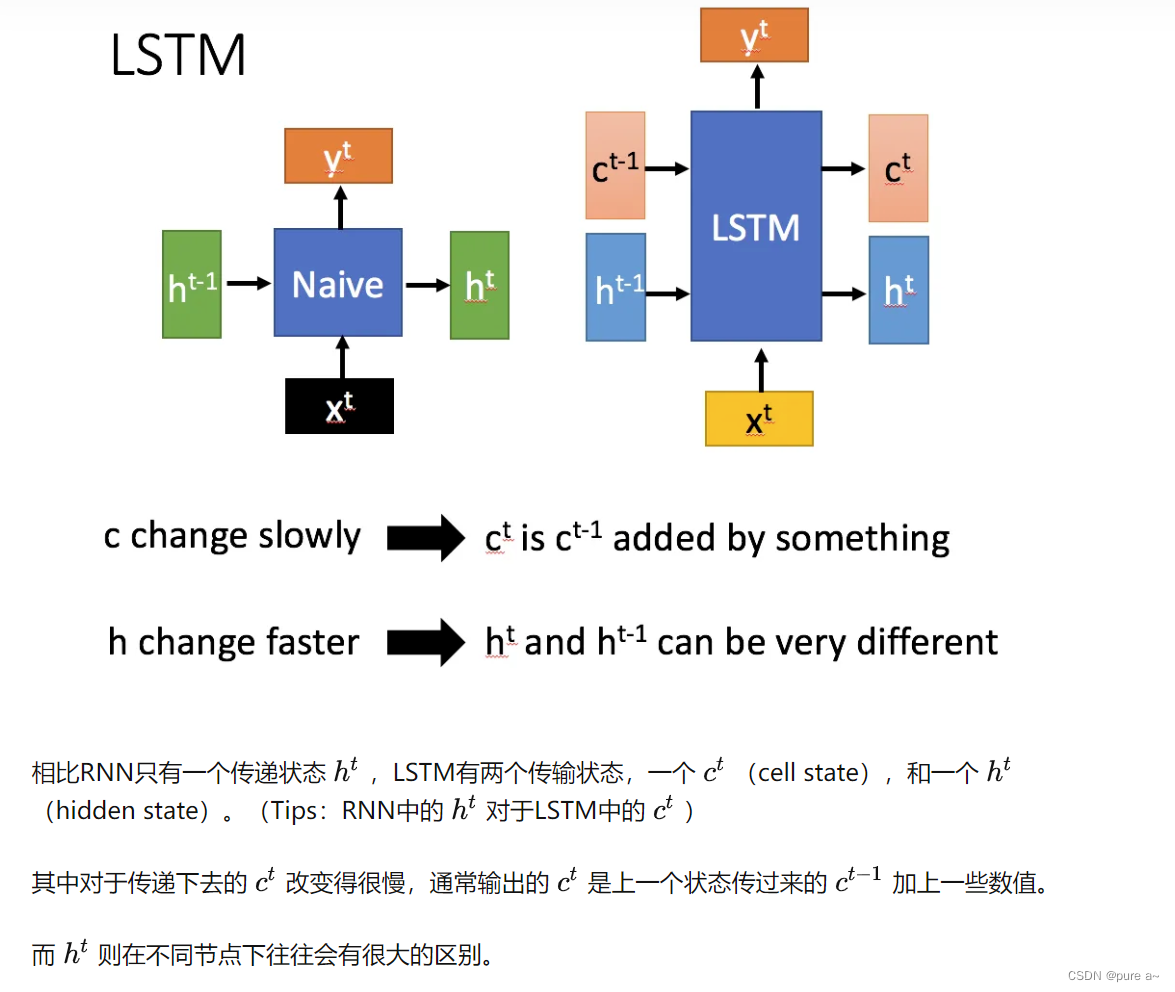
LSTM内部结构
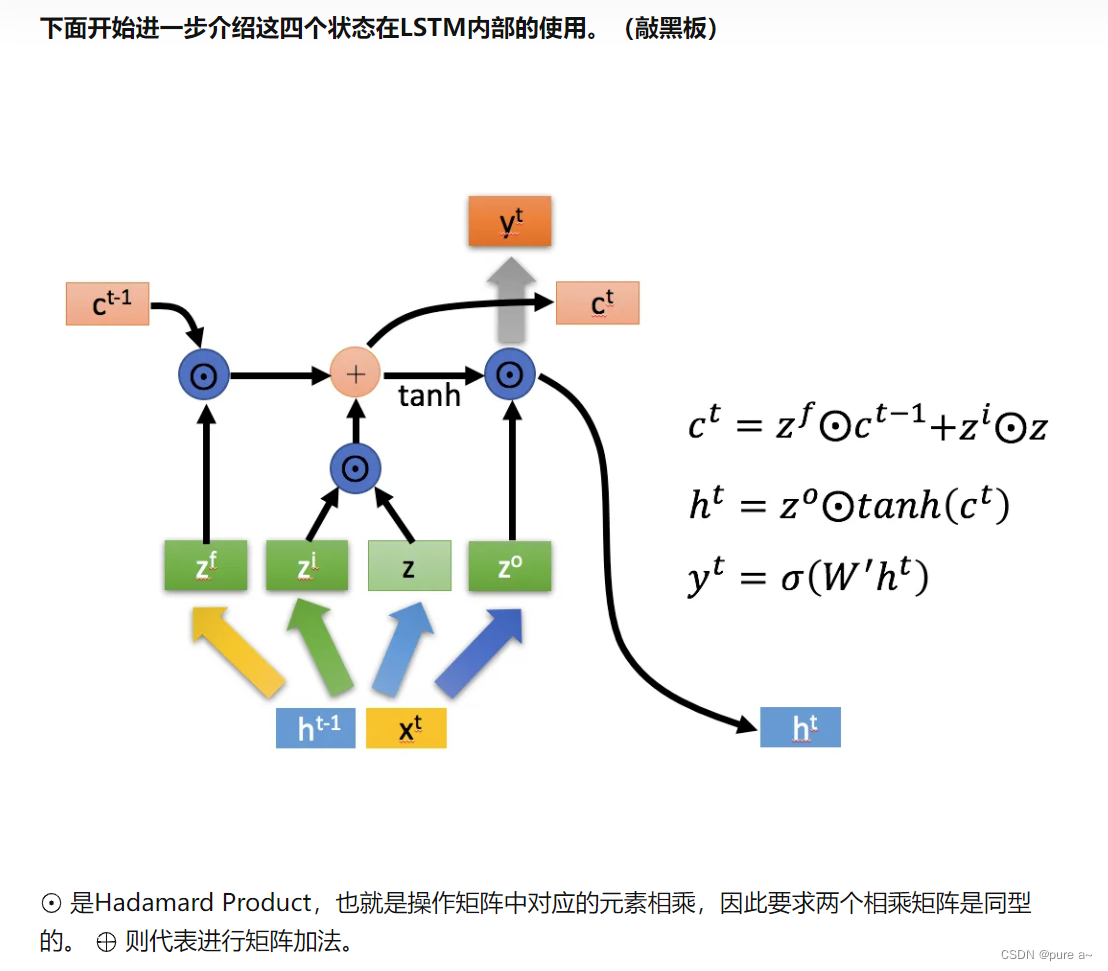
LSTM内部主要有三个阶段
1)忘记阶段,通过Z_f来作为忘记门控,来控制上一个状态c_t-1哪些需要留 哪些需要忘记(对上一个节点传进来的输入进行选择性的忘记-》忘记不重要的,记住重要的)
2)选择记忆阶段,将这个阶段的输入进行有选择的记忆,主要是会对输入x_t进行选择记忆。哪些重要则着重记录下来,哪些不重要,则少记一些。当前的输入内容由前面计算得到的z表示。而选择的门控信号则是由z_i(i代表information)来进行控制。
上面的两个结果相加 得到传输给下一状态的c_t(主要做的事情是选择忘记之前传入内容 选择记忆当前内容)
3)输出阶段:决定了当前哪些状态会被当做当前状态的输出 主要是通过z_0确定
客观评价:LSTM可以通过门控状态来控制传输状态,记住需要长时间记忆的,忘记不重要的信息;相比RNN只有一种记忆叠加的方式 可以更好的处理需要“长期记忆”的任务
但是因为引入了很多内容 导致参数变多 使得训练难度增大。