RNN循环神经网络,在“时间序列”,“可变长序列到序列” 或“在上下文模型”中有着非常广泛的应用。现在论文中说到RNN,基本上说的就是LSTM,同时也有GRU用了比LSTM更少的gate和参数,可以达到类似的效果。
本文主要是介绍RNN,LSTM的原理,及举一个程序的例子来说明如何用TF实现LSTM。
RNN
首先,DNN是输入feature全链接到下一层的神经元,通过一个linear regression加到神经元,神经元上有一个激活函数(通常RNN的激活函数是Sigmod函数,使用ReLU会产生指数爆炸的问题。不过有一篇论文说ReLU训练RNN比LSTM效果还好。CNN用的是ReLU、leaky ReLU、ELU,maxout、tanh),然后输出的feature按照同样的方法堆几层,最后一个softmax输出结果。
其中,DNN是instance(基于实例)的一种MDP(马尔可夫决策过程,即无后效性或无记忆性),只考虑当前状态,不考虑之前的状态。但在具体应用时,会发现在处理有些任务时,具有memory的网络才能够解决问题。比如进行视频行为分析,一个人的手停在半空中,你说他的手是要往上还是往下?只有结合之前的视频才能够更有效做出判断。所以,给神经网络以记忆。
所以,RNN就把前一个输出的hinding layer或output保存起来,在下一次输入时,把上一次保存的值输入进来。如下图所示:所以上一次的输出或hinding layer,会影响下一次的输出,同时会更新存储的值。

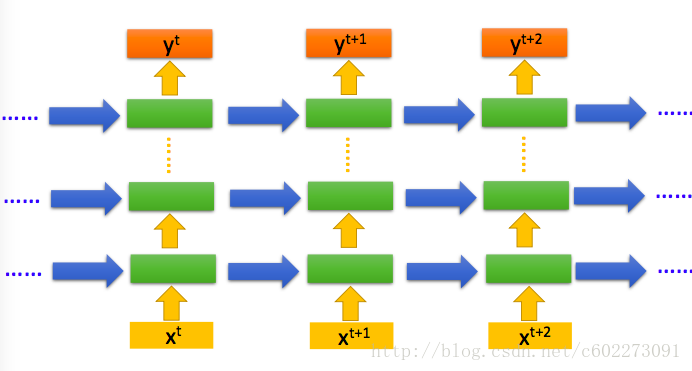
当然,RNN可以有多个隐层,如下图:不要看它是有这么多,其实它就是一个网络,表示的是不同的时刻。
同理CPU的流水线,每过一个时刻,各个寄存器的状态就会更新,这里的寄存器就是memory,蓝色的箭头。
RNN的网络结构还有下图,其实总结起来就是要保存memory,但是这里的RNN一般会保存上一个状态的memory,通俗来说就是它只有上一个时刻的记忆。
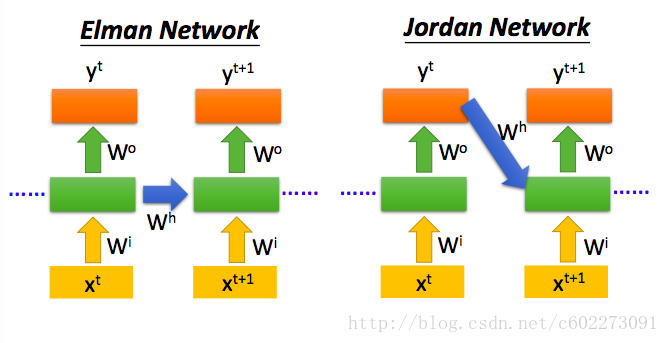
这里的双向的RNN训练时,比如训练一个sentence auto-encoder,下面的训练的输入时正向的,上面的输入正好和下面的sentence顺序相反,为什么要这么训练呢?我觉得这样的话就使得这个RNN有了prediction的功能。
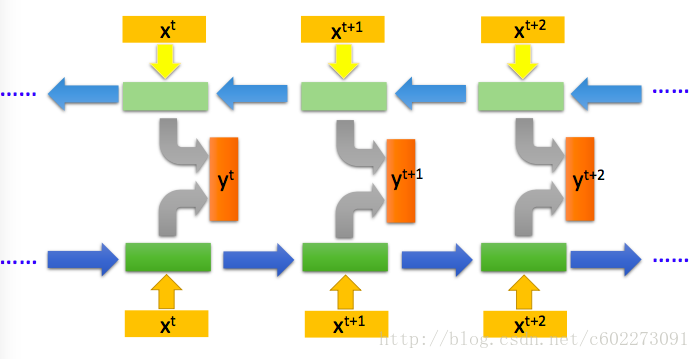
其实熟悉DNN的话,其实就是在DNN的基础上加入了memory这个东西,同时把memory作为input。但是在training的时候就有了不少技巧。
RNN在训练的时候,会有gradient vanishing和gradient explode的情况。一个是指数爆炸,一个是后向传递的时候参数接近于0,权值没有被更新。使用LSTM可以解决gradient vanishing的问题,因为memory和input操作都是加法。【7】【8】在RNN的作者训练RNN的时候,增加了一个叫做Clipping的操作,将梯度限制在一定的范围内,不让它超过一定的范围。
LSTM
LSTM图例如下 :
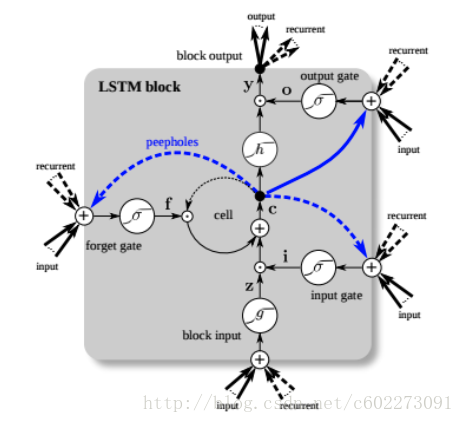
这里先来把整个框架画出来:在输入的地方有一个input gate,来判断输入是否有效。gate打开输入才会进入memory cell。在与memory gate相连的有一个Forget gate,这里的作用是,判断是否把memory置为0,置为0就是Forget。然后有一个输出Gate,是否对外进行输出。这些gate的开关都是由神经网络决定的(其实就是由输入的feature进行了一个linear regression,再输入到Gate function,某种激活函数,Sigmoid)。
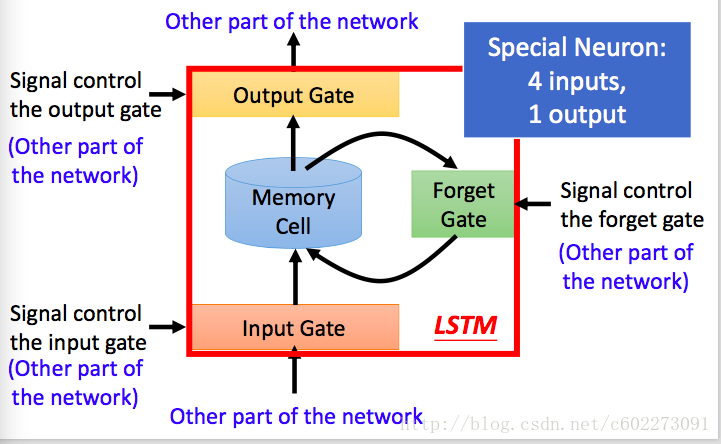
下图中对memory cell进行了详细的解释:zizi,zz,zfzf,zozo是四个gate,由input feature经过linear regression得到。输入的z通过activation function之后变成了g(z),然后这个g(z)和f(zi)相乘送进了memory cell,得到新的memory:这里面的c就是memory,f(zf)如果是0,那么Forget Gate启动,memory被清空。否则就保留memory。输出的a受到output gate的控制。 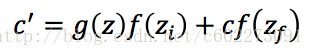
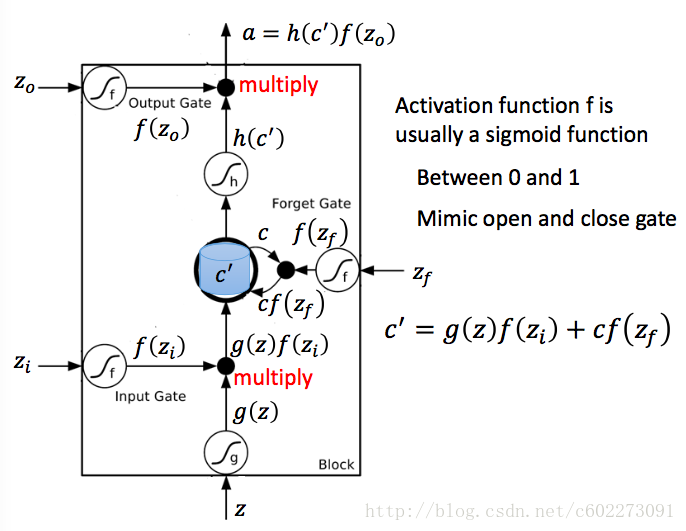
其实通过对比就会发现,LSTM和CNN很像,因为每个gate的input feature也是从最原始的输入通过linear regression这种线性变化来的。
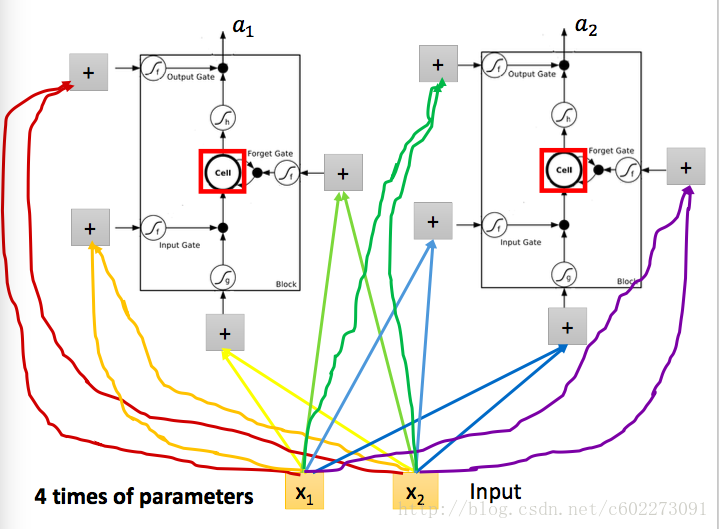
当然实际在计算的时候输入的不仅仅是有input feature,还有memory,还有memory的输出。

Example
目前RNN的应用:
- sentiment anlysis 情感分析:输入一个序列,输出的是情感,比如对某部电影的评价。
- speech recognition:输入原始的声音信号,输出的是识别的文字。声音被分成了多个片段,然后每个片段对应一个字,其中有一个null的字,表示什么都没有。
- machine translation:进行机器翻译,首先是输入sequence,然后输入结束后输出,有终止符表示停止了。
- syntactic parsing:对一句话进行语法组织。
- sequence-to-sequence Auto-Encoder:输入一句话,然后进行encode,再decoder,把整句话恢复回来。用这样的方法,可以获取它的sequence feature,接着可以用来做匹配。如果是声音,就可以进行声音的匹配,不过这里匹配出来的是语义上的联系。用这个方法就可以从语料库里面选出语义类似的片段,进行可以得出文本。这里面可以看到有两个部分,一个部分是LSTM Encoder,一个是LSTM的Decoder,使用Encoder输入input sequence,LSTM的Decoder就是输出回答,那么就是所谓的问答系统。非常神奇~
- image caption generation:输入图片,输出描述的话。
- Attention-based model:(Neural Turing Machine)会把各种资源表示成feature vector存储在memory之中。然后会训练一个RNN从memory中选择合适的项目,然后整合输出。
- Reading Comprehension:给题目,然后一堆选项,需要找到合适的选项,这些都是可以用LSTM进行训练。
- Visual Question Answering:比如给你一副图片,然后提问题,这个人穿什么颜色的衣服?然后会回答:xxx
- speech Question Answering:比如托福的听力材料。
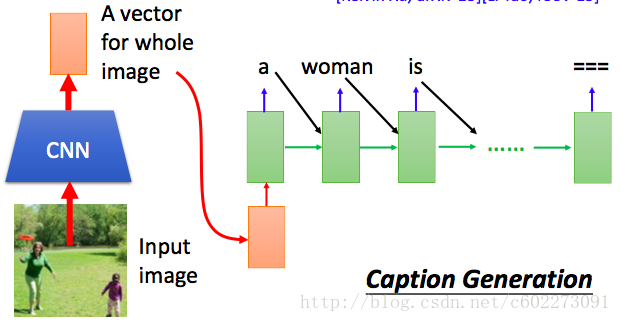
Attention Model:以前的冯诺依曼机架构在人工智能领域已经是下面的model。

example:首先,进行数据预处理,把每个词进行word2vec(或叫做word embedding),每个输入的embedding layer通过LSTM之后,就会获得整个句子的feature vector,通过一个DNN就可以得出这句话是Negative或是Positive的。其中,还有一种Vector h表示方法就是bag of words,把文本每个词进行切割,得到每个词的个数,得到一句话的vector。
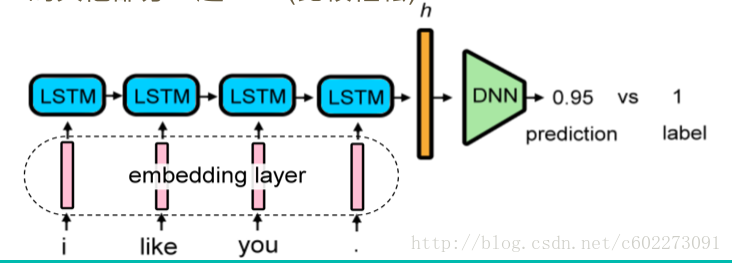
在数据中还有没有标记的数据,可以使用EM算法,KNN等等进行标记。这里提供的是使用已经标记好的数据训练的模型对未标记的数据进行标记。
首先创建一个utils目录,理由有一个util.py。对数据进行预处理,构建vocabulary等。
import os
import tensorflow as tf
import numpy as np
from keras.preprocessing.text import Tokenizer
from keras.preprocessing.sequence import pad_sequences
from keras.utils import to_categorical
import _pickle as pk
# calss to address the data.
class DataManager:
def __init__(self):
self.data = {}
def add_data(self,name,data_path,with_label=True):
print('read data from %s ...' % data_path)
X, Y = [], []
with open(data_path, 'r') as f:
for line in f:
if with_label:
lines = line.strip().split(' +++$+++ ')
X.append(lines[1])
Y.append(int(lines[0]))
else:
X.append(line)
if with_label:
self.data[name] = [X,Y]
else:
self.data[name] = [X]
def tokenize(self, vocab_size):
print('Create new tokenizer')
self.tokenizer = Tokenizer(num_words=vocab_size)
for key in self.data:
print('Tokenizing %s' %key)
texts = self.data[key][0]
self.tokenizer.fit_on_texts(texts)
def save_tokenizer(self, path):
print('Save tokenizer to %s' % path)
pk.dump(self.tokenizer, open(path, 'wb'))
def load_tokenizer(self, path):
print('Load tokenizer from %s' % path)
self.tokenizer = pk.load(open(path, 'rb'))
def to_sequence(self, maxlen):
self.maxlen = maxlen
for key in self.data:
print('Converting %s to sequence ' % key)
tmp = self.tokenizer.texts_to_sequences(self.data[key][0])
self.data[key][0] = np.array(pad_sequences(tmp, maxlen=maxlen))
def to_bow(self):
for key in self.data:
print ('Converting %s to tfidf'%key)
self.data[key][0] = self.tokenizer.texts_to_matrix(self.data[key][0],mode='count')
# Convert label to category type, call this function if use categorical loss
def to_category(self):
for key in self.data:
if len(self.data[key]) == 2:
self.data[key][1] = np.array(to_categorical(self.data[key][1]))
def get_semi_data(self,name,label,threshold,loss_function) :
# if th==0.3, will pick label>0.7 and label<0.3
label = np.squeeze(label)
index = (label>1-threshold) + (label<threshold)
semi_X = self.data[name][0]
semi_Y = np.greater(label, 0.5).astype(np.int32)
if loss_function=='binary_crossentropy':
return semi_X[index,:], semi_Y[index]
elif loss_function=='categorical_crossentropy':
return semi_X[index,:], to_categorical(semi_Y[index])
else :
raise Exception('Unknown loss function : %s'%loss_function)
def get_data(self,name):
return self.data[name]
# split data to two part by a specified ratio
# name : string, same as add_data
# ratio : float, ratio to split
def split_data(self, name, ratio):
data = self.data[name]
X = data[0]
Y = data[1]
data_size = len(X)
val_size = int(data_size * ratio)
return (X[val_size:],Y[val_size:]),(X[:val_size],Y[:val_size])主函数 main.py 如下:
import sys, argparse, os
import keras
import _pickle as pk
import readline
import numpy as np
from keras import regularizers
from keras.models import Model
from keras.layers import Input, GRU, LSTM, Dense, Dropout, Bidirectional
from keras.layers.embeddings import Embedding
from keras.optimizers import Adam
from keras.callbacks import EarlyStopping, ModelCheckpoint
import keras.backend.tensorflow_backend as K
import tensorflow as tf
from utils.util import DataManager
parser = argparse.ArgumentParser(description='Sentiment classification')
parser.add_argument('model')
parser.add_argument('action', choices=['train','test','semi'])
# training argument
parser.add_argument('--batch_size', default=128, type=float)
parser.add_argument('--nb_epoch', default=20, type=int)
parser.add_argument('--val_ratio', default=0.1, type=float)
parser.add_argument('--gpu_fraction', default=0.3, type=float)
parser.add_argument('--vocab_size', default=20000, type=int)
parser.add_argument('--max_length', default=40,type=int)
# model parameter
parser.add_argument('--loss_function', default='binary_crossentropy')
parser.add_argument('--cell', default='LSTM', choices=['LSTM','GRU'])
parser.add_argument('-emb_dim', '--embedding_dim', default=128, type=int)
parser.add_argument('-hid_siz', '--hidden_size', default=512, type=int)
parser.add_argument('--dropout_rate', default=0.3, type=float)
parser.add_argument('-lr','--learning_rate', default=0.001,type=float)
parser.add_argument('--threshold', default=0.1,type=float)
# output path for your prediction
parser.add_argument('--result_path', default='result.csv',)
# put model in the same directory
parser.add_argument('--load_model', default = None)
parser.add_argument('--save_dir', default = 'model/')
args = parser.parse_args()
train_path = 'data/training_label.txt'
test_path = 'data/testing_data.txt'
semi_path = 'data/training_nolabel.txt'
def simpleRNN(args):
inputs = Input(shape=(args.max_length,))
# Embedding layer
embedding_inputs = Embedding(args.vocab_size,
args.embedding_dim,
trainable=True)(inputs)
# RNN
return_sequence = False
dropout_rate = args.dropout_rate
if args.cell == 'GRU':
RNN_cell = GRU(args.hidden_size,
return_sequences=return_sequence,
dropout=dropout_rate)
elif args.cell == 'LSTM':
RNN_cell = LSTM(args.hidden_size,
return_sequences=return_sequence,
dropout=dropout_rate)
RNN_output = RNN_cell(embedding_inputs)
# DNN layer
outputs = Dense(args.hidden_size//2,
activation='relu',
kernel_regularizer=regularizers.l2(0.1))(RNN_output)
outputs = Dropout(dropout_rate)(outputs)
outputs = Dense(1, activation='sigmoid')(outputs)
model = Model(inputs=inputs,outputs=outputs)
# optimizer
adam = Adam()
print ('compile model...')
# compile model
model.compile( loss=args.loss_function, optimizer=adam, metrics=[ 'accuracy',])
return model
def main():
# limit gpu memory usage
def get_session(gpu_fraction):
gpu_options = tf.GPUOptions(per_process_gpu_memory_fraction=gpu_fraction)
return tf.Session(config=tf.ConfigProto(gpu_options=gpu_options))
K.set_session(get_session(args.gpu_fraction))
save_path = os.path.join(args.save_dir,args.model)
if args.load_model is not None:
load_path = os.path.join(args.save_dir,args.load_model)
### process data###
#####read data#####
dm = DataManager()
print ('Loading data...')
if args.action == 'train':
dm.add_data('train_data', train_path, True)
elif args.action == 'semi':
dm.add_data('train_data', train_path, True)
dm.add_data('semi_data', semi_path, False)
else:
raise Exception ('Implement your testing parser')
# prepare tokenizer
print ('get Tokenizer...')
if args.load_model is not None:
# read exist tokenizer
dm.load_tokenizer(os.path.join(load_path,'token.pk'))
else:
# create tokenizer on new data
dm.tokenize(args.vocab_size)
if not os.path.isdir(save_path):
os.makedirs(save_path)
if not os.path.exists(os.path.join(save_path,'token.pk')):
dm.save_tokenizer(os.path.join(save_path,'token.pk'))
# convert to sequences
dm.to_sequence(args.max_length)
# initial model
print ('initial model...')
model = simpleRNN(args)
print (model.summary())
if args.load_model is not None:
if args.action == 'train':
print ('Warning : load a exist model and keep training')
path = os.path.join(load_path,'model.h5')
if os.path.exists(path):
print ('load model from %s' % path)
model.load_weights(path)
else:
raise ValueError("Can't find the file %s" %path)
elif args.action == 'test':
print ('Warning : testing without loading any model')
# training
if args.action == 'train':
(X,Y),(X_val,Y_val) = dm.split_data('train_data', args.val_ratio)
earlystopping = EarlyStopping(monitor='val_acc', patience = 3, verbose=1, mode='max')
save_path = os.path.join(save_path,'model.h5')
checkpoint = ModelCheckpoint(filepath=save_path,
verbose=1,
save_best_only=True,
save_weights_only=True,
monitor='val_acc',
mode='max' )
history = model.fit(X, Y,
validation_data=(X_val, Y_val),
epochs=args.nb_epoch,
batch_size=args.batch_size,
callbacks=[checkpoint, earlystopping] )
# testing
elif args.action == 'test' :
raise Exception ('Implement your testing function')
# semi-supervised training
elif args.action == 'semi':
(X,Y),(X_val,Y_val) = dm.split_data('train_data', args.val_ratio)
[semi_all_X] = dm.get_data('semi_data')
earlystopping = EarlyStopping(monitor='val_acc', patience = 3, verbose=1, mode='max')
save_path = os.path.join(save_path,'model.h5')
checkpoint = ModelCheckpoint(filepath=save_path,
verbose=1,
save_best_only=True,
save_weights_only=True,
monitor='val_acc',
mode='max' )
# repeat 10 times
for i in range(10):
# label the semi-data
semi_pred = model.predict(semi_all_X, batch_size=1024, verbose=True)
semi_X, semi_Y = dm.get_semi_data('semi_data', semi_pred, args.threshold, args.loss_function)
semi_X = np.concatenate((semi_X, X))
semi_Y = np.concatenate((semi_Y, Y))
print ('-- iteration %d semi_data size: %d' %(i+1,len(semi_X)))
# train
history = model.fit(semi_X, semi_Y,
validation_data=(X_val, Y_val),
epochs=2,
batch_size=args.batch_size,
callbacks=[checkpoint, earlystopping] )
if os.path.exists(save_path):
print ('load model from %s' % save_path)
model.load_weights(save_path)
else:
raise ValueError("Can't find the file %s" %path)
if __name__ == '__main__':
main() 如果是训练模型,那就是:python main.py train –cell LSTM
如果加入semi-supervised learning,那就是:python main.py semi –load_model
来源: http://blog.csdn.net/c602273091/article/details/78940207
Ref Links:
【1】CMU 10707: https://www.cs.cmu.edu/~rsalakhu/10707/
【2】kaggle 比赛: https://www.kaggle.com/c/ml-2017fall-hw4/data
【3】RNN,LSTM: https://www.youtube.com/watch?v=WCUNPb-5EYI
【4】RNN,LSTM:http://speech.ee.ntu.edu.tw/~tlkagk/courses/ML_2016/Lecture/RNN%20(v2).pdf
【5】极好的博客: http://colah.github.io/posts/2015-08-Understanding-LSTMs/
【6】对LSTM的解释: https://deeplearning4j.org/lstm.html
【7】Gradient vanishing: http://www.wildml.com/2015/10/recurrent-neural-networks-tutorial-part-3-backpropagation-through-time-and-vanishing-gradients/
【8】Gradient Exploding: https://www.quora.com/How-does-LSTM-help-prevent-the-vanishing-and-exploding-gradient-problem-in-a-recurrent-neural-network
【9】MNIST RNN: https://www.youtube.com/watch?v=IASyrQamTQk
【10】RNN Code: https://github.com/MorvanZhou/tutorials/tree/master/tensorflowTUT/tf20_RNN2