RNN是对时间序列数据的一种预测算法,被大量用于金融市场估计、视频序列处理、行为预测等课题中。说起来复杂,实际上和普通的一维神经网络没什么区别,还是权重偏执那一套。那么怎么将上个时间中的知识传下去呢?RNN中有个状态变量(cell state),上一时间的状态变量和输入数据一起,共同组成本次时间的输入。
常用的RNN结构有LSTM(Long Short-Term Memory, 长短期记忆网络)和GRU(Gated recurrent units ,开关循环单元)。下面通过图片简单对比一下两者的结构:
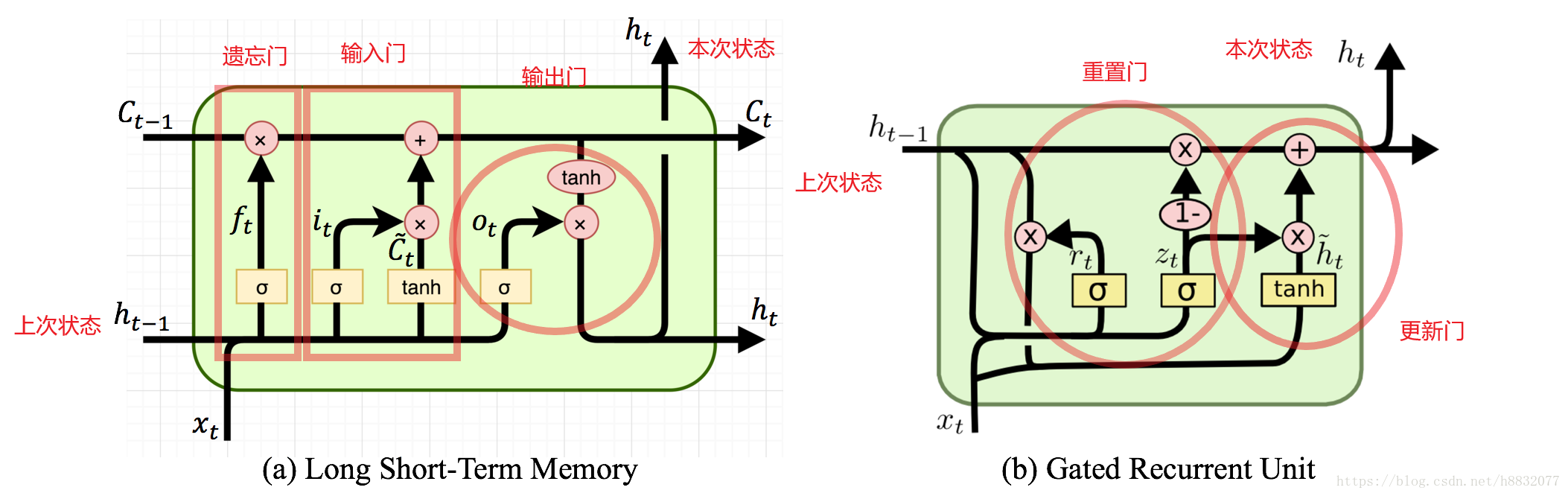
LSTM由三个部分组成:遗忘门,控制哪些部分保留,哪些部分舍弃;输入门,sigmoid这条线负责选择更新的信息,tanh这条线负责添加新候选信息;输出门,控制哪些部分被输出。
GRU由两部分组成:重置门,将输入与之前的状态结合起来;更新门,多少的输入和状态被保留。
如果觉得上图比较复杂,可以参考这个网址。
LSTM原理
LSTM数学原理
1.输入门
2.遗忘门
3.输出门
4.候选
5.输出
其中,
表示激活函数,
表示矩阵乘法。
可以看到,1、2、3的公式是一样的,只是内部的权重换了一下而已。
LSTM的tensorflow实现
Tensorflow实现LSTM非常简单,一共只要3句话。
#创建rnn类
cell = tf.nn.rnn_cell.LSTMCell(10)
#初始化状态0
state = cell.zero_state(batchsize, tf.float32)
#创建网络
output, state = tf.nn.static_rnn(cell, [tinputs], initial_state=state, dtype=tf.float32)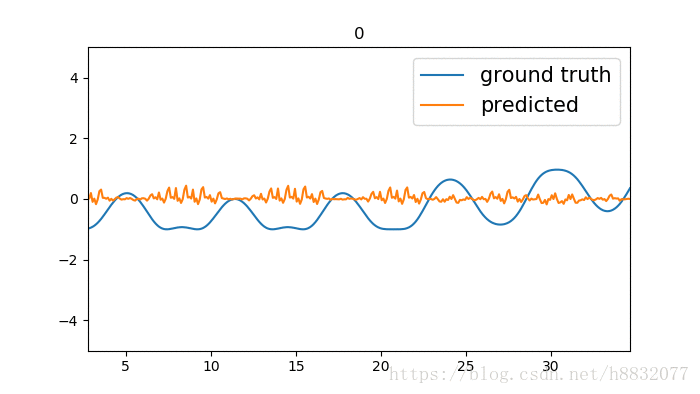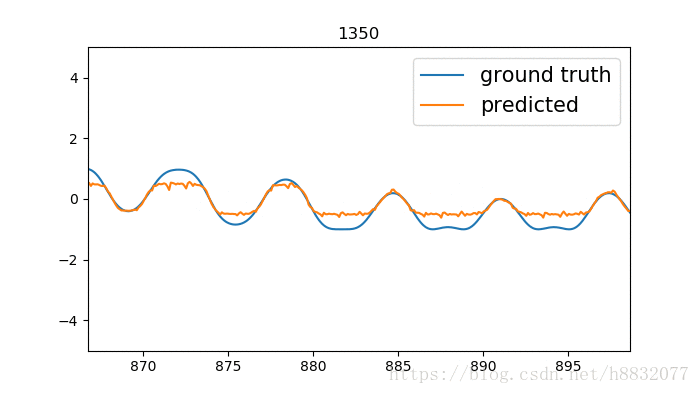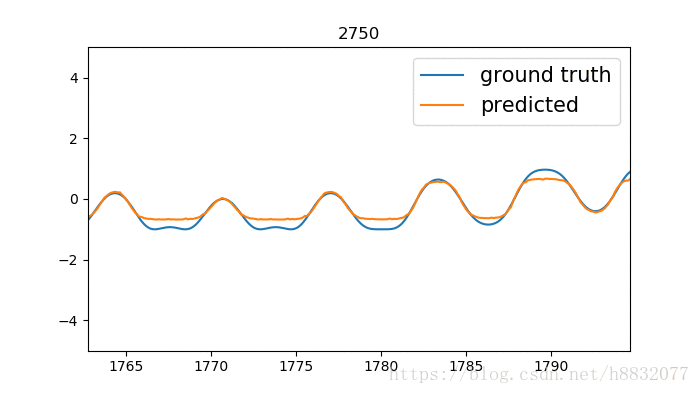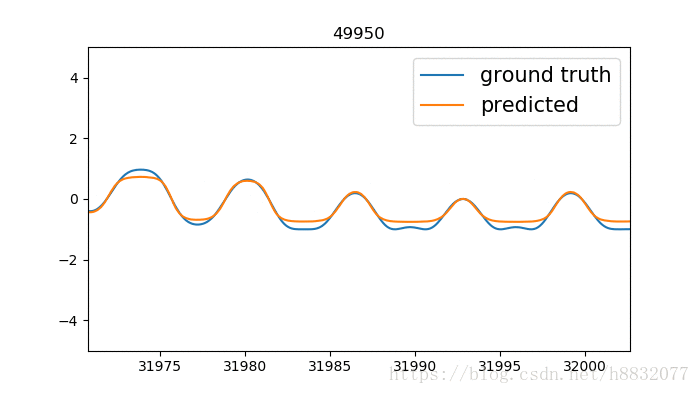
标题为训练次数,蓝色的线是我们模拟的时间序列函数,橙色的线是预测结果。
LSTM简单实现
下面,我们自己写一个LSTM试一试。根据我们上面的公式,简单的LSTM实现如下:
class RNN:
def __init__(self, batchsize, length):
self.batchsize = batchsize
self.outputshape = length
def _input_add_state(self, input, state, active_fn=tf.nn.tanh, name=None):
inputshape = input.get_shape().as_list()
with tf.variable_scope(name):
u = tf.get_variable(name='U', initializer=tf.random_uniform((inputshape[-1], self.outputshape)))
w = tf.get_variable(name='W', initializer=tf.random_uniform((self.outputshape, self.outputshape)))
b = tf.get_variable(name='B', initializer=tf.random_uniform((inputshape[0], self.outputshape)))
return active_fn(tf.matmul(input, w) + tf.matmul(state, u) + b)
class LSTM(RNN):
def __init__(self, batchsize, length):
super().__init__(batchsize, length)
self.hidden = tf.Variable(tf.zeros((self.batchsize, self.outputshape)),trainable=False)
self.candidate = tf.Variable(tf.random_uniform((self.batchsize, self.outputshape)),trainable=False)
def build(self, inputs, reuse=False):
with tf.variable_scope('LSTM', reuse=reuse):
forget = self._input_add_state(inputs, self.hidden, name='forget')
inputgate = self._input_add_state(inputs, self.hidden, name='inputgate')
output = self._input_add_state(inputs, self.hidden, name='output')
self.candidate = tf.multiply(forget, self.candidate) + tf.multiply(inputgate,
self._input_add_state(inputs, self.hidden,
tf.nn.tanh,
name='candi'))
self.hidden = tf.multiply(output, self.candidate)
return self.hidden我们首先写了一个基类,用于实现门的公式,剩下的就是实现公式了。tensorflow内部实际上把4个U和4个W纵向合为一个矩阵了。所以你使用tensorflow实现时,会发现只有2个trainable variable。而我们使用的是最简单易读的实现,所以可训练参数共12个:4个w,4个u,4个b。
效果如下:
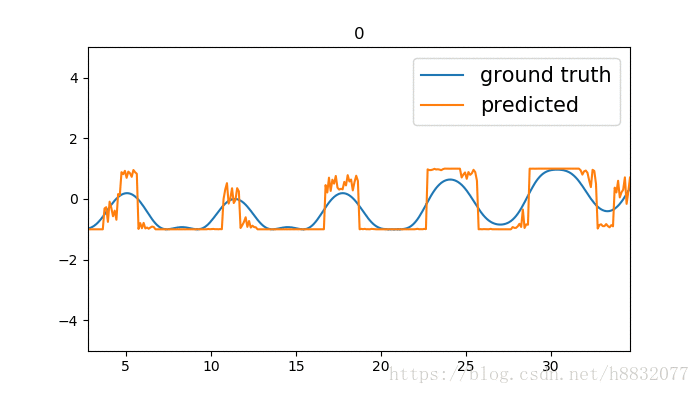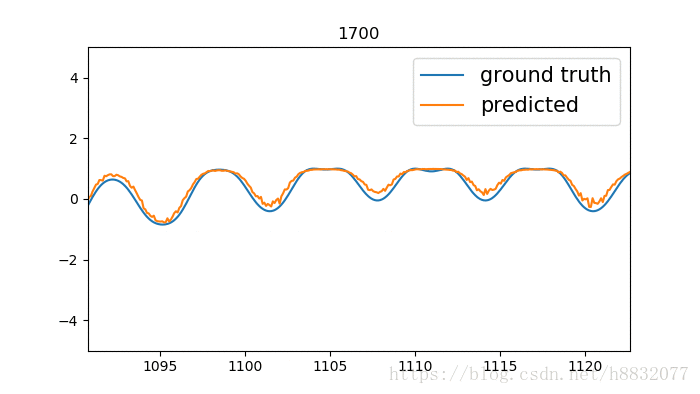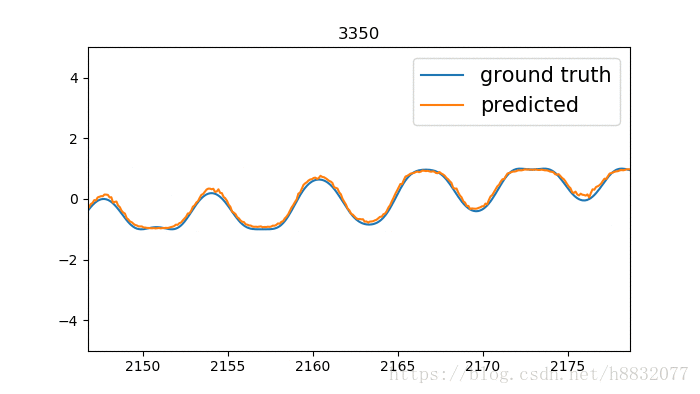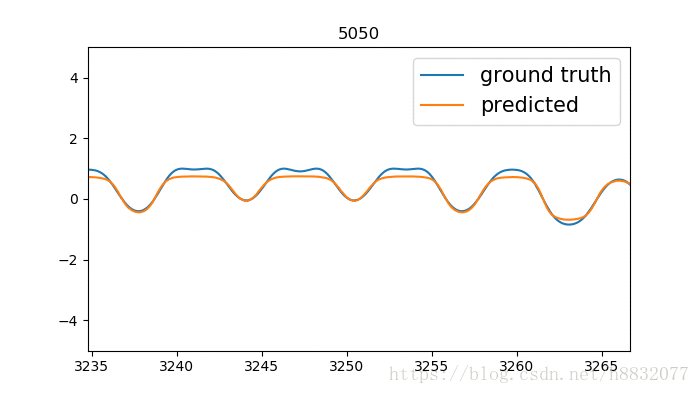
标题为训练次数,蓝色的线是我们模拟的时间序列函数,橙色的线是预测结果。我们实现的LSTM效果要优于tensorflow,为什么呢?因为LSTM的激活函数默认为tanh,这个函数只会输出(-1,1)间的数,相当于人为截断,将tensorflow实现的代码改为
cell = tf.nn.rnn_cell.LSTMCell(10,activation=lambda x:x)那么得到的结果就比较好了,如下:
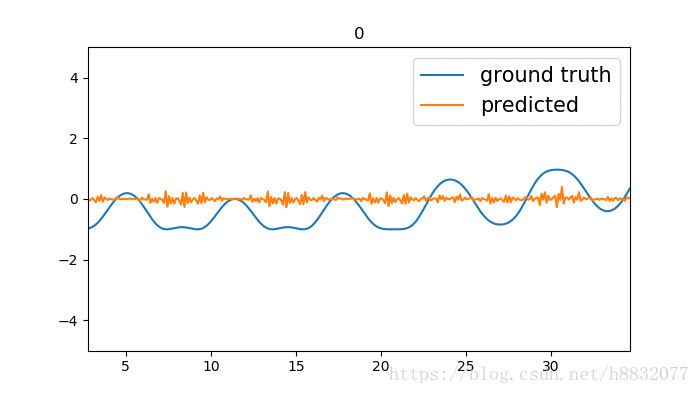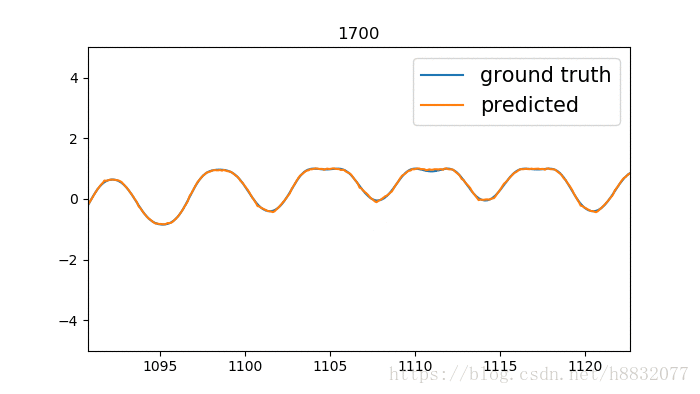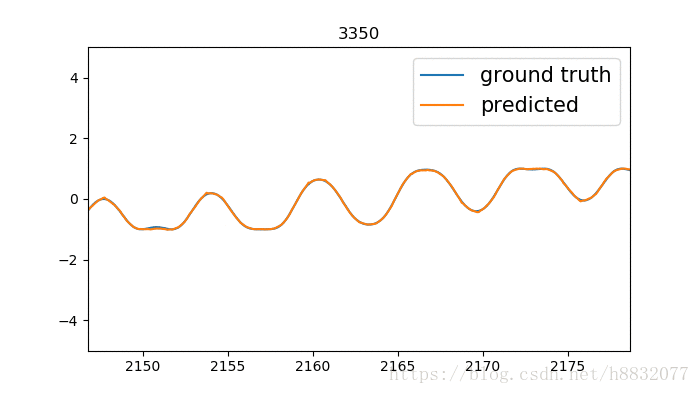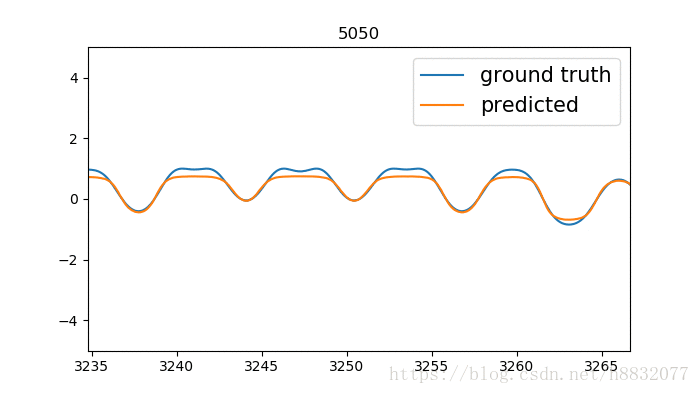
以上代码及数据生成方式请参照我的GIT,使用时请注意选择分支。
GRU原理
GRU数学原理
1.更新门
2.重置门
3.输出
其中,
表示激活函数,
表示矩阵乘法。
比起LSTM少了一个门,参数规模小1/4。
REF
GRU的tensorflow实现
还是3行代码,就是这么简洁。
cell = tf.nn.rnn_cell.GRUCell(10, activation=lambda x: x)
state = cell.zero_state(batchsize, tf.float32)
output, state = tf.nn.static_rnn(cell, [tinputs], initial_state=state, dtype=tf.float32)效果:
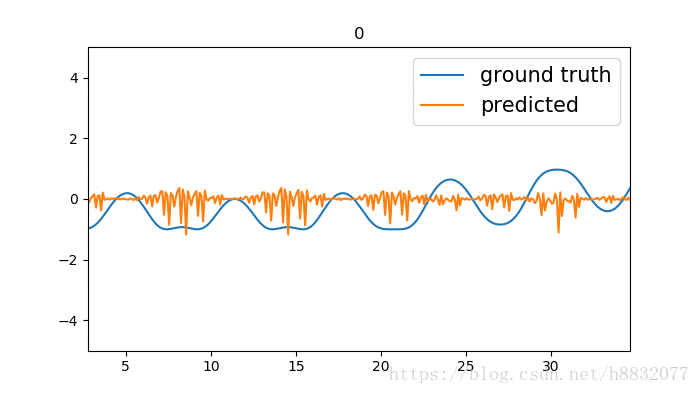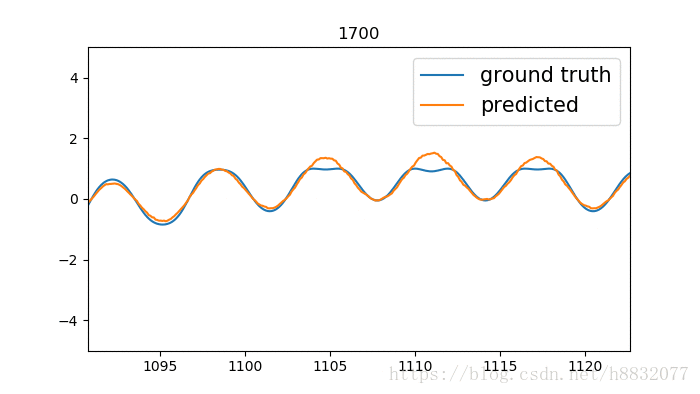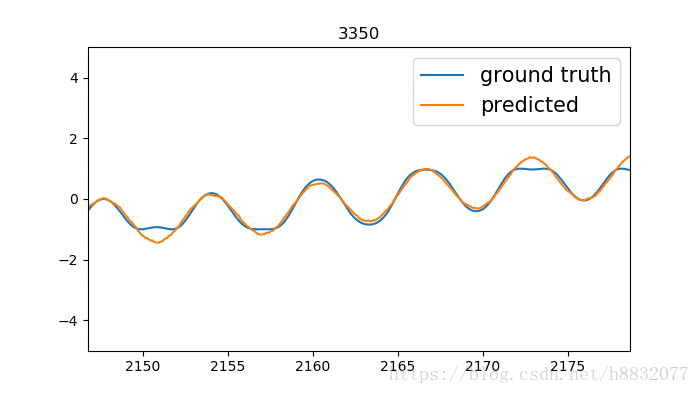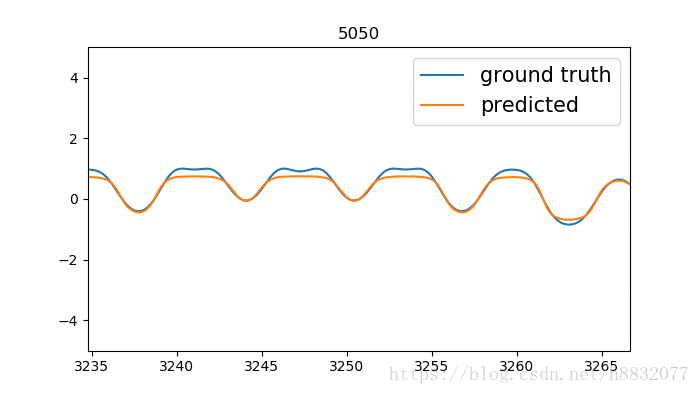
毕竟少了一个门,拟合不了一些凹的地方。
GRU简单实现
卷起袖子再来写一遍。之前我们写的基类又能派上用场了,如下:
class RNN:
def __init__(self, batchsize, length):
self.batchsize = batchsize
self.outputshape = length
def _input_add_state(self, input, state, active_fn=tf.nn.tanh, name=None):
inputshape = input.get_shape().as_list()
with tf.variable_scope(name):
u = tf.get_variable(name='U', initializer=tf.random_uniform((inputshape[-1], self.outputshape)))
w = tf.get_variable(name='W', initializer=tf.random_uniform((self.outputshape, self.outputshape)))
b = tf.get_variable(name='B', initializer=tf.random_uniform((inputshape[0], self.outputshape)))
return active_fn(tf.matmul(input, w) + tf.matmul(state, u) + b)
class GRU(RNN):
def __init__(self, batchsize, length):
super().__init__(batchsize, length)
self.hidden = tf.Variable(tf.zeros((self.batchsize, self.outputshape)), trainable=False)
self.candidate = tf.Variable(tf.random_uniform((self.batchsize, self.outputshape)), trainable=False)
def build(self, inputs, reuse=False):
with tf.variable_scope('GRU', reuse=reuse):
update = self._input_add_state(inputs, self.hidden, name='update')
reset = self._input_add_state(inputs, self.hidden, name='reset')
self.hidden = tf.multiply(1 - update, self.hidden) + \
tf.multiply(update,
self._input_add_state(inputs, tf.multiply(reset, self.hidden), name='candidate'))
return self.hidden效果如下
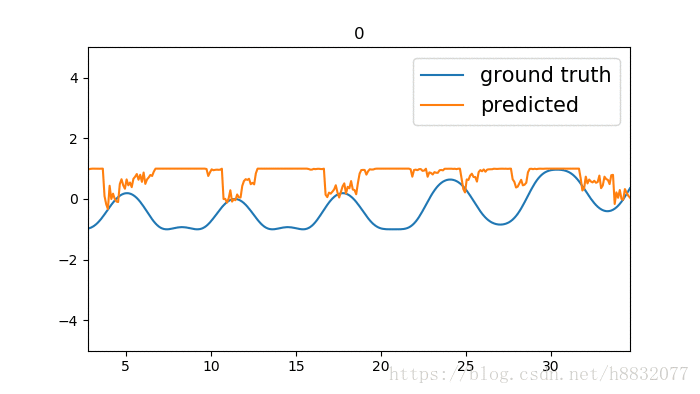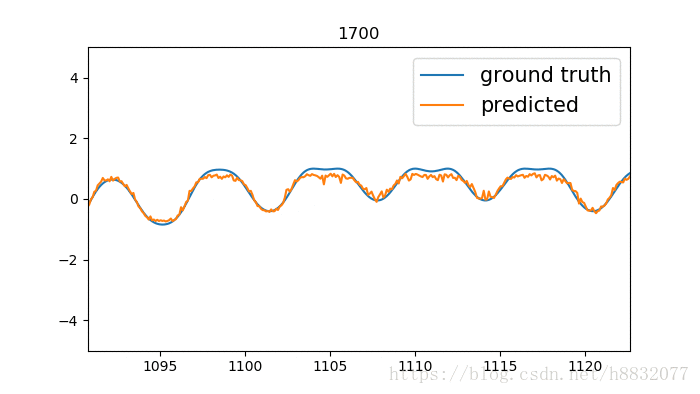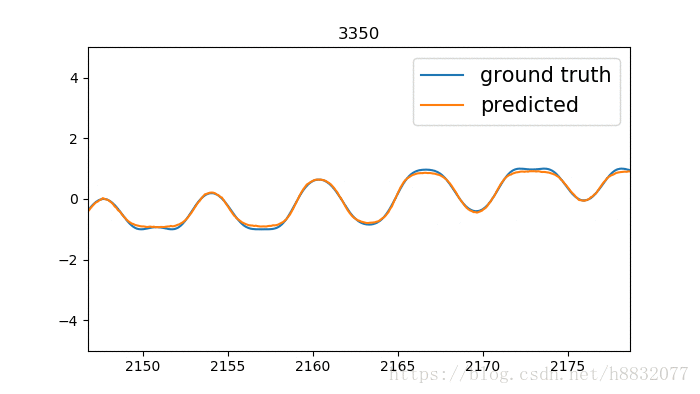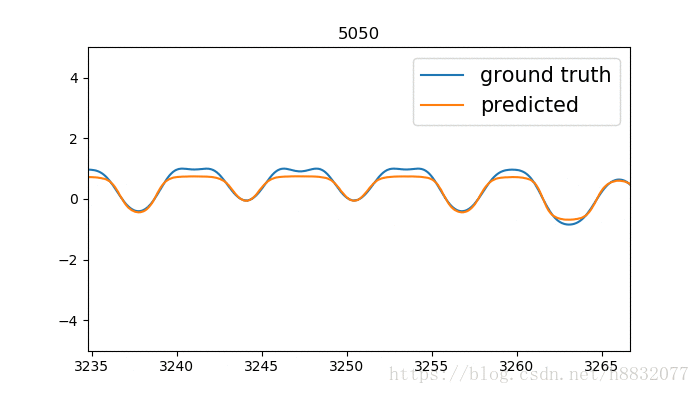
拟合凹的地方还是有点问题,又比tensorflow自带的效果要好一点,什么鬼,看来代码还是要自己写一遍靠谱。寻找和tensorflow不一样的地方,发现tensorflow里激活函数固定为sigmoid:
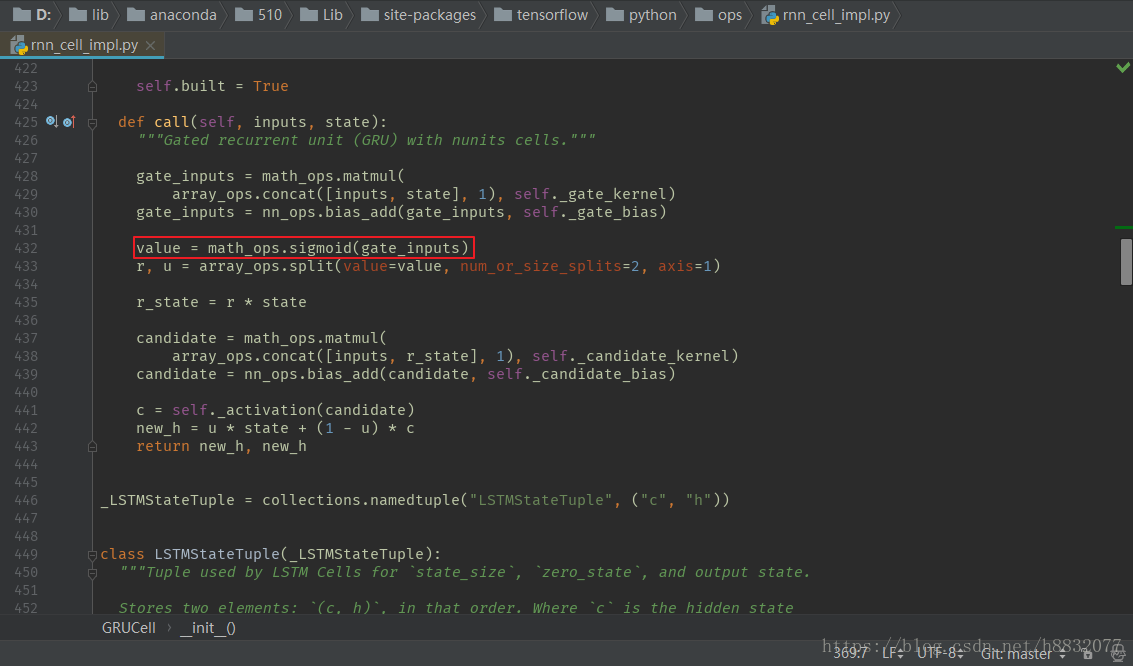
改为tanh,效果和我自己实现的差不多,如下:
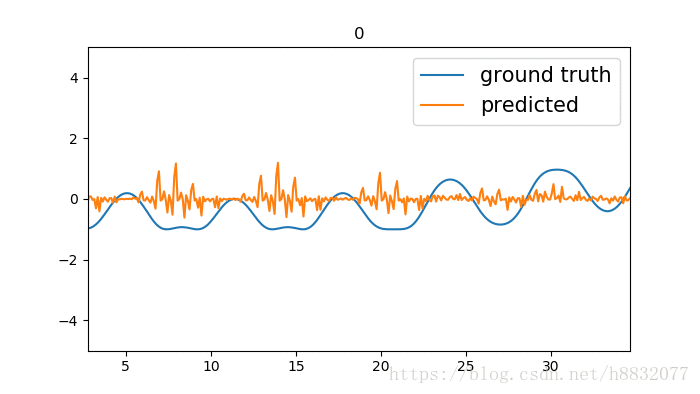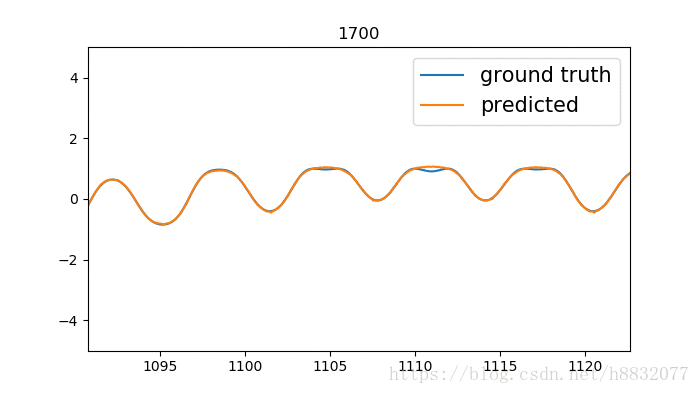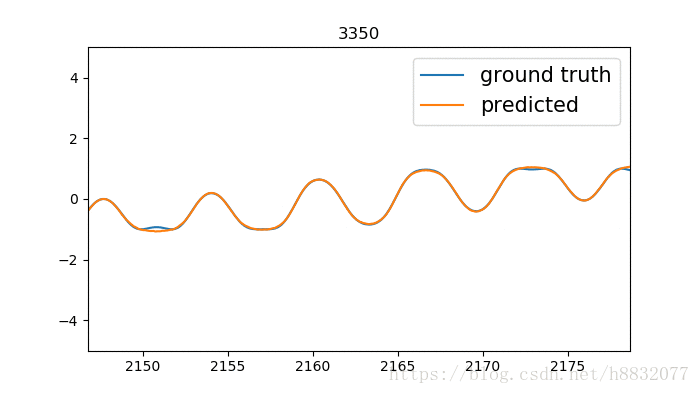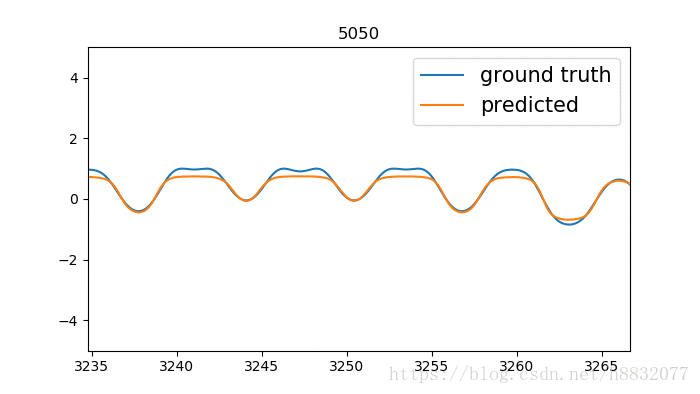
心累,有空的小伙伴可以去官方merge一下,将激活函数改为可变的。
以上代码及数据生成方式请参照我的GIT,使用时请注意选择对应分支。
上面的例子可以看到,LSTM和GRU的效果差不多,对于某些凹的地方,多一个门的LSTM表现更好一点。所以RNN也不是万能的,如果时间序列足够复杂无规律,像中国股市那样,我估计是预测得不好;但是如果稍微有规律的数据,RNN还是能做到有效预测。
最后,祝您身体健康,再见!