推荐资料
- wiki:Long short-term memory
- 简书:[译] 理解 LSTM 网络
- Essentials of Deep Learning : Introduction to Long Short Term Memory
- deeplearning4j: A Beginner’s Guide to Recurrent Networks and LSTMs
- paper:Learning to Forget: Continual Prediction with LSTM
个人的一些理解
LSTM结构一
我们先从下面这张图开始:
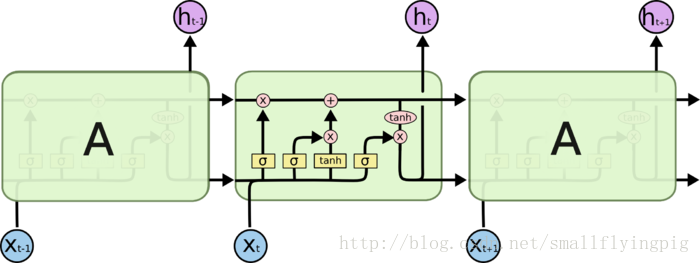
[图片来自:http://colah.github.io/posts/2015-08-Understanding-LSTMs/]
理解上图,可以先看推荐资料2( 简书:[译] 理解 LSTM 网络),但是我在看完推荐资料2之后,还是有一些疑惑:
1. 网络的输出是什么?是
2. 激活函数的输出是一个一维的标量还是一个维度不变的向量?(激活函数包括
3. LSTM,是一个层的结构?还是网络单个节点的结构?我们在MLP的示意图中往往用一个节点表示一维的数据,数据是N维的就有N个节点,那么这里的LSTM是一个层的结构还是针对一个节点的?
这里就针对以上问题一一解答:
1. 网络的输出是
2. 我们先解答第三个问题,LSTM是一个层的结构,也就是,
3. 这里解答第二个问题,激活函数的输出和输出的维数是相同的,通常和xt,ht的维数是相同的(如果前面xt和ht的矩阵变换没有改变他们的维数的话)。
LSTM结构二
还有一张图也很经典:
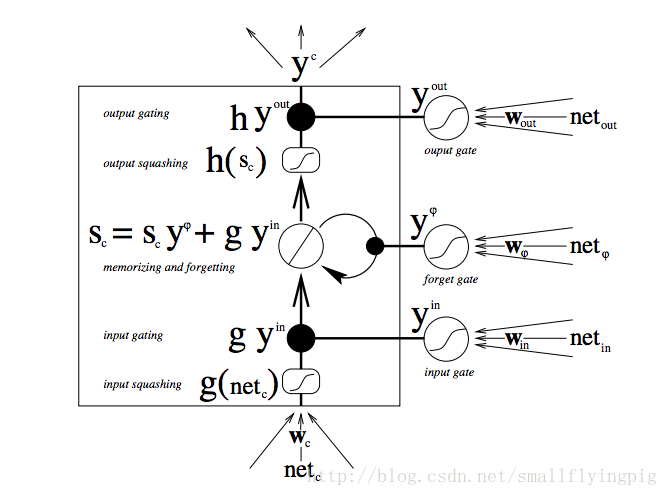
[图片来自paper:Learning to Forget: Continual Prediction with LSTM]
推荐先看推荐资料4(deeplearning4j: A Beginner’s Guide to Recurrent Networks and LSTMs)
这幅图很容易分清楚网络的输入和输出,但是,具体的运算就不是很清楚了(paper中解释的很清楚,但是公式太多了),我在看到这张图时候,有以下几个问题:
1. 四个net都表示什么?
2. 为什么不见网络的输入
3. gate处的激活函数和信息流中的激活函数有什么区别(一个是圆形的,一个是方形的)?
4. 图中的黑点代表什么运算?
解答:
1. 四个net表示什么呢?论文中说是
琢磨半天表示没懂。最后看了 wiki:Long short-term memory里面的公式,觉得应该是
对于三个
2. 为什么不见网络的输入
3. 通常
4. 图中的黑点表示 Hadamard product,也就是矩阵中对应元素分别相乘。