PointNet++的pytorch实现代码阅读
pytorch代码: https://github.com/yanx27/Pointnet2_pytorch
PointNet以及PointNet++的原理可以参考从PointNet到PointNet++,本篇主要详述PointNet++代码的实现。
代码主要由两部分组成,pointnet_util.py封装着一些重要的函数组件,pointnet2.py用来搭建模型。
1. 功能函数文件
1.1 square_distance函数
该函数主要用来在ball query过程中确定每一个点距离采样点的距离。函数输入是两组点,N为第一组点的个数,M为第二组点的个数,C为输入点的通道数(如果是xyz时C=3),返回的是两组点之间两两的欧几里德距离,即 的矩阵。由于在训练中数据通常是以Mini-Batch的形式输入的,所以有一个Batch数量的维度为B。
def square_distance(src, dst):
"""
dist = (xn - xm)^2 + (yn - ym)^2 + (zn - zm)^2
= sum(src**2,dim=-1)+sum(dst**2,dim=-1)-2*src^T*dst
Input:
src: source points, [B, N, C]
dst: target points, [B, M, C]
Output:
dist: per-point square distance, [B, N, M]
"""
B, N, _ = src.shape
_, M, _ = dst.shape
dist = -2 * torch.matmul(src, dst.permute(0, 2, 1)) # 2*(xn * xm + yn * ym + zn * zm)
dist += torch.sum(src ** 2, -1).view(B, N, 1) # xn*xn + yn*yn + zn*zn
dist += torch.sum(dst ** 2, -1).view(B, 1, M) # xm*xm + ym*ym + zm*zm
return dist
1.2 farthest_point_sample函数
最远点采样是Set Abstraction模块中较为核心的步骤,其目的是从一个输入点云中按照所需要的点的个数npoint采样出足够多的点,并且点与点之间的距离要足够远。最后的返回结果是npoint个采样点在原始点云中的索引。
具体步骤如下:
- 先随机初始化一个centroids矩阵,后面用于存储npoint个采样点的索引位置,大小为 ,其中B为BatchSize的个数,即B个样本;
- 利用distance矩阵记录某个样本中所有点到某一个点的距离,初始化为 矩阵,初值给个比较大的值,后面会迭代更新;
- 利用farthest表示当前最远的点,也是随机初始化,范围为0~N,初始化B个,对应到每个样本都随机有一个初始最远点;
- batch_indices初始化为0~(B-1)的数组;
- 直到采样点达到npoint,否则进行如下迭代:
- 设当前的采样点centroids为当前的最远点farthest;
- 取出这个中心点centroid的坐标;
- 求出所有点到这个farthest点的欧式距离,存在dist矩阵中;
- 建立一个mask,如果dist中的元素小于distance矩阵中保存的距离值,则更新distance中的对应值,随着迭代的继续distance矩阵中的值会慢慢变小,其相当于记录着某个样本中每个点距离所有已出现的采样点的最小距离;
- 最后从distance矩阵取出最远的点为farthest,继续下一轮迭代
def farthest_point_sample(xyz, npoint):
"""
Input:
xyz: pointcloud data, [B, N, C]
npoint: number of samples
Return:
centroids: sampled pointcloud index, [B, npoint]
"""
device = xyz.device
B, N, C = xyz.shape
centroids = torch.zeros(B, npoint, dtype=torch.long).to(device)
distance = torch.ones(B, N).to(device) * 1e10
farthest = torch.randint(0, N, (B,), dtype=torch.long).to(device)
batch_indices = torch.arange(B, dtype=torch.long).to(device)
for i in range(npoint):
# 更新第i个最远点
centroids[:, i] = farthest
# 取出这个最远点的xyz坐标
centroid = xyz[batch_indices, farthest, :].view(B, 1, 3)
# 计算点集中的所有点到这个最远点的欧式距离
dist = torch.sum((xyz - centroid) ** 2, -1)
# 更新distances,记录样本中每个点距离所有已出现的采样点的最小距离
mask = dist < distance
distance[mask] = dist[mask]
# 从更新后的distances矩阵中找出距离最远的点,作为最远点用于下一轮迭代
farthest = torch.max(distance, -1)[1]
return centroids
1.3 index_points函数
按照输入的点云数据和索引返回由索引的点云数据。例如points为 的点云,idx为 ,则返回B个样本中每个样本的第1,333,1000,2000个点组成的 的点云集。当然如果idx为一个 维度的,则它会按照idx中的维度结构将其提取成 。
def index_points(points, idx):
"""
Input:
points: input points data, [B, N, C]
idx: sample index data, [B, D1,...DN]
Return:
new_points:, indexed points data, [B, D1,...DN, C]
"""
device = points.device
B = points.shape[0]
view_shape = list(idx.shape)
view_shape[1:] = [1] * (len(view_shape) - 1)
repeat_shape = list(idx.shape)
repeat_shape[0] = 1
batch_indices = torch.arange(B, dtype=torch.long).to(device).view(view_shape).repeat(repeat_shape)
new_points = points[batch_indices, idx, :]
return new_points
1.4 query_ball_point函数
query_ball_point函数用于寻找球形领域中的点。输入中radius为球形领域的半径,nsample为每个领域中要采样的点,new_xyz为S个球形领域的中心(由最远点采样在前面得出),xyz为所有的点云;输出为每个样本的每个球形领域的nsample个采样点集的索引 ,详细的解析都在备注里。
def query_ball_point(radius, nsample, xyz, new_xyz):
"""
Input:
radius: local region radius
nsample: max sample number in local region
xyz: all points, [B, N, C]
new_xyz: query points, [B, S, C]
Return:
group_idx: grouped points index, [B, S, nsample]
"""
device = xyz.device
B, N, C = xyz.shape
_, S, _ = new_xyz.shape
group_idx = torch.arange(N, dtype=torch.long).to(device).view(1, 1, N).repeat([B, S, 1])
# sqrdists: [B, S, N] 记录中心点与所有点之间的欧几里德距离
sqrdists = square_distance(new_xyz, xyz)
# 找到所有距离大于radius^2的,其group_idx直接置为N;其余的保留原来的值
group_idx[sqrdists > radius ** 2] = N
# 做升序排列,前面大于radius^2的都是N,会是最大值,所以会直接在剩下的点中取出前nsample个点
group_idx = group_idx.sort(dim=-1)[0][:, :, :nsample]
# 考虑到有可能前nsample个点中也有被赋值为N的点(即球形区域内不足nsample个点),这种点需要舍弃,直接用第一个点来代替即可
# group_first: [B, S, k], 实际就是把group_idx中的第一个点的值复制为了[B, S, K]的维度,便利于后面的替换
group_first = group_idx[:, :, 0].view(B, S, 1).repeat([1, 1, nsample])
# 找到group_idx中值等于N的点
mask = group_idx == N
# 将这些点的值替换为第一个点的值
group_idx[mask] = group_first[mask]
return group_idx
1.5 Sampling + Grouping
Sampling + Grouping主要用于将整个点云分散成局部的group,对每一个group都可以用PointNet单独的提取局部的全局特征。Sampling + Grouping需要用到上面定义的那些函数,分成了sample_and_group和sample_and_group_all两个函数,其区别在于sample_and_group_all直接将所有点作为一个group。
sample_and_group的实现步骤入下:
- 先用farthest_point_sample函数实现最远点采样FPS得到采样点的索引,再通过index_points将这些点的从原始点中挑出来,作为new_xyz
- 利用query_ball_point和index_points将原始点云通过new_xyz 作为中心分为npoint个球形区域其中每个区域有nsample个采样点
- 每个区域的点减去区域的中心值
- 如果每个点上面有新的特征的维度,则用新的特征与旧的特征拼接,否则直接返回旧的特征
sample_and_group_all直接将所有点作为一个group,即增加一个长度为1的维度而已,当然也存在拼接新的特征的过程,这里不再细述。
def sample_and_group(npoint, radius, nsample, xyz, points):
"""
Input:
npoint: Number of point for FPS
radius: Radius of ball query
nsample: Number of point for each ball query
xyz: Old feature of points position data, [B, N, C]
points: New feature of points data, [B, N, D]
Return:
new_xyz: sampled points position data, [B, npoint, C]
new_points: sampled points data, [B, npoint, nsample, C+D]
"""
B, N, C = xyz.shape
# 从原点云中挑出最远点采样的采样点为new_xyz
new_xyz = index_points(xyz, farthest_point_sample(xyz, npoint))
# idx:[B, npoint, nsample] 代表npoint个球形区域中每个区域的nsample个采样点的索引
idx = query_ball_point(radius, nsample, xyz, new_xyz)
# grouped_xyz:[B, npoint, nsample, C]
grouped_xyz = index_points(xyz, idx)
# grouped_xyz减去采样点即中心值
grouped_xyz -= new_xyz.view(B, npoint, 1, C)
# 如果每个点上面有新的特征的维度,则用新的特征与旧的特征拼接,否则直接返回旧的特征
if points is not None:
grouped_points = index_points(points, idx)
new_points = torch.cat([grouped_xyz, grouped_points], dim=-1)
else:
new_points = grouped_xyz
return new_xyz, new_points
def sample_and_group_all(xyz, points):
"""
Input:
xyz: input points position data, [B, N, C]
points: input points data, [B, N, D]
Return:
new_xyz: sampled points position data, [B, 1, C]
new_points: sampled points data, [B, 1, N, C+D]
"""
device = xyz.device
B, N, C = xyz.shape
new_xyz = torch.zeros(B, 1, C).to(device)
grouped_xyz = xyz.view(B, 1, N, C)
if points is not None:
new_points = torch.cat([grouped_xyz, points.view(B, 1, N, -1)], dim=-1)
else:
new_points = grouped_xyz
return new_xyz, new_points
1.6 SetAbstraction层
普通的SetAbstraction实现的代码较为简单,主要是前面的一些函数的叠加应用。首先先通过sample_and_group的操作形成局部的group,然后对局部的group中的每一个点做MLP操作,最后进行局部的最大池化,得到局部的全局特征。
class PointNetSetAbstraction(nn.Module):
def __init__(self, npoint, radius, nsample, in_channel, mlp, group_all):
'''
Input:
npoint: Number of point for FPS sampling
radius: Radius for ball query
nsample: Number of point for each ball query
in_channel: the dimention of channel
mlp: A list for mlp input-output channel, such as [64, 64, 128]
group_all: bool type for group_all or not
'''
super(PointNetSetAbstraction, self).__init__()
self.npoint = npoint
self.radius = radius
self.nsample = nsample
self.mlp_convs = nn.ModuleList()
self.mlp_bns = nn.ModuleList()
last_channel = in_channel
for out_channel in mlp:
self.mlp_convs.append(nn.Conv2d(last_channel, out_channel, 1))
self.mlp_bns.append(nn.BatchNorm2d(out_channel))
last_channel = out_channel
self.group_all = group_all
def forward(self, xyz, points):
"""
Input:
xyz: input points position data, [B, C, N]
points: input points data, [B, D, N]
Return:
new_xyz: sampled points position data, [B, C, S]
new_points_concat: sample points feature data, [B, D', S]
"""
xyz = xyz.permute(0, 2, 1)
if points is not None:
points = points.permute(0, 2, 1)
# 形成group
if self.group_all:
new_xyz, new_points = sample_and_group_all(xyz, points)
else:
new_xyz, new_points = sample_and_group(self.npoint, self.radius, self.nsample, xyz, points)
# new_xyz: sampled points position data, [B, npoint, C]
# new_points: sampled points data, [B, npoint, nsample, C+D]
new_points = new_points.permute(0, 3, 2, 1) # [B, C+D, nsample,npoint]
# 利用1x1的2d的卷积相当于把每个group当成一个通道,共npoint个通道,对[C+D, nsample]的维度上做逐像素的卷积,结果相当于对单个C+D维度做1d的卷积
for i, conv in enumerate(self.mlp_convs):
bn = self.mlp_bns[i]
new_points = F.relu(bn(conv(new_points)))
# 对每个group做一个max pooling得到局部的全局特征
new_points = torch.max(new_points, 2)[0]
new_xyz = new_xyz.permute(0, 2, 1)
return new_xyz, new_points
这里要具体说一下使用 Multi-Scale Grouping(MSG)方法的SA层:
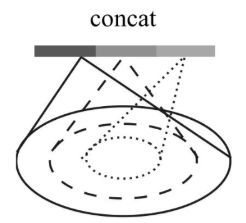
大部分的形式都与普通的SA层相似,但是这里radius_list输入的是一个list例如
,对于不同的半径做ball query,最终将不同半径下的点点云特征保存在new_points_list中,再最后拼接到一起。具体代码如下:
class PointNetSetAbstractionMsg(nn.Module):
def __init__(self, npoint, radius_list, nsample_list, in_channel, mlp_list):
super(PointNetSetAbstractionMsg, self).__init__()
self.npoint = npoint
self.radius_list = radius_list
self.nsample_list = nsample_list
self.conv_blocks = nn.ModuleList()
self.bn_blocks = nn.ModuleList()
for i in range(len(mlp_list)):
convs = nn.ModuleList()
bns = nn.ModuleList()
last_channel = in_channel + 3
for out_channel in mlp_list[i]:
convs.append(nn.Conv2d(last_channel, out_channel, 1))
bns.append(nn.BatchNorm2d(out_channel))
last_channel = out_channel
self.conv_blocks.append(convs)
self.bn_blocks.append(bns)
def forward(self, xyz, points):
"""
Input:
xyz: input points position data, [B, C, N]
points: input points data, [B, D, N]
Return:
new_xyz: sampled points position data, [B, C, S]
new_points_concat: sample points feature data, [B, D', S]
"""
xyz = xyz.permute(0, 2, 1)
if points is not None:
points = points.permute(0, 2, 1)
B, N, C = xyz.shape
S = self.npoint
new_xyz = index_points(xyz, farthest_point_sample(xyz, S))
new_points_list = []
for i, radius in enumerate(self.radius_list):
K = self.nsample_list[i]
group_idx = query_ball_point(radius, K, xyz, new_xyz)
grouped_xyz = index_points(xyz, group_idx)
grouped_xyz -= new_xyz.view(B, S, 1, C)
if points is not None:
grouped_points = index_points(points, group_idx)
grouped_points = torch.cat([grouped_points, grouped_xyz], dim=-1)
else:
grouped_points = grouped_xyz
grouped_points = grouped_points.permute(0, 3, 2, 1) # [B, D, K, S]
for j in range(len(self.conv_blocks[i])):
conv = self.conv_blocks[i][j]
bn = self.bn_blocks[i][j]
grouped_points = F.relu(bn(conv(grouped_points)))
new_points = torch.max(grouped_points, 2)[0] # [B, D', S]
new_points_list.append(new_points)
new_xyz = new_xyz.permute(0, 2, 1)
new_points_concat = torch.cat(new_points_list, dim=1)
return new_xyz, new_points_concat
1.7 FeaturePropagation层
FeaturePropagation层的实现主要通过线性差值与MLP堆叠完成。当点的个数只有一个的时候,采用repeat直接复制成N个点;当点的个数大于一个的时候,采用线性差值的方式进行上采样,再对上采样后的每一个点都做一个MLP,同时拼接上下采样前相同点个数的SA层的特征。
线性差值的公式入下: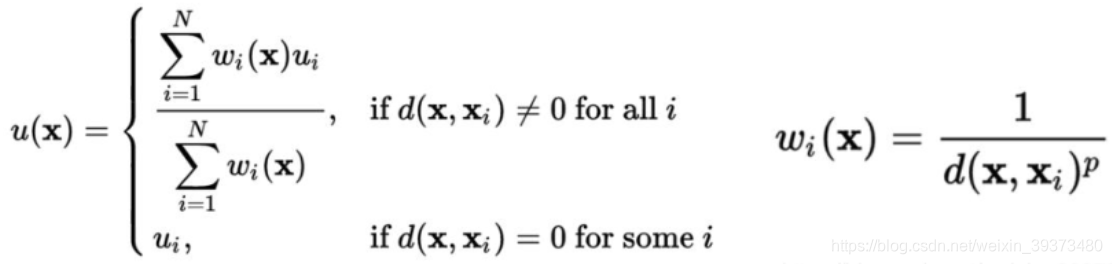
简单来说就是距离越远的点权重越小,最后对于每一个点的权重再做一个全局的归一化。
class PointNetFeaturePropagation(nn.Module):
def __init__(self, in_channel, mlp):
super(PointNetFeaturePropagation, self).__init__()
self.mlp_convs = nn.ModuleList()
self.mlp_bns = nn.ModuleList()
last_channel = in_channel
for out_channel in mlp:
self.mlp_convs.append(nn.Conv1d(last_channel, out_channel, 1))
self.mlp_bns.append(nn.BatchNorm1d(out_channel))
last_channel = out_channel
def forward(self, xyz1, xyz2, points1, points2):
"""
Input:
xyz1: input points position data, [B, C, N]
xyz2: sampled input points position data, [B, C, S]
points1: input points data, [B, D, N]
points2: input points data, [B, D, S]
Return:
new_points: upsampled points data, [B, D', N]
"""
xyz1 = xyz1.permute(0, 2, 1)
xyz2 = xyz2.permute(0, 2, 1)
points2 = points2.permute(0, 2, 1)
B, N, C = xyz1.shape
_, S, _ = xyz2.shape
if S == 1:
interpolated_points = points2.repeat(1, N, 1)
else:
dists = square_distance(xyz1, xyz2)
dists, idx = dists.sort(dim=-1)
dists, idx = dists[:, :, :3], idx[:, :, :3] # [B, N, 3]
dists[dists < 1e-10] = 1e-10
weight = 1.0 / dists # [B, N, 3]
weight = weight / torch.sum(weight, dim=-1).view(B, N, 1) # [B, N, 3]
interpolated_points = torch.sum(index_points(points2, idx) * weight.view(B, N, 3, 1), dim=2)
if points1 is not None:
points1 = points1.permute(0, 2, 1)
new_points = torch.cat([points1, interpolated_points], dim=-1)
else:
new_points = interpolated_points
new_points = new_points.permute(0, 2, 1)
for i, conv in enumerate(self.mlp_convs):
bn = self.mlp_bns[i]
new_points = F.relu(bn(conv(new_points)))
return new_points
2. 模型主文件
模型的主体搭建起来都较为容易,主要难点还在于上面的功能函数的编写,下面直接贴出代码。特别需要说明的是part segmentation和scene segmentation的区别主要在于后者不会sample_and_group_all,这说明在场景的分割问题中不适合把点的特征下采样到单个点再进行上采样。
2.1 Classification
class PointNet2ClsMsg(nn.Module):
def __init__(self):
super(PointNet2ClsMsg, self).__init__()
self.sa1 = PointNetSetAbstractionMsg(512, [0.1, 0.2, 0.4], [16, 32, 128], 0, [[32, 32, 64], [64, 64, 128], [64, 96, 128]])
self.sa2 = PointNetSetAbstractionMsg(128, [0.2, 0.4, 0.8], [32, 64, 128], 320, [[64, 64, 128], [128, 128, 256], [128, 128, 256]])
self.sa3 = PointNetSetAbstraction(None, None, None, 640 + 3, [256, 512, 1024], True)
self.fc1 = nn.Linear(1024, 512)
self.bn1 = nn.BatchNorm1d(512)
self.drop1 = nn.Dropout(0.4)
self.fc2 = nn.Linear(512, 256)
self.bn2 = nn.BatchNorm1d(256)
self.drop2 = nn.Dropout(0.4)
self.fc3 = nn.Linear(256, 40)
def forward(self, xyz):
B, _, _ = xyz.shape
l1_xyz, l1_points = self.sa1(xyz, None)
l2_xyz, l2_points = self.sa2(l1_xyz, l1_points)
l3_xyz, l3_points = self.sa3(l2_xyz, l2_points)
x = l3_points.view(B, 1024)
x = self.drop1(F.relu(self.bn1(self.fc1(x))))
x = self.drop2(F.relu(self.bn2(self.fc2(x))))
x = self.fc3(x)
x = F.log_softmax(x, -1)
return x
2.2 Part Segmentation
class PointNet2PartSeg(nn.Module):
def __init__(self, num_classes):
super(PointNet2PartSeg, self).__init__()
self.sa1 = PointNetSetAbstraction(npoint=512, radius=0.2, nsample=64, in_channel=3, mlp=[64, 64, 128], group_all=False)
self.sa2 = PointNetSetAbstraction(npoint=128, radius=0.4, nsample=64, in_channel=128 + 3, mlp=[128, 128, 256], group_all=False)
self.sa3 = PointNetSetAbstraction(npoint=None, radius=None, nsample=None, in_channel=256 + 3, mlp=[256, 512, 1024], group_all=True)
self.fp3 = PointNetFeaturePropagation(in_channel=1280, mlp=[256, 256])
self.fp2 = PointNetFeaturePropagation(in_channel=384, mlp=[256, 128])
self.fp1 = PointNetFeaturePropagation(in_channel=128, mlp=[128, 128, 128])
self.conv1 = nn.Conv1d(128, 128, 1)
self.bn1 = nn.BatchNorm1d(128)
self.drop1 = nn.Dropout(0.5)
self.conv2 = nn.Conv1d(128, num_classes, 1)
def forward(self, xyz):
# Set Abstraction layers
l1_xyz, l1_points = self.sa1(xyz, None)
l2_xyz, l2_points = self.sa2(l1_xyz, l1_points)
l3_xyz, l3_points = self.sa3(l2_xyz, l2_points)
# Feature Propagation layers
l2_points = self.fp3(l2_xyz, l3_xyz, l2_points, l3_points)
l1_points = self.fp2(l1_xyz, l2_xyz, l1_points, l2_points)
l0_points = self.fp1(xyz, l1_xyz, None, l1_points)
# FC layers
feat = F.relu(self.bn1(self.conv1(l0_points)))
x = self.drop1(feat)
x = self.conv2(x)
x = F.log_softmax(x, dim=1)
x = x.permute(0, 2, 1)
return x, feat
2.3 Scene Segmentation
class PointNet2SemSeg(nn.Module):
def __init__(self, num_classes):
super(PointNet2SemSeg, self).__init__()
self.sa1 = PointNetSetAbstraction(1024, 0.1, 32, 3, [32, 32, 64], False)
self.sa2 = PointNetSetAbstraction(256, 0.2, 32, 64 + 3, [64, 64, 128], False)
self.sa3 = PointNetSetAbstraction(64, 0.4, 32, 128 + 3, [128, 128, 256], False)
self.sa4 = PointNetSetAbstraction(16, 0.8, 32, 256 + 3, [256, 256, 512], False)
self.fp4 = PointNetFeaturePropagation(768, [256, 256])
self.fp3 = PointNetFeaturePropagation(384, [256, 256])
self.fp2 = PointNetFeaturePropagation(320, [256, 128])
self.fp1 = PointNetFeaturePropagation(128, [128, 128, 128])
self.conv1 = nn.Conv1d(128, 128, 1)
self.bn1 = nn.BatchNorm1d(128)
self.drop1 = nn.Dropout(0.5)
self.conv2 = nn.Conv1d(128, num_classes, 1)
def forward(self, xyz):
l1_xyz, l1_points = self.sa1(xyz, None)
l2_xyz, l2_points = self.sa2(l1_xyz, l1_points)
l3_xyz, l3_points = self.sa3(l2_xyz, l2_points)
l4_xyz, l4_points = self.sa4(l3_xyz, l3_points)
l3_points = self.fp4(l3_xyz, l4_xyz, l3_points, l4_points)
l2_points = self.fp3(l2_xyz, l3_xyz, l2_points, l3_points)
l1_points = self.fp2(l1_xyz, l2_xyz, l1_points, l2_points)
l0_points = self.fp1(xyz, l1_xyz, None, l1_points)
x = self.drop1(F.relu(self.bn1(self.conv1(l0_points))))
x = self.conv2(x)
x = F.log_softmax(x, dim=1)
return x