
一 、前言
YOLO(You Only Look Once)是一种快速、高效、准确的目标检测算法,由Joseph Redmon等人于2016年提出。相比于其他目标检测算法,YOLO使用单个神经网络实现目标检测,使其更快、更高效。
YOLO算法的基本原理是将输入图像分成一个个网格,然后每个网格都会预测该网格内存在的物体的边框位置和类别概率。与传统的目标检测算法相比,YOLO在处理整个图像时只需要执行一次前向传递操作,因此速度非常快。此外,YOLO的网络结构比较简单,具有很强的通用性和可扩展性,可以应用于多种不同的目标检测任务。
在实际应用中,YOLO已经被广泛应用于各种计算机视觉应用,例如自动驾驶、监控和机器人。它以其高准确性和实时处理能力而闻名,是许多目标检测任务的首选算法之一。
二、目标检测常用名词
anchor box
候选框,需要手动设置,而且数据集不同的时候,候选框的大小也不同,
bounding box
给出物体在图像中的定位区域的表示,通常包含左上角点的坐标x1,y1, 还有这个检测框的宽高,
–>(x1, y1, H, W)。一般就是预测框
ground turth
在训练集上标注的物体框,一般包含物体的坐标、种类,是真实框
IoU
是预测框和真实框的交集除以并集。IoU = (bounding box 交 ground truth)/ (bounding box 并 ground truth),用来评测算法的检测结果和真是结果的重叠程度,IoU越大说明重叠程度越高,模型的检测效果越好,一般在0-1之间。
nms(非极大值抑制)
在得出IoU之后,使用非极大值抑制,就可以保留同一区域内同一目标IoU最大的那个检测框,从而去点一些多余的重复框。
mAP
这是一个所有类别AP值总和的平均数,用来评价模型的性能,衡量检测器在所有类别上的性能好坏。
RPN
候选区域,通常用于two-stage目标检测器。提取出所有可能包含识别目标的一些区域。RPN做的事情就是,如果存在一个区域,他的p > 0.5, 则认为它是所检测类别中的某一类,但是具体属于哪一个类还不确定 ,用Network把这一个区域提取出来,就是所谓的感兴趣区域,然后RPN在这些感兴趣的区域上输出bounding box。 意思就是在一张图上面选出一些感兴趣的候选区域,只对这些感兴趣的候选区域进行处理,然后忽略掉那些不感兴趣的背景之类的信息。
PR曲线
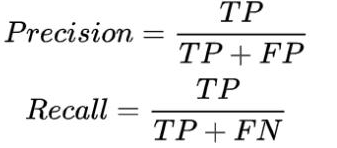
Precision是精度,Recall是召回率,P—R曲线就是根据这两个值来绘制的,

FLOPS FLOPs parameters
FLOPS:floating point opreations per second的缩写,意思是每秒浮点数运算次数,可以理解为计算的速度,这是用来衡量硬件的指标。
三、YOlO_V1
1.概述
- 深度学习经典检测方法
two-stage(两阶段):Faster–rcnn Mask-Rcnn系列(多了预选框)
9one-stage(单阶段):YOLO系列 - one-stage:
最核心的优势:速度非常快,适合做实时检测任务!
但是缺点也是有的,效果通常情况下不会太好! - two-stage:
速度通常较慢(5FPS),但是效果通常还是不错的!
非常实用的通用框架有MaskRcnn,
2.核心思想
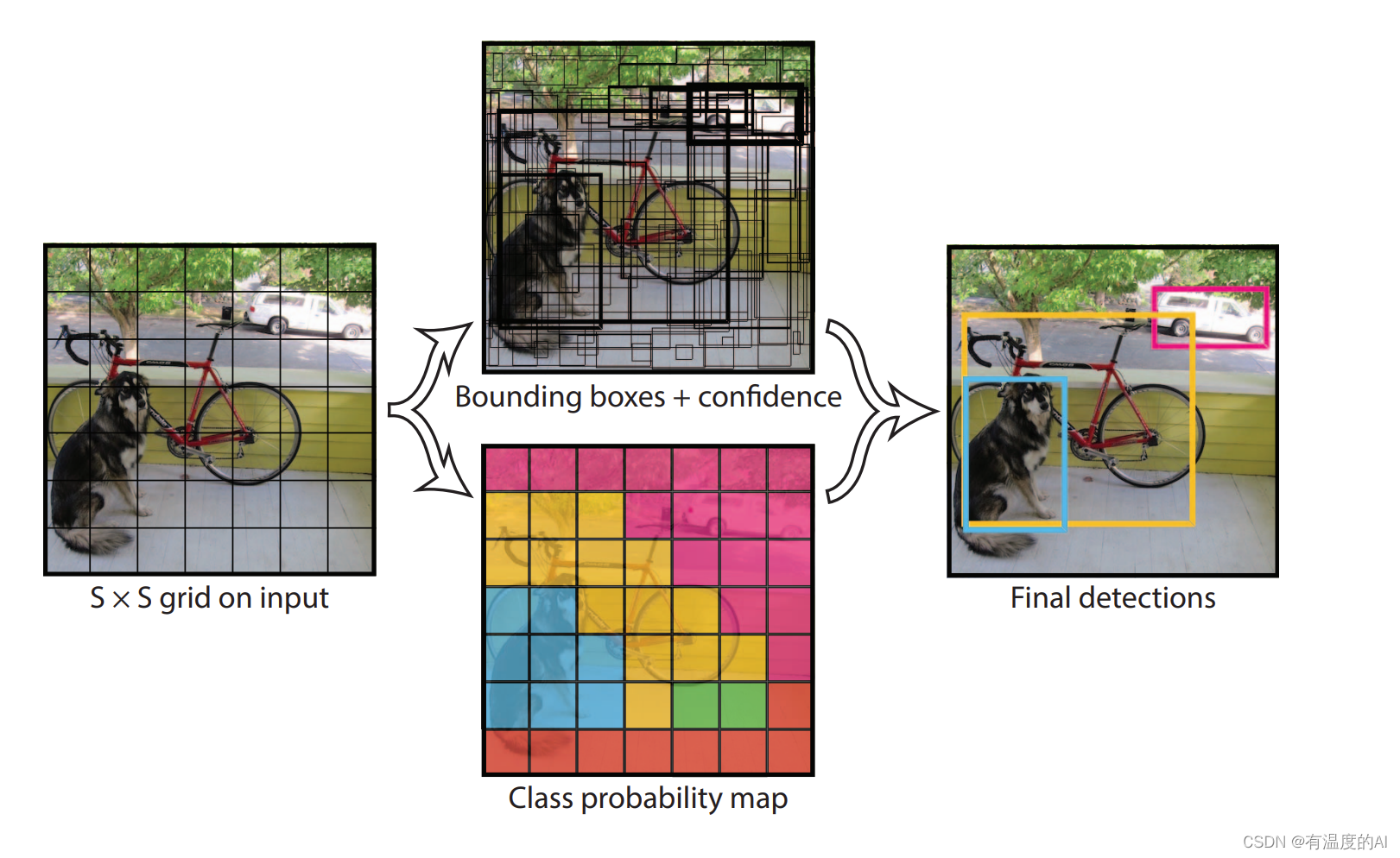
YOLOV1最后生成7×7的网格(grid cell),每个grid cell会产生两个预测框(bounding box),每个grid cell产生的两个预测框只能预测同一种类物体,也就是说YOLOV1最多只能预测49种物体,两个预测框中哪一个与标注框的IOU大就选哪一个(此即正样本),另外一个会被舍弃(负样本);特殊情况(如果有两个相同种类的物体中心点都落在同一个grid cell中,此时这个grid cell的两个预测框有可能都与真实框有最大的IOU,也即两个预测框都为正样本,这也就是说YOLOV1最多能预测49×2个目标)。如果标注框的中心点落在哪一个grid cell中就由这个grid cell产生的两个预测框去负责预测,没有标注框中心点落入的grid cell产生的两个预测框都视为负样本,置信度越小越好。
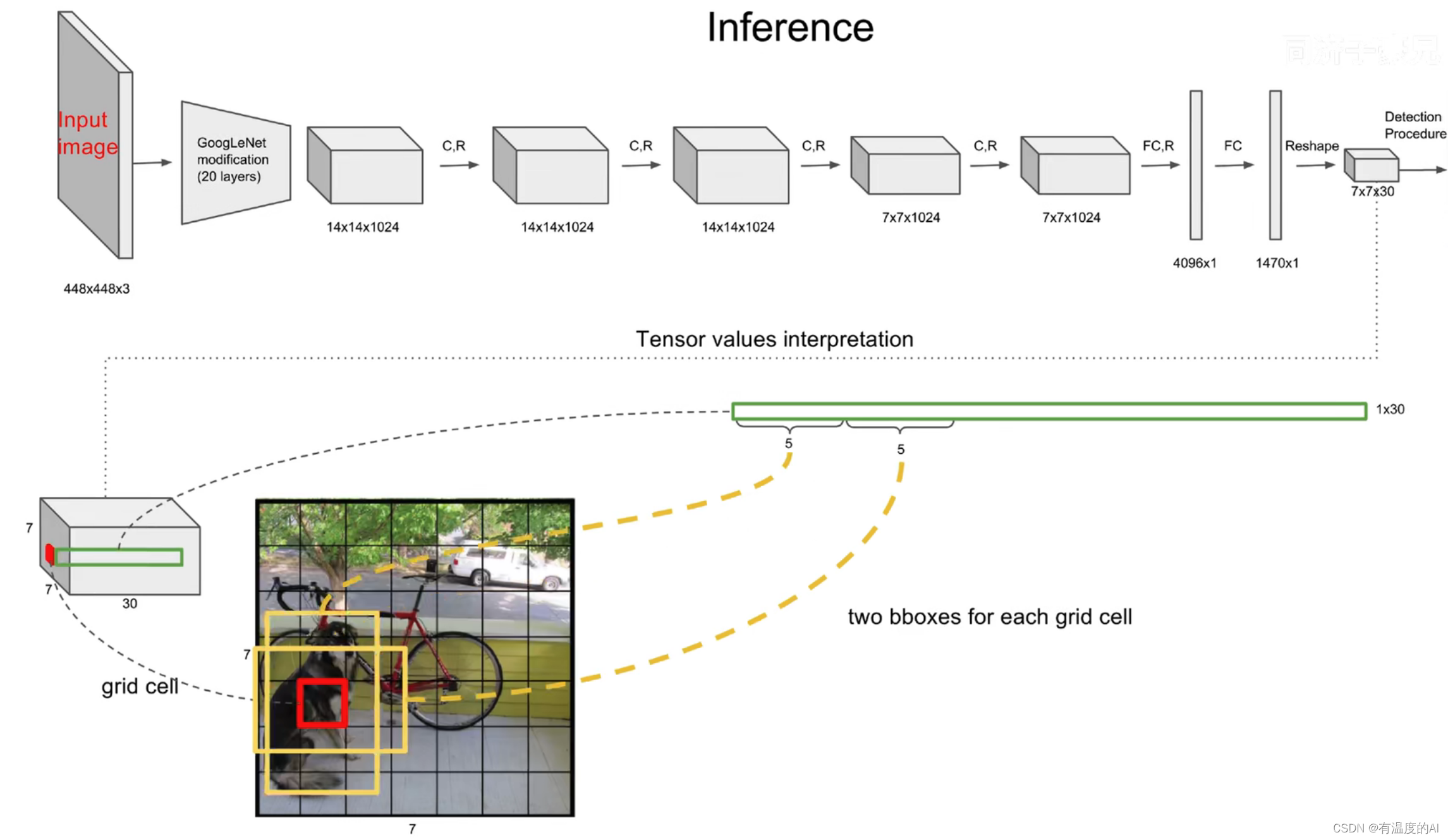 7×7意味着7×7个grid cell,30表示每个grid cell包含30个信息,其中两个预测框,每个预测框包含五个信息(x y w h c),分别为中心点位置坐标,宽高以及置信度,剩下20个是针对VOC数据集的20个种类的预测概率(即假设该grid cell负责预测物体,那么它是某个类别的概率)。
7×7意味着7×7个grid cell,30表示每个grid cell包含30个信息,其中两个预测框,每个预测框包含五个信息(x y w h c),分别为中心点位置坐标,宽高以及置信度,剩下20个是针对VOC数据集的20个种类的预测概率(即假设该grid cell负责预测物体,那么它是某个类别的概率)。
](https://tianfeng.space/wp-content/uploads/2023/05/20210301174140196.png)
3.损失函数
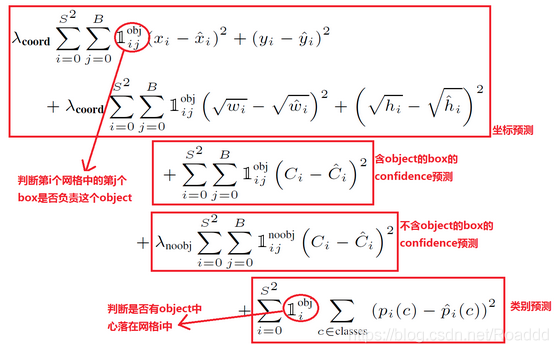 分别为位置误差,两个置信度误差(目标和非目标),分类误差组成
分别为位置误差,两个置信度误差(目标和非目标),分类误差组成
4.特点
优点:快速,简单!
问题1:每个Cell只预测一个类别,如果重叠无法解决
问题2:小物体检测效果一般,长宽比可选的但单