因为简历上写的项目是目标检测,之前在地平线面试也被问了YOLO,再加上YOLO是目前比较著名的目标检测算法,所以集中学习一下
参考文章:1、Yolo系列
当前目标检测算法分为两种1
:
- 包含Region proposals提取阶段的两阶段目标检测框架:R-CNN/Fast-RCNN/Faster-FCNN/R-FCN
准确率(mAP值)更高,但其速度较慢,很难满足图片或视频实时性处理要求 - 端到端的单阶段目标检测框架:Yolo-v1/Yolo-v2/Yolo-v3及SSD,和最近Facebook提出的RetinaNet
准确率较低,但却能在保证一定准确率的情况下,拥有更快、甚至实时的推理速度,因此在现实工程实践中也获得了较多的应用。
YOLOv1 :
YOLO概述:
- resize图片,448*448(输入图片尺寸固定,因为后面与fc层)
- 运行神经网络 前端cnn–>feature map --> cnn、Average Pool 、fc*2 --> 目标类别、位置和其置信度等
- NMS非极大值抑制

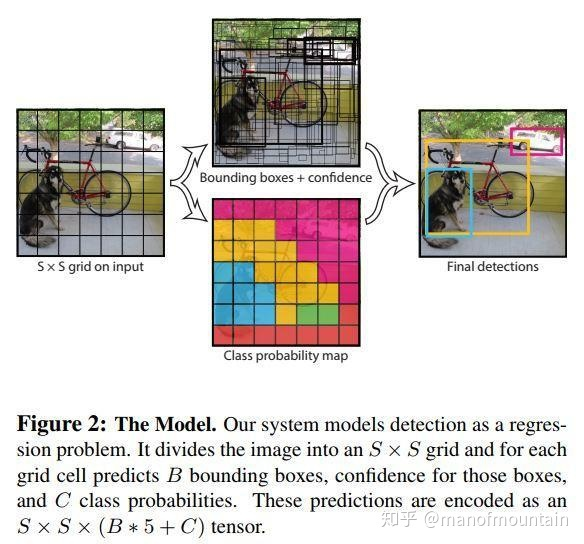
具体过程见下图:
置信度 = Pr(Object) ∗ IOUpredtruth ,其实就是Pc * IoU,到后面我们会选择具有最高概率的Pc的框,然后把和这个框置信度高的框删除,达到减少框的目的。最后输出S*S* (B*5 + C)
YOLO v1的缺点:
- 直接在image level上划分grid区域,然后每个区域指定固定数目的boxes,再对这些boxes作回归检测、分析,这可能会导致它不大能处理不同scales的目标。实验表明它在处理很小的群体目标时性能极差
- 此外因为它仅使用最后一层的抽象CNN特征来得到目标框的位置、类别等信息,因此生成出的目标框不够细化。
- 最后它的training loss计算中对不同大小的目标框一视同仁,不加区分。这导致它不能较好的对待小尺度的目标框。实验表明localization error较大是它精度相对于Faster-FCNN模型不高的主要因素。
YOLO v2 :
改进:
-
BN(batch normalization)的引入
Yolo v2通过在之前Yolo中用到的所有conv层加入bn,整个模型的检测mAP有效提升了近2%。BN的引入也让作者放弃了在新的模型中使用之前用于防止模型过拟合的dropout层。 -
finetune时高精度分类器的使用(没看懂)
-
使用卷积生成的Anchor boxes
Yolo v1模型当初直接在特征提取主干网络最后端生成的feature maps上后接FC,然后生成得到预测的目标框的类别、位置等信息。 -
使用K-means cluster来选取anchor boxes
-
直接目标框位置检测(没看懂)
-
细粒度特征的使用
-
多尺度训练