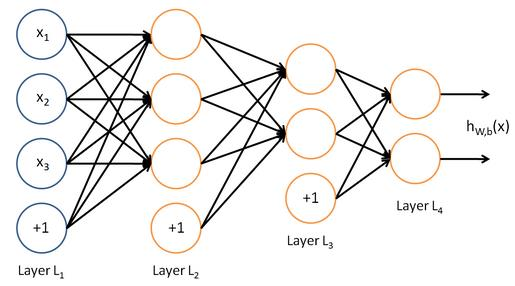
前馈神经网络
MLP:multi-layer percetron
- Feed Forward and Back error propagation
- 解决异或划分问题
缺点:
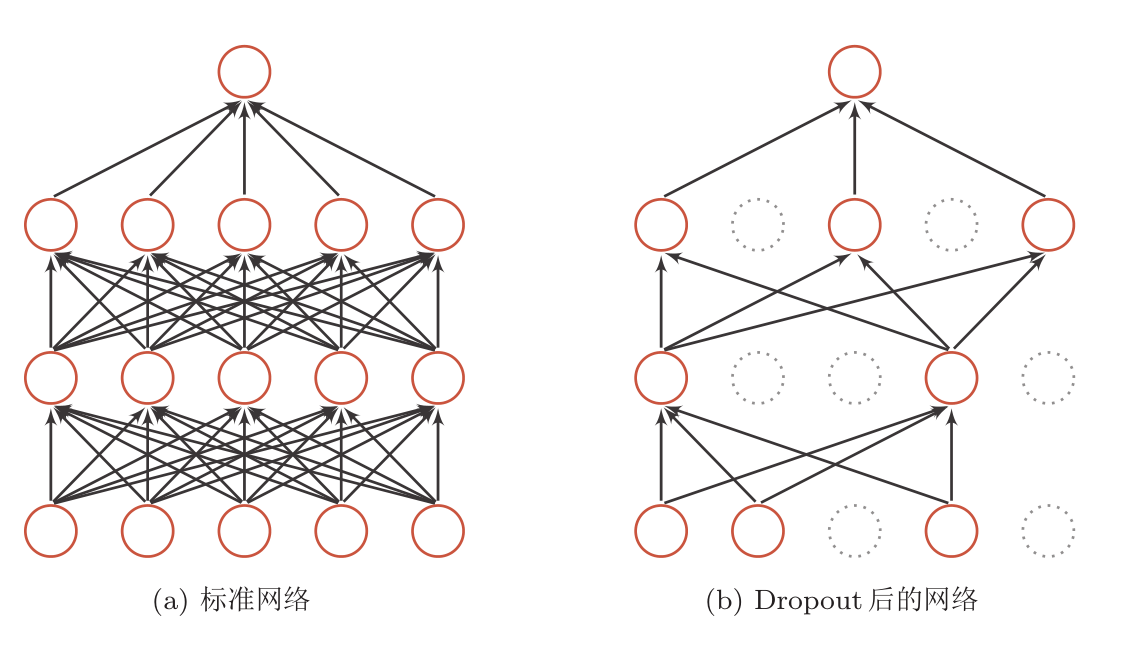
- 容易过拟合
- 容易陷入局部最优化
- 梯度消失
- 计算资源不充分,训练集小
- DNN 深一点效果好,宽一点容易理解,发现潜在规律
-
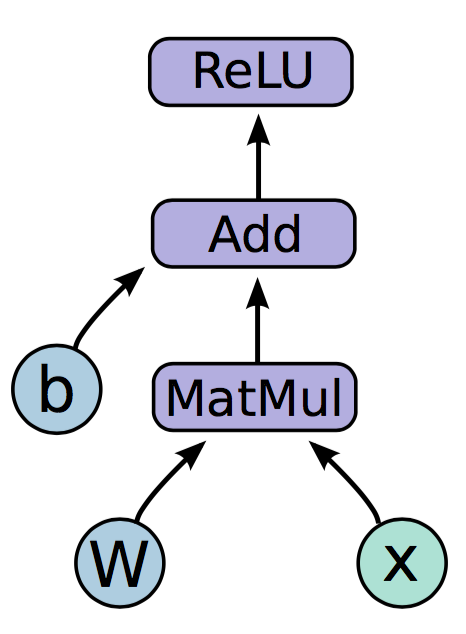
前向计算公式:
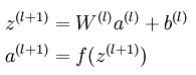
-
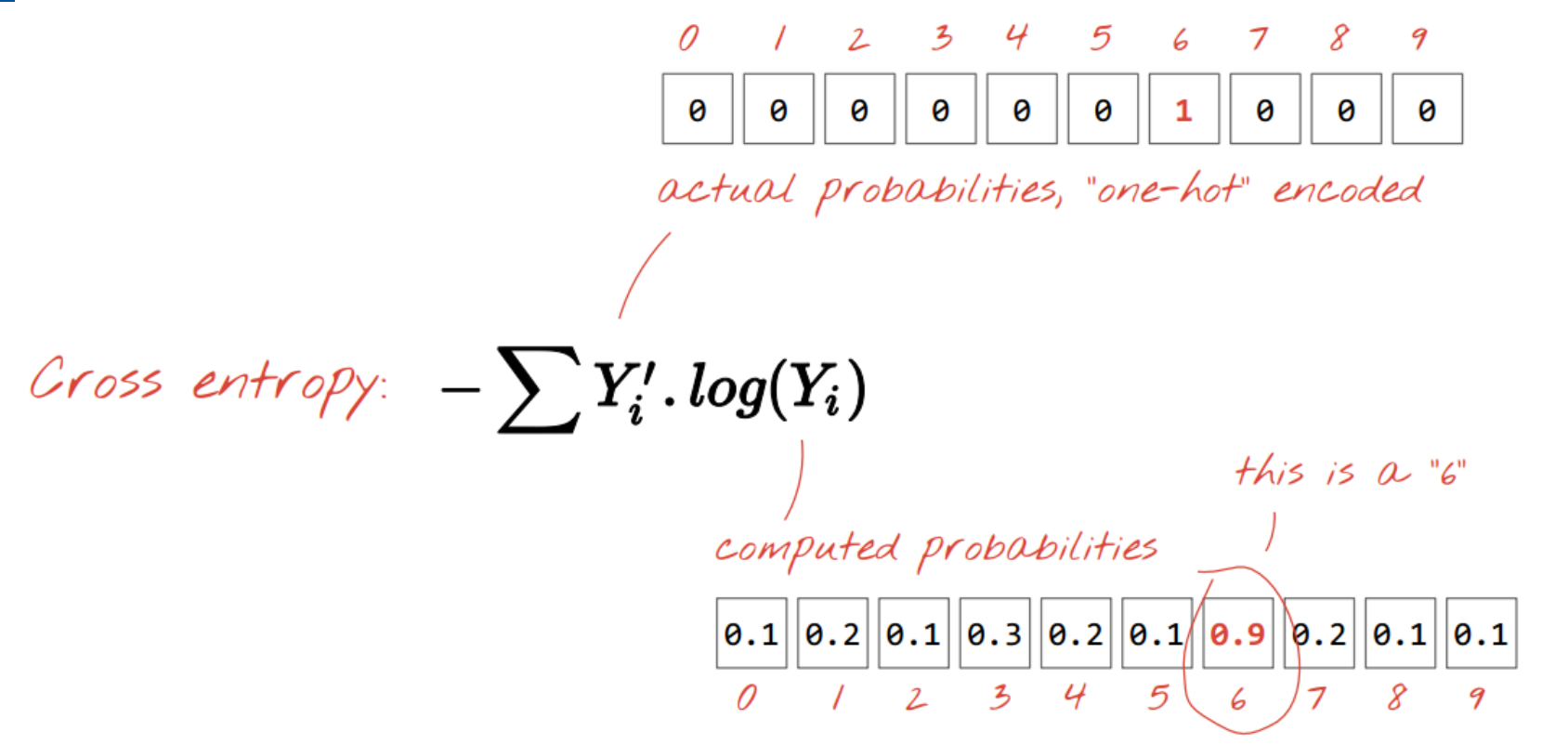
损失函数:
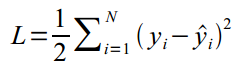
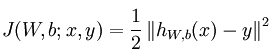
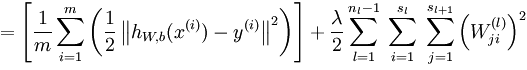
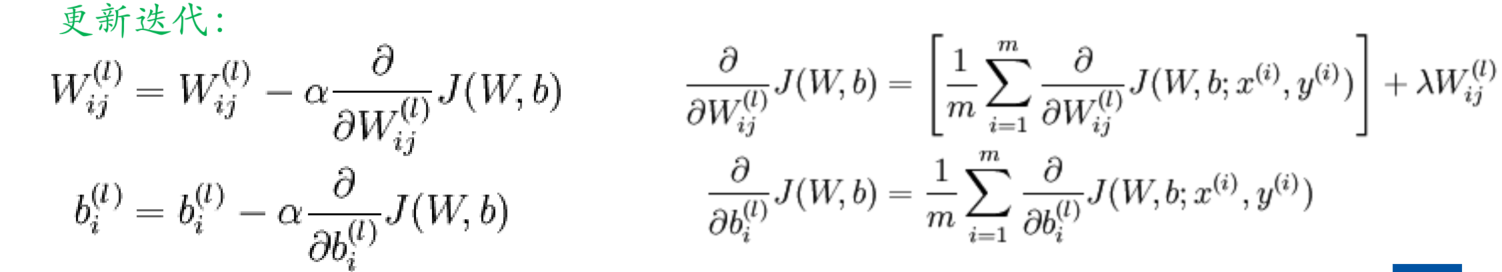
常见激活函数
- sigmoid函数
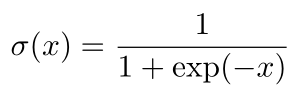
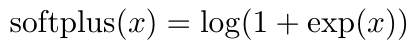
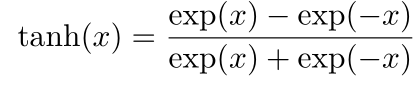
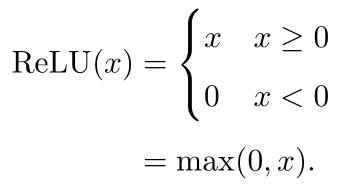
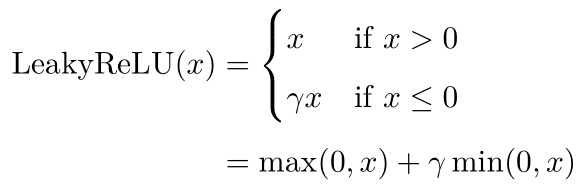

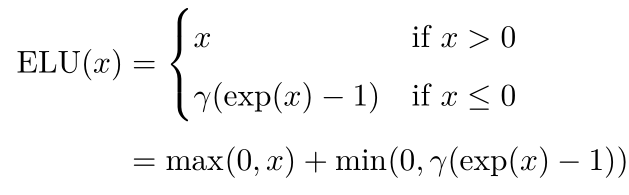
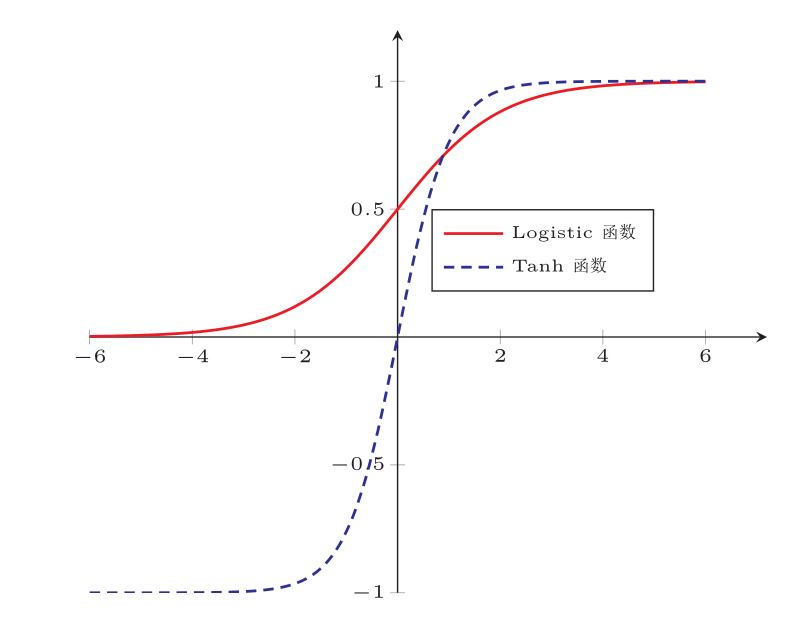
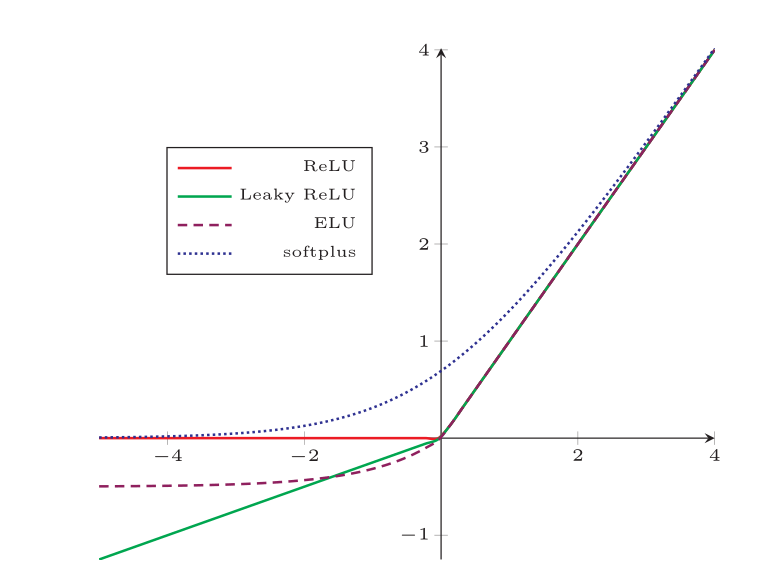

梯度消失与爆炸

通用逼近定理

根据通用近似定理,对于具有线性输出层和至少一个使用“挤压”性质的激活函数的隐藏层组成的前馈神经网络
- 只要其隐藏层神经元的数量足够,它可以以任意的精度来近似任何从一个定义在实数空间中的有界闭集函数。
- 隐含层的数量不是越多越好,层数和特征的个数太多,会造成优化的难度和出现过拟合的现象
- 只需要输入最基本的特征x1, x2, 只要给予足够多层的神经网络和神经元,神经网络会自己组合出最有用的特征
tensorflow实现
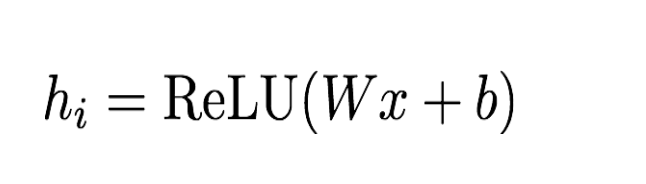


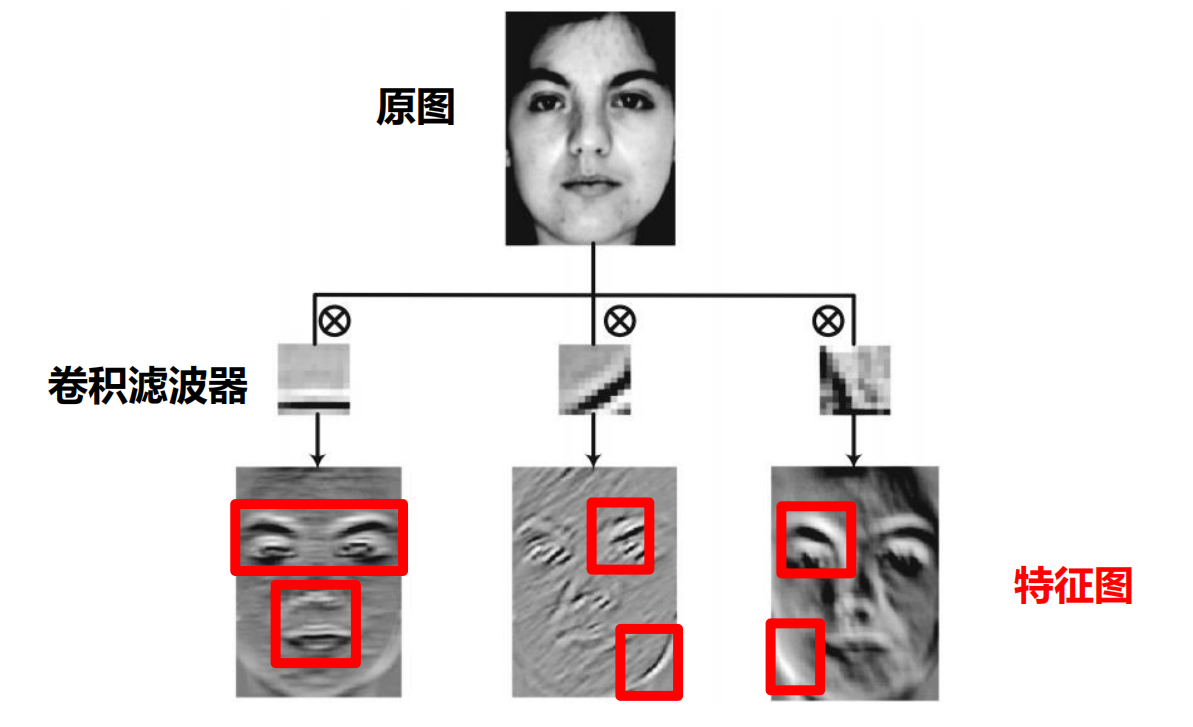
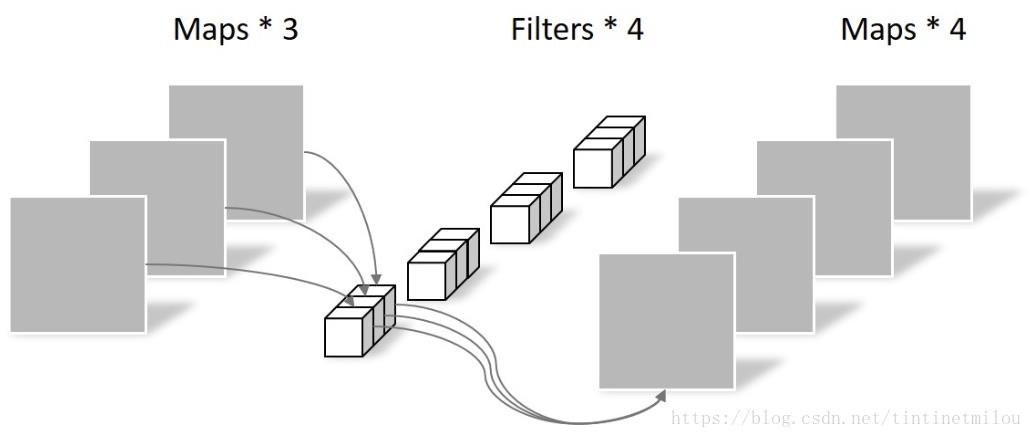
- 一张图片-个滤波器,得一个特征图
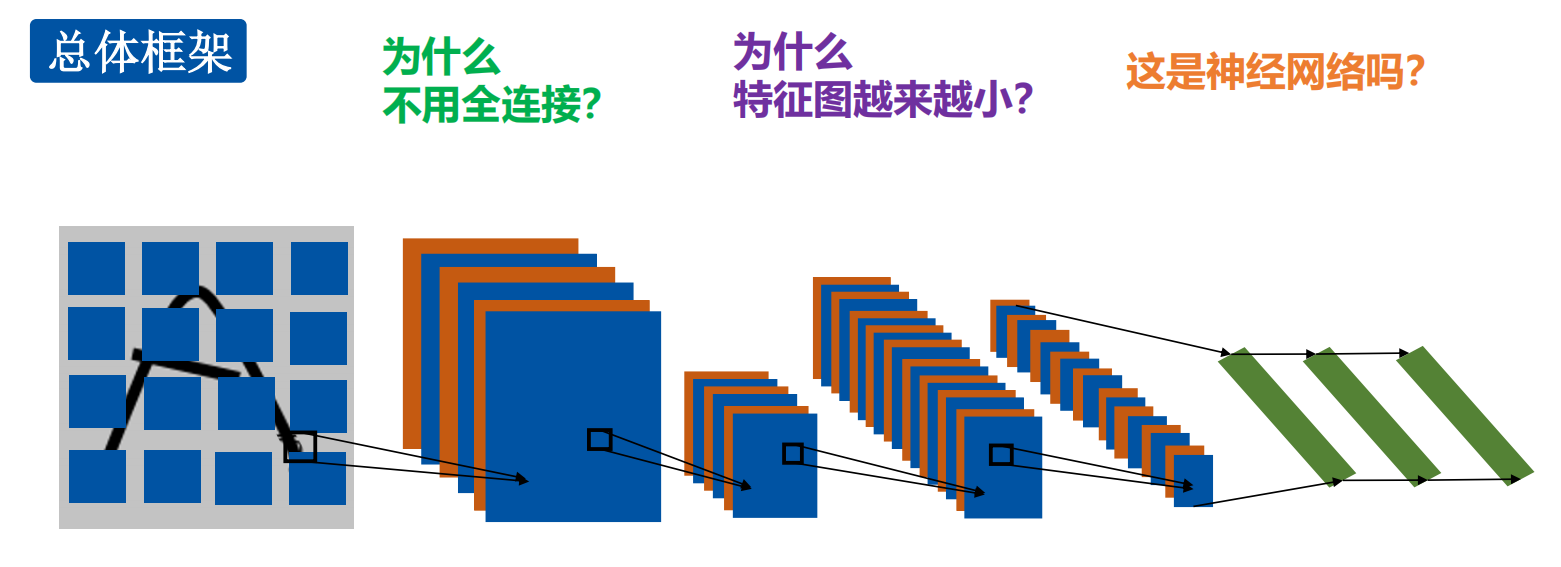
- 为什么不用全连接?
计算量太大,容易过拟合 - 为什么特征图越来越小?
下采样,即池化会让特征图尺寸变小 - 这是神经网络么?是的
CNN的由来:
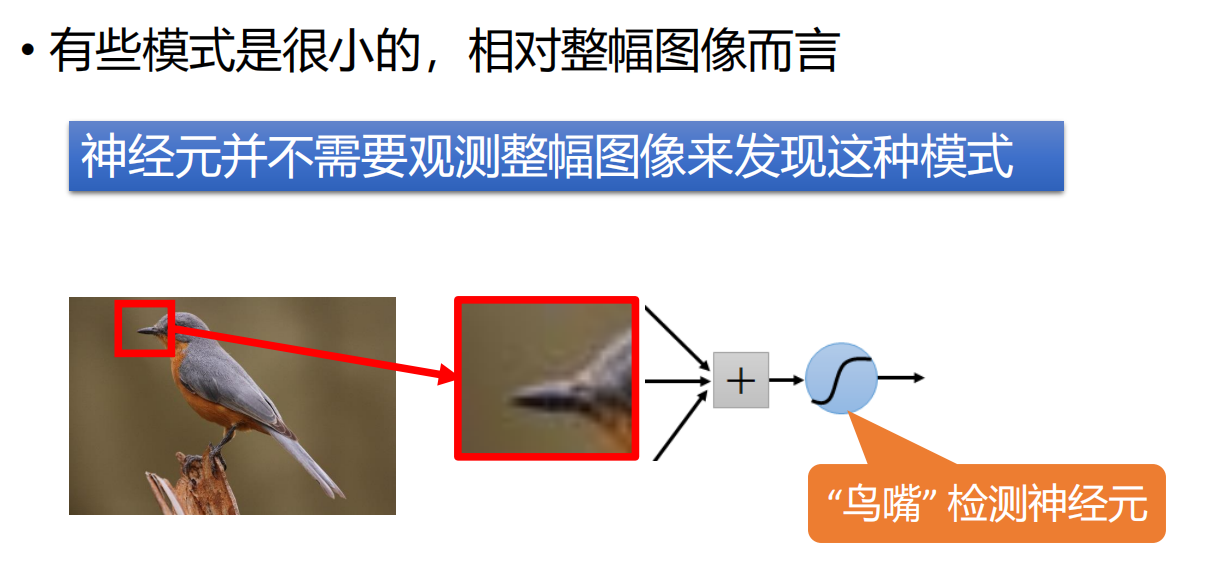
- 引出,CNN的第一个特点:局部感知


- 引导出第二个特征:权重共享
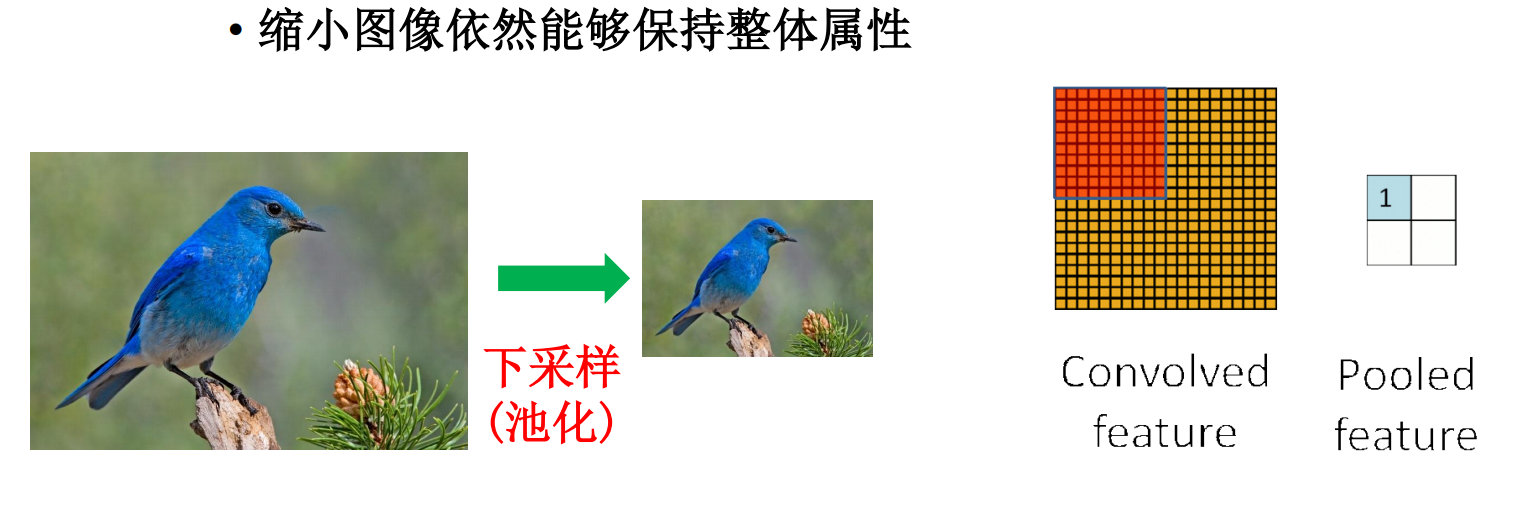
- 第三个特征:池化,下采样
全连接网络的BP算法
- 模型函数表达式
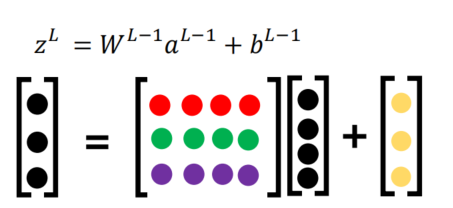
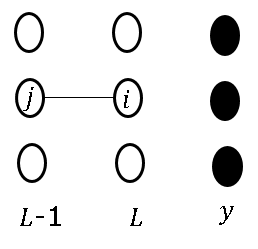
- L-1层,即输出层的前一层,反向传播的梯度由输出的误差和L-1层与L层之间的权重决定


- 所以整个损失矩阵 δ i L \delta_i^L δiL,由负的误差*隐层输出的导数(激活函数的导数 * 权重)
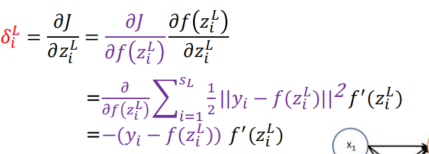


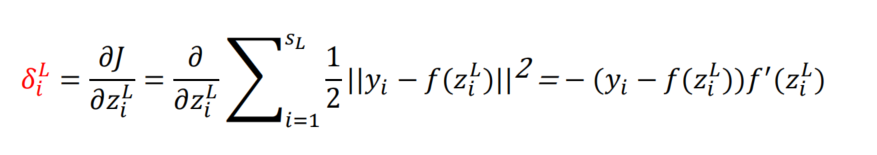
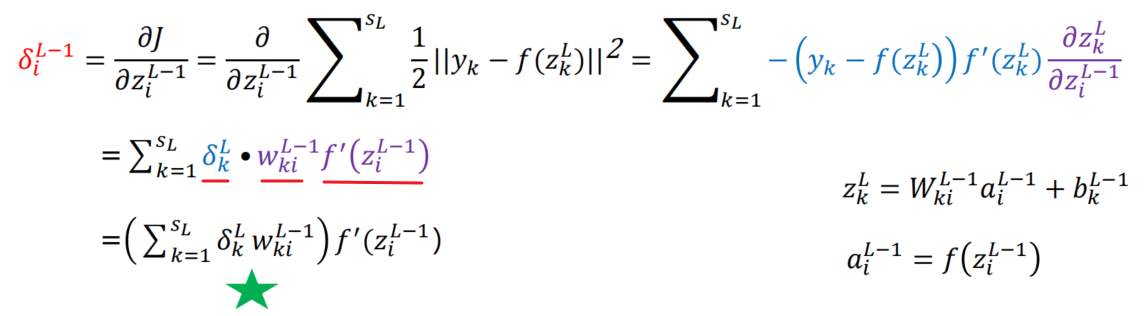
- L-2层,由L-1层的误差项(误差*激活函数的导数)
CNN的卷积BP算法



- δ \delta δ是误差矩阵
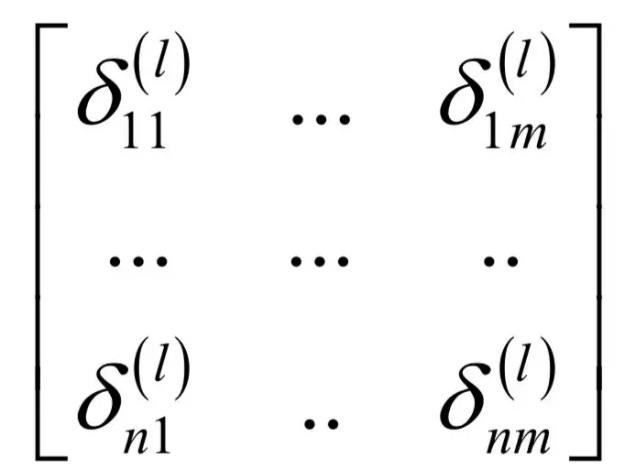

残差如何传递?


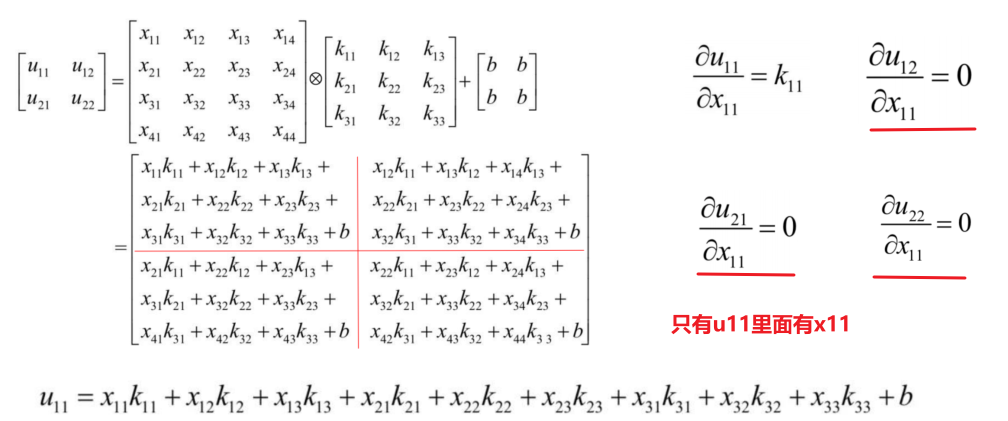
δ \delta δ求解详细过程
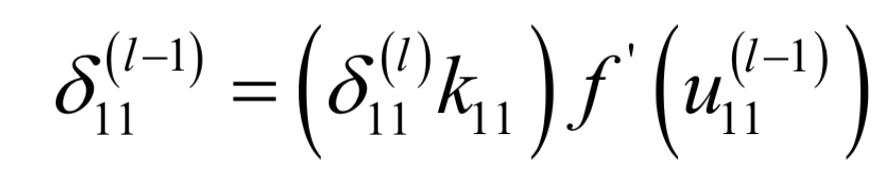
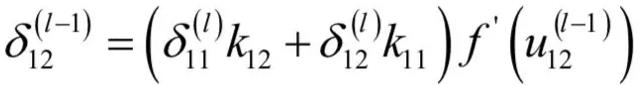
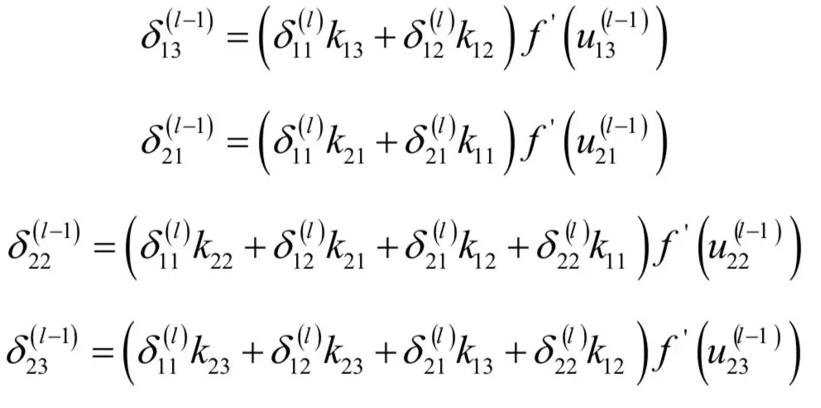
- 关键核心公式
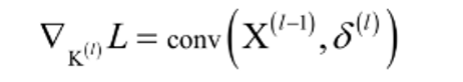
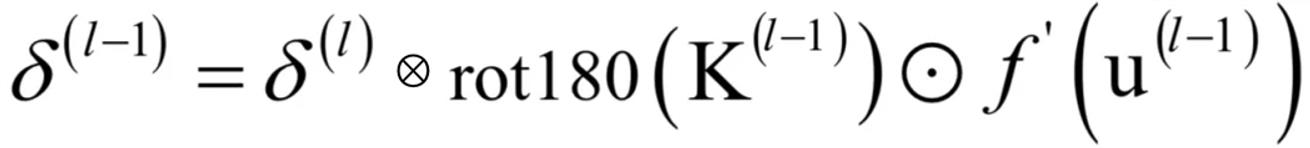
- 误差项,求完导是1,所以残差项传递与bias项无关
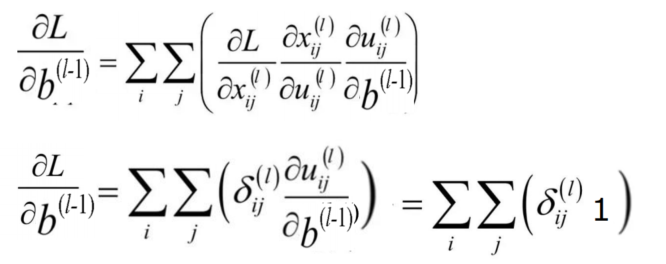
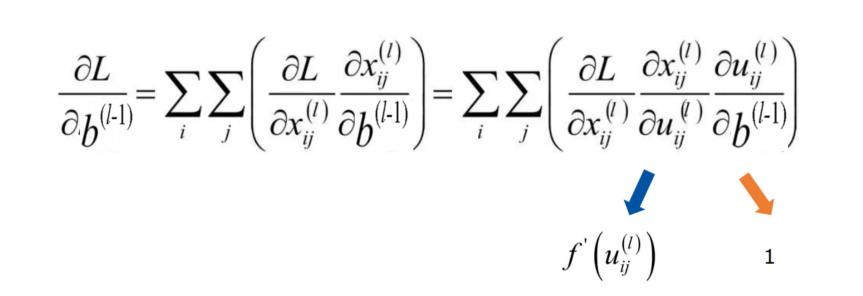
- 多个特征图可以并行卷积
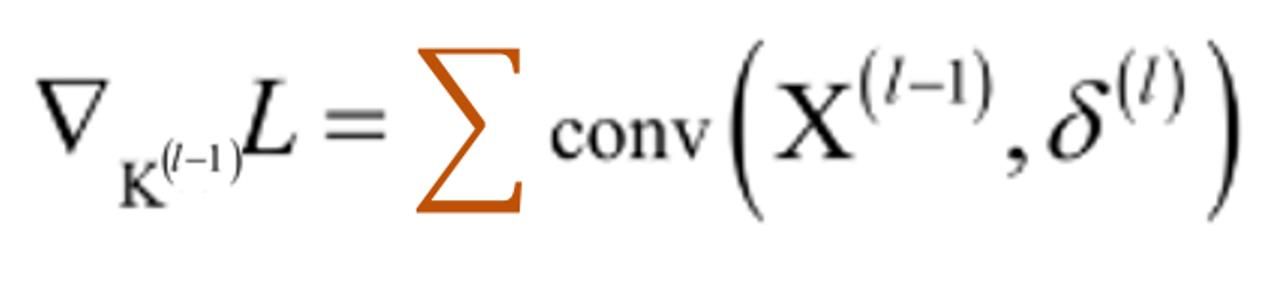

Advanced CNN
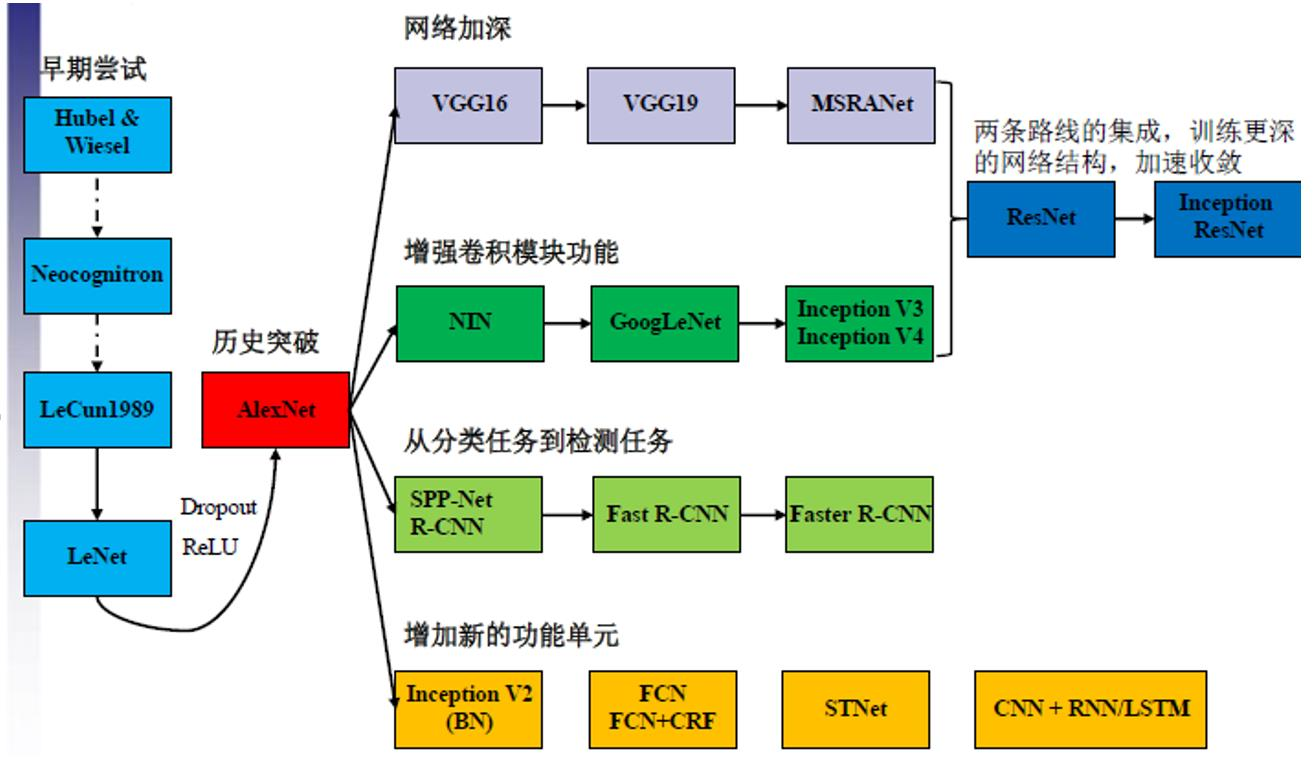
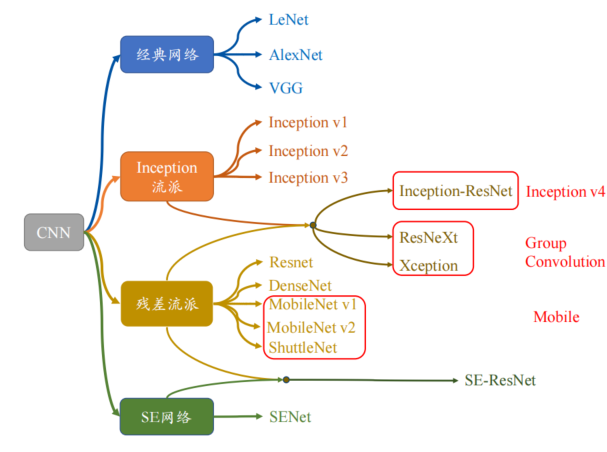
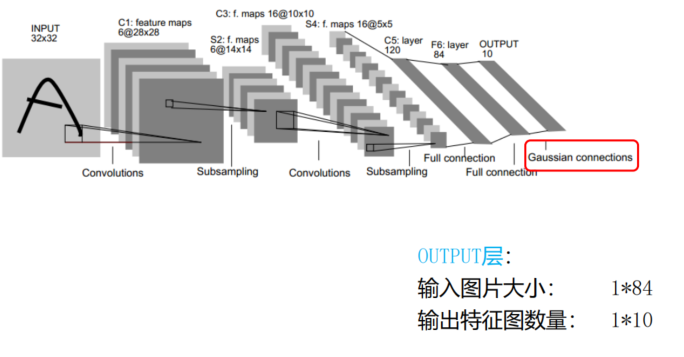
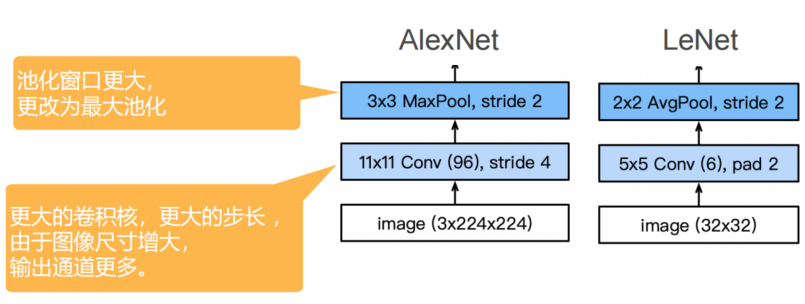
- LeNet
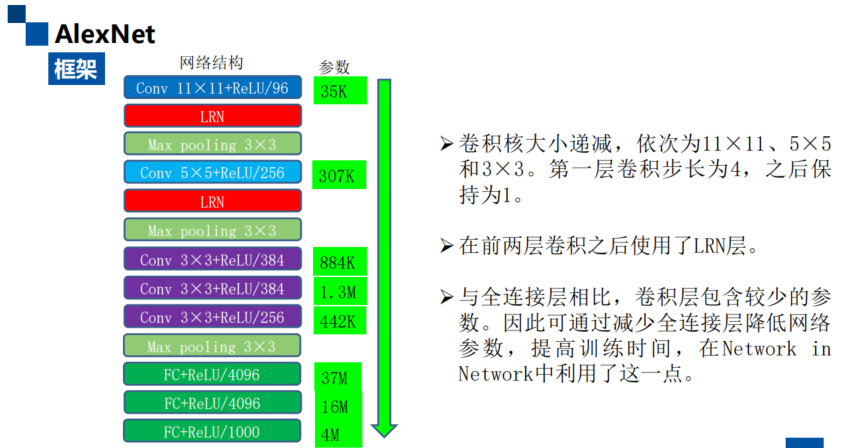
AlexNet
- 修改点:Dropout、Regularization、ReLu激活函数、最大池化法
- 特点:池化窗口更大,跟改为最大池化;更大的卷积核(三个额外的卷积核),更大的步长,由于图像尺寸增大,输出通道更多
LRN
局部响应归一化层(Local Response Normalization)
为什么要引入LRN层?
- 首先要引入一个神经生物学的概念:侧抑制(lateral inhibitio),
即指被激活的神经元抑制相邻的神经元。 - 归一化(normaliazation)的目的就是“抑制”,LRN就是借鉴这种侧抑制来实现局部抑制,尤其是我们使用RELU的时候,这种“侧抑制”很有效 ,因而在alexnet里使用有较好的效果。
归一化有什么好处?
- 归一化有助于快速收敛
- 对局部神经元的活动创建竞争机制,使得其中响应比较大的值变得相对更大,并抑制其他反馈较小的神经元,增强了模型的泛化能力。
VGG
- 比AlexNet更深入更大,以获得更强的特征
- 更多稠密层,更多卷积层(更深更窄更好),分组成块(VGG块重复)
NIN
network in network
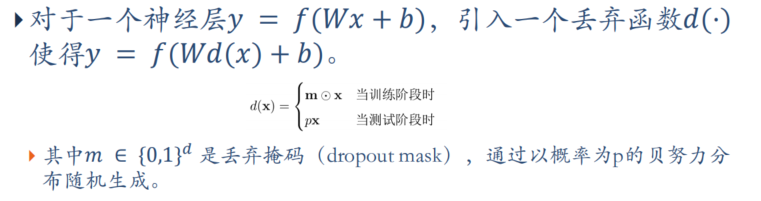
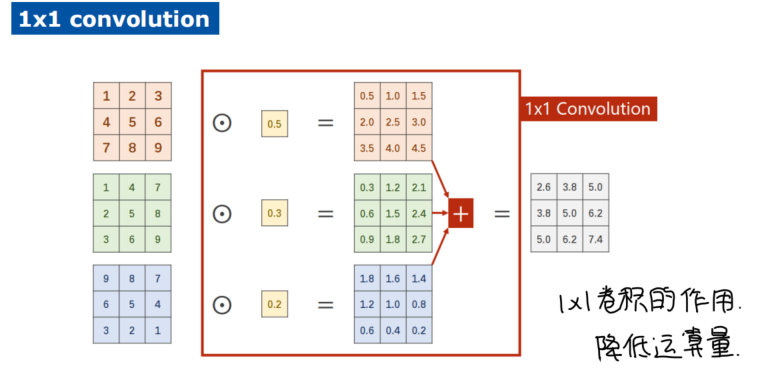
- 在网络层之间加了一个网络,可以控制输出的维度
- maxout节点可以逼近任何凸函数,而NIN节点理论上可以逼近任何函数
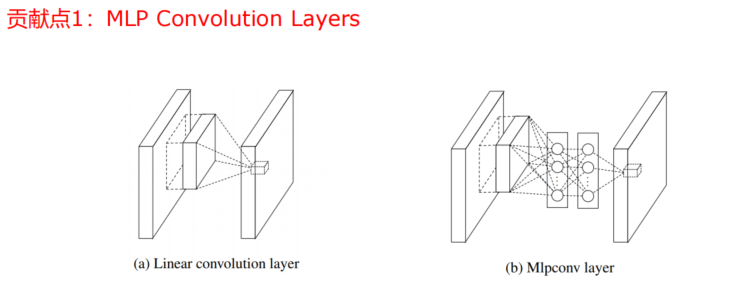
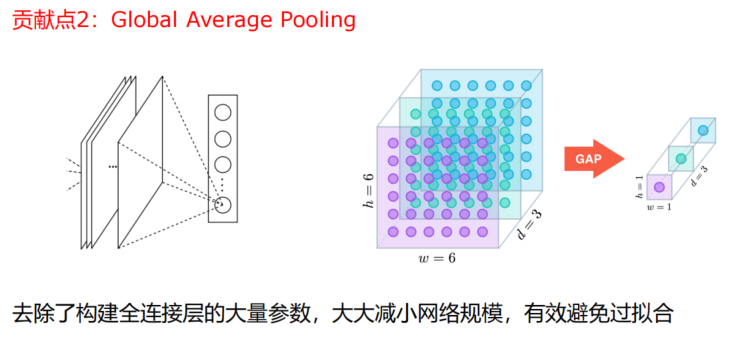
- 意思是直接由卷积层直接输出,不经过全连接层
NIN主要优点:
- 更好的局部抽象能力;
- 更小的参数空间;
- 更小的全局 over-fitting。
GoogleNet
- 5个stage,9个Inception块
Inception块
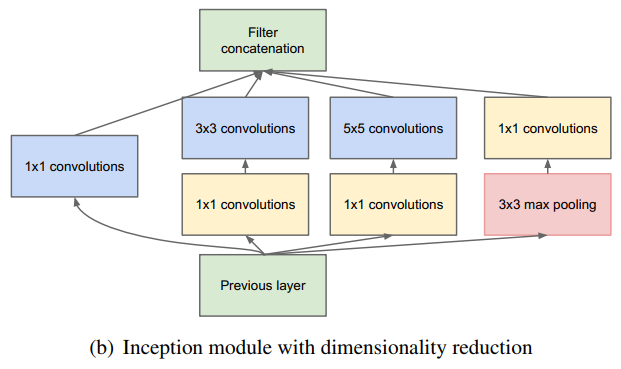
- 与Network in Netwok 类似,GoogLeNet采用子网 络 堆 叠 的 方 式 搭 建 , 每 个 子 网 络 为 一 个Inception 模块
Inception module 包含四个分支:
- Shortcut连接:将前一层输入通过1×1卷积
- 减少网络参数,降低运算量(1x1卷积降维)
- 多尺度,多层次滤波:输入通过1×1卷积之后分别连接卷集核大小为3和5的卷积。
- 多尺度:提高了所学特征的多样性,增强了网络对不同尺度的鲁棒性
- 多层次:符合Hebbian原理,即通过1×1卷积把具有高度相关性的不同通道的滤波结果
进行组合,构建出合理的稀疏结构
- 池化分支:相继连接3×3 pooling和1×1卷积
ResNet
- 残差神经网络要解决什么问题呢?
- 随着网络深度的增加,acc会很快的上升然后下降,但是这个下降并不是因为过拟合,再增加过多的层让网络更深会导致训练误差的增加
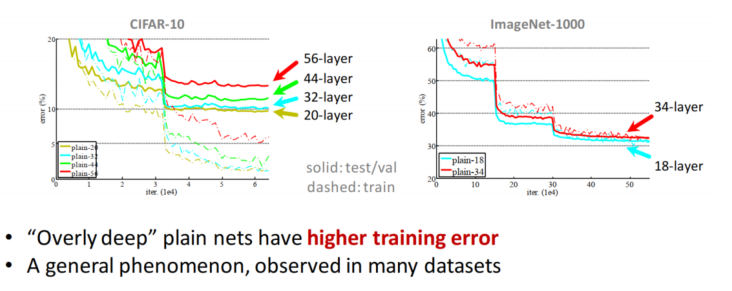
- 解决方案:跳跃连接

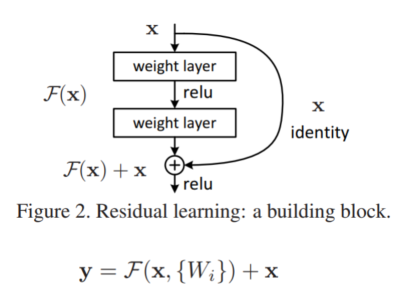

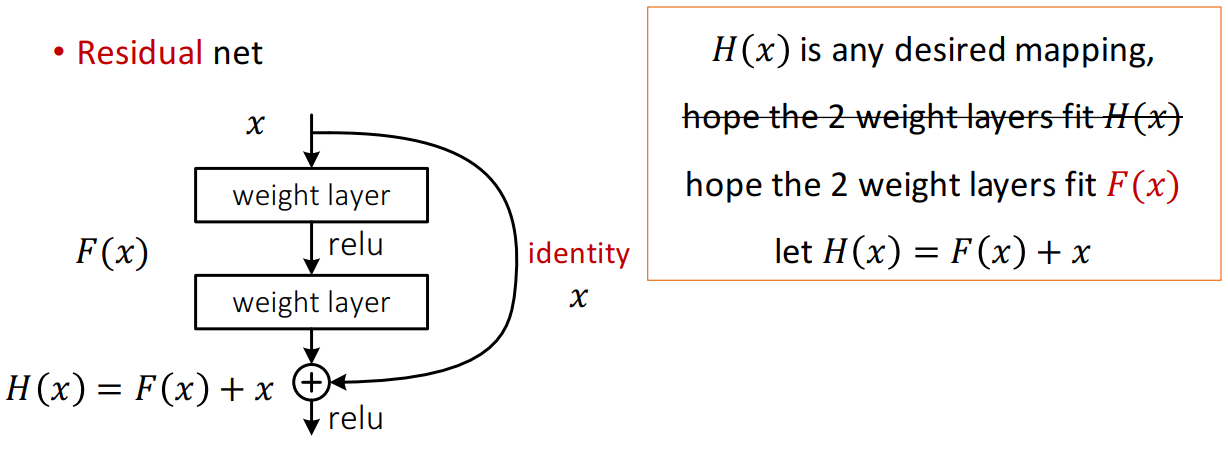
- 这么做的核心思想:将目标函数,由非函数嵌套类转换为函数嵌套类
- 非嵌套函数会远离target(可能是先近后远),嵌套函数不会发生

- 对比之前的,反向传播由连乘,改为连加,更快更有效的传播
引入残差的跳跃连接之后,损失函数更加平滑,why?

- 也就是说,后面每一层都和前面有关系(一般是2~3层,方式是相加)
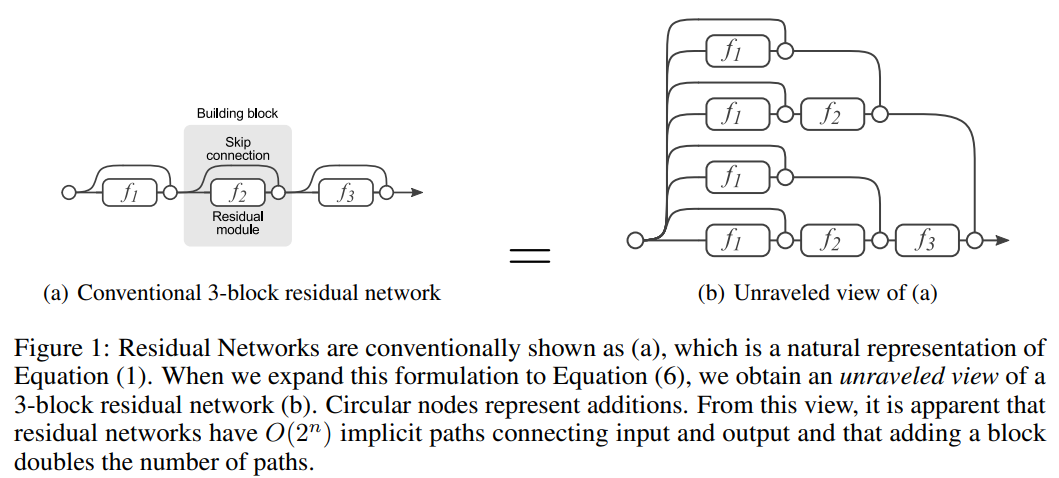
DenseNet
- ResNet是每个层与前面的某层(一般是2~3层)短路连接在一起,连接方式是通过元素级相加。
- DenseNet,每个层都会与前面所有层在channel维度上连接(concat),并作为下一层的输入
- 就是每个通道的特征图之间做纵向拼接
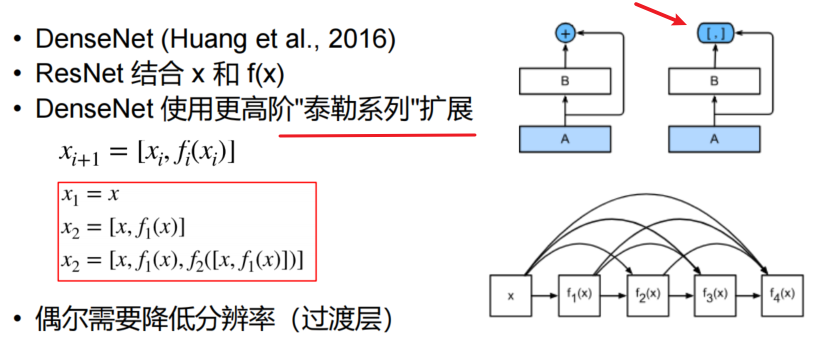
- 就是每个通道的特征图之间做纵向拼接
Light weight CNN
MobileNets
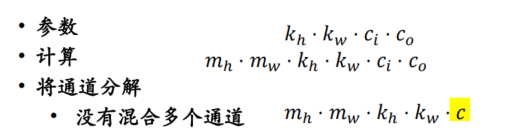
- 常规卷积
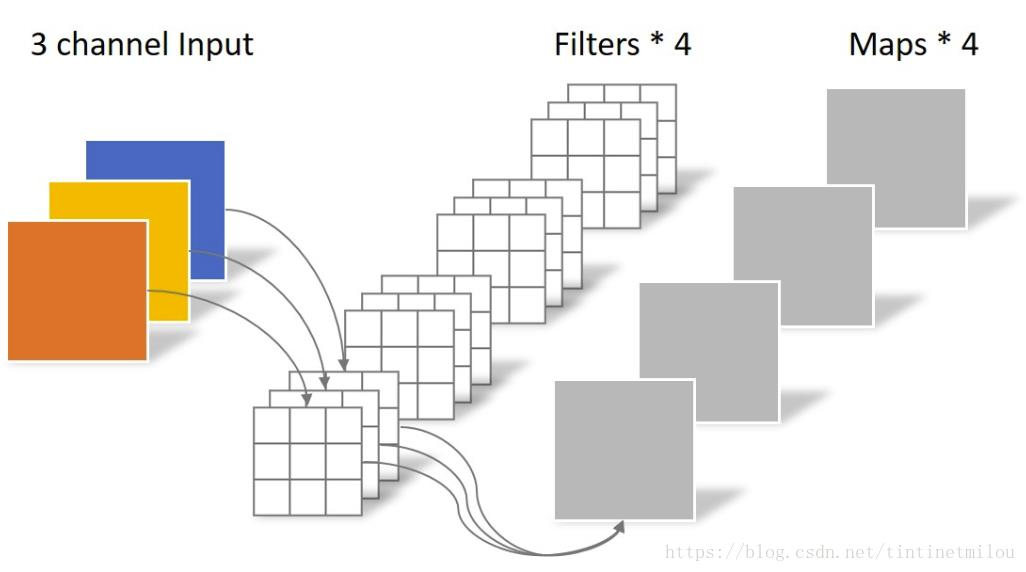
- 深度可分离卷积,先通道分离,再逐点卷积,结合起来
- Xception的核心思想是使用深度可分离卷积来替代传统的卷积操作。深度可分离卷积将卷积操作分为两个步骤:深度卷积和逐点卷积。
- 首先,使用深度卷积在每个输入通道上进行卷积操作,
- 然后使用逐点卷积将不同通道之间的信息进行整合。这种方法可以大大减少模型参数数量和计算量,同时提高模型的准确性和泛化能力。
SE-Net
SE-Net的核心思想是使用Squeeze-and-Excitation(S-E)模块来增强卷积神经网络的表示能力。
在传统的卷积神经网络中,每个卷积层都会学习一些特征,但是这些特征并不是同等重要的,有些特征对于分类任务更加重要,有些特征则不那么重要。
- 因此,SE-Net提出了S-E模块来自适应地学习每个通道的权重,从而增强网络的表示能力。
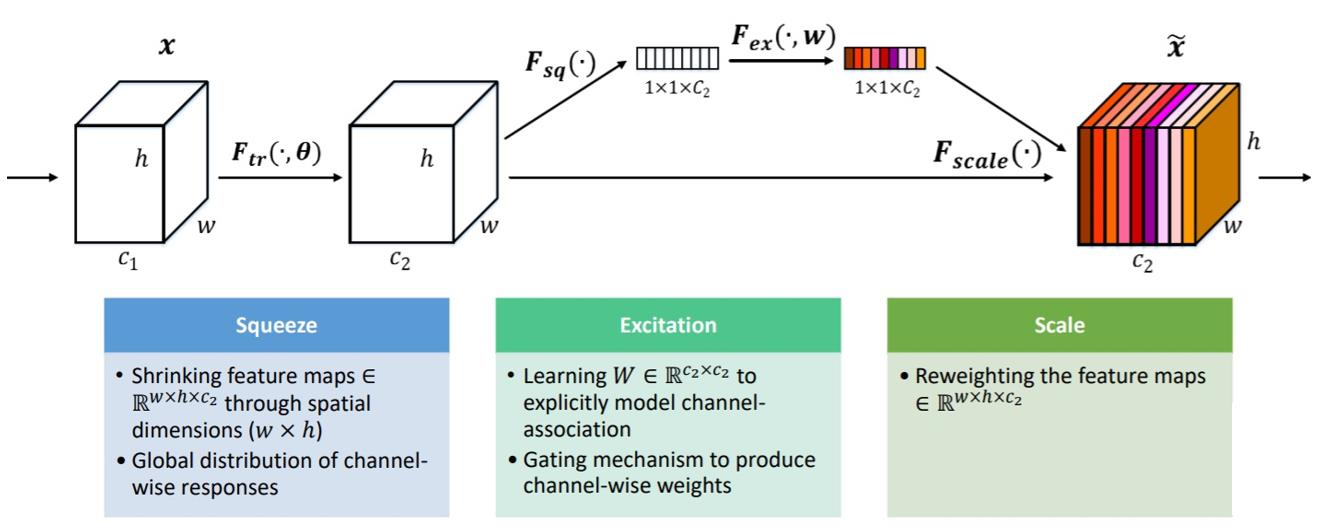
S-E模块包括两个步骤:squeeze和excitation。 - 在squeeze步骤中,通过
全局平均池化操作来压缩每个通道的特征图,得到一个全局特征向量。这个全局特征向量包含了每个通道的全局信息,可以用来表示每个通道的重要性。 - 在excitation步骤中,使用
一个全连接层来学习每个通道的权重,然后使用softmax函数将权重归一化,最后使用这些权重来对每个通道的特征图进行加权求和。这样,S-E模块可以自适应地学习每个通道的重要性,从而增强网络的表示能力。
注意力机制:注意力机制则是通过学习一组权重,来对不同位置的特征图进行加权求和。
注意力机制可以分为两种:空间注意力和通道注意力。
- 空间注意力是通过学习一组权重,来对不同位置的特征图进行加权求和,从而使模型更关注重要的区域。
- 通道注意力则是通过学习一组权重,来对不同通道的特征图进行加权求和,从而增强模型的表示能力。
CondenseNet
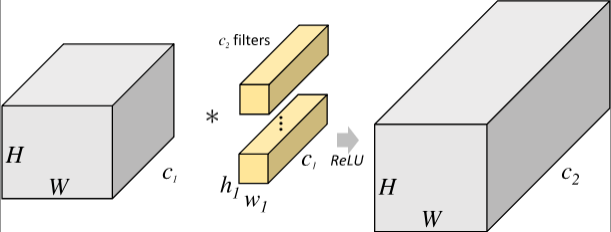
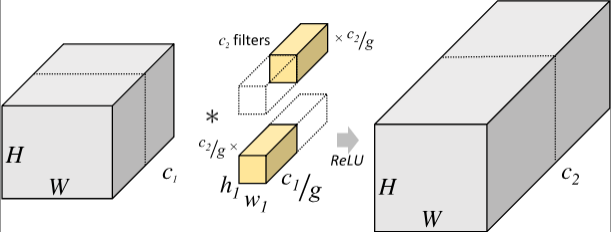
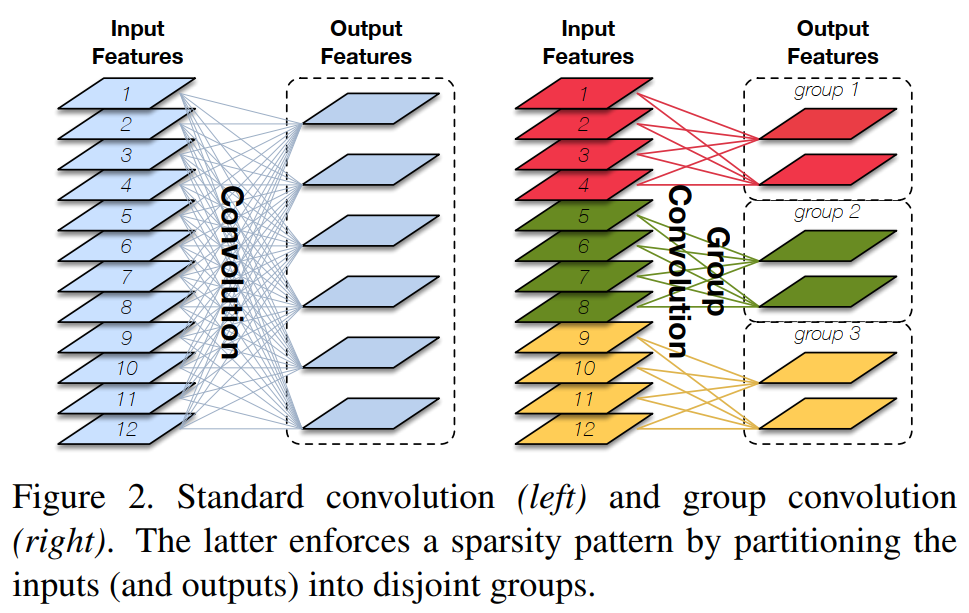
Group Convolution 分组卷积
- 常规卷积
- 分组卷积

EfficientNet
EfficientNet的核心思想是使用复合缩放系数和网络结构搜索来设计高效且准确的卷积神经网络。
具体来说,EfficientNet将网络深度、宽度和分辨率三个维度进行复合缩放,从而得到一系列不同规模的网络。然后,使用网络结构搜索算法来搜索每个规模下的最优网络结构,从而得到高效且准确的卷积神经网络。
在EfficientNet中,网络深度、宽度和分辨率三个维度都是重要的因素。
- 网络深度可以增加模型的表达能力,但会增加模型的计算量和参数数量;
- 网络宽度可以增加模型的特征提取能力,但会增加模型的计算量和参数数量;
- 分辨率可以提高模型对细节的感知能力,但会增加模型的计算量和内存占用。
- 因此,EfficientNet通过复合缩放系数来平衡这三个维度,得到一系列不同规模的网络,从而可以在不同的计算资源限制下,选择适合的网络规模。
EfficientNet还使用网络结构搜索算法来搜索每个规模下的最优网络结构。这个算法可以自动搜索最优的网络结构,从而得到高效且准确的卷积神经网络。这种方法可以大大减少人工设计网络的时间和精力,同时提高模型的准确性和泛化能力。