文章目录
keras
第一章 keras简介
1 简介
Keras是由纯python编写的基于theano/tensorflow的深度学习框架。
Keras是一个高层神经网络API,支持快速实验,能够把你的idea迅速转换为结果,如果有如下需求,可以优先选择Keras:
a)简易和快速的原型设计(keras具有高度模块化,极简,和可扩充特性)
b)支持CNN和RNN,或二者的结合
c)无缝CPU和GPU切换
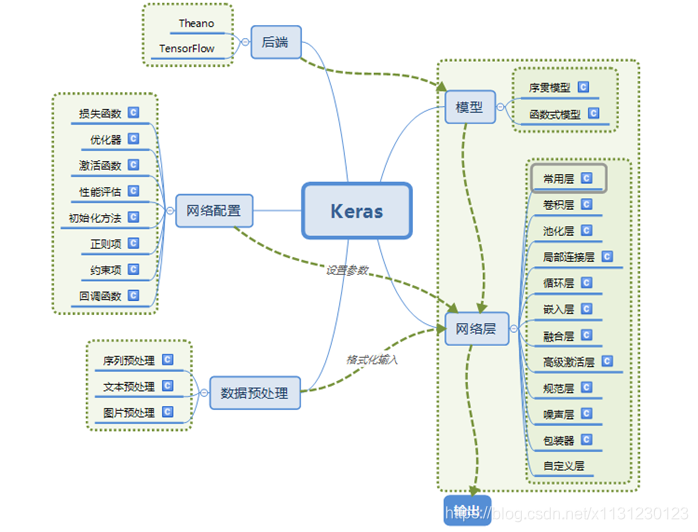
2 搭建神经网络步骤
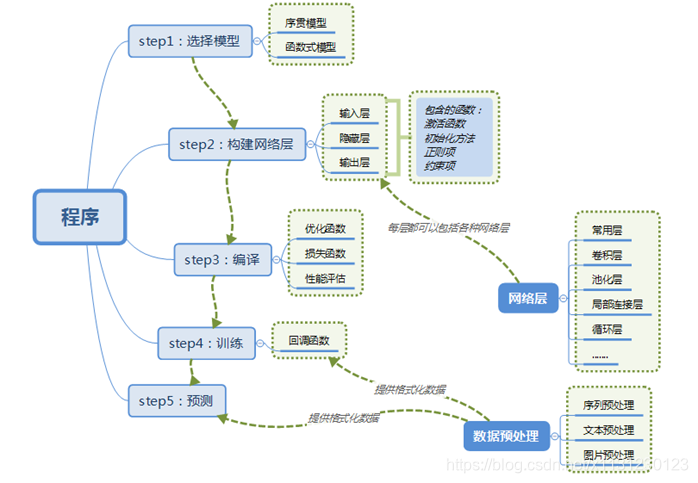
3 数据格式(data_format)
目前主要有两种方式来表示张量:
a) th模式或channels_first模式,Theano和caffe使用此模式。
b)tf模式或channels_last模式,TensorFlow使用此模式。
下面举例说明两种模式的区别:
对于100张RGB3通道的16×32(高为16宽为32)彩色图,
th表示方式:(100,3,16,32)
tf表示方式:(100,16,32,3)
唯一的区别就是表示通道个数3的位置不一样。
4 模型
Keras有两种类型的模型,序贯模型(Sequential)和函数式模型(Model),函数式模型应用更为广泛,序贯模型是函数式模型的一种特殊情况。
a)序贯模型(Sequential):单输入单输出,一条路通到底,层与层之间只有相邻关系,没有跨层连接。这种模型编译速度快,操作也比较简单
b)函数式模型(Model):多输入多输出,层与层之间任意连接。这种模型编译速度慢。
5 keras源码分析
https://www.jianshu.com/p/8dcddbc1c6d4
第二章 多层感知器 DNN
多层感知器(Multi Layer Perceptron)
1、单个神经元
神经网络中计算的基本单元是神经元,一般称作「节点」(node)或者「单元」(unit)。节点从其他节点接收输入,或者从外部源接收输入,然后计算输出。每个输入都辅有「权重」(weight,即 w),权重取决于其他输入的相对重要性。节点将函数 f(定义如下)应用到加权后的输入总和,如图 所示:
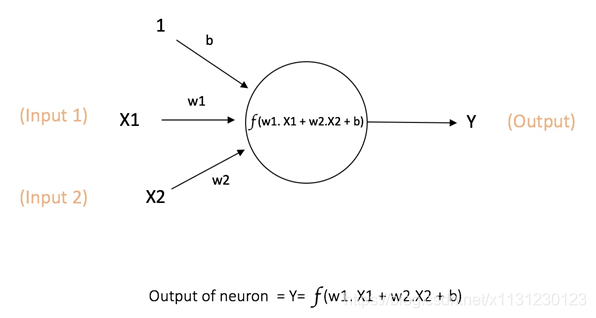
此网络接受 X1 和 X2 的数值输入,其权重分别为 w1 和 w2。另外,还有配有权重 b(称为「偏置(bias)」)的输入 1。我们之后会详细介绍「偏置」的作用。
神经元的输出 Y 如图 1 所示进行计算。函数 f 是非线性的,叫做激活函数。激活函数的作用是将非线性引入神经元的输出。因为大多数现实世界的数据都是非线性的,我们希望神经元能够学习非线性的函数表示,所以这种应用至关重要。
每个(非线性)激活函数都接收一个数字,并进行特定、固定的数学计算 [2]。在实践中,可能会碰到几种激活函数:
• Sigmoid(S 型激活函数):输入一个实值,输出一个 0 至 1 间的值 σ(x) = 1 / (1 + exp(−x))
• tanh(双曲正切函数):输入一个实值,输出一个 [-1,1] 间的值 tanh(x) = 2σ(2x) − 1
• ReLU:ReLU 代表修正线性单元。输出一个实值,并设定 0 的阈值(函数会将负值变为零)f(x) = max(0, x)
偏置的重要性:偏置的主要功能是为每一个节点提供可训练的常量值(在节点接收的正常输入以外)。

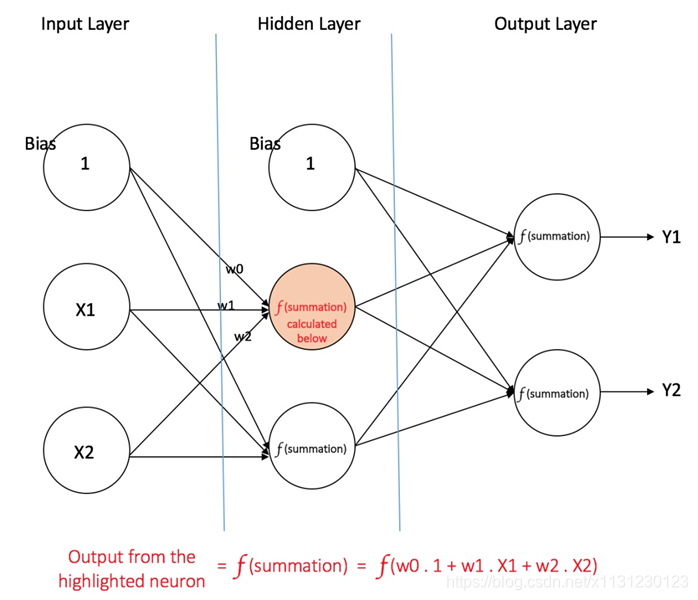
一个前馈神经网络可以包含三种节点:
- 输入节点(Input Nodes):输入节点从外部世界提供信息,总称为「输入层」。在输入节点中,不进行任何的计算——仅向隐藏节点传递信息。
- 隐藏节点(Hidden Nodes):隐藏节点和外部世界没有直接联系(由此得名)。这些节点进行计算,并将信息从输入节点传递到输出节点。隐藏节点总称为「隐藏层」。尽管一个前馈神经网络只有一个输入层和一个输出层,但网络里可以没有也可以有多个隐藏层。
- 输出节点(Output Nodes):输出节点总称为「输出层」,负责计算,并从网络向外部世界传递信息。
在前馈网络中,信息只单向移动——从输入层开始前向移动,然后通过隐藏层(如果有的话),再到输出层。在网络中没有循环或回路 [3](前馈神经网络的这个属性和递归神经网络不同,后者的节点连接构成循环)。
下面是两个前馈神经网络的例子: - 单层感知器——这是最简单的前馈神经网络,不包含任何隐藏层。你可以在 [4] [5] [6] [7] 中了解更多关于单层感知器的知识。
- 多层感知器——多层感知器有至少一个隐藏层。我们在下面会只讨论多层感知器,因为在现在的实际应用中,它们比单层感知器要更有用。
2、多层感知机
多层感知器(Multi Layer Perceptron,即 MLP)包括至少一个隐藏层(除了一个输入层和一个输出层以外)。单层感知器只能学习线性函数,而多层感知器也可以学习非线性函数。
3、怎么训练MLP(BP算法)
最初,所有的边权重(edge weight)都是随机分配的。对于所有训练数据集中的输入,人工神经网络都被激活,并且观察其输出。这些输出会和我们已知的、期望的输出进行比较,误差会「传播」回上一层。该误差会被标注,权重也会被相应的「调整」。该流程重复,直到输出误差低于制定的标准。
(1)前向传播过程,最终计算出误差
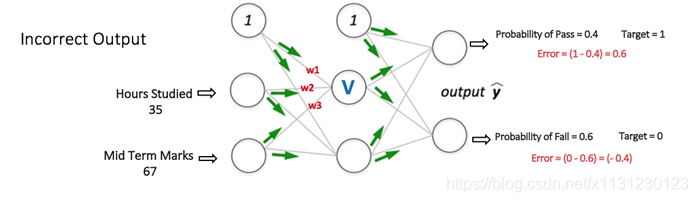
(2)反向传播过程,由误差去更新权重
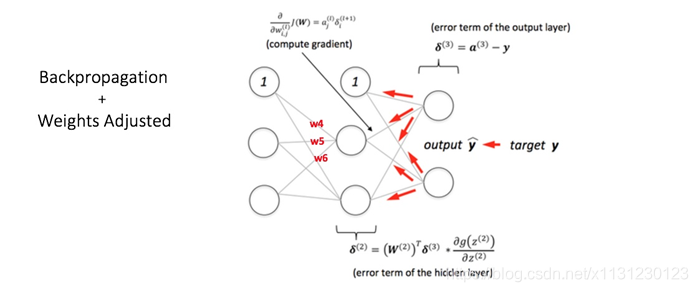
(3)再次前向传播,误差比之前的小

4、反思
(1)需要偏差?
个人觉得,本质上,需要偏差是为了怕数据是0无法训练。
(2)激活函数的意义
添加非线性,让神经网络可以解决非线性问题。
(3)什么是深度学习?
这一章写了 MLP,要想构建MLP去进行图像识别,里面的参数几十亿个,理论可以去做,但是却无法实现出来,因为硬件跟不上,想要进行深度学习,学习到高维度特征,就要找别的办法。
5、使用keras构建MLP
(1)mnist_mlp.py
典型的手写数据集,主要掌握这个步骤。
# -*- coding:utf-8 -*-
'''Trains a simple deep NN on the MNIST dataset.
Gets to 98.40% test accuracy after 20 epochs
(there is *a lot* of margin for parameter tuning).
2 seconds per epoch on a K520 GPU.
'''
from __future__ import print_function
import keras
from keras.datasets import mnist
from keras.models import Sequential
from keras.layers import Dense, Dropout
from keras.optimizers import RMSprop
# batch是一个很关键的量 太大 太小都不行
batch_size = 128
# 表示label的 后面分类用到了
num_classes = 10
# 训练20轮
epochs = 20
# the data, split between train and test sets
# 加载数据
(x_train, y_train), (x_test, y_test) = mnist.load_data()
# 转换格式 数据流必须这么进入CNN
x_train = x_train.reshape(60000, 784)
x_test = x_test.reshape(10000, 784)
# 数据类型的要求
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
# 全都变成0到1之间的数据
x_train /= 255
x_test /= 255
# 60000 train samples
# 10000 test samples
print(x_train.shape, 'train samples')
print(x_test.shape, 'test samples')
# convert class vectors to binary class matrices
# 这个方法会把label全都转变为矩阵 这里就会转成(60000,10)的label矩阵
# 未转变之前的label是: [5 0 4 ... 5 6 8]
# 转变后在对应位置的是1 其余的都是0
y_train = keras.utils.to_categorical(y_train, num_classes)
y_test = keras.utils.to_categorical(y_test, num_classes)
# 构建的序贯模型对象 序贯模型构建十分简单快捷
# 这里构建的是一个多层
model = Sequential()
model.add(Dense(512, activation='relu', input_shape=(784,)))
model.add(Dropout(0.2))
model.add(Dense(512, activation='relu'))
model.add(Dropout(0.2))
model.add(Dense(num_classes, activation='softmax'))
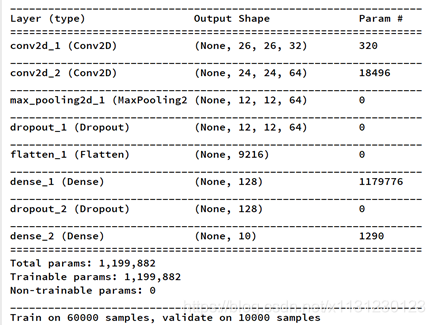
model.summary()
model.compile(loss='categorical_crossentropy',
optimizer=RMSprop(),
metrics=['accuracy'])
history = model.fit(x_train, y_train,
batch_size=batch_size,
epochs=epochs,
verbose=1,
validation_data=(x_test, y_test))
score = model.evaluate(x_test, y_test, verbose=0)
print('Test loss:', score[0])
print('Test accuracy:', score[1])
(2)本次例子中keras注意点
dense方法:
# as first layer in a sequential model:
model = Sequential()
model.add(Dense(32, input_shape=(16,)))
# now the model will take as input arrays of shape (*, 16)
# and output arrays of shape (*, 32)
# after the first layer, you don't need to specify
# the size of the input anymore:
model.add(Dense(32))
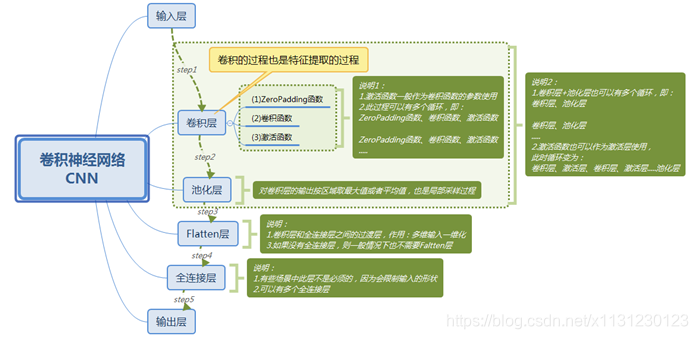
第二章 CNN卷积神经网络
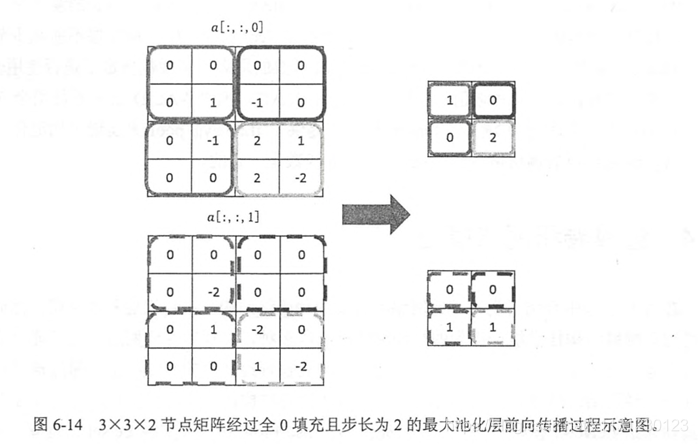
1、CNN理解
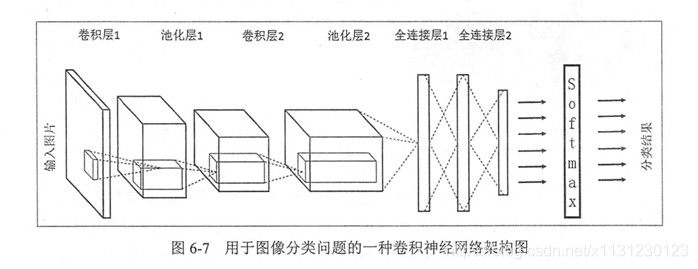


卷积的前向传播
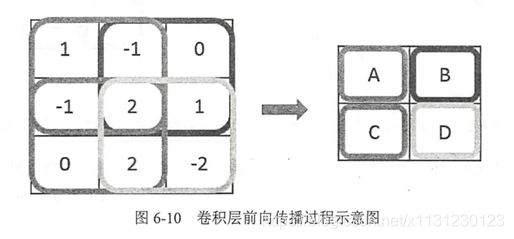
池化
2、LeNet
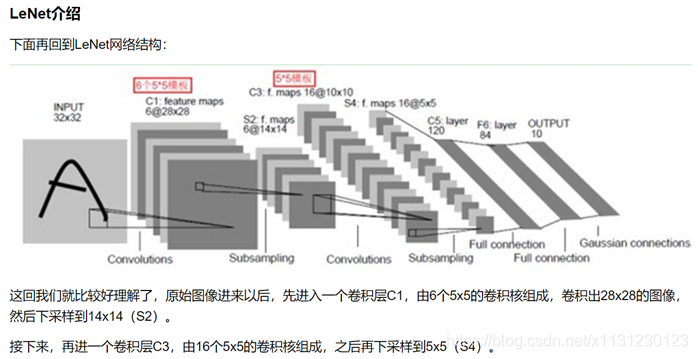



卷积核:一般大小是33或者55,注意卷积后得到的output的shape(还得考虑步长)。
步长: 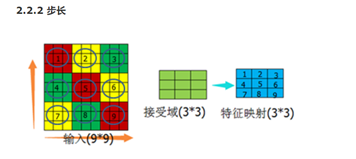
权值共享:如果输入大小32321,过滤器(卷积核)大小为55,不使用0填充,步长为1,如果接下来就是C1卷积层,这一层深度为6,那么这里就有参数 5516+1=156个,每个卷积核的值(权值)和每个卷积核对应的bias是针对一整张图的,所以说权值共享。
稀疏连接:C1层有node个数:62828=4704个,每个node与 input数据有55+1个连接,那么连接个数为470426=122 304 个连接。
3、keras构建CNN
CNN_MNIST.PY
'''Trains a simple convnet on the MNIST dataset.
Gets to 99.25% test accuracy after 12 epochs
(there is still a lot of margin for parameter tuning).
16 seconds per epoch on a GRID K520 GPU.
'''
from __future__ import print_function
import keras
from keras.datasets import mnist
from keras.models import Sequential
from keras.layers import Dense, Dropout, Flatten
from keras.layers import Conv2D, MaxPooling2D
from keras import backend as K
batch_size = 1024
num_classes = 10
epochs = 1
# input image dimensions
img_rows, img_cols = 28, 28
# the data, split between train and test sets
(x_train, y_train), (x_test, y_test) = mnist.load_data()
if K.image_data_format() == 'channels_first':
x_train = x_train.reshape(x_train.shape[0], 1, img_rows, img_cols)
x_test = x_test.reshape(x_test.shape[0], 1, img_rows, img_cols)
input_shape = (1, img_rows, img_cols)
else:
x_train = x_train.reshape(x_train.shape[0], img_rows, img_cols, 1)
x_test = x_test.reshape(x_test.shape[0], img_rows, img_cols, 1)
input_shape = (img_rows, img_cols, 1)
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
x_train /= 255
x_test /= 255
print('x_train shape:', x_train.shape)
print(x_train.shape[0], 'train samples')
print(x_test.shape[0], 'test samples')
# convert class vectors to binary class matrices
y_train = keras.utils.to_categorical(y_train, num_classes)
y_test = keras.utils.to_categorical(y_test, num_classes)
model = Sequential()
model.add(Conv2D(32, kernel_size=(3, 3),
activation='relu',
input_shape=input_shape))
model.add(Conv2D(64, (3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(num_classes, activation='softmax'))
model.compile(loss=keras.losses.categorical_crossentropy,
optimizer=keras.optimizers.Adadelta(),
metrics=['accuracy'])
model.fit(x_train, y_train,
batch_size=batch_size,
epochs=epochs,
verbose=1,
validation_data=(x_test, y_test))
score = model.evaluate(x_test, y_test, verbose=0)
print('Test loss:', score[0])
print('Test accuracy:', score[1])
输入图片是2828,在conv2d_1中,卷积核33,所以得到的图是2626的,设置深度为32,那么一共有参数33*32+32=320个。
第三章 RNN循环神经网络
1、RNN简介
https://zhuanlan.zhihu.com/p/28054589
(1)单层网络
输入是x,经过变换Wx+b和激活函数f得到输出y。
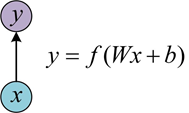
(2) 经典的RNN n个输入n个输出
如:
自然语言处理问题。x1可以看做是第一个单词,x2可以看做是第二个单词,依次类推。
语音处理。此时,x1、x2、x3……是每帧的声音信号。
时间序列问题。例如每天的股票价格等等
序列形的数据就不太好用原始的神经网络处理了。为了建模序列问题,RNN引入了隐状态h(hidden state)的概念,h可以对序列形的数据提取特征,接着再转换为输出。先从h1的计算开始看:
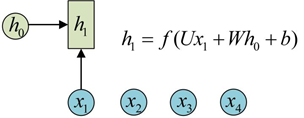
图示中记号的含义是:
圆圈或方块表示的是向量。
一个箭头就表示对该向量做一次变换。如上图中h0和x1分别有一个箭头连接,就表示对h0和x1各做了一次变换。
在很多论文中也会出现类似的记号,初学的时候很容易搞乱,但只要把握住以上两点,就可以比较轻松地理解图示背后的含义。
h2的计算和h1类似。要注意的是,在计算时,每一步使用的参数U、W、b都是一样的,也就是说每个步骤的参数都是共享的,这是RNN的重要特点,一定要牢记。
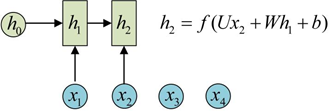
怎么得到输出?得到输出值的方法就是直接通过h进行计算:
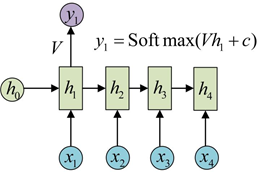
使用同样的V和c得到所有的输出:
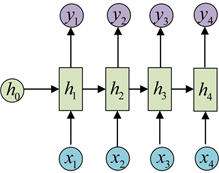
由于这个限制的存在,经典RNN的适用范围比较小,但也有一些问题适合用经典的RNN结构建模,如:
计算视频中每一帧的分类标签。因为要对每一帧进行计算,因此输入和输出序列等长。
输入为字符,输出为下一个字符的概率。这就是著名的Char RNN(详细介绍请参考:The Unreasonable Effectiveness of Recurrent Neural Networks,Char RNN可以用来生成文章,诗歌,甚至是代码,非常有意思)。
(3)n个输入1个输出
实际上,我们只在最后一个h上进行输出变换就可以了。这种结构通常用来处理序列分类问题。如输入一段文字判别它所属的类别,输入一个句子判断其情感倾向,输入一段视频并判断它的类别等等。
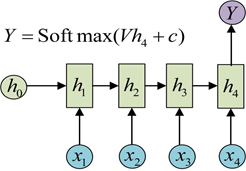
(4)1个输入n个输出
这种1 VS N的结构可以处理的问题有:
从图像生成文字(image caption),此时输入的X就是图像的特征,而输出的y序列就是一段句子
从类别生成语音或音乐等
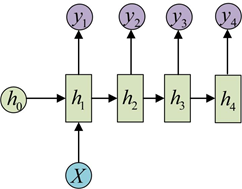
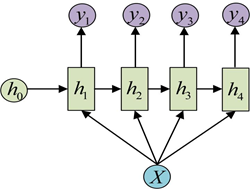
(5) n个输入m个输出 Encoder-Decoder模型 Seq2Seq模型
下面我们来介绍RNN最重要的一个变种:N vs M。这种结构又叫Encoder-Decoder模型,也可以称之为Seq2Seq模型。
原始的N vs N RNN要求序列等长,然而我们遇到的大部分问题序列都是不等长的,如机器翻译中,源语言和目标语言的句子往往并没有相同的长度。
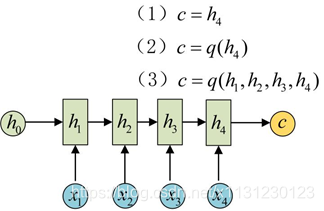
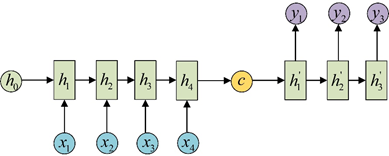
为此,Encoder-Decoder结构先将输入数据编码成一个上下文向量c:
得到c有多种方式,最简单的方法就是把Encoder的最后一个隐状态赋值给c,还可以对最后的隐状态做一个变换得到c,也可以对所有的隐状态做变换。
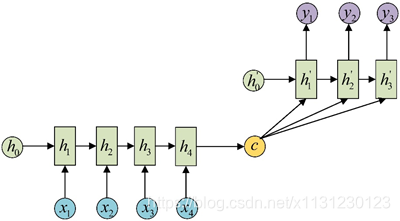
拿到c之后,就用另一个RNN网络对其进行解码,这部分RNN网络被称为Decoder。具体做法就是将c当做之前的初始状态h0输入到Decoder中:
由于这种Encoder-Decoder结构不限制输入和输出的序列长度,因此应用的范围非常广泛,比如:
机器翻译。Encoder-Decoder的最经典应用,事实上这一结构就是在机器翻译领域最先提出的
文本摘要。输入是一段文本序列,输出是这段文本序列的摘要序列。
阅读理解。将输入的文章和问题分别编码,再对其进行解码得到问题的答案。
语音识别。输入是语音信号序列,输出是文字序列。
…………
(6)Attention机制
在Encoder-Decoder结构中,Encoder把所有的输入序列都编码成一个统一的语义特征c再解码,因此, c中必须包含原始序列中的所有信息,它的长度就成了限制模型性能的瓶颈。如机器翻译问题,当要翻译的句子较长时,一个c可能存不下那么多信息,就会造成翻译精度的下降。
Attention机制通过在每个时间输入不同的c来解决这个问题,下图是带有Attention机制的Decoder:
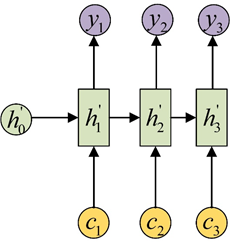

2、RNN 的推导
(1)经典模型(还有其他形式)
每一个时间的输出不仅仅与当前的输入有关,还和以前的隐藏层有关。
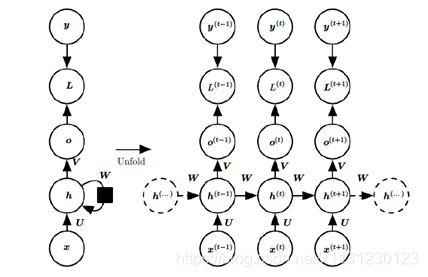
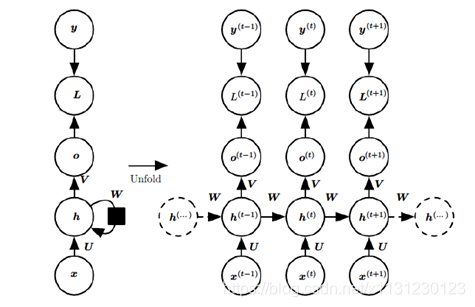
上图中左边是RNN模型没有按时间展开的图,如果按时间序列展开,则是上图中的右边部分。我们重点观察右边部分的图。
这幅图描述了在序列索引号tt附近RNN的模型。其中:
1)x(t)x(t)代表在序列索引号tt时训练样本的输入。同样的,x(t−1)x(t−1)和x(t+1)x(t+1)代表在序列索引号t−1t−1和t+1t+1时训练样本的输入。
2)h(t)h(t)代表在序列索引号tt时模型的隐藏状态。h(t)h(t)由x(t)x(t)和h(t−1)h(t−1)共同决定。
3)o(t)o(t)代表在序列索引号tt时模型的输出。o(t)o(t)只由模型当前的隐藏状态h(t)h(t)决定。
4)L(t)L(t)代表在序列索引号tt时模型的损失函数。
5)y(t)y(t)代表在序列索引号tt时训练样本序列的真实输出。
6)U,W,VU,W,V这三个矩阵是我们的模型的线性关系参数,它在整个RNN网络中是共享的,这点和DNN很不相同。 也正因为是共享了,它体现了RNN的模型的“循环反馈”的思想。
(2)RNN的前向传播

(3)RNN反向传播


(4)小结
上面总结了通用的RNN模型和前向反向传播算法。当然,有些RNN模型会有些不同,自然前向反向传播的公式会有些不一样,但是原理基本类似。
RNN虽然理论上可以很漂亮的解决序列数据的训练,但是它也像DNN一样有梯度消失时的问题,当序列很长的时候问题尤其严重。因此,上面的RNN模型一般不能直接用于应用领域。在语音识别,手写书别以及机器翻译等NLP领域实际应用比较广泛的是基于RNN模型的一个特例LSTM
3、RNN的其他形式
有必要看一下RNN的其他形式。
循环链接是从输出o到隐藏层h。没有上面的h到h模型强大。o作为输出,除非维度很高,否则会损失一部分h的信息。没有直接的循环链接,而只是间接的将h信息传递到下一层。但其易于训练,可以并行化训练。
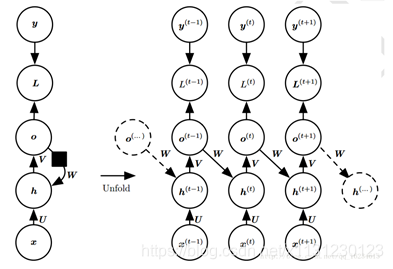
就是将输出作为循环链接。由于时间步的解耦,可以并行训练,使用导师驱动过程进行训练。
上图训练时标记y作为循环链接输入,测试时使用输出o作为循环链接输入。
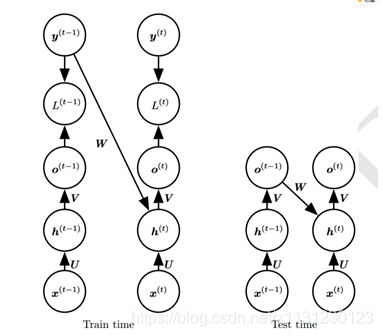
这里还有更多变体,不知何用
https://blog.csdn.net/qq_16234613/article/details/79476763
4、RNN 存在梯度消失和爆炸的原因
https://zhuanlan.zhihu.com/p/28687529
https://zhuanlan.zhihu.com/p/28749444
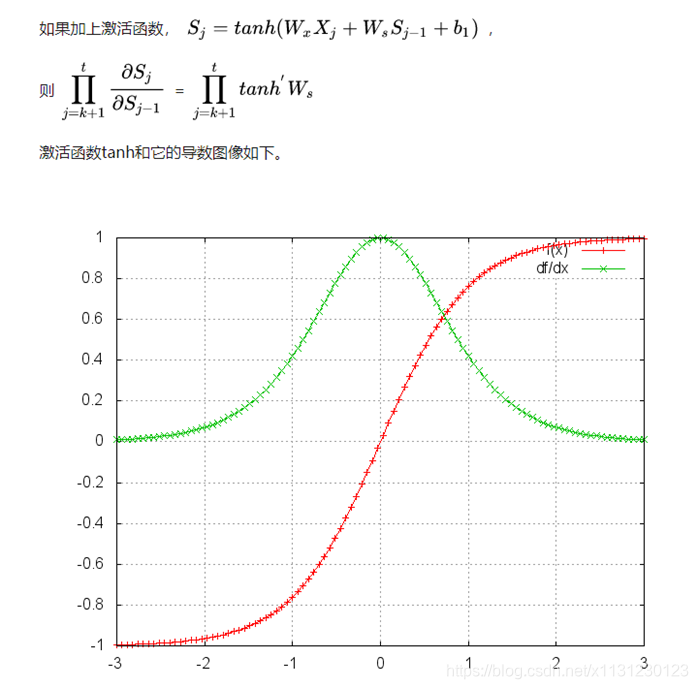

第四章 RNN特例 LSTM
1、从RNN到LSTM
RNN结构如下,共享参数矩阵U、V、W。
忽略去输出o、损失L、实际输出y,RNN结构如下:


一般的RNN会出现问题,大牛们改进了RNN结构,LSTM有很多的变种,这里说一种最常用的LSTM。
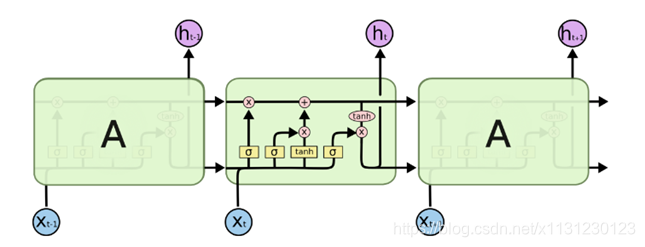
2、剖析LSTM结构
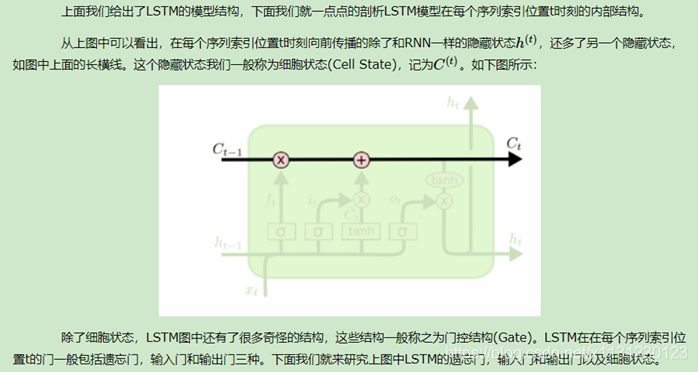
2.1 遗忘门

2.2 输入门
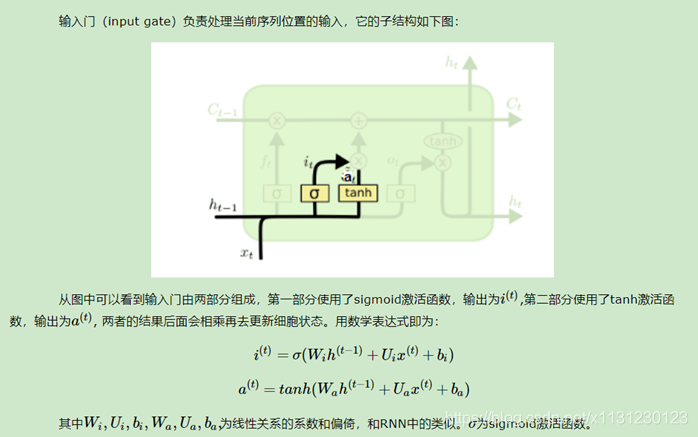
2.3 细胞状态更新
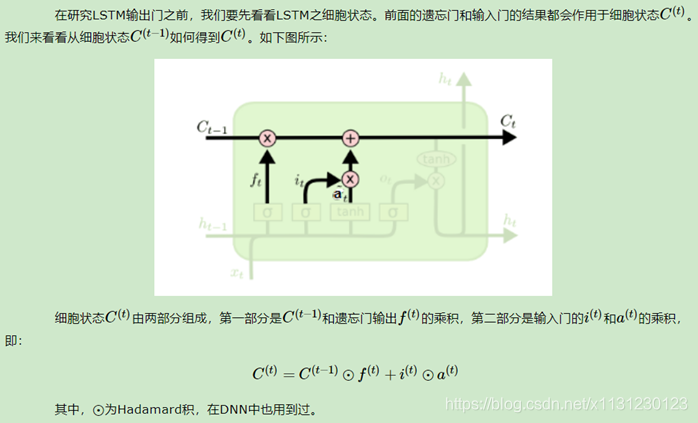
2.4 输出门
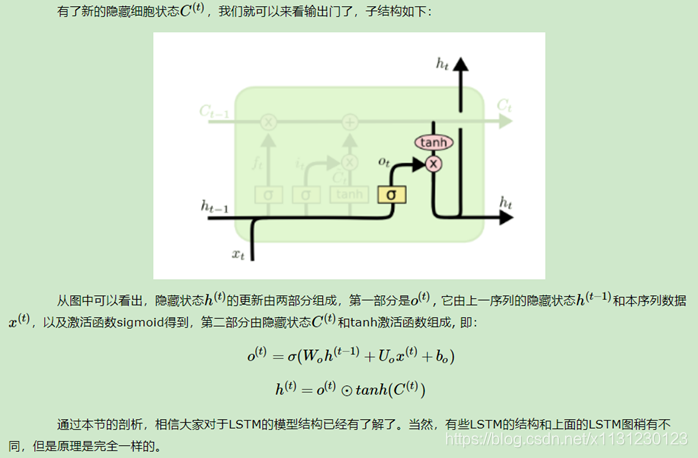
3、前向传播算法

4、反向传播算法


第五章 受限玻尔兹曼机 RBM
1、简介
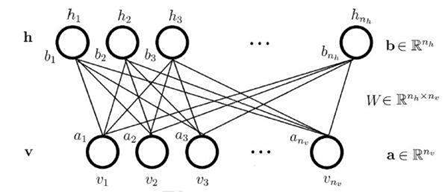
RBM能提取特征并且重构输入。
RBM的关键词是双向,偏差不同,被训练来做双向的,比如翻译,翻译了之后又重构回去。所以训练有三步:一是由输入正向传导得到输出,二是反向重建回原数据,三是由KL散度,改变权重和偏差,直到输入与重建尽可能接近。RBM的数据不需要被标记,对真实世界的数据集,比如照片、时佩璞、语音、传感器数据非常重要,所有这些数据都是未标记的,不要人为标记,RBM自动排序数据,并通过适当调整权重和偏差,RBM能够提取到重要特征和重建输入。RBM能决定哪个输入的特征是重要的,并且他们应该如何组合为格式化模式,也就是说,RBM是特征提取器神经网络的一部分。其全部被设计用于识别数据中的固有模式,这些网络也成为自动编码器,因为在某种程度上,他们必须编码自己的结构。
第六章 深度信念网络 DBM
1、简介
DBM在结构上和传统的MPL相似,但是训练方法完全不同。DBM可以当成多个RBM的堆叠,首先训练第一个RBM(即是图里的第一层和第二层),让其尽可能提取特征并重构输入,然后使用训练好的第一个RBM的输出作为第二个RBM的输入,以此训练第二个RBM。重复这个过程,直到所有层训练完毕。DBM是在逐渐优化全局的一个识别,对比CNN,CNN的前几层网络是在提取图片边缘特征,后面几层是在组合图片特征形成最终的特征。随着DBM模型的逐渐改进,就像一个相机镜头逐渐聚焦图片。
训练好之后,我们得到的一个能提取固有模式的模型,此时需要引入一个带label的小数据集,像监督学习一样引导整个网络。这对于现实很重要,因为带有label的只是一小部分数据集。

第七章 蒙特卡罗方法 马尔可夫链
1、蒙特卡罗方法
蒙特卡罗法在求定积分时候的应用:
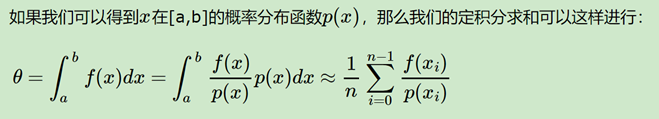

关键点在于概率分布函数p(x),计算机对于简单分布函数是有随机的,但对于复杂的概率分布函数,怎么去采样得到这个样本集呢? 提出 接受-拒绝采样。


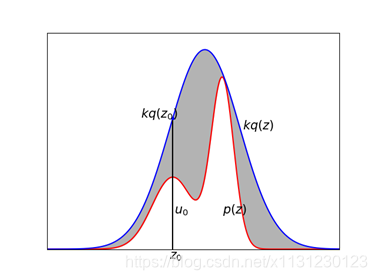
import numpy as np
import matplotlib.pyplot as plt
def f1(x):
return 0.3*np.exp(-(x-0.3)**2) + 0.7* np.exp(-(x-2.)**2/0.3)
def f2(x):
sigma =1.2
return 3/(np.sqrt(2*np.pi)*sigma**2)*np.exp(-0.5*(x-1.4)**2/sigma**2)
x = np.arange(-4.,6.,0.01)
plt.plot(x,f1(x),color = "red")
plt.plot(x,f2(x),color = "blue")
plt.xticks([])
plt.yticks([])
plt.ylim(0,0.9)
plt.xlim(-4,6)
plt.plot([0.3,0.3],[0,0.54601532],color = "black")
plt.plot(0.3,0.54601532,'b.')
plt.fill_between(x,f1(x),f2(x),color = (0.7,0.7,0.7))
plt.annotate('$z_0$',xy=(0.,0),xytext=(0.2,-0.04),fontsize=15)
plt.annotate('$u_0$',xy=(0.,0.),xytext=(0.35,0.15),fontsize=15)
plt.annotate('$kq(z_0)$',xy=(0.,0.),xytext=(-0.8,0.55),fontsize=15)
plt.annotate('$p(z)$',xy=(0.,0.),xytext=(2,0.15),fontsize=15)
plt.annotate('$kq(z)$',xy=(0.,0.),xytext=(2.7,0.5),fontsize=15)
plt.show()
import numpy as np
import matplotlib.pyplot as plt
size = 10000000
z = np.random.normal(loc = 1.4,scale = 1.2, size = size)
sigma = 1.2
qz = 1/(np.sqrt(2*np.pi)*sigma**2)*np.exp(-0.5*(z-1.4)**2/sigma**2)
k = 3
u = np.random.uniform(low = 0, high = k*qz, size = size)
pz = 0.3*np.exp(-(z-0.3)**2) + 0.7* np.exp(-(z-2.)**2/0.3)
sample = z[pz >= u]
plt.hist(sample,bins=150,normed = True)
plt.show()
2、马尔可夫链
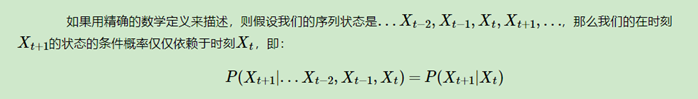
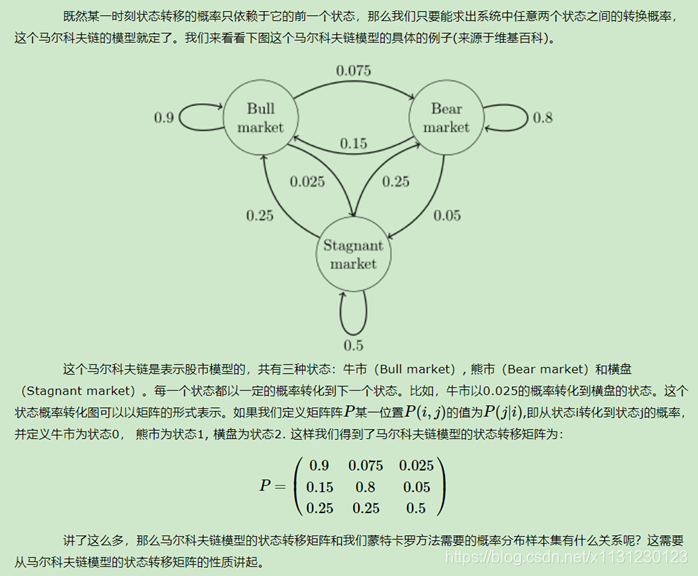
这个性质其实就是矩阵特征值的幂法(数值分析)求主特征值和对应特征向量的一个方法。
马尔可夫链采样:
如果假定我们可以得到我们需要采样样本的平稳分布所对应的马尔科夫链状态转移矩阵,那么我们就可以用马尔科夫链采样得到我们需要的样本集,进而进行蒙特卡罗模拟。但是一个重要的问题是,随意给定一个平稳分布ππ,如何得到它所对应的马尔科夫链状态转移矩阵P呢?这是个大问题。我们绕了一圈似乎还是没有解决任意概率分布采样样本集的问题。
幸运的是,MCMC采样通过迂回的方式解决了上面这个大问题,我们在下一篇来讨论MCMC的采样,以及它的使用改进版采样: M-H采样和Gibbs采样.
3、MCMC采样 M-H采样
http://www.cnblogs.com/pinard/p/6638955.html
马尔可夫链的细致平稳条件:






4、Gibbs采样
http://www.cnblogs.com/pinard/p/6645766.html
第八章 递归神经网络 RNTN
附录 python工具
1、# -- coding:utf-8 --
2、keras中7大数据集datasets介绍
https://blog.csdn.net/weixin_41770169/article/details/80249986
3、关于keras模型中常用的方法
• model.summary():打印出模型概况,它实际调用的是keras.utils.print_summary
(这个方法算是简单的可视化了,十分方便)
• model.get_config():返回包含模型配置信息的Python字典。模型也可以从它的config信息中重构回去
config = model.get_config()
model = Model.from_config(config)
#or, for Sequential:
model = Sequential.from_config(config)
• model.get_layer():依据层名或下标获得层对象
• model.get_weights():返回模型权重张量的列表,类型为numpy array
• model.set_weights():从numpy array里将权重载入给模型,要求数组具有与model.get_weights()相同的形状。
• model.to_json:返回代表模型的JSON字符串,仅包含网络结构,不包含权值。可以从JSON字符串中重构原模型:
from models import model_from_json
json_string = model.to_json()
model = model_from_json(json_string)
• model.to_yaml:与model.to_json类似,同样可以从产生的YAML字符串中重构模型
from models import model_from_yaml
yaml_string = model.to_yaml()
model = model_from_yaml(yaml_string)
• model.save_weights(filepath):将模型权重保存到指定路径,文件类型是HDF5(后缀是.h5)
• model.load_weights(filepath, by_name=False):从HDF5文件中加载权重到当前模型中, 默认情况下模型的结构将保持不变。如果想将权重载入不同的模型(有些层相同)中,则设置by_name=True,只有名字匹配的层才会载入权重
4、序贯模型Sequential
指定输入数据的shape
模型需要知道输入数据的shape,因此,Sequential的第一层需要接受一个关于输入数据shape的参数,后面的各个层则可以自动的推导出中间数据的shape,因此不需要为每个层都指定这个参数。有几种方法来为第一层指定输入数据的shape
• 传递一个input_shape的关键字参数给第一层,input_shape是一个tuple类型的数据,其中也可以填入None,如果填入None则表示此位置可能是任何正整数。数据的batch大小不应包含在其中。
• 有些2D层,如Dense,支持通过指定其输入维度input_dim来隐含的指定输入数据shape,是一个Int类型的数据。一些3D的时域层支持通过参数input_dim和input_length来指定输入shape。
• 如果你需要为输入指定一个固定大小的batch_size(常用于stateful RNN网络),可以传递batch_size参数到一个层中,例如你想指定输入张量的batch大小是32,数据shape是(6,8),则你需要传递batch_size=32和input_shape=(6,8)。
model = Sequential()
model.add(Dense(32, input_dim=784))
model = Sequential()
model.add(Dense(32, input_shape=(784,)))
5、pillow 图片处理
https://www.cnblogs.com/chimeiwangliang/p/7130434.html
附录 学习中的想法
1、神经网络的本质
个人理解,其实不管卷积网络还是神经网络,本质是都是对原始数据集分布进行特征映射,将原始比较乱的数据分布,根据标记映射到另一个比较易于区分的分布上。从而实现可分性。
2、深度学习如何使用
对于未标记数据,想进行的无非是特征提取、无监督学习、模式识别,可以采用RBM或者自动编码器。
对于已有标记的数据,针对于不同任务,有不同的选择。
文本处理任务:如情感分析,解析和明明实体识别,使用递归网路或递归神经网络(RNTN),对于在字符级别操作的任何语言模型,使用递归网络。
图像识别任务:使用深度信念网络或卷积网络。
对象识别任务:使用卷积网络或者RNTN。
语音识别任务:递归网路。
