什么时候用到CNN?
CNN的出现是由观察图片的这三点特征得出的:
1)图片中需要识别的图案(pattern)远小于整张图片,因此我们不需要遍历整张图片去找出这个图案;
2)同样的图案可能出现在不同的位置,但它们的性质是一样的,因此可以采用相同的参数;
3)对一张图片的像素点采用下采样的方式不改变整体检测目标
根据这三个特征,我们就得到了CNN的实现框图:
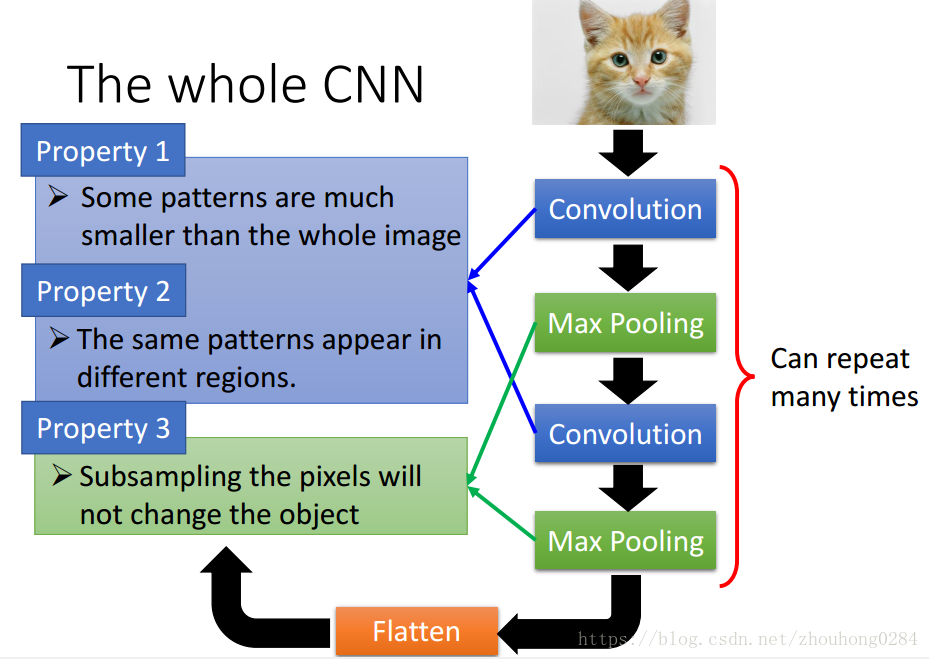
原理
CNN是DNN的一种简单实现。
卷积过程实际上就是一层神经网络的实现,优点是:
1.它利用卷积实现更少的参数构建,
2.利用位移实现参数共享,使得需要的参数更少
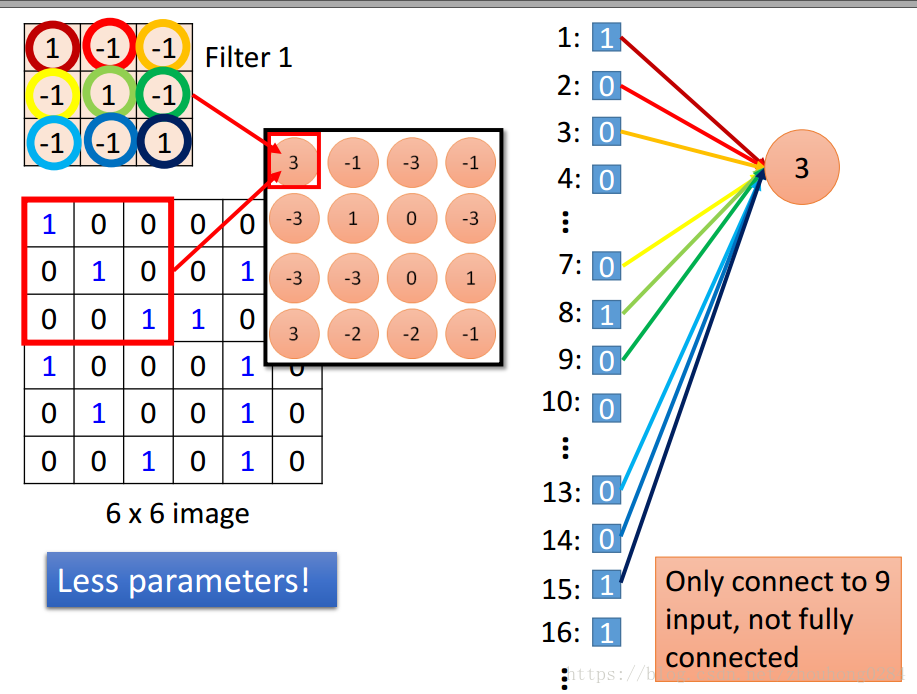
利用k个filter对图片做卷积之后,形成的k维矩阵(tensor)就是一个feature map,每一维都称为一个channel.
max pooling过程对应图片的第三个特征:下采样。我们通过一定size的框来选出这个框中最大的数值,也就是最明显的特征。
整个框架在Keras中的步骤是:
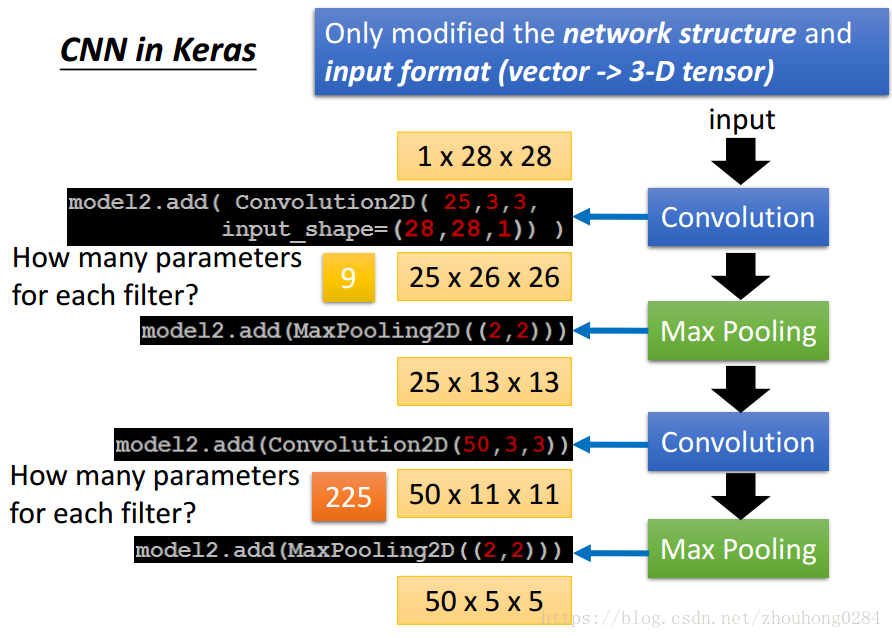
注意看图中flter的参数数量以及处理后的图片参数信息量。
CNN的更多应用
语音分析:将语音转换为频谱之后,频谱图像就是一个输入,当利用卷积做处理时,注意filter单元只在频谱方向移动,因为时间序列的处理在后期的fully connected NN中会被处理。
文本分析:将每个单词用一个特定的矢量来表示,将这个矢量作为一个图像输入进行分析,此时的filter只在时间序列上移动,因为每个矢量在上下维度具有独特性,不会发现相同的pattern。
深度学习书
卷积计算通过三个重要的思想来帮助改进机器学习系统:系数交互,参数共享,等变表示。
稀疏交互为什么有效?
有时候我们可以通过只占用几十到几百个像素点的核来检测一些小的有意义的特征,例如图像的边缘。而且在深度卷积网络中,处在网络深层的单元可能与绝大部分输入是间接交互的,这允许网络可以通过只描述稀疏交互的基石来高效地描述多个变量的复杂交互。
稀疏交互优点:需要存储的参数更少,不仅减少了模型的存储需求,还提高了它的统计效率。
参数共享为什么有效?
同样的图案可能出现在不同的位置,但它们的性质是一样的,因此可以采用相同的参数。
参数共享:虽然没有改变前向传播的运行时间,但它显著地把模型的存储需求降低至k个参数。
参数共享的特殊形式使得神经网络层具有对平移等变的性质。(等变:如果一个函数满足输入改变,输出也以同样方式改变这一性质,我们就说它是等变的。)这说明,如果我们把输入中的一个事件向后延时,在输出中仍然会有完全相同的表示,只是时间延后了。这就说明,如果是a,b,1,3,5,a,b,那么对应在输出中a,b会保持一样的输出,可能是¥…¥,因此在输出中很容易找出相同的模式。