一、卷积神经网络概述
卷积神经网络专门用于处理具有类似网格结构的神经网络,比如说时间序列数据(可认为是在时间轴上有规律地采样形成的一维网格,举个例子就是医学上的心电图,就是1D图像),然后就是图像数据(二维网格,就是2D图像)
但是,同样也可以使用一般的神经网络做这方面,可以将每个像素点当成一个输入。如果这样,卷积神经网络的优越性就体现出来了。其优势主要体现在三个方面:稀疏连接,参数共享,等变表示。这会在之后分析卷积神经网络的结构中的卷积层会具体说明。
二、卷积神经网络结构

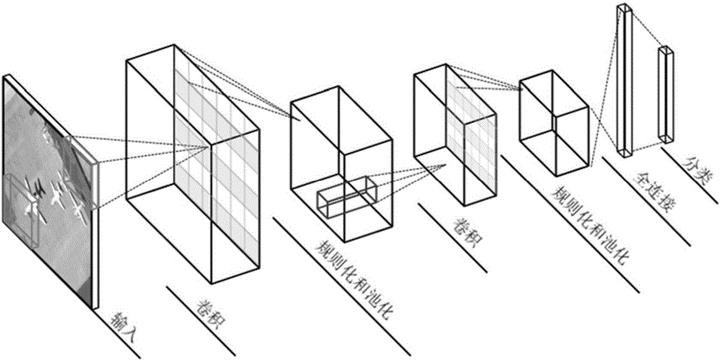
- 输入层
- 卷积层
- 激励层
- 池化层
- 全连接层
1.输入层
输入层往往做的是图像的预处理,常用的有PCA降维,归一化等
2.卷积层
卷积过程涉及到三个问题:
- 步长(stride)
- 填补空白(padding)
- 卷积核(kernel/filter)
kernel/filter:与输入图像数据进行卷积运算的卷积核,在深度学习中,学习的过程也是调整卷积核的参数 的过程
stride:卷积核在原图像数据中水平方向和垂直方向每次步进的长度
padding:卷积运算后,输出图片尺寸一般会缩小。同时由于原始图片边缘信息对输出贡献较少,输出可能丢失边缘信息,因此通过对原始图片尺寸扩展,扩展区补零。
设原始图像尺寸为 ,padding长度
,stride长度
,kernel尺寸
,则输出图像尺寸:
由于卷积运算的特性,每个单元(像素点)只会与一部分单元(像素点)相关联,而一般神经网络中,每个神经元都是与其他所有的神经元互联。在卷积神经网络中,这称作稀疏连接。这样模型存储的参数更少了,同时也提高了运算速度。
每个卷积核在进行滑动卷积运算过程中,其参数是共享的,相当于每个卷积核在原始图像中发掘出了一个特征。将这些特征按第三维度(2D图像数据)堆叠,例如视频中有两个卷积核运算结果的堆叠过程。比如在处理图像时,卷积层的第一层进行图像的边缘检测。这一般需要对整个图像进行参数共享,而相对于处理已经剪裁而使其居中的人脸图像是,因为是提取不同位置上的不同特征,所以一般不对整幅图像做参数共享
由于上述的参数共享,使得卷积神经网络具有平移等变性,即使输入的某一特征平移到何处,卷积核都能找到该特征并呈现出较大的激活值。例如在处理时间序列的数据时,即使输入中的某一事件向后延时,在输出中仍然会有相对于不做延时的表现。
3.激励层
回顾之前一般的神经网络,对于神经网络某一层(除输出层),其计算过程:
卷积层的作用类似于之前提到的线性计算,即 ,通过激活函数
将线性空间映射到非线性空间,在卷积神经网络中,常使用Relu,likely Relu作为激活函数。
4.池化层
池化层夹杂在连续的卷积层中,用于压缩数据,防止过拟合现象。
直观地来说,在处理某个任务的时候,池化层就是为了将图片数据中最重要的特征提取出来,去除对该问题不太重要的特征。
池化层的运算过程如下图所示:
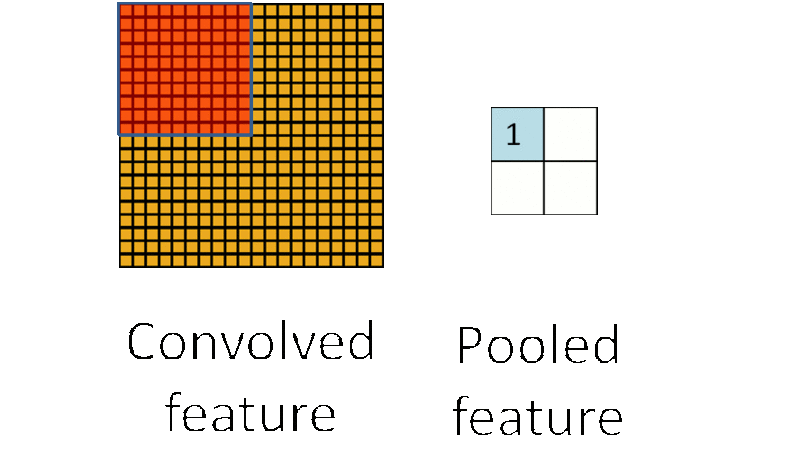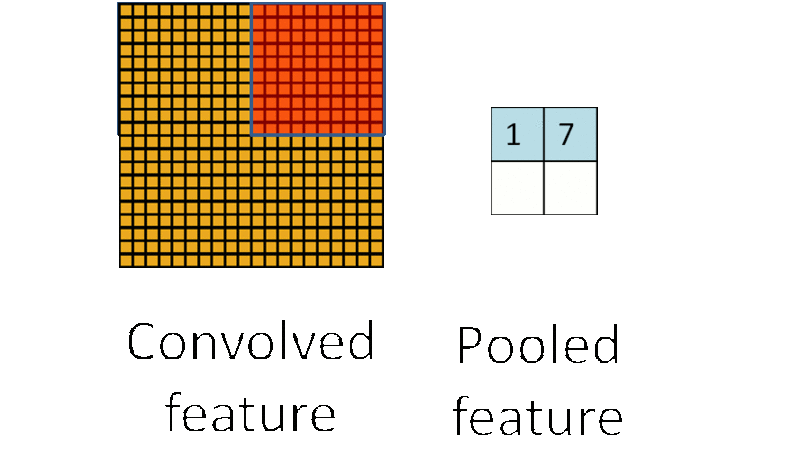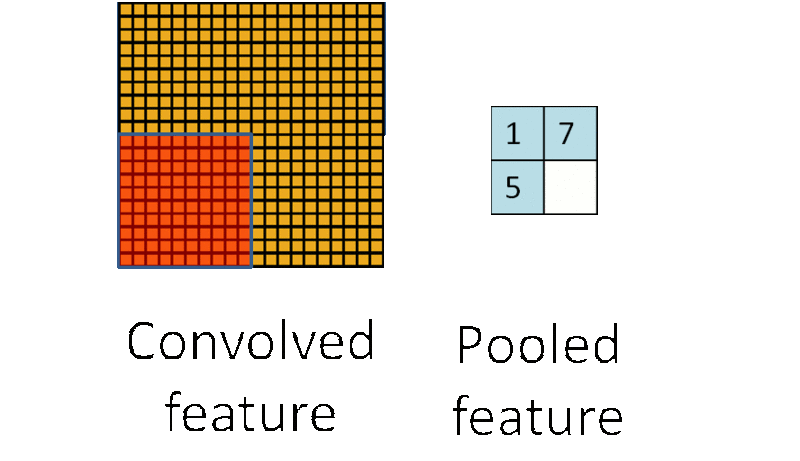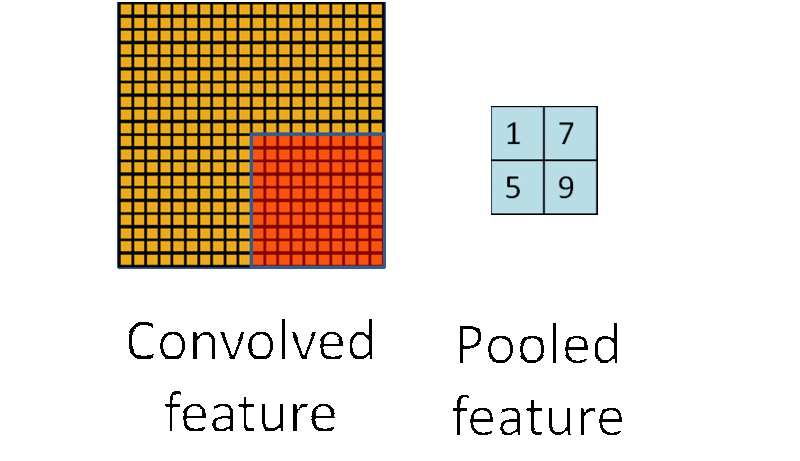

在选择池化层类型时,一般有max pool 和 average pool,最多使用的是max pool
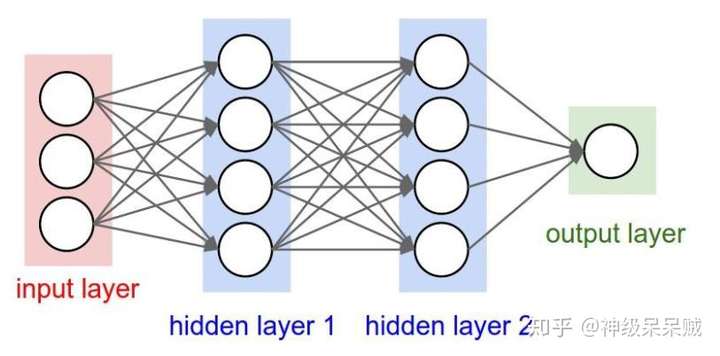
5.全连接层
全连接层类似于传统神经网络的连接方式,两层之间的神经元两两相互连接。全连接层在整个模型中往往处于网络的末尾处。

三、卷积神经网络的计算过程
与传统网络一样,卷积神经网络也是通过定义代价函数,衡量真实值与预测值之间的差距,逐步调整 等参数以最小化代价函数。
1.卷积层的计算
卷积层的正向传播计算如下图所示,输入图像数据与卷积核对应单元内的参数 相乘并累加,最后再上偏置。

类比于一般的神经网络,经过上述线性计算后,通过激励层的激活函数将线性空间映射到非线性空间。
2.池化层的计算
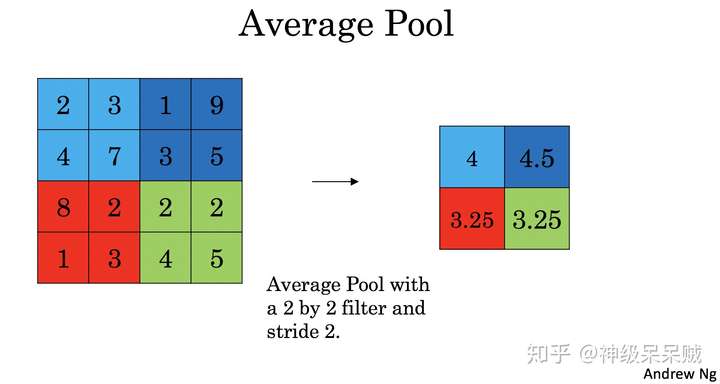
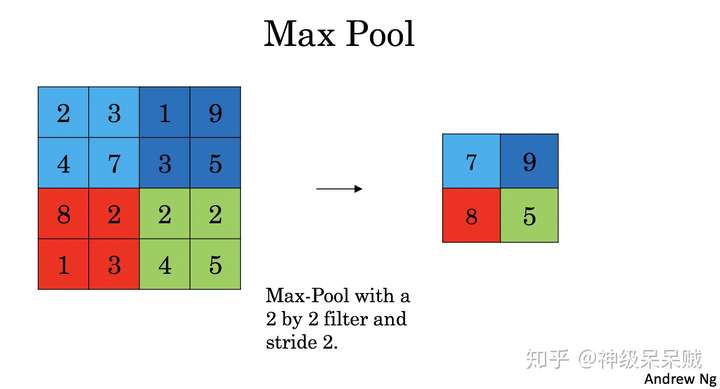
池化层正向传播主要有 Max Pool 和 Average Pool的计算
对于Max Pool,从滑动窗口每次选定的区域中选择最大的值,如下图所示:

同样地对于Average Pool,从滑动窗口每次选定的区域中取平均值,如下图所示: