1. cnn是dnn(fully connected)的简化版
比dnn的参数更少。为什么可以用更少的参数?
1)因为在每一层的hidden layer里面,每个神经元(neuron)只分析上一层的部分信息,而不是全部的信息。比如对于一个图像识别的任务,第一层的hidden layer中的每一 个neuron可以只负责识别原始图像的一部分信息,如下图所示(图片来自台大李宏毅老师机器学习课程视频),

要识别图片里是否有一只鸟,对于第一层的hidden layer中的每一个neuron,可以只负责识别鸟身体的一小部分,比如有的neuron负责识别是否有鸟嘴,有的neuron负责识 别是否有爪子,有的neuron负责识别是否有翅膀。你把鸟的身体分为几部分就大致需要多少neuron。
2 )同一张图片里相似的pattern可能出现在不同的区域,可以用同一个neuron,同一组参数识别出这些相似的pattern

3 )可以对图片做subsampling(分别对横向pixels,纵向pixels),而不会改变图片里的pattern
下图的图像识别任务这么做subsampling是可以的,但是对于诸如alphago

2. cnn的架构

。

1 )convolution原理
在一层的hidden layer里面会有多个filter matrix,每一个filter matrix里面的参数是学出来的,filter的size自己设定。每个filter可以想象为一个具有某个焦距的摄像头,
用这个摄像头去扫描整张图像。然后换一个焦距,再去扫描图像。

如下图,原始图片里的相同的pattern,经过一个filter之后得到的pixel应该能够保证相同
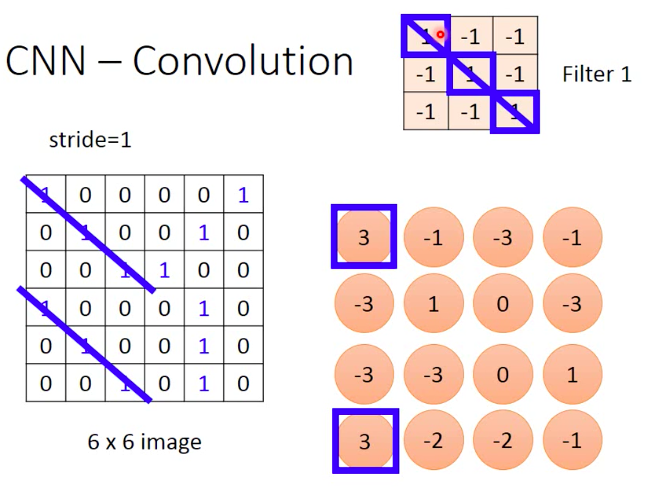
原始图像经过一个filter之后得到一个feature map

新得到的feature map的size会比原始图像的size要小,size(feature map) = size(原始图像)+1 + 2*pading - stride
上图中,原始图像里每个pixel只用一个数值来表示,但经过filter作用之后每个位置用两个数值来表示,这就是feature map的深度,而深度其实就是取决于filter matrix 的
个数。
为什么说convoluiton是fully connected的简化版

为什么cnn可以实现更少的参数?因为在filter matrix对图像进行滑动扫描的时候,参数是共享的(shared weights)

max polling
对feature map做groupen操作,对每一个group取最大值,或平均值

2 )cnn实现
李宏毅老师用的keras来实现cnn
可以发现后面的convolution层的filter个数一般多于前面的concolution层。这是因为第一层的convolutiuon层的input就是原是图像,所包含的pattern比较少,所以用较少的
filter就可以应对。而后面的convolution层接收的输入所包含的pattern则更多、更抽象,所以需要更多的pattern。

参考资料:
https://www.bilibili.com/video/av10590361/?from=search&seid=1312558671544415597