今天重点理解了几篇介绍CNN的博文,跑了几个基于keras的cnn的代码样例,只能说实现了对CNN的初窥!
博文:http://blog.csdn.net/qq_25762497/article/details/51052861#t0 从这篇博文里面获取了计算一个维度(宽或高)内一个输出单元里可以有几个隐藏单元的公式
博文:http://blog.csdn.net/u012641018/article/details/52238169 从这篇文章里面算清了需要多少权值参数,同时理解了权值共享的情况
权值共享(Shared Weights)
在卷积网络中,每个稀疏过滤器hi通过共享权值都会覆盖整个可视域,这些共享权值的单元构成一个特征映射,如下图所示。
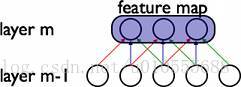
在图中,有3个隐层单元,他们属于同一个特征映射。同种颜色的链接的权值是相同的,我们仍然可以使用梯度下降的方法来学习这些权值,只需要对原始算法做一些小的改动, 这里共享权值的梯度是所有共享参数的梯度的总和。我们不禁会问为什么要权重共享呢?一方面,重复单元能够对特征进行识别,而不考虑它在可视域中的位置。另一方面,权值 共享使得我们能更有效的进行特征抽取,因为它极大的减少了需要学习的自由变量的个数。通过控制模型的规模,卷积网络对视觉问题可以具有很好的泛化能力。
空间排列(Spatial arrangement)
一个输出单元的大小有以下三个量控制:depth, stride 和 zero-padding。
- 深度(depth) : 顾名思义,它控制输出单元的深度,也就是filter的个数,连接同一块区域的神经元个数。又名:depth column
- 步幅(stride):它控制在同一深度的相邻两个隐含单元,与他们相连接的输入区域的距离。如果步幅很小(比如 stride = 1)的话,相邻隐含单元的输入区域的重叠部分会很多; 步幅很大则重叠区域变少。
- 补零(zero-padding) : 我们可以通过在输入单元周围补零来改变输入单元整体大小,从而控制输出单元的空间大小。
我们先定义几个符号:
- WW : 输入单元的大小(宽或高)
- FF : 感受野(receptive field)
- SS : 步幅(stride)
- PP : 补零(zero-padding)的数量
- KK : 深度,输出单元的深度
则可以用以下公式计算一个维度(宽或高)内一个输出单元里可以有几个隐藏单元:
如果计算结果不是一个整数,则说明现有参数不能正好适合输入,步幅(stride)设置的不合适,或者需要补零,证明略,下面用一个例子来说明一下。
这是一个一维的例子,左边模型输入单元有5个,即W=5W=5, 边界各补了一个零,即P=1P=1,步幅是1, 即S=1S=1,感受野是3,因为每个输出隐藏单元连接3个输入单元,即F=3F=3,根据上面公式可以计算出输出隐藏单元的个数是:5−3+21+1=55−3+21+1=5,与图示吻合。右边那个模型是把步幅变为2,其余不变,可以算出输出大小为:5−3+22+1=35−3+22+1=3,也与图示吻合。若把步幅改为3,则公式不能整除,说明步幅为3不能恰好吻合输入单元大小。

另外,网络的权重在图的右上角,计算方法和普通神经网路一样。
博文:http://blog.csdn.net/cxmscb/article/details/71023576 这篇文章讲的比较细致