说明:本系列是七月算法深度学习课程的学习笔记
1神经网络与卷积神经网络
1.1 深度神经网络适合计算机视觉处理吗
深度神经网络简称DNN,卷积神经网络简称CNN。
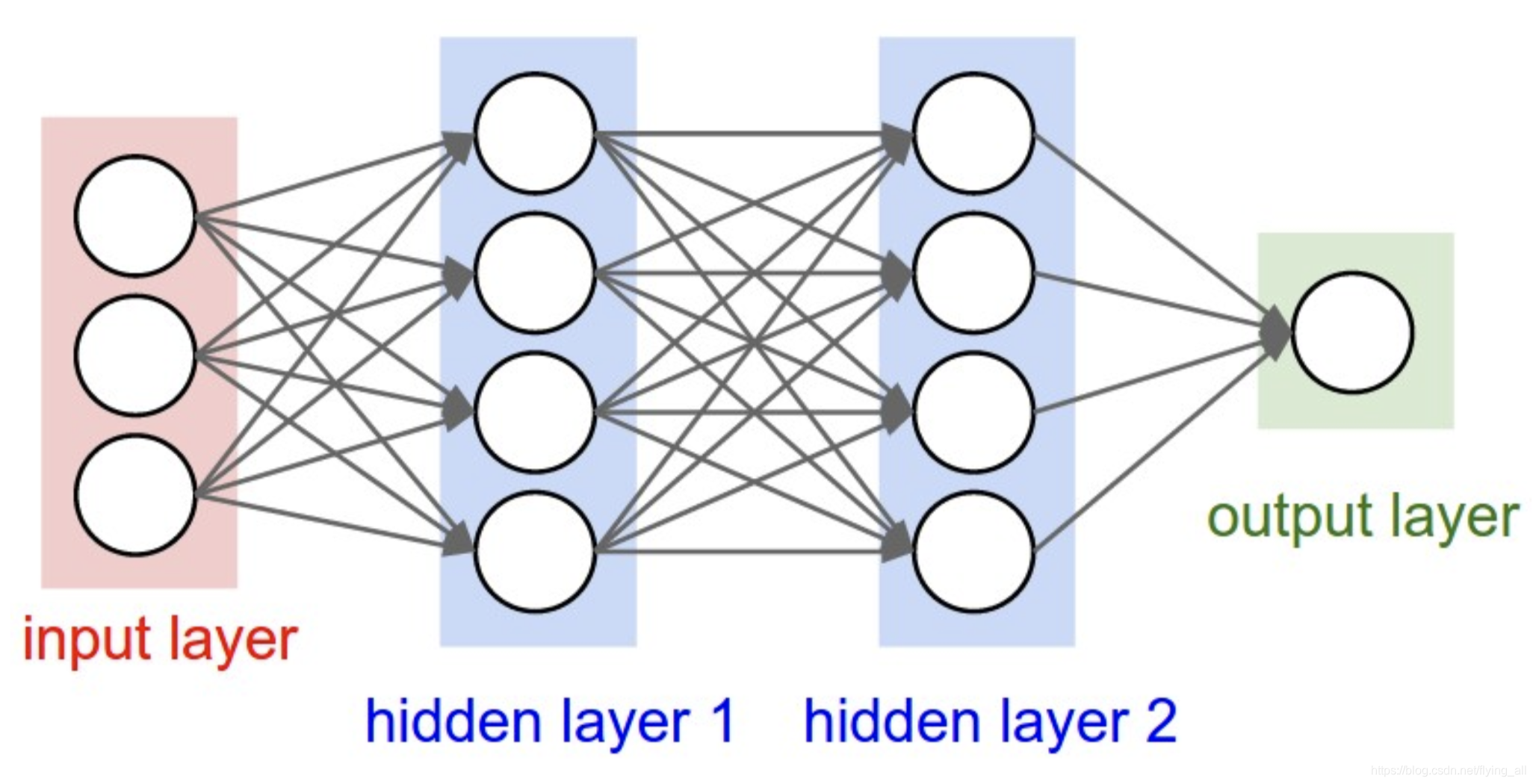
DNN的每一层与后面一层都是全连接。如果输入层是3维,隐层1有4个神经元。那从输入层到隐层1会有35=15个参数。如果隐层2有4个神经元,从隐层1到隐层2,需要44=16个参数。
在图像视频处理中,输入是非常大的。例如一张图片可能的输入是32x32x3,也就是一张长32,宽32的彩色图片。如果输入层有1万张图片用于训练,那参数就是=307210000维(在图像处理中一般会把 原始的输入矩阵做flatten,变为向量)。这是非常大的一个数。每一个隐层神经元数量实际中不会太少,因为太少就很难捕捉到重要信息,例如4000,参数量变为40003072*10000。这是一个很大的数字。这还只是一层。参数量大,在工程上压力大,计算、加载、存储压力都很大。参数量大,也很容易过拟合。所以DNN不适合。CNN可以。
1.2CNN的结构
CNN为什么适合计算机视觉处理呢?先看下CNN的结构。

一个CNN包含:数据输入层/input layer+卷积计算层/conv layer、激励层activation layer、池化层 pooling layer、全连接层 FC layer、Batch Normalization层(可能有)。
1.2.1 数据输入层
有3种常见的数据处理方式。
1 去均值:把数据的各个维度都中心化到0,相当于没有了截距。
2 归一化:把数据的各个维度都归一化到同样的范围,便于梯度计算,各个维度收敛速度一致。
常见的归一化的方法有:
min-max标准化,将数据归一到[0,1]范围内。
。
z-score标准化:处理后数据变为符合标准正态分布。
,其中μ为所有样本数据的均值,σ为所有样本数据的标准差。
3 PCA/白化:PCA 降维 。白化:降维之后的各个维度可能幅度不一致,这里再做一次归一化。
注意:这里需要说明的是如果在训练集上做了什么操作,在测试集或者预测的时候也需要做同样的处理。可以使用样本的归一化的值(均值、方差等),做归一化。
1.2.2 卷积层
卷积层的几个核心概念:局部关联、 窗口滑动。
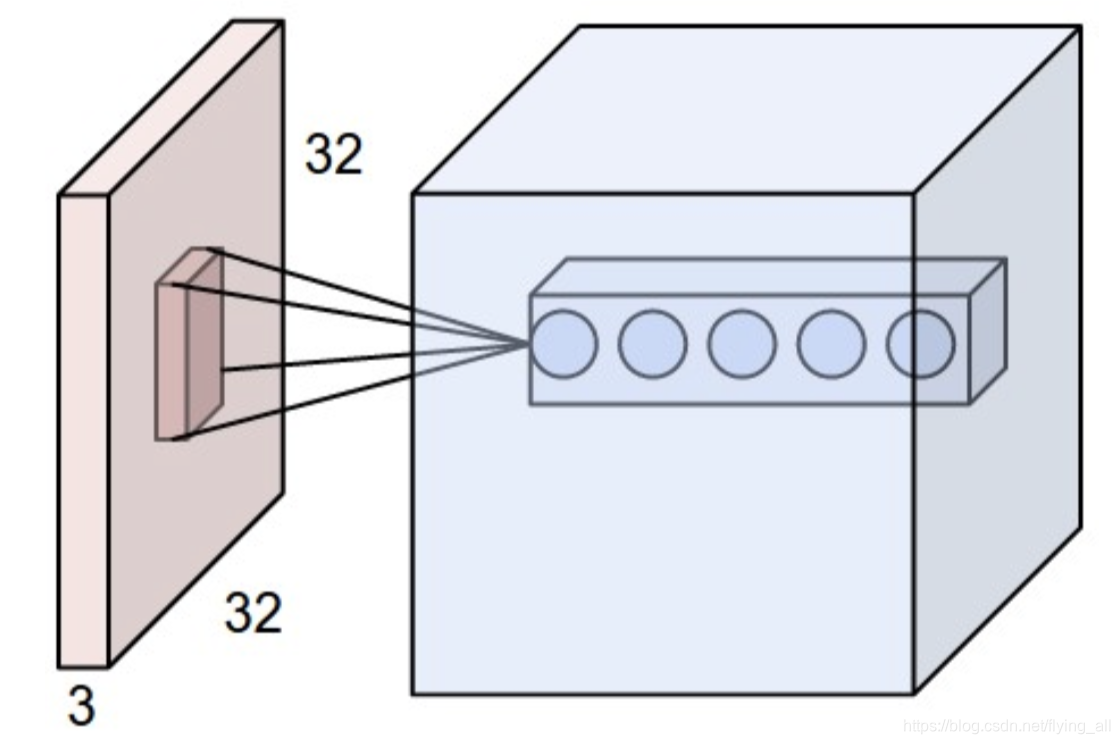
局部关联是指用输入层的一小块区域与下一层的每个神经元做内积。这块小区域被称为一个窗口。一个窗口计算完,按照一定的步长移动窗口,直至计算完成。滑动过程中遇到最后一次计算,不够窗口宽度,可以填充0,补充完整。
下一层神经元的个数被称为深度。
下一层中每个神经元的连接权重是固定的。如图中下一层有5个神经元,那就是5组参数。每一组参数是会与窗口中的数据做内积,如果窗口是一个3x3x3的大小,那一个神经元的参数个数就是3x3x3。这一层参数总个数是3x3x3x5。这样参数的数量与DNN(32x32x3x5)相比就少了很多。
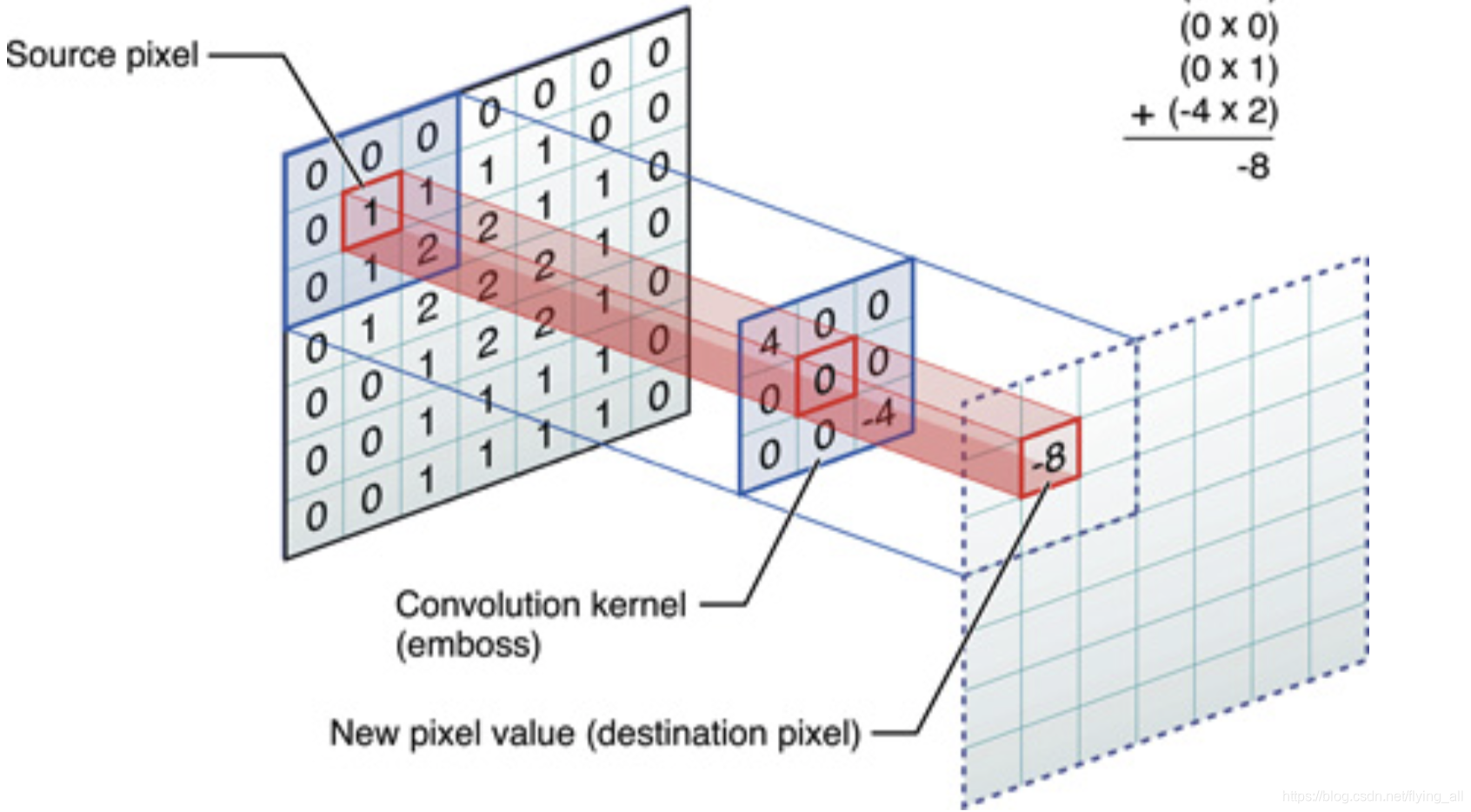
一组固定的权重与不同的窗口内数据做内积,这个过程称为卷积。
1.2.3 激励层
激励层:把卷积层的输出做非线性变换。否则无论加多少个隐层,这个符合函数还是线性的。是不能形成弯曲的曲线,在某些数据上是没法分割的。
常用的激励函数有:sigmoid、tanh(双曲正切)、Relu、Leaky Relu、ELU、Maxout
只要神经网络正常,选择哪个激励函数不影响最后的结果。
慎用sigmoid函数,优先选择Relu,可以继续尝试Leaky Relu、Maxout。
1.2.3 池化层
池化层:夹在连续的卷积层中间。主要起到压缩数据和参数的作用,可以防止过拟合。
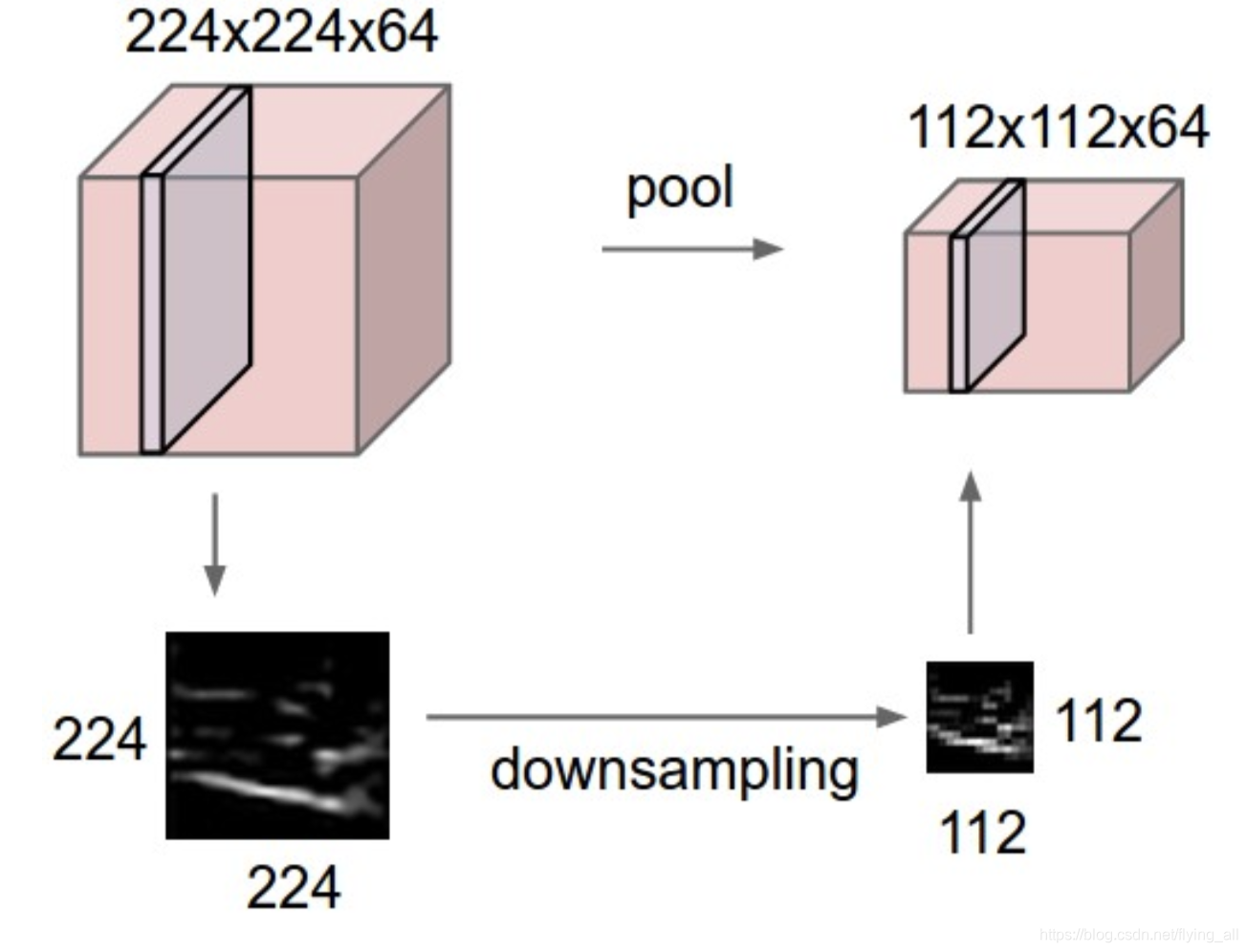
可以做池化的原因是发现将一个224x224的特征可视化之后发现降低到112x112,特征不会丢失很多。
可以采取的池化方法是max pooling和average pooling。

相当于给一个图像做了模糊化。减少了数据量,对下一层就意味着减少了输入的参数量。同时因为模糊化了,降低过拟合的风险。
1.2.4 全连接层
全连接:两层之间所有神经元都有权重链接。通常全连接层放在CNN的尾部。
一个典型的CNN结构=INPUT +[[CONV->RELU]*N->POOLING?]*M+[FC->RELU]*K+FC
1.3CNN的训练算法
先定义loass function:衡量和实际结构之间的差距
找到最小化损失函数的W和b,CNN中使用的是SGD
利用BP 链式法则求导,求出dw和db(将错误信息回传到每一层)
利用SGD/随机梯度下降,迭代更新W和b(学习到新一轮知识)
1.4CNN的优缺点
优点:共享卷积核,优化计算量;
无需手动选择特征,训练好权重即得特征;
深层次的网络抽取图像信息丰富,表达效果好。
缺點:需要调参、计算量大
物理含义不明确
2正则化与Droupout
原因:神经网络学习能力过强,可能会过拟合
传统方式可以使用L1、L2正则化,在NN中是使用dropout。
Dropout正则化:别一次开启所有学习单元。给每个神经元安了一个开关,这个开关会以一定的概率关闭。
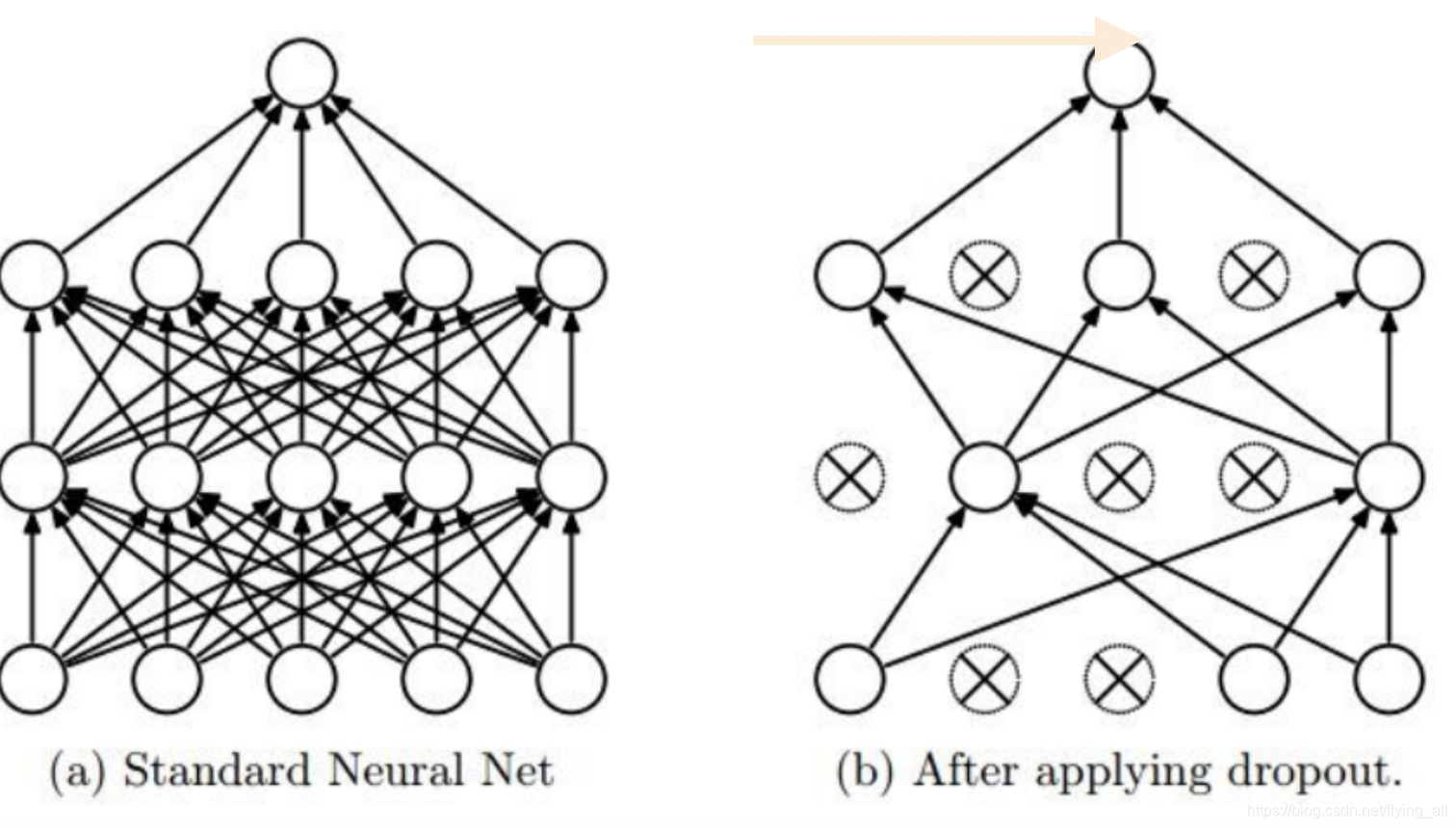
在训练阶段:
p=0.5
def train_step(X):
H1 = np.maximum(0, np.dot(W1,X)+b1)
U1 = np.random.rand(H1.shape) <p//<p则保留
H1 = H1*U1
...
在预测阶段:
def predict(X):
H1 = np.maximum(0, np.dot(W1,X)+b1)*p
....
在预测阶段会乘以概率p,实际工程中,会在训练阶段除以p。
p=0.5
def train_step(X):
H1 = np.maximum(0, np.dot(W1,X)+b1)
U1 = (np.random.rand(H1.shape) <p)/p
H1 = H1*U1
...
def predict(X):
H1 = np.maximum(0, np.dot(W1,X)+b1)
....
对dropout的理解方式一:不要记住太多的东西,学习过程中保持泛华能力。
对dropout的理解方式二:每次都关掉一部分感知器,得到一个新模型,最后做融合。不至于听一家之言。
3典型结构与训练调优
典型CNN网络有:Lenet、AlexNet、ZFNet、VGG、GoogleNet、ResNet。
调优:可以在这些典型的网络模型基础上训练自己的图片分类模型。可以做的是:不要修改层的名称,使用原有参数,降低学习率;修改层的名称,修改分类数为自己的分类数量,提高学习率;新增自己的层,提高学习率。
