目录
2、Bounding Box Prediction—边界框预测
前言
YOLO v3(《Yolov3:An incremental improvement》)是Joseph Redmon大神于2018年发表的一篇单阶段目标检测论文,这也是作者关于yolo系列的最后一篇论文。yolo v3在yolo系列中是一个较为成熟的模型,在工业界也普遍使用,因此对yolo v3 做研究是有着重要意义的。
对比前面的V1、V2,v3除了网络结构,其余变化不大,主要是将当今一些较好的检测思想融入到了YOLO中,在保持速度优势的前提下,进一步提升了检测精度,尤其是对小物体的检测能力。具体来说,YOLOv3主要改进了网络结构、网络特征及后续计算三个部分。
改进点:
- 多尺度预测(引入FPN)
- 更好的backbone(darknet-53,类似于ResNet引入残差结构)
- 分类器不再使用softmax(darknet-19中使用),损失函数中采用binary cross-entropy loss(二分类交叉损失熵)
1、网络架构
YOLOv3继续借鉴了当前优秀的检测框架的思想,如的残差网络和特征融合等,提出了如图下图所示的网络结构,称之为DarkNet-53。作者在ImageNet上实验发现darknet-53相对于ResNet-152和ResNet101,不仅在分类精度上差不多,计算速度还比ResNet-152和ResNet-101强多了,网络层数也比它们少。
YOLO v3模型结构如下图所示:

● DBL:代表卷积、BN及Leaky ReLU三层的组合,在YOLOv3中卷积都是以这样的组合出现的,构成了DarkNet的基本单元。DBL后面的数字代表有几个DBL模块。
● res:res代表残差模块,res后面的数字代表有几个串联的残差模块。
● 上采样:上采样使用的方式为上池化,即元素复制扩充的方法使得特征图尺寸扩大,没有学习参数。
● Concat:上采样后将深层与浅层的特征图进行Concat操作,即通道的拼接,类似于FPN,但FPN使用的是逐元素相加。
● 残差思想:DarkNet-53借鉴了ResNet的残差思想,在基础网络中大量使用了残差连接,因此网络结构可以设计的很深,并且缓解了训练中梯度消失的问题,使得模型更容易收敛。
● 多层特征图:通过上采样与Concat操作,融合了深、浅层的特征,最终输出了3种尺寸的特征图,用于后续检测。多层特征图对于多尺度物体及小物体检测是有利的。
● 无池化层:之前的YOLO网络有5个最大池化层,用来缩小特征图的尺寸,下采样率为32,而DarkNet-53并没有采用池化的做法,而是通过步长为2的卷积核来达到缩小尺寸的效果,下采样次数同样是5次,总体下采样率为32。
需要注意的是,concat操作与加和操作的区别:加和操作来源于ResNet思想,将输入的特征图,与输出特征图对应维度对应位置进行相加,即 y = f(x) + x ;而concat操作源于DenseNet网络的设计思路,将特征图按照通道维度直接进行拼接,例如8*8*16的特征图与8*8*16的特征图拼接后生成8*8*32的特征图。上采样层(upsample):作用是将小尺寸特征图通过插值等方法,生成大尺寸图像。例如使用最近邻插值算法,将8*8的图像变换为16*16。上采样层不改变特征图的通道数。
1.1 backbone网络
YOLOv3在YOLOv2提出的Darknet-19的基础上引入了残差模块,并进一步加深了网络,改进后的网络有53个卷积层,命名为Darknet-53,网络结构如下:

作者采用Darknet-53作为特征提取网络,去掉了网络中的Avgpool,connected和softmax层。
整个v3结构里面,是没有池化层和全连接层的。前向传播过程中,张量的尺寸变换是通过改变卷积核的步长来实现的,比如stride=(2, 2),这就等于将图像边长缩小了一半(即面积缩小到原来的1/4)。在yolo_v3中,要经历5次缩小,会将特征图缩小到原输入尺寸的1/32。输入为416x416,则输出为13x13(416/32=13)。
2、Bounding Box Prediction—边界框预测
2.1 多尺度预测
从模型结构可以发现,YOLOv3输出了3个不同大小的特征图,从上到下分别对应深层、中层与浅层的特征。深层的特征尺寸小,感受野大,有利于检测大尺度目标,中等尺度特征图用于检测中等目标,浅层的特征图用于检测小尺度目标,这一点类似于FPN结构。
在每个grid cell预先设定一组不同大小和宽高比的边框,来覆盖整个图像的不同位置和多种尺度。每种尺度预测3个box, anchor的设计方式仍然使用聚类(得到9个聚类中心,将其按照大小均分给3个尺度,利用这三种尺度的特征层进行边框的预测。
2.2 anchor网格偏移量预测
由前一部分的讲解可知,Yolo Head输出是三维的w,h 的每一个点对应原图划分的网格,channel对应的是该anchor的预测值,那我们如何计算anchor的具体位置呢?
yolo的思想是将一张图片划分为W*W个网格,每一个网格负责中心点落在该网格的目标.每个网格可以看作一个感兴趣区域,既然是区域,就需要计算预测anchor的具体坐标与bbox的w和h.
c h a n n e l = t x + t y + t w + t h + o b j + n u m c l a s s e s channel =t_x+t_y+t_w+t_h+obj+num_{classes} channel=tx+ty+tw+th+obj+numclasses
其中预测值tx,ty并不是anchor的坐标,而是anchor的偏移量,同样的 t w , t h t_w,t_h tw,th是先验框的缩放因子,先验框的大小由k-means聚类xml标签文件中保存的坐标位置得到,每一个anchor有三个不同大小的先验框,预测层Yolohead有三个,总共的先验框数量为划分总网格数的三倍.
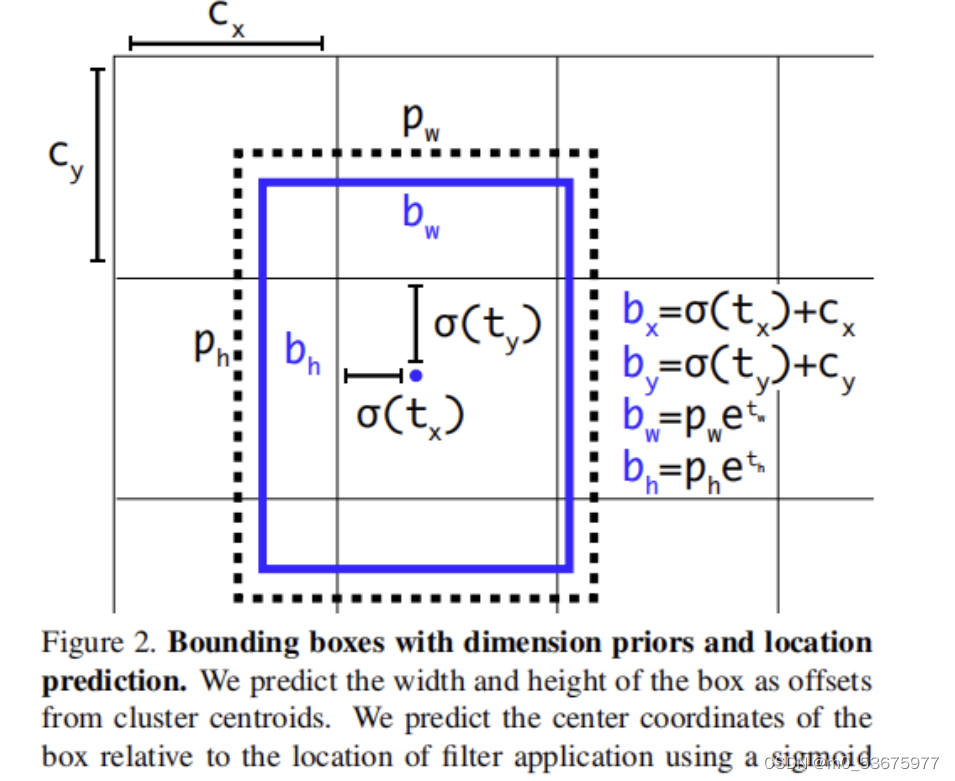
上图表示了bbox的回归过程 c x , c y c_x,c_y cx,cy是网格左上角坐标,anchor向右下方偏移,为了防止anchor偏移量超出网格导致定位精度损失过高,yolov3使用了sigmoid函数将预测值tx,ty进行限制到[0,1](可以加速网络的收敛),最后得出anchor的预测坐标 b x , b y b_x,b_y bx,by.bbox的w与h由预测缩放因子 t w 与 t h t_w与t_h tw与th决定, p w 和 p h p_w和p_h pw和ph为anchor模板映射到特征图上的宽和高,通过指数函数对 t w t_w tw与 t h t_h th进行放大在分别与 p w 和 p h p_w和p_h pw和ph相乘就得到了最终预测的w和h.PS:此处的x,y坐标点都是anchor映射到特征图的值,并不是原图上的坐标,在plot bbox应该将其转换到真实图片上的坐标再进行绘制.
2.3 Yolo Head
YOLOv3使用的方法有别于SSD,虽然都利用了多个特征图的信息,但SSD的特征是从浅到深地分别预测,没有深浅的融合,而YOLOv3的基础网络更像是SSD与FPN的结合。YOLOv3默认使用了COCO数据集,一共80个物体类别,因此一个Anchor需要80维的类别预测值,4个位置预测及一个置信度预测。每个cell有三个Anchor,因此一共需要3×(80+5)=255,也就是每一个特征图的预测通道数。
当输入为 416*416 模型会输出10647个预测框(三种尺寸的特征图,每种尺寸三个预测框一共 (13×13+26×26+52×52)×3=10647 ),为每个输出框根据训练集中的ground truth为每个预测框打上标签(正例:与ground truth的IOU最大;负例:IOU<阈值0.5;忽略:预测有物体的框但IOU并非最大在NMS中被舍去)。再使用损失函数进行优化,更新网络参数。
如上图所示:在训练过程中对于每幅输入图像,yolov3会预测三个不同大小的3D tensor,对应着三个不同的scale,设计这三个scale的目的是为了能检测出不同大小的物体。 这里以13 * 13的tensor为例,对于这个scale,原始输入图像会被分割成13 × 13的grid cell,每个grid cell对应着3D tensor中的1x1x255这样一个长条形voxel。255是由3*(4+1+80)而来,由上图可知,公式 N×N×[3×(4+1+80)] 中 N×N 表示的是scale size例如上面提到的 13×13 。3表示的是each grid cell predict 3 boxes。4表示的是坐标值即 (tx,ty,th,tw) 。1表示的是置信度,80表示的是COCO类别数目。
- 如果训练集中某一个ground truth对应的bounding box中心恰好落在了输入图像的某一个grid cell中,那么这个grid cell就负责预测此物体的bounding box,于是这个grid cell所对应的置信度为1,其他grid cell的置信度为0.每个grid cell都会被赋予3个不同大小的prior box,学习过程中,这个grid cell会学会如何选择哪个大小的prior box。作者定义的是选择与ground truth的IOU重合度最高的prior box。
- 上面说到的三个预设的不同大小的prior box,这三个大小是如何计算的,首先在训练前,将COCO数据集中的所有bbox使用k-means clustering分成9个类别,每3个类别对应一个scale,故总共3个scale,这种关于box大小的先验信息帮助网络准确预测每个box的offset和coordinate。从直观上,大小合适的box会使得网络更精准的学习.
在预测过程中
将图片输入训练好的预测网络,首先输出预测框的信息 (obj,tx,ty,th,tw,cls) ,每个预测框的class-specific confidence score(conf_score=obj*cls)以后,设置阈值,滤掉得分低的预测框,对保留的预测框进行NMS处理,就得到最终的检测结果。
- 阈值处理:去除掉大部分不含预测物体的背景框
- NMS处理:去除掉多余的bounding box,防止重复预测同一物体
总结预测流程就是:
然后再遍历三种尺度
→ 遍历每种尺度的预测框
→ 将预测框分类scores中最大的作为该box的预测类别
→ 将预测框的confidence与其80维的分类scores相乘
→ 设定nms_thresh和iou_thresh,使用nms和iou去除背景边框和重复边框
→ 遍历留下的每一个预测框,可视化
3、正负样本匹配规则
在yolov3论文中提到正负样本的匹配规则是:给每一个groundtrue box分配一个正样本,这个正样本是所有bbox中找一个与gt_box的重叠区域最大的一个预测框,也就是和该gt_box的iou最大的预测框.但是如果利用这个规则去寻找正样本,正样本的数量是很少的,这将使得网络难以训练.如果一个样本不是正样本,那么它既没有定位损失,也没有类别损失,只有置信度损失,在yolov3的论文中作者尝试用focal loss来缓解正负样本不均匀的问题,但是并没有取得很好的效果,原因就在于负样本值参与了置信度损失,对loss的影响占比很小.作者首先将bbox与gr_box的左上角对齐,再计算出存在目标的anchor的bbox与gr_box的iou,并设定一个iou阈值,如果anchor template的iou大于阈值则归为正样本.
4、损失函数
损失包含置信度损失,定位损失,类别预测损失。其中置信度损失考虑所有样本,定位损失只考虑正样本,分类损失正样本。


5、训练策略
1.使用了多尺度训练。
2.使用了数据扩增。
3.使用了标准化归一化。