论文题目:《Scaling Instruction-Finetuned Language Models》
论文链接:https://arxiv.org/pdf/2210.11416.pdf
github链接:https://github.com/google-research/text-to-text-transfer-transformer#released-model-checkpoints
huggingface链接:https://huggingface.co/docs/transformers/model_doc/flan-t5
本文分析了使用“指令数据”对语言模型进行微调所带来的改进,涉及缩放 :1)增加微调任务,2) 增大模型大小,以及 (3) 添加思维链数据。Google 研究人员2022年10月发布了这篇论文,我们今天将对这篇文章重新阅读,本篇论文分析了如何指令微调大型语言模型以及带来的性能提升。
摘要
研究已经证明,在一组表述为指令的数据集上微调语言模型可以提高模型性能和对未知任务的泛化能力。在本文中,作者探索了指令微调,特别关注:
- (1)缩放任务数量;
- (2)缩放模型大小;
- (3)链式思维数据微调;
论文发现,在上述方面进行指令微调可以显着提高各种模型(PaLM、T5、U-PaLM)、提示设置(零样本、少样本、CoT)和评估基准(MMLU、BBH、 TyDiQA、MGSM、开放式生成、RealToxicityPrompts)。例如,在 1800多种 任务上微调的 Flan-PaLM 540B 指令大大优于 PaLM 540B(平均提升 +9.4%)。Flan-PaLM 540B 在多个基准测试中实现了最优的性能,例如在五次 MMLU 上达到 75.2%。论文还公开发布了 Flan-T5权重,即使与参数量更大的模型(例如 PaLM 62B)相比,它也能实现强大的零样本性能。总的来说,指令微调是提高预训练语言模型性能和可用性的通用方法。
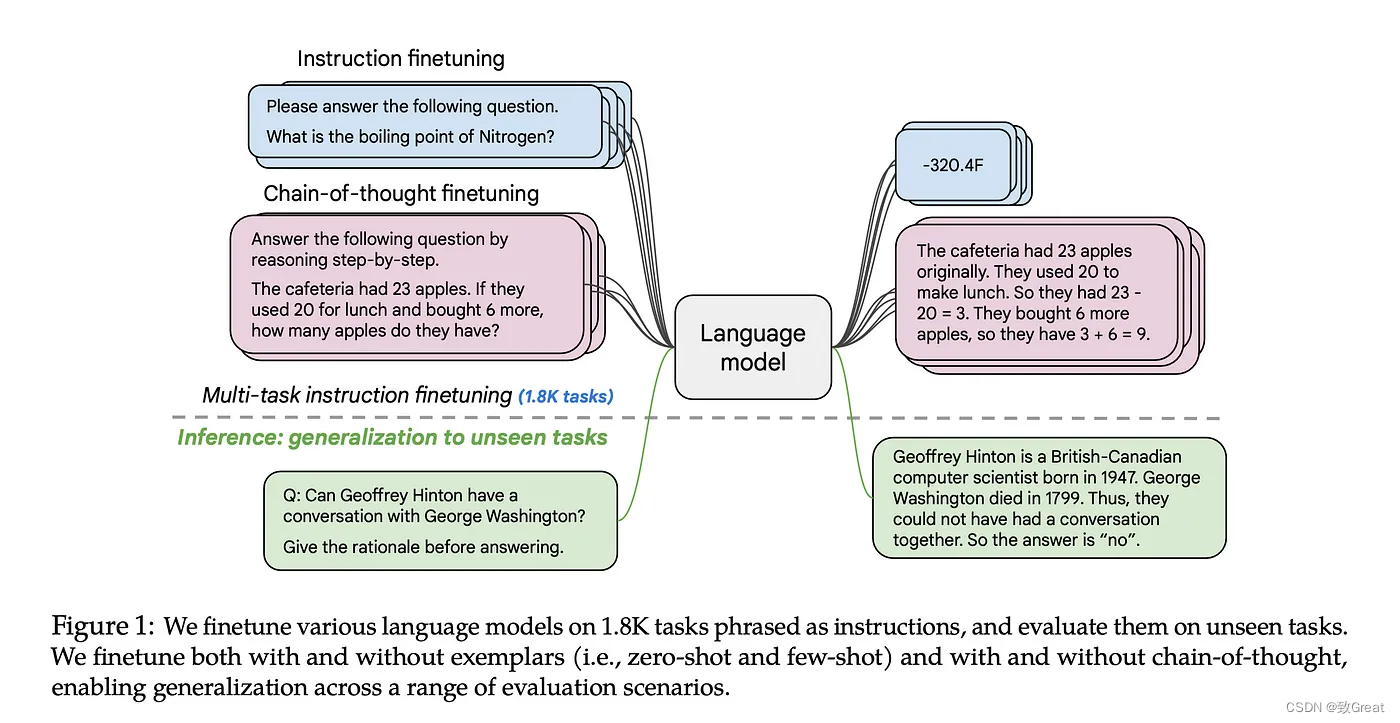
简介
指令是一组数据集,一组用指令表达的任务。使用指令数据进行微调使模型能够更好地响应指令,并减少对样本的需求。一般的发现是,微调的好处与任务的数量和模型的大小成比例。两种关系都是正相关的(模型越大,训练任务越多,即指令在少样本和零样本示例中性能提升更多),这项研究还使用思维链 (CoT) 数据对模型进行微调。
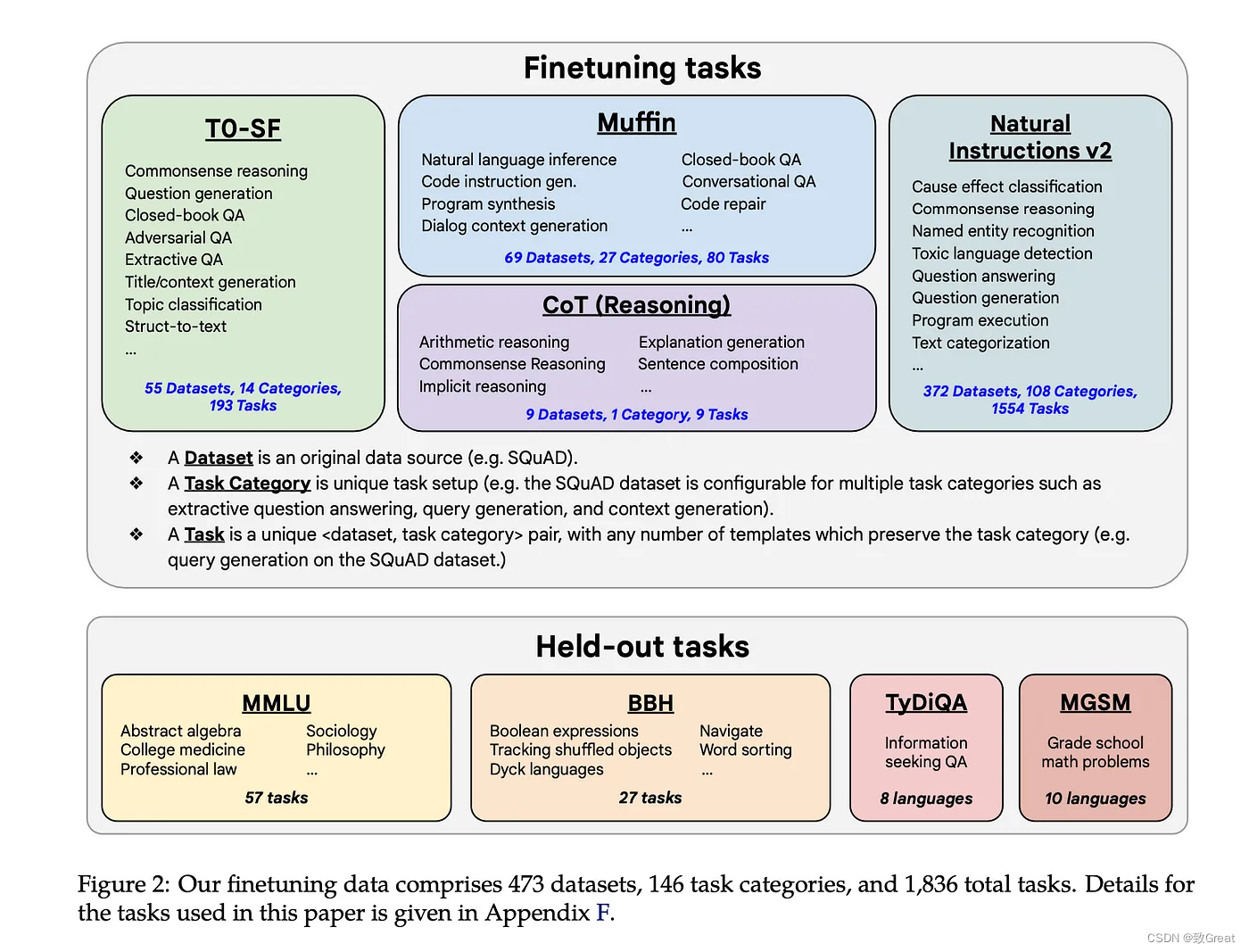
微调数据
该数据包括总共 1836 种指令任务,包括 473个 数据集,146 个任务类别,涉及FLAN、T0、Natural Instructions,以及一些对话、程序合成和链式思维推理任务。所有数据源都是公开的。保留了 57 个 MMLU 任务以供评估。
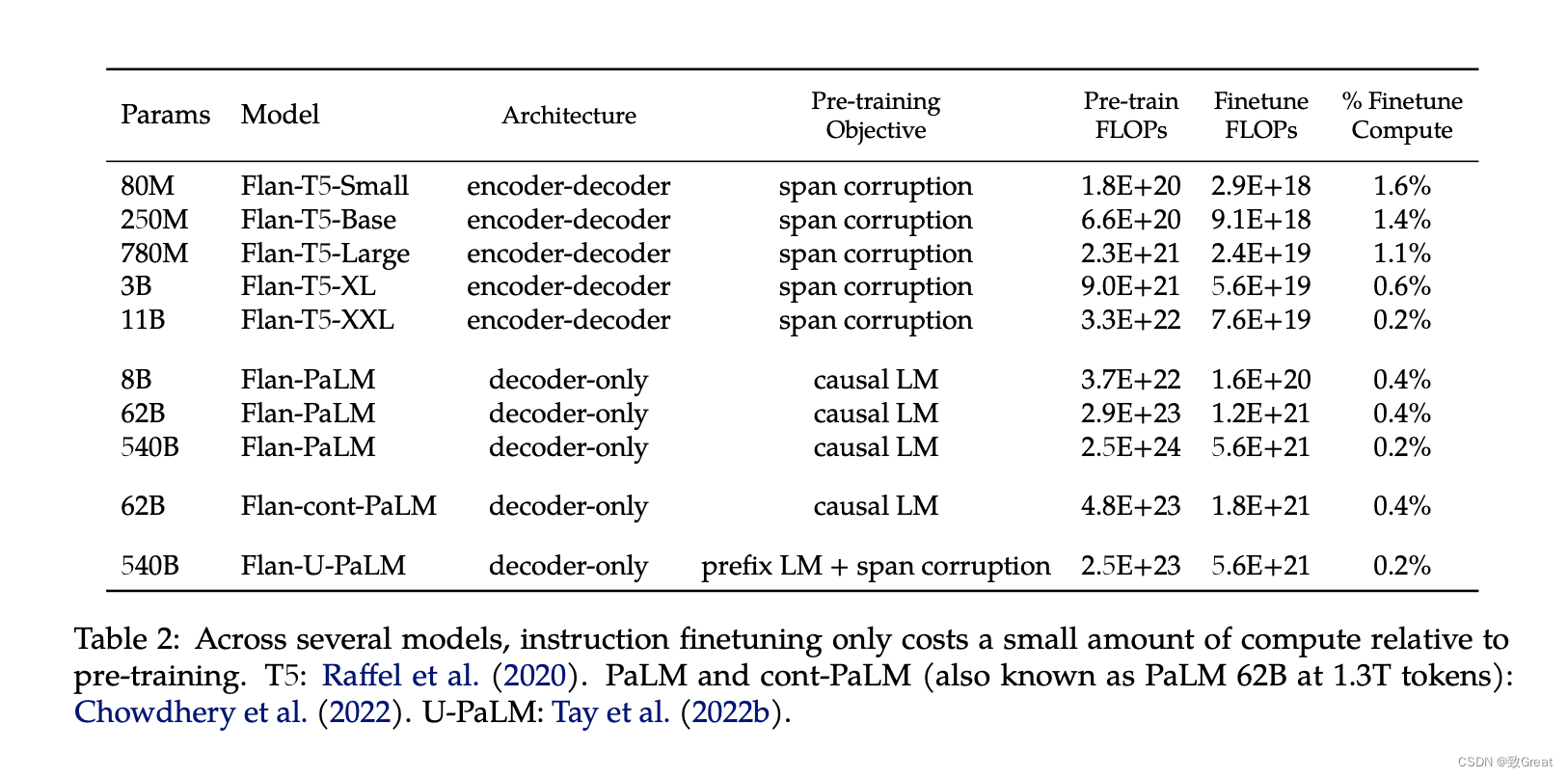
位于本文中心的最大模型是 PaLM 模型。 该模型的微调版本是 F(ine-tuneed)-lan(gauge)-PaLM 即FlanPaLM,该论文还对从 80M 参数到 11B 参数版本的 T5 模型进行了微调。
Flan Finetuning
任务混合物。 先前的文献表明,增加指令微调中的任务数量可以提高对未见任务的泛化能力。 在本文中,我们通过组合先前工作中的四种混合来扩展到 1,836 个微调任务:
- Muffin3(80 个任务)包含来自 Wei 等人的 62 个任务。 (2021) 以及本文添加到这项工作中的 26 个新任务,包括对话数据)和程序综合数据(。
- T0-SF(193 个任务)包括来自 T0的任务,这些任务与 Muffin 中使用的数据不重叠(SF 代表“sans Flan”)。
- NIV2(1554 个任务)
- 思想链微调混合。 第四种微调数据混合(推理)涉及 CoT 注释。 它混合了来自先前工作的九个数据集,人类评分者为训练语料库手动编写了 CoT 注释。 这九个数据集包括算术推理 (Cobbe et al., 2021)、多跳推理 (Geva et al., 2021) 和自然语言推理 (Camburu et al., 2020) 等任务。 我们为每个任务手动编写十个指令模板。
微调的计算能力范围为训练基本模型所需的总计算能力的 0.2% 到 1.6%。
模型评估
- MMLU 包括数学、历史、法律和医学等 57 个任务的试题。
- BBH 包括来自 BIG-Bench的 23 项具有挑战性的任务,PaLM 在这些任务中的表现低于人类评分者的平均水平。
- TyDiQA是一个跨 8 种不同类型语言的问答基准。
- MGSM是 Cobbe 等人提出的数学单词问题的多语言基准。 手动翻译成 10 种语言。,PaLM 论文中也使用了这些基准。
使用超过六个分数(MMLU-Direct、MMLU-CoT、BBH-Direct、BBH-CoT、TyDiQA-Direct 和 MGSM-CoT)的宏观平均值完成指标的归一化平均值, 评估结果(下表中的归一化平均值显示了所有模型和任务的微调组合)如下:
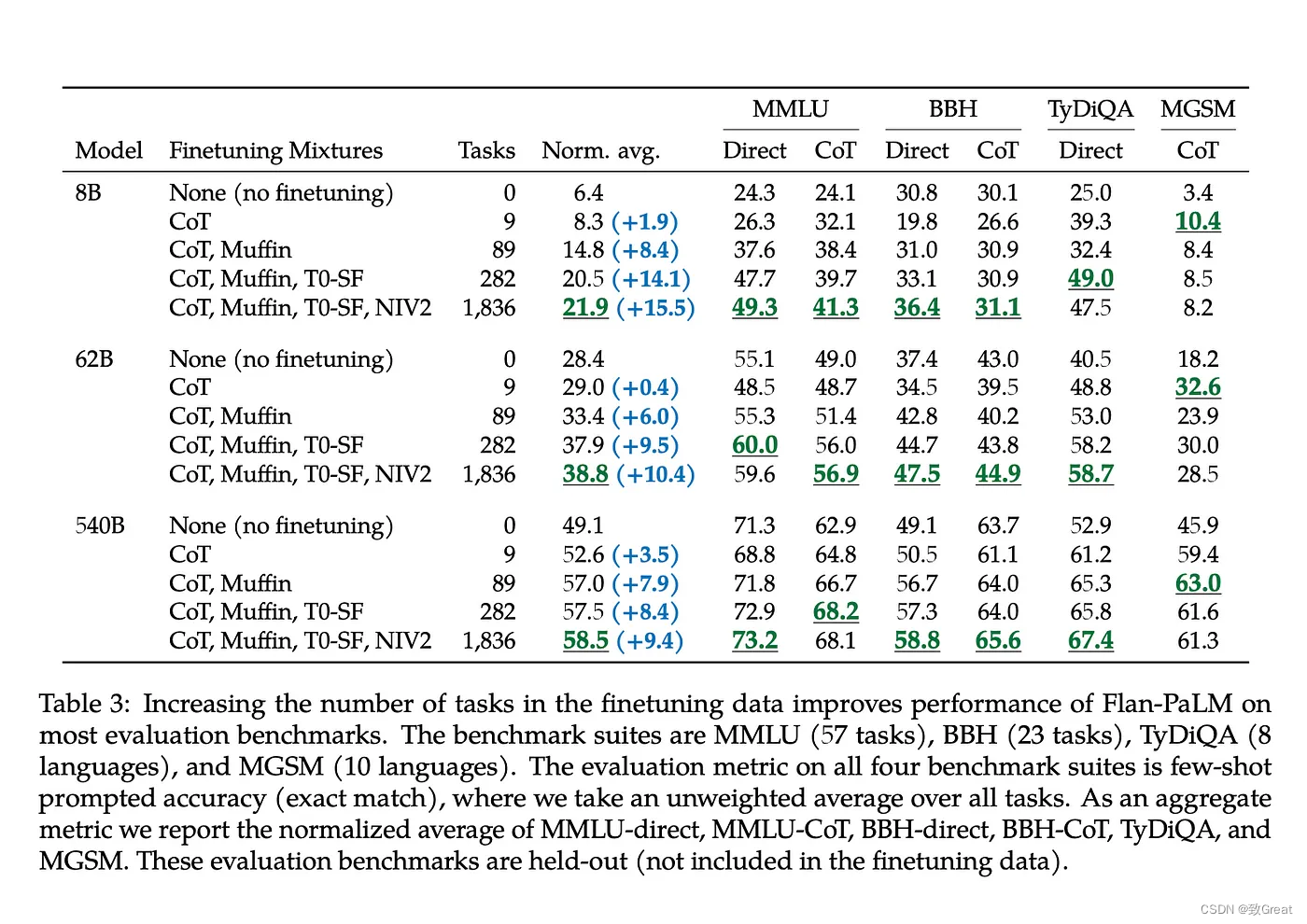
训练任务的缩放效果
可以看到:
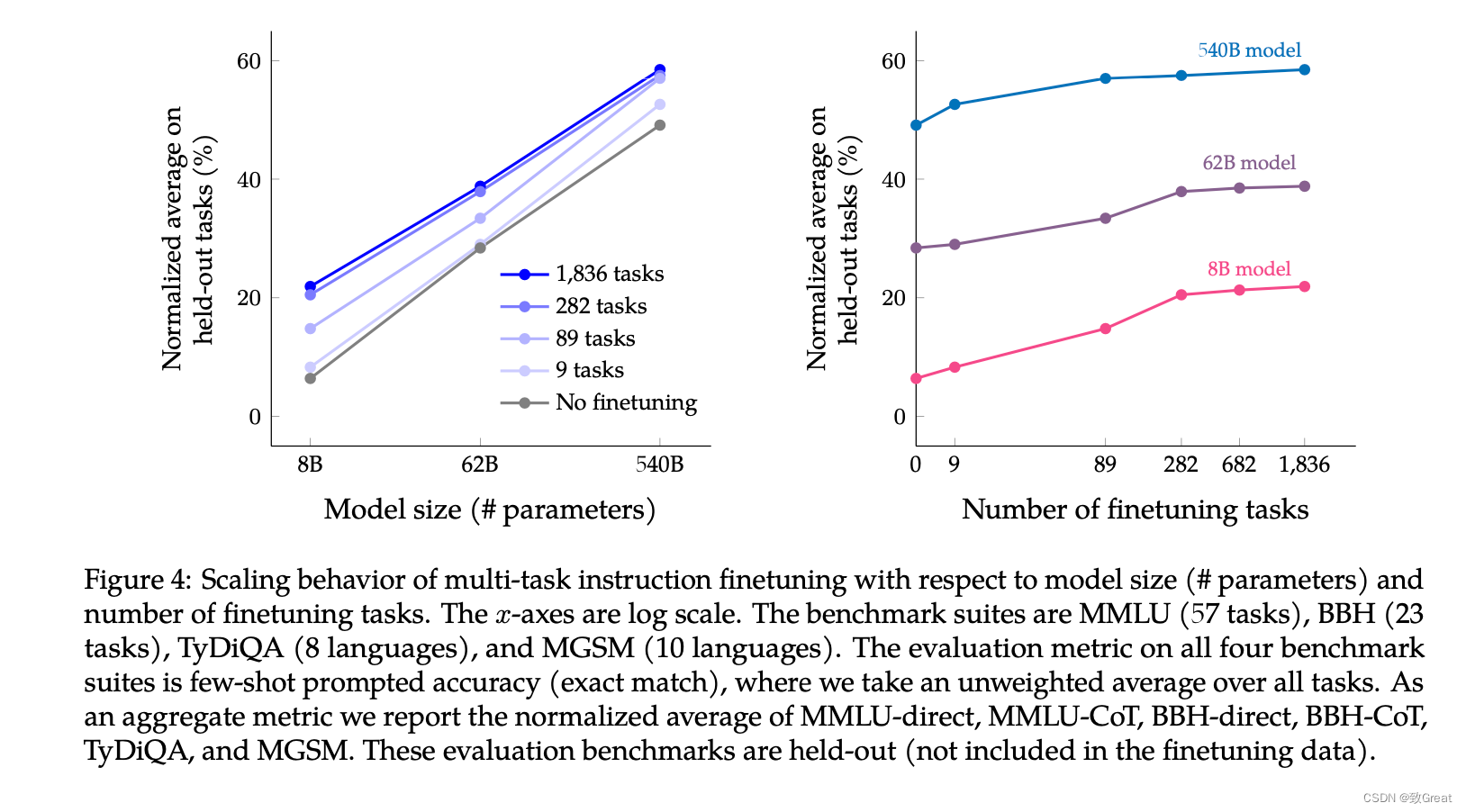
- 随着模型size的增大,模型效果不断提升;
- 随着模型使用的finetune数据集的增多,模型效果也是不断提升的。
CoT对模型效果的影响
由于在指令微调混合中包含思想链 (CoT) 数据,导致 Flan-PaLM 的推理能力得到改进,在多个基准测试中超越了先前的模型。 该研究消融了 CoT 微调数据,表明没有 CoT 的指令微调实际上会降低推理能力。 仅包括九个 CoT 数据集可提高所有评估的性能。

Chain of Thought 数据指令微调的另一个重要好处是解锁零样本推理。 这测试了模型在没有 CoT 的少量示例的情况下产生自己的推理技能的能力。 本次测试使用了 23 项未知挑战的 BBH 基准测试结果。 关键的激活短语是“让我们一步一步地思考”。 PaLM 本身不生成 CoT 数据(尤其是零样本版本)。 该论文中大多数成功的零样本 CoT 实验实际上利用了 InstructGPT(Ouyang 等人,2022),它是指令微调的(我们假设该指令微调包含一些类似 CoT 的数据)。
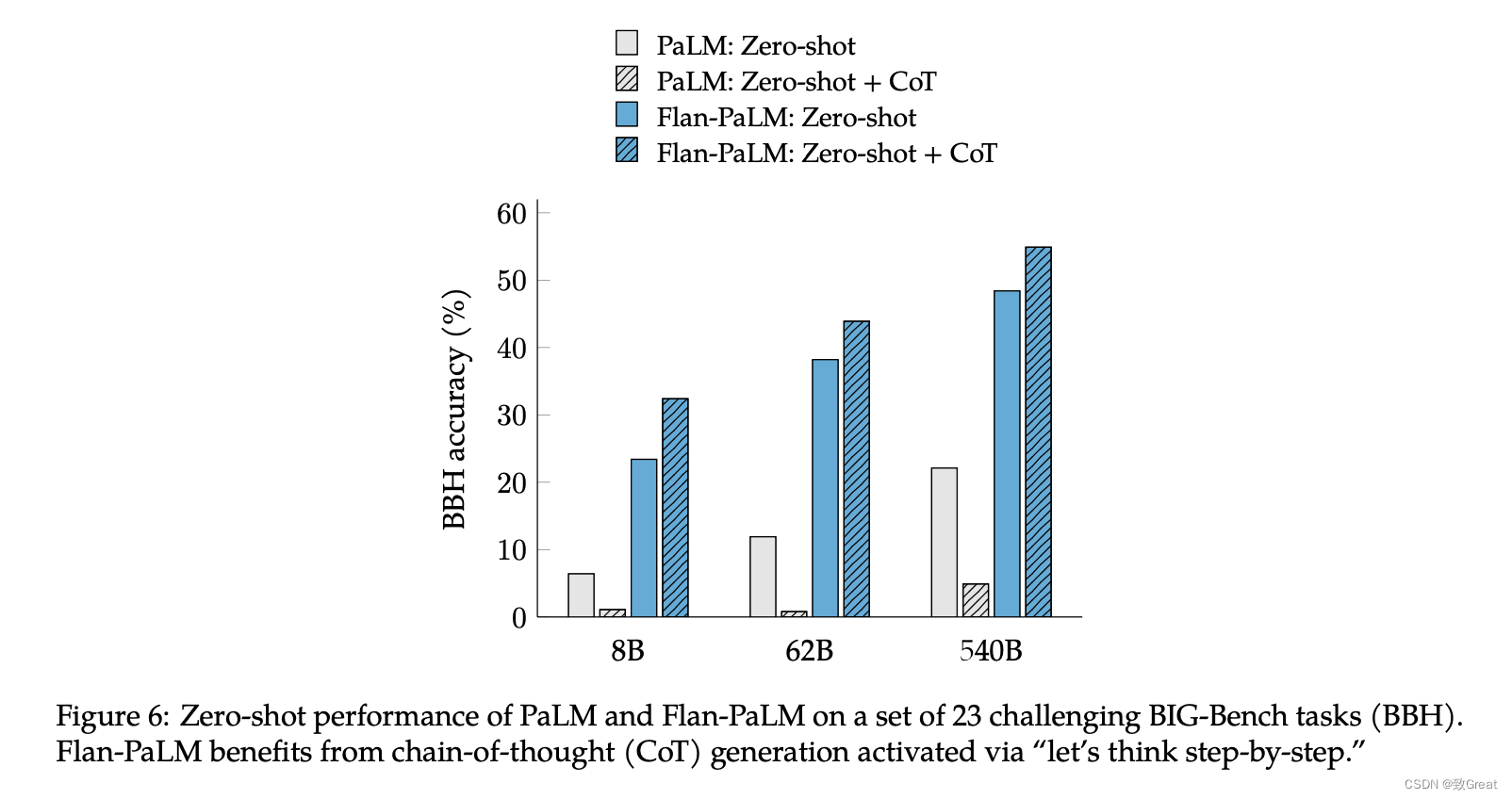
可以看到:
- 对于不加入Flan训练的Palm模型,CoT文本的加入并不能够带来效果的提升;
- 对于Flan之后的Palm模型,CoT能够明显的提升模型的效果;
- Flan本身也能够给模型带来足够的效果提升。
最后,文中还给了几个具体的case如下:
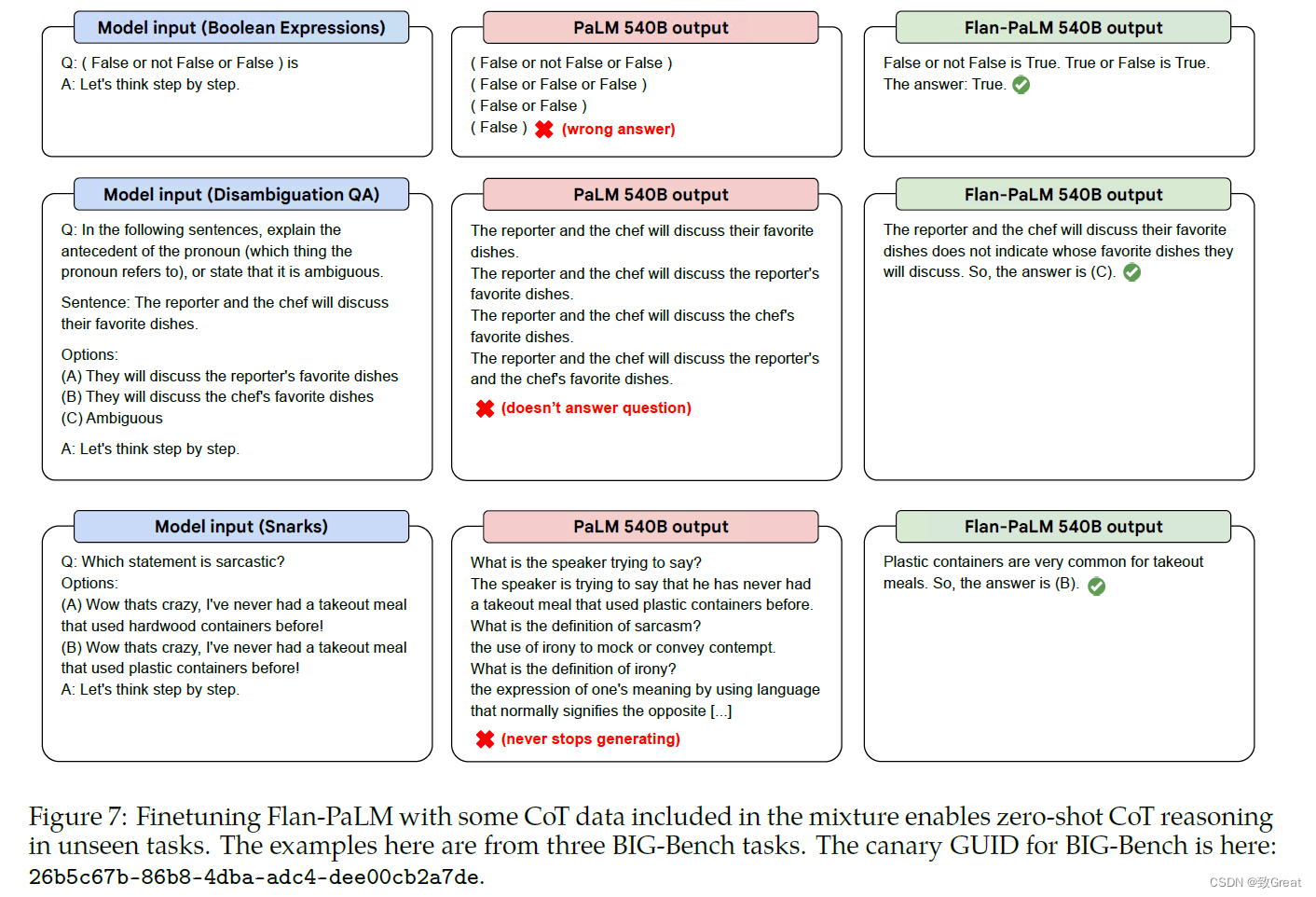
FLAN对T5 和 PaLM 的结果
除了在自回归语言模型的情况下,文中还对T5进行了考察,看了一下T5这种完形填空式的预训练方式得到的大模型对于Flan以及CoT数据集的兼容性,得到结果如下:

指令微调 (Flan) 在其他持续预训练方法的基础上提高了性能。 基准组合是 MMLU(57 个任务)、BBH(23 个任务)、TyDiQA(8 种语言)和 MGSM(10 种语言)。 所有四个基准套件的评估指标都是少量提示的准确性(精确匹配),我们对所有任务取一个未加权的平均值。 作为聚合指标,我们报告了 MMLU-direct、MMLU-CoT、BBH-direct、BBH-CoT、TyDiQA 和 MGSM 的归一化平均值。 这些评估基准是保留的(不包括在微调数据中)。
开放接口人工标注指标
标准基准和矩阵不足以真正理解/评价可用性。 因此,研究团队决定进行人工评估,以调查指令微调对模型对具有挑战性的输入做出开放式反应的能力的影响。 使用一组 190 个示例来评估响应。 该评估集包括以零样本方式向模型提出的问题,涉及五个具有挑战性的类别,每个类别有 20 个问题:创造力、上下文推理、复杂推理、计划和解释。 creativity, reasoning over contexts, complex reasoning, planning, 和 explanation.
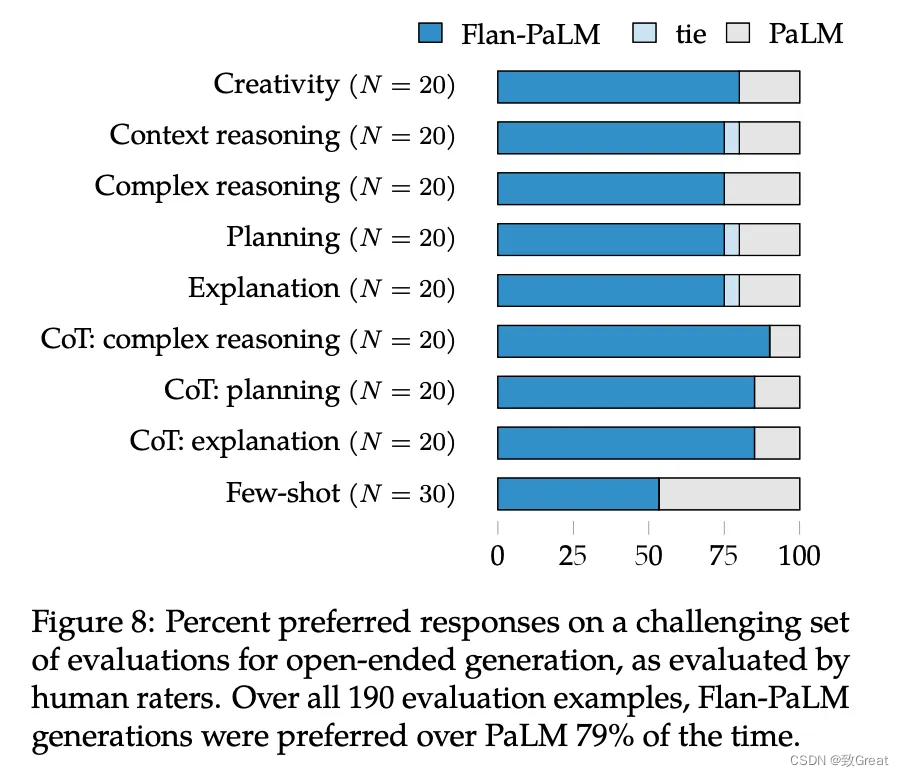
在 190 个示例中,Flan-PaLM 代在 79% 的情况下是首选。 对于每一个零样本设置,Flan-PaLM 都以很大的优势受到青睐,并且对于使用 CoT 触发短语的输入,评分者对 Flan-PaLM 的偏好比 PaLM 进一步增加了约 10%。 至于few-shot,与PaLM相比没有退步。
结论
- 指令微调的 Flan-PaLM 模型以计算高效的方式扩展,参数量扩展到 540B 参数语言模型,任务扩展到 1.8K 微调任务,并在微调中包括思想链 (CoT) 数据。
- Flan-PaLM 在多个基准测试中实现了最先进的性能,例如在五次 MMLU 上达到 75.2%。
- Flan-PaLM 还改进了可用性。