在上一个视频中,您被介绍到了生成性AI项目的生命周期。
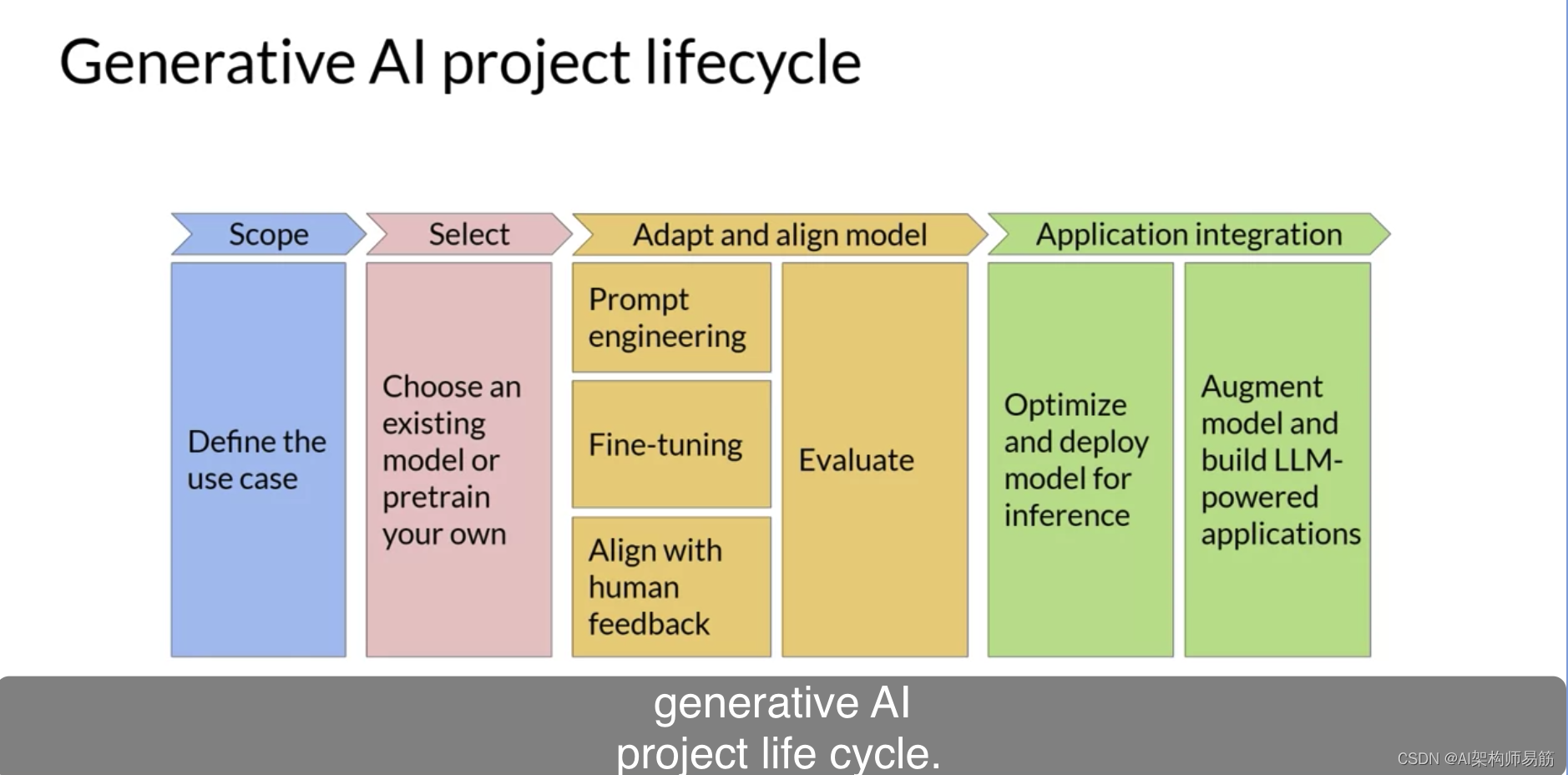
如您所见,在您开始启动您的生成性AI应用的有趣部分之前,有几个步骤需要完成。一旦您确定了您的用例范围,并确定了您需要LLM在您的应用程序中的工作方式,您的下一步就是选择一个要使用的模型。
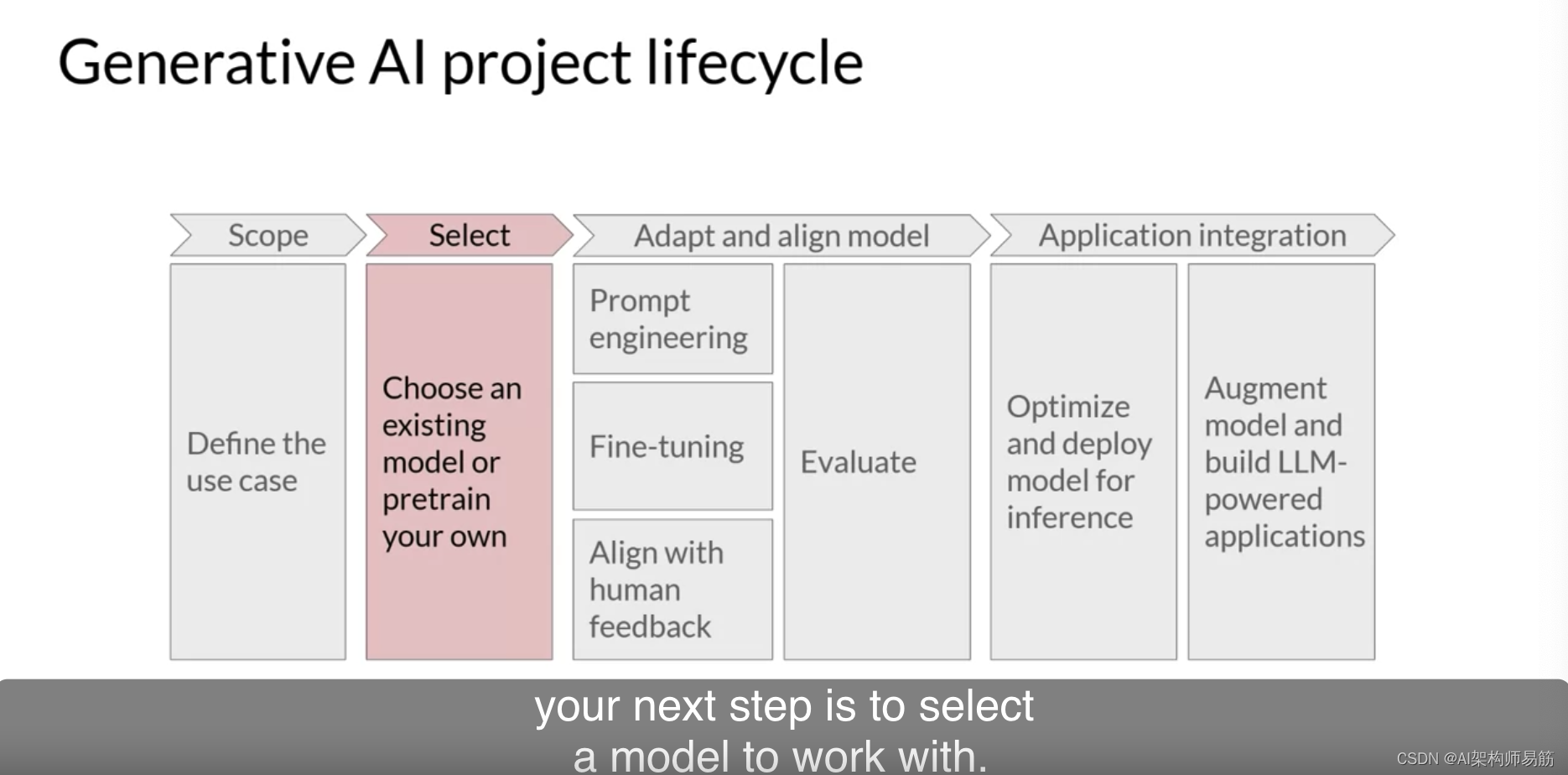
您首先的选择将是使用现有的模型还是从头开始训练您自己的模型。在某些特定情况下,从头开始训练您自己的模型可能是有利的,您将在本课程后面了解到这些情况。

但是,通常情况下,您将使用现有的基础模型开始开发您的应用程序。许多开源模型都可供像您这样的AI社区成员在您的应用程序中使用。一些主要框架的开发者,如用于构建生成性AI应用的Hugging Face和PyTorch,已经策划了您可以浏览这些模型的中心。
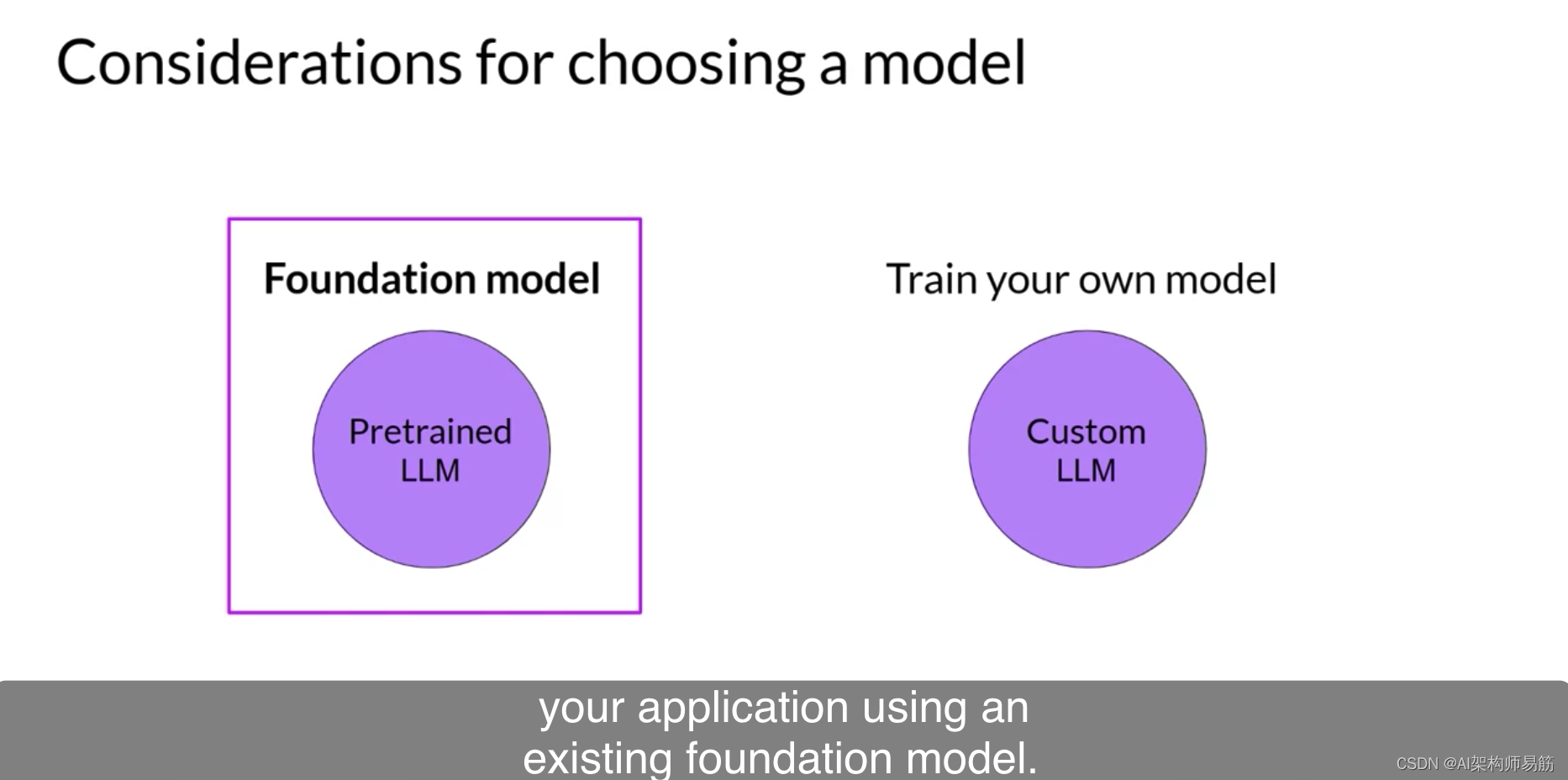
这些中心的一个非常有用的特点是包括模型卡片,描述了每个模型的最佳用例、如何进行训练以及已知的限制的重要细节。您将在本周结束时的阅读材料中找到这些模型中心的一些链接。
您选择的确切模型将取决于您需要执行的任务的细节。Transformers模型架构的变体适用于不同的语言任务,这主要是因为模型训练方式的差异。为了帮助您更好地了解这些差异,并发展关于哪个模型用于特定任务的直觉,让我们仔细看看大型语言模型是如何被训练的。有了这些知识,您将更容易浏览模型中心并找到最适合您用例的模型。
首先,让我们从高层次看看LLMs的初始训练过程。这个阶段通常被称为预训练。

如您在第1课中所见,LLMs编码了语言的深度统计表示。这种理解是在模型的预训练阶段发展起来的,当模型从大量的非结构化文本数据中学习时。这可以是GB、TB,甚至是PB大小的非结构化文本。这些数据来自许多来源,包括从互联网上抓取的数据和为训练语言模型专门组装的文本语料库。
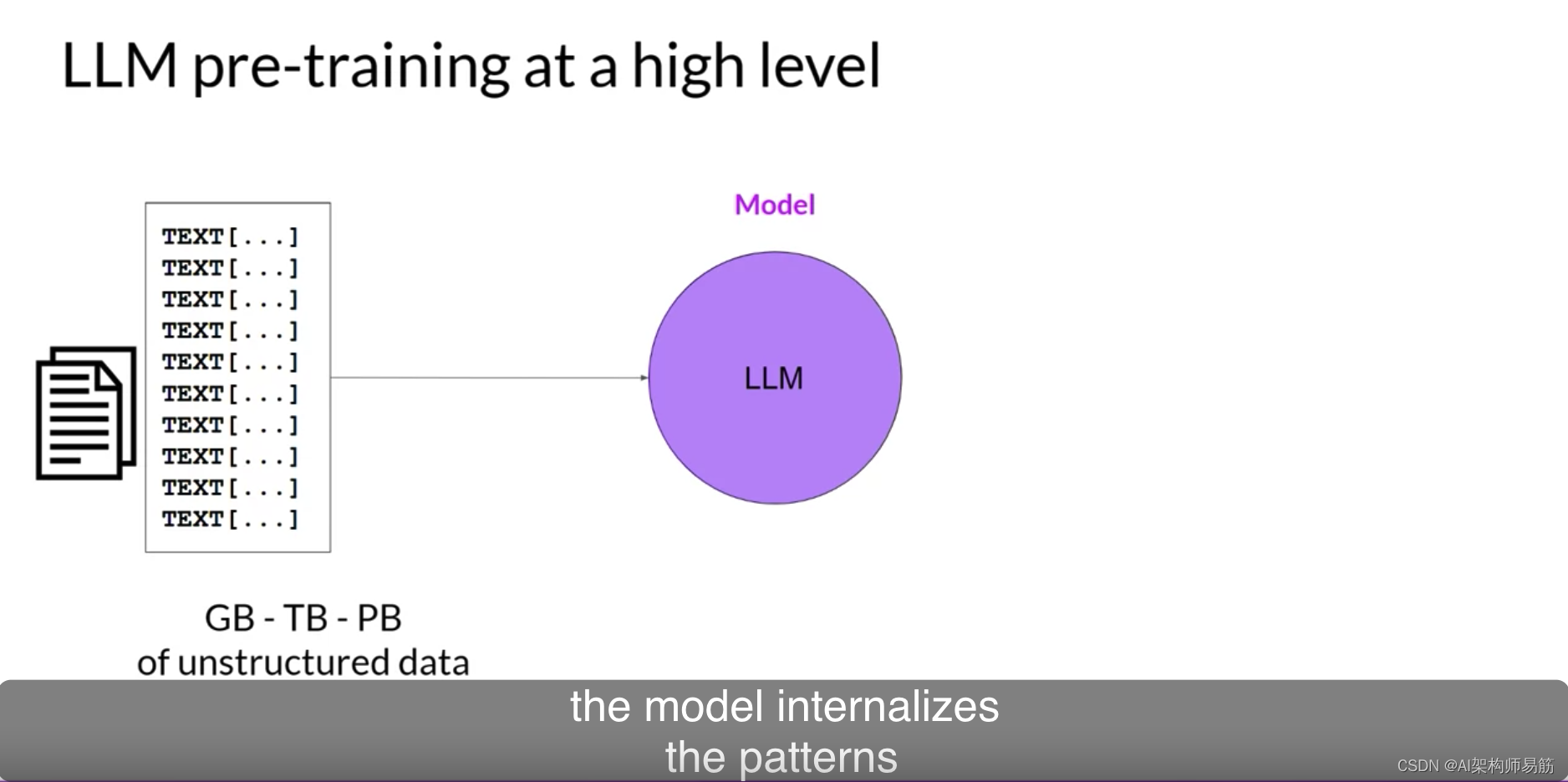
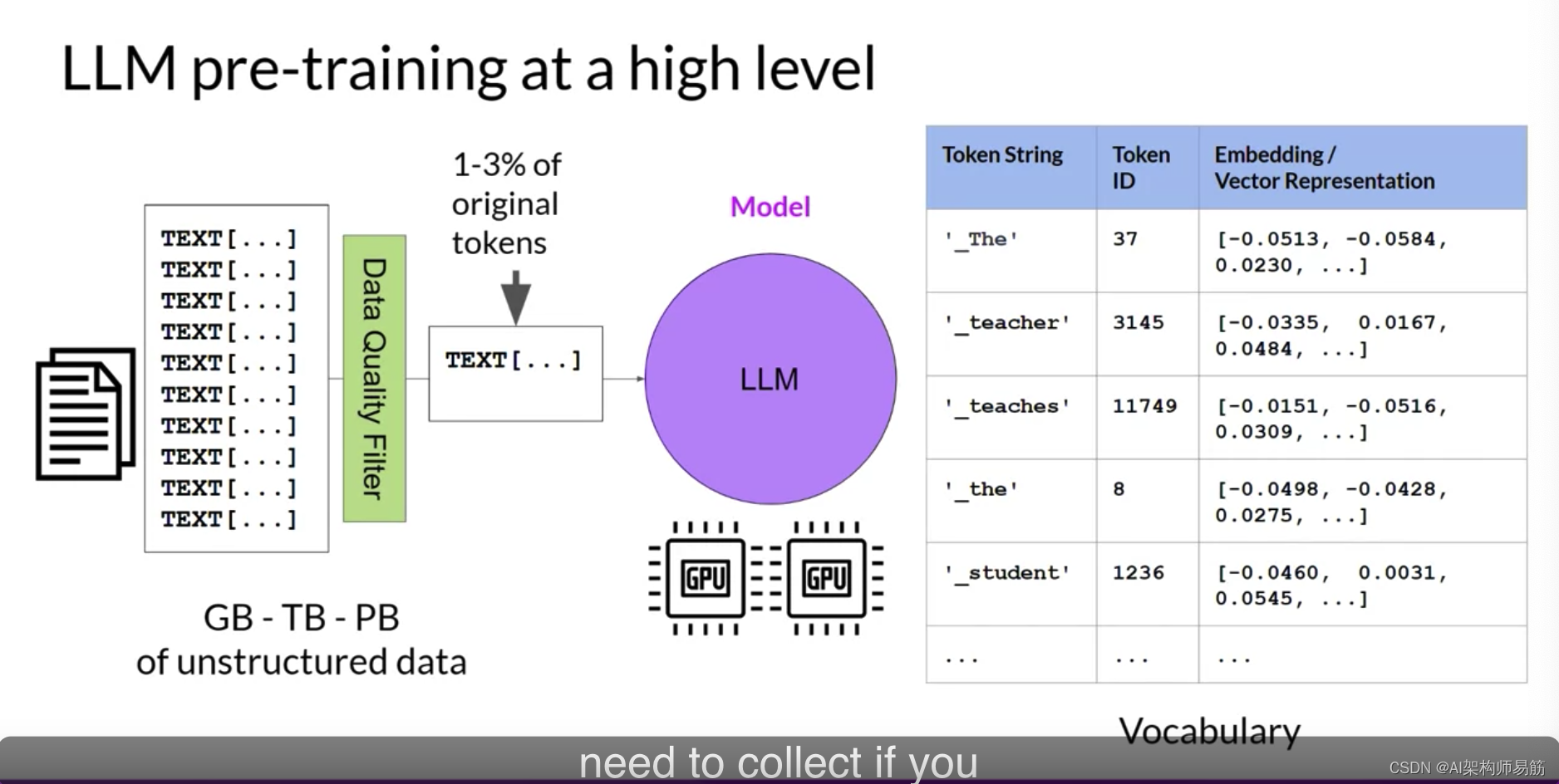
在这个自监督学习步骤中,模型内化了语言中存在的模式和结构。这些模式然后使模型能够完成其训练目标,这取决于模型的架构,正如您很快将看到的那样。在预训练期间,模型权重得到更新,以最小化训练目标的损失。编码器为每个令牌生成一个嵌入或向量表示。预训练也需要大量的计算和使用GPUs。

请注意,当您从公共网站如互联网抓取训练数据时,您通常需要处理数据以提高质量,解决偏见,并删除其他有害内容。由于这种数据质量策划,通常只有1-3%的令牌用于预训练。当您估计需要收集多少数据时,如果您决定预训练您自己的模型,您应该考虑这一点。
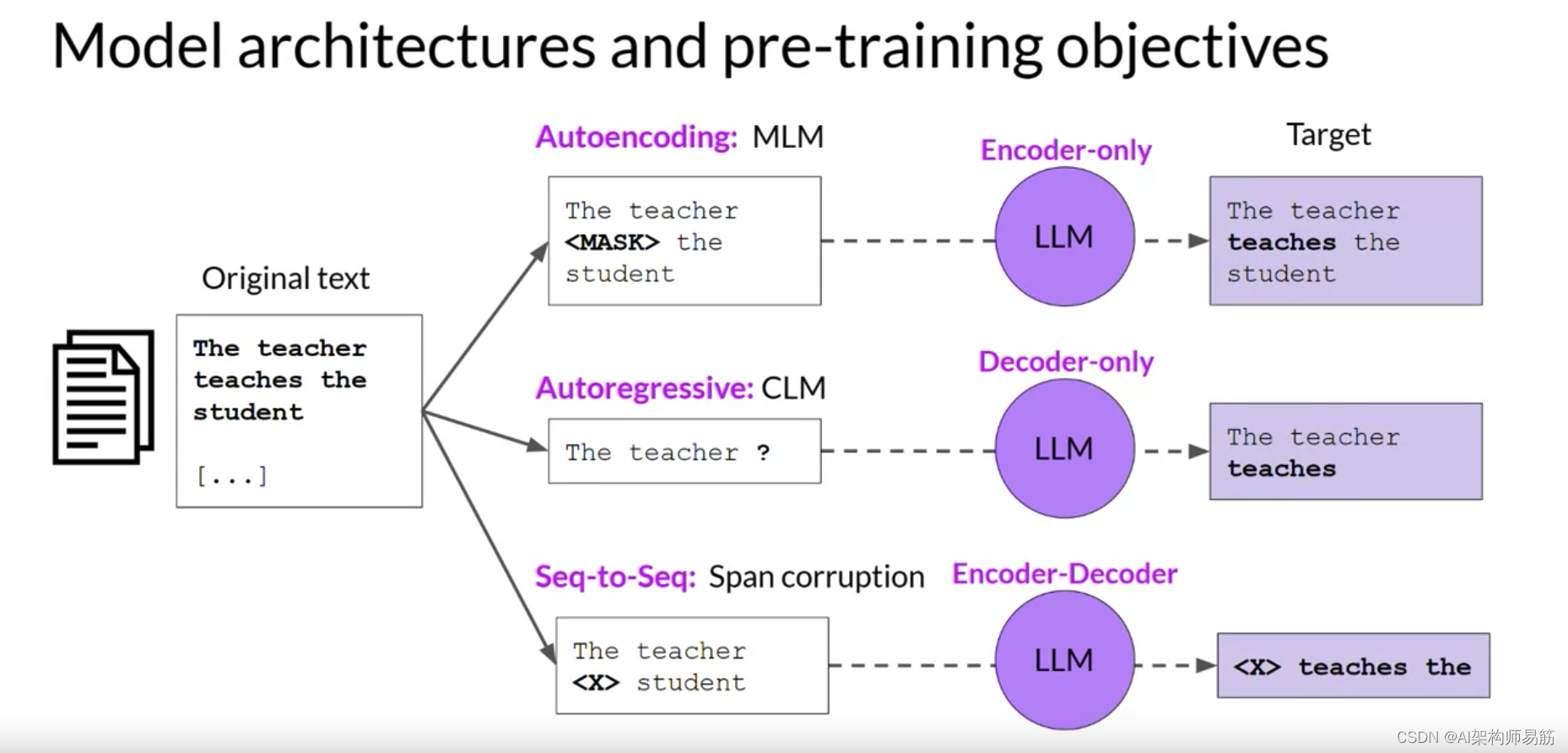
本周早些时候,您看到Transformers模型有三种变体;仅编码器、编码器-解码器模型和仅解码器。
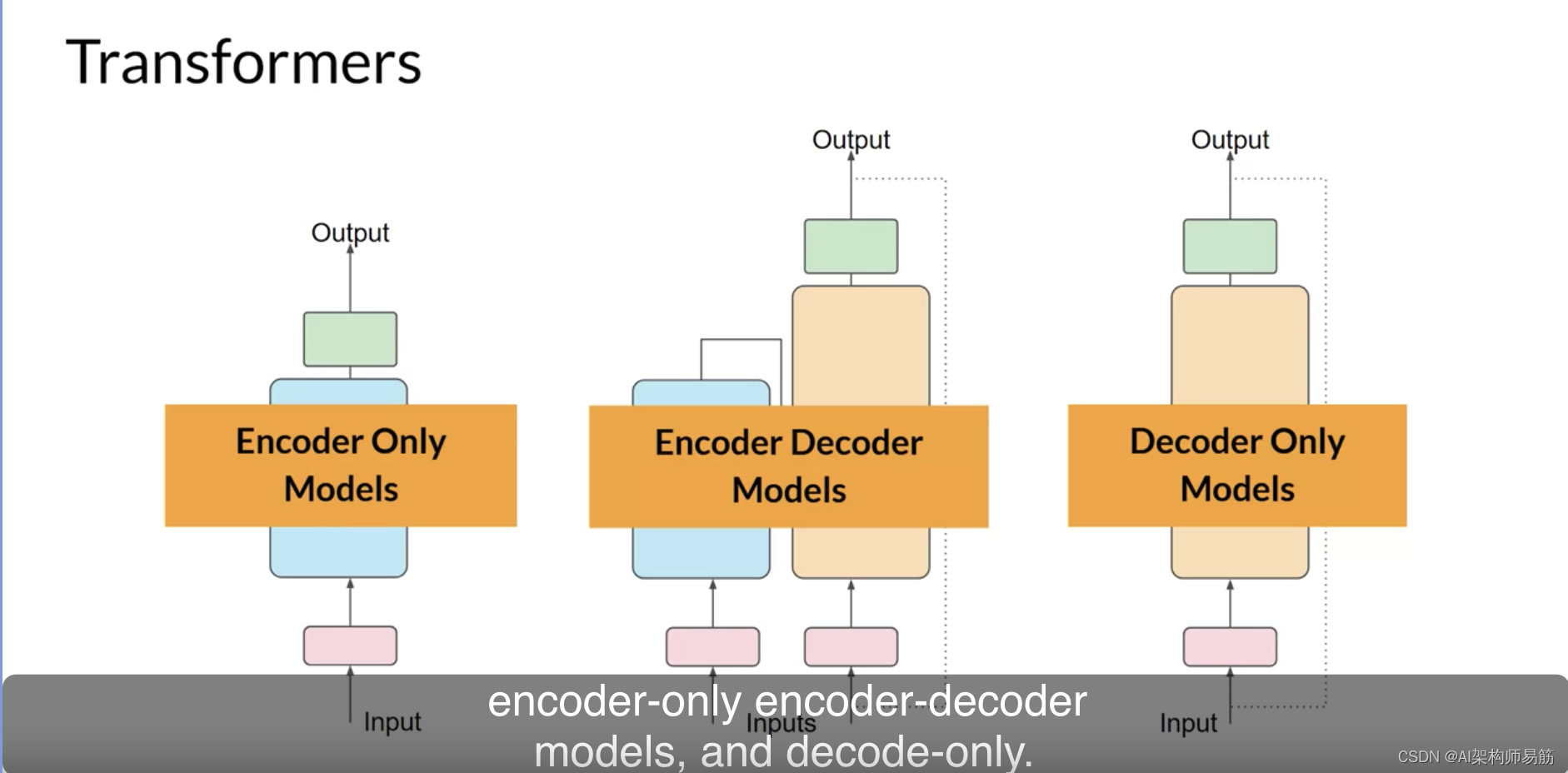
每一个都是基于一个不同的目标进行训练的,因此学会执行不同的任务。
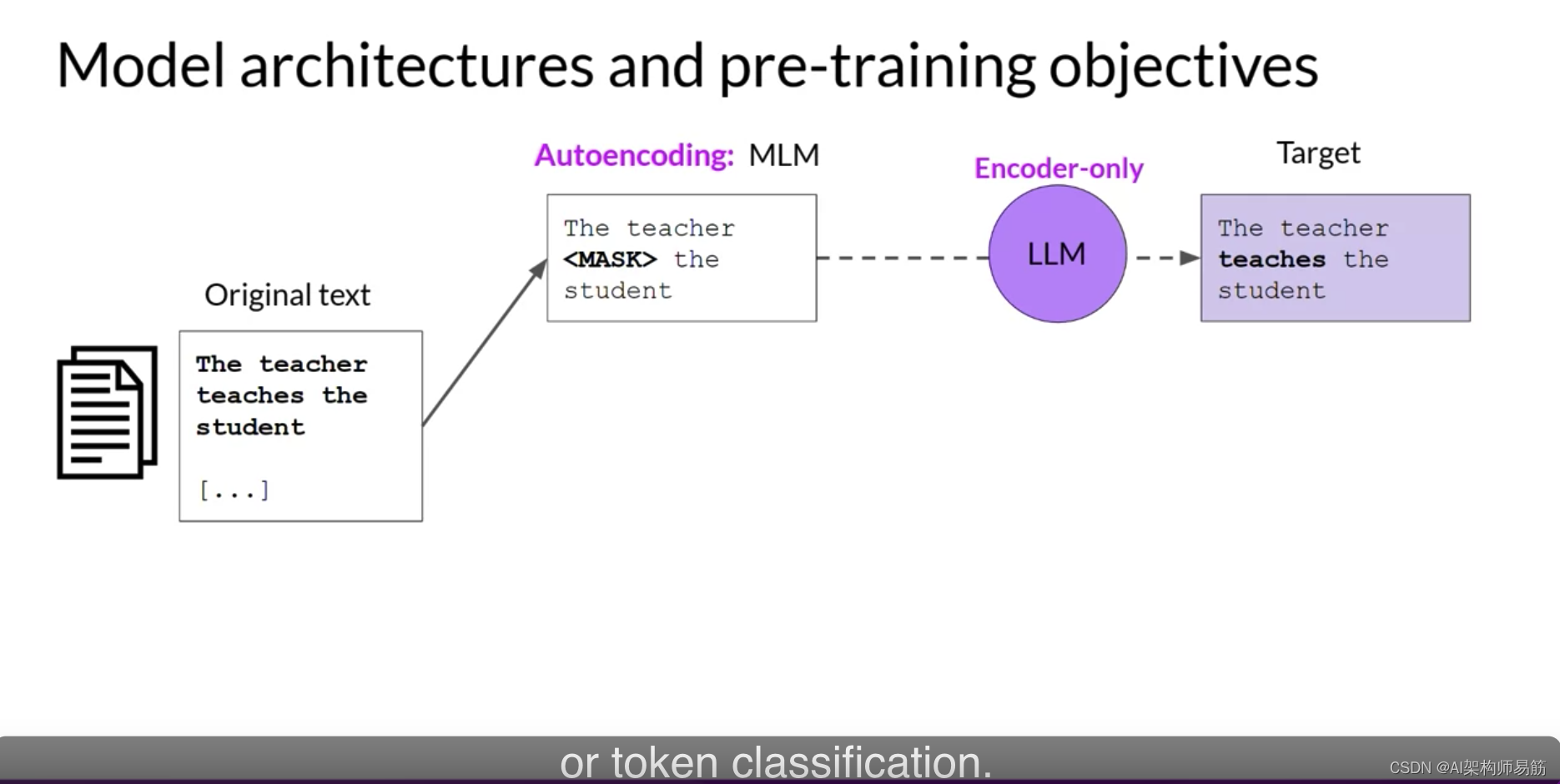
仅编码器模型也被称为自动编码模型,它们使用遮罩语言建模进行预训练。

这里,输入序列中的令牌被随机遮罩,训练目标是预测遮罩令牌以重构原始句子。

这也被称为去噪目标。

自动编码模型产生了输入序列的双向表示,这意味着模型对令牌的整个上下文有了解,而不仅仅是之前的单词。仅编码器模型非常适合从这种双向上下文中受益的任务。

您可以使用它们执行句子分类任务,例如情感分析或令牌级任务,如命名实体识别或单词分类。自动编码模型的一些众所周知的示例是BERT和RoBERTa。

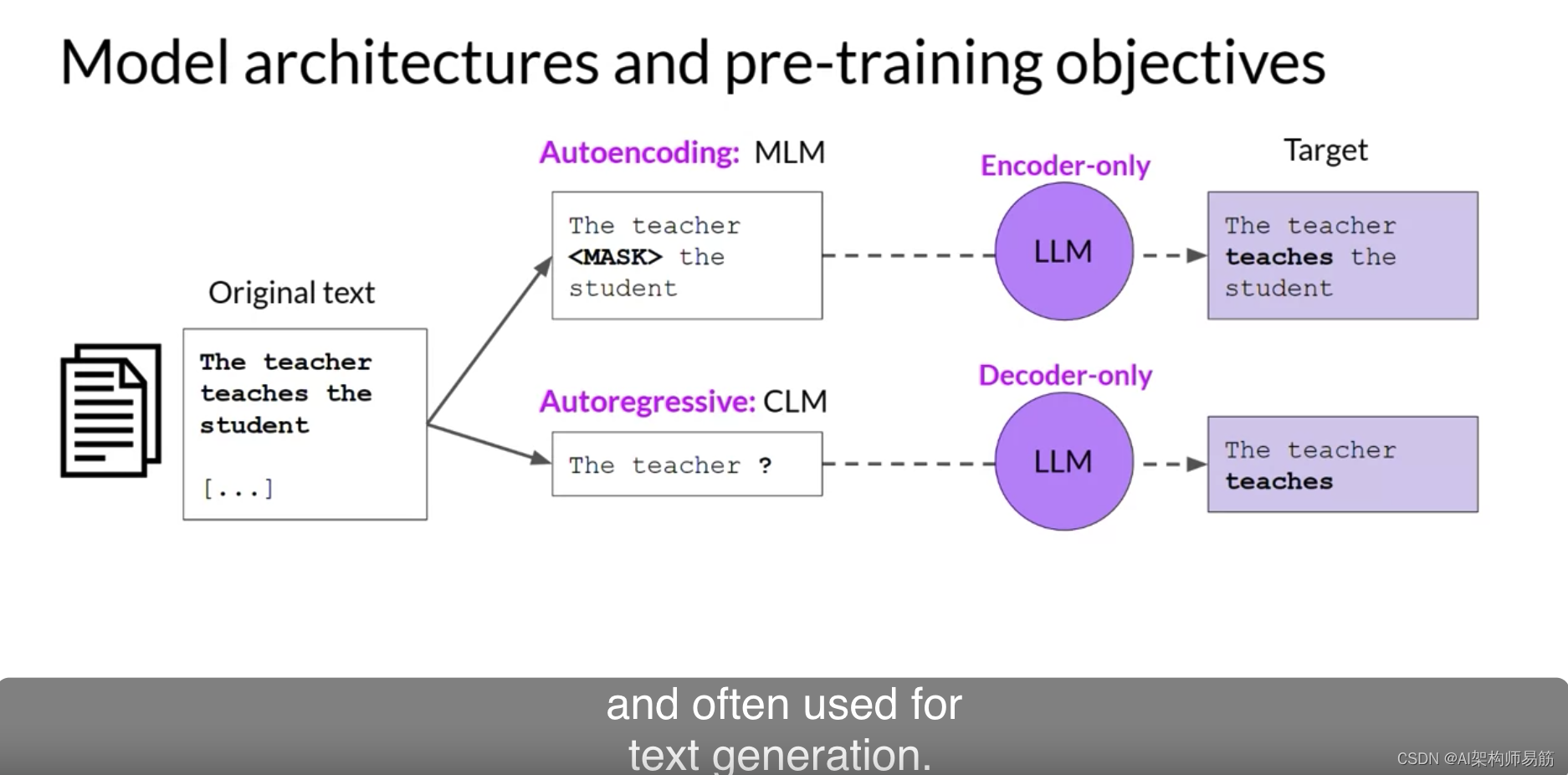
现在,让我们看看仅解码器或自回归模型,它们使用因果语言建模进行预训练。这里,训练目标是基于之前的令牌序列预测下一个令牌。
预测下一个令牌有时被研究人员称为完整的语言建模。基于解码器的自回归模型,遮罩输入序列,只能看到直到问题令牌的输入令牌。
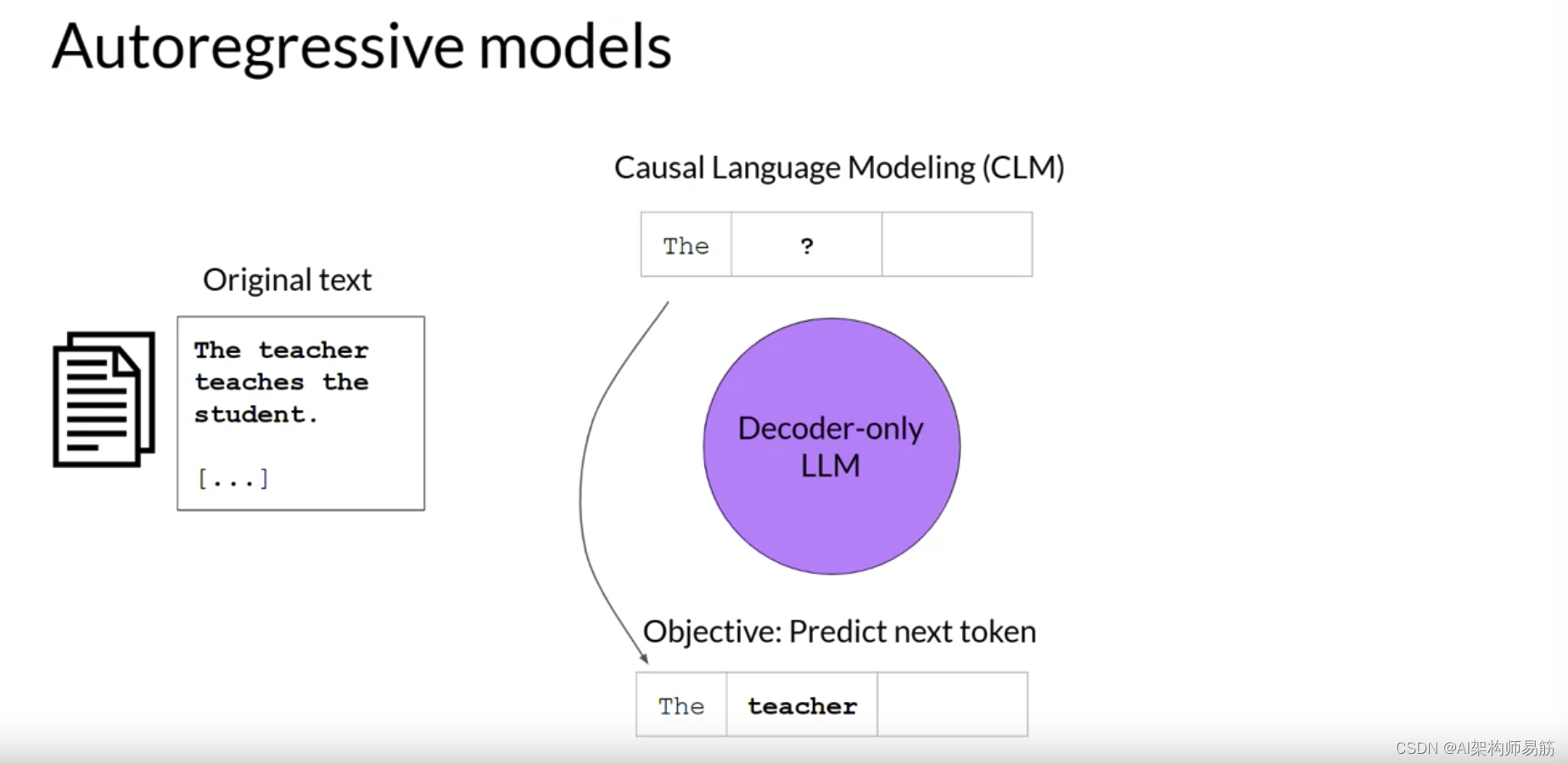
模型不知道句子的结尾。然后,模型一个接一个地迭代输入序列来预测下一个令牌。

与编码器架构相反,这意味着上下文是单向的。

通过学习从大量示例中预测下一个令牌,模型建立了语言的统计表示。这种类型的模型使用原始架构的解码器组件,而不使用编码器。

仅解码器模型通常用于文本生成,尽管较大的仅解码器模型显示出强大的Zero shot推理能力,并且通常可以很好地执行一系列任务。GPT和BLOOM是基于解码器的自回归模型的一些众所周知的示例。

Transformers模型的最后一个变体是使用原始Transformers架构的编码器和解码器部分的序列到序列模型。预训练目标的确切细节因模型而异。一个受欢迎的序列到序列模型T5,使用Span corruption跨度腐败预训练编码器,这遮罩随机输入令牌序列。那些遮罩序列然后被替换为一个唯一的哨兵令牌,这里显示为x。哨兵令牌是添加到词汇表的特殊令牌,但不对应于输入文本的任何实际单词。
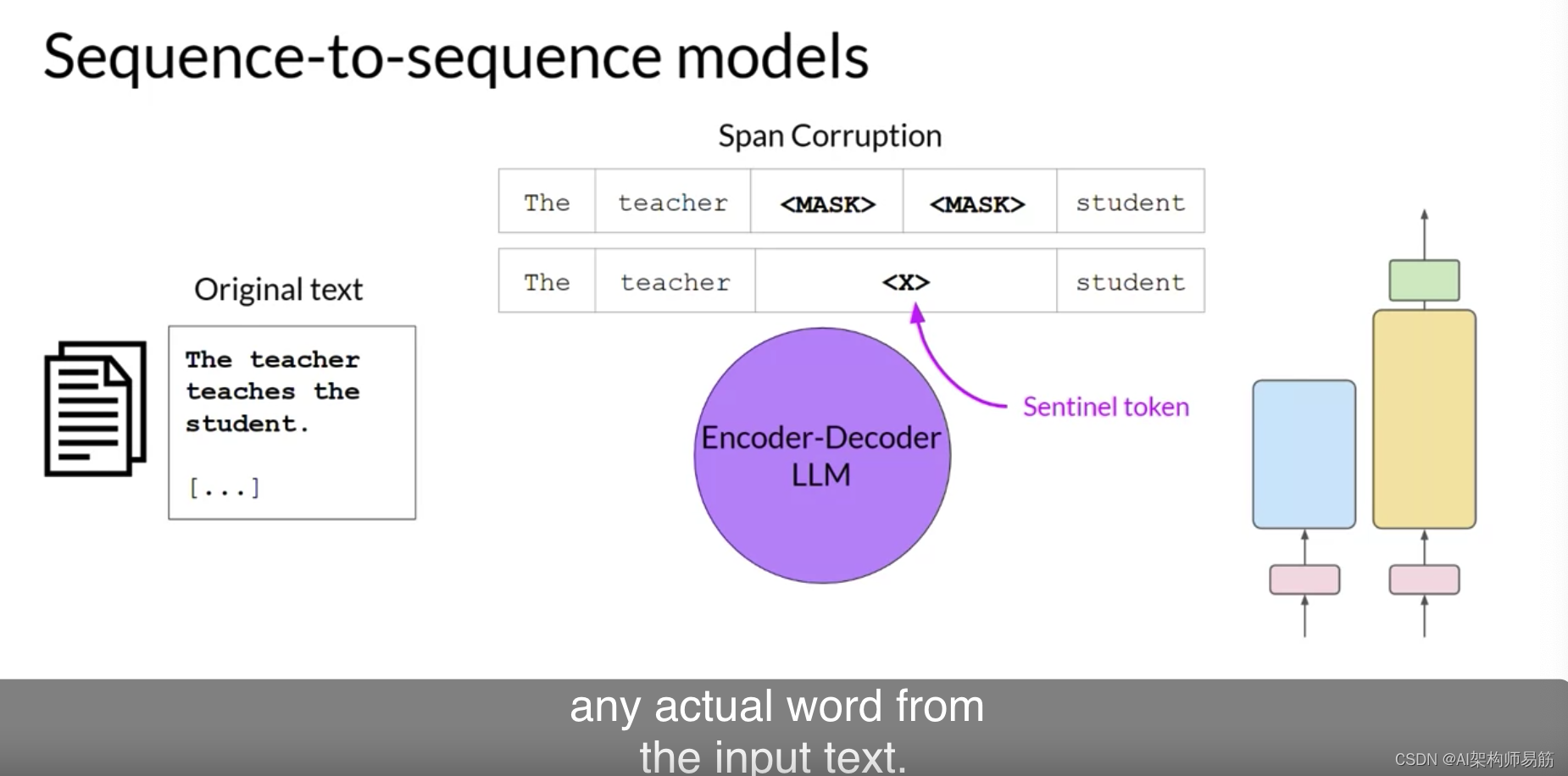
解码器然后被分配自回归地重建遮罩令牌序列。输出是哨兵令牌后面的预测令牌。
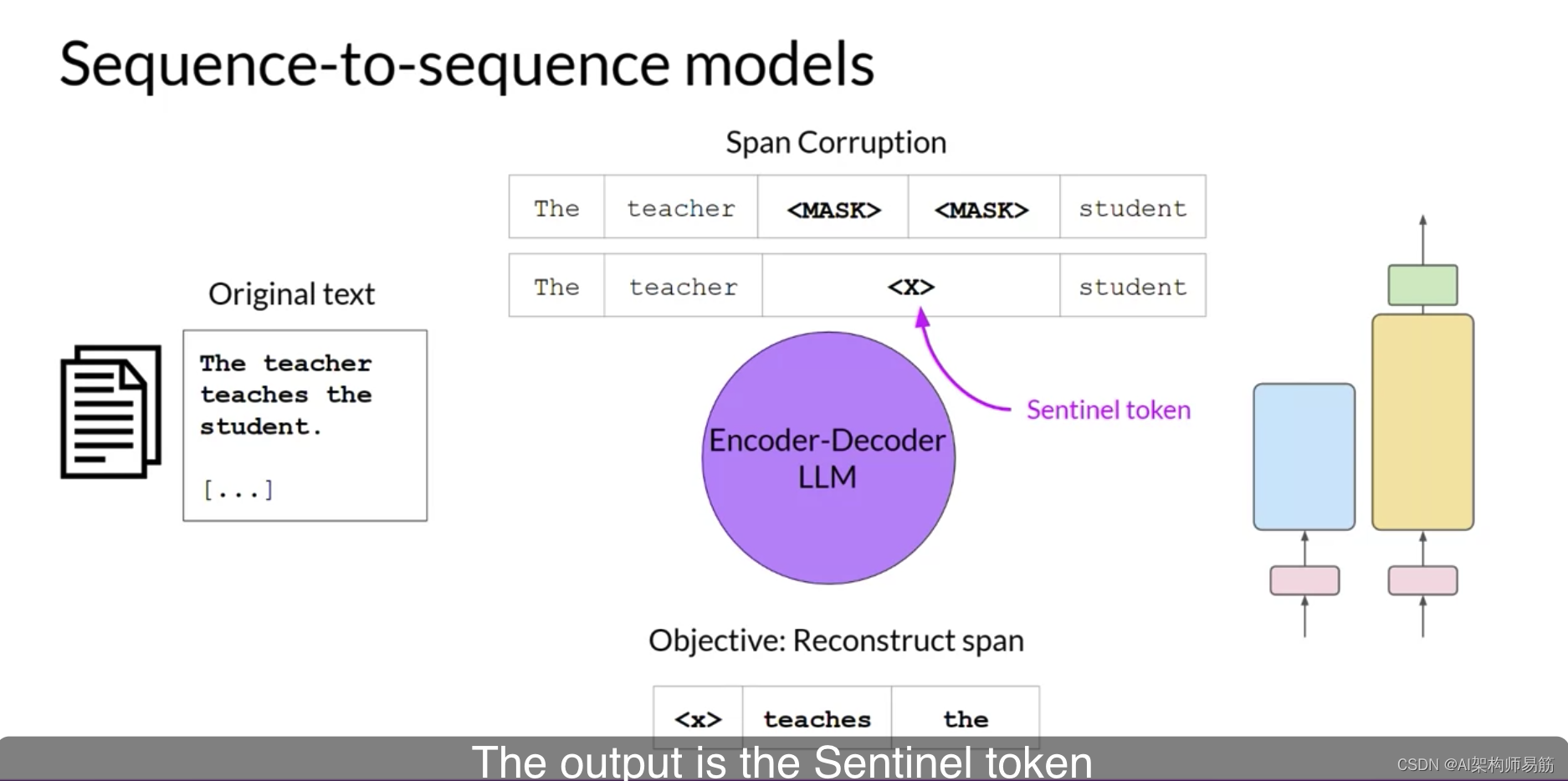
您可以使用序列到序列模型进行翻译、摘要和问答。当您有一体文本作为输入和输出时,它们通常是有用的。除了T5,您将在本课程的实验室中使用,另一个众所周知的编码器-解码器模型是BART,不是Bird。

总之,这是一个快速比较不同的模型架构和预训练目标的目标。自动编码模型使用遮罩语言建模进行预训练。它们对应于原始Transformers架构的编码器部分,通常与句子分类或令牌分类一起使用。
自回归模型使用因果语言建模进行预训练。这种类型的模型使用原始Transformers架构的解码器组件,并经常用于文本生成。
序列到序列模型使用原始Transformers架构的编码器和解码器部分。预训练目标的确切细节因模型而异。T5模型使用span corruption跨度腐败进行预训练。序列到序列模型通常用于翻译、摘要和问答。
现在您已经看到了这些不同的模型架构是如何被训练的,以及它们适合的特定任务,您可以选择最适合您用例的模型类型。还有一件事要记住的是,任何架构的较大模型通常更有能力很好地执行它们的任务。研究人员发现,模型越大,就越有可能在没有额外的上下文学习或进一步训练的情况下按照您的需要工作。这种观察到的模型能力随大小增加的趋势,近年来推动了更大模型的发展。
这种增长是由研究中的拐点驱动的,如高度可扩展的Transformers架构的引入,用于训练的大量数据的访问,以及更强大的计算资源的开发。
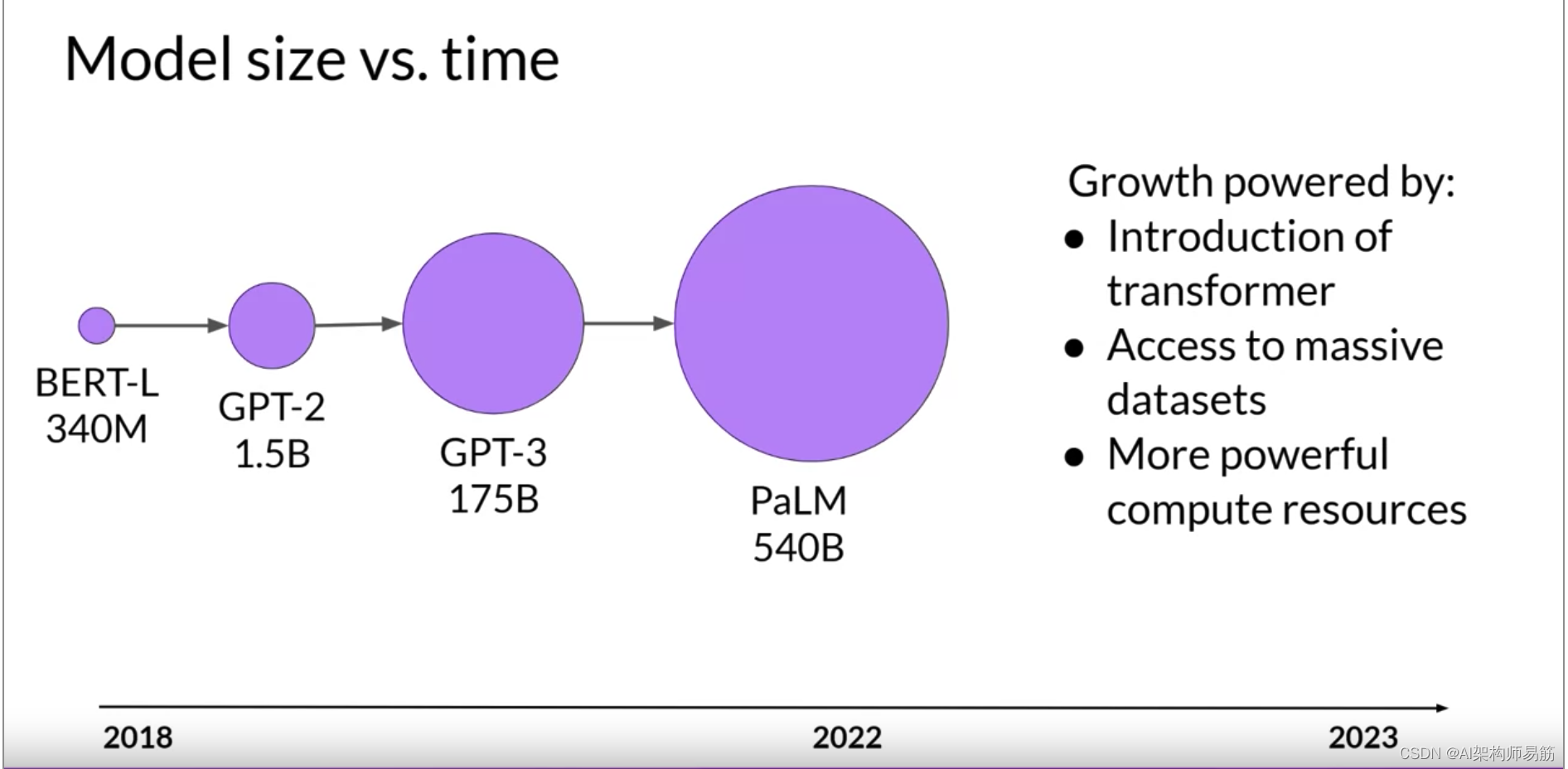
这种模型大小的稳定增长实际上使一些研究人员推测LLMs存在一个新的摩尔定律。像他们一样,您可能会问,我们是否可以只是继续添加参数来增加性能并使模型更智能?这种模型增长可能会导致什么?

虽然这听起来很棒,但事实证明,训练这些巨大的模型是困难和非常昂贵的,以至于不断地训练更大和更大的模型可能是不可行的。让我们在下一个视频中仔细看看与训练大型模型相关的一些挑战。
参考
https://www.coursera.org/learn/generative-ai-with-llms/lecture/2T3Au/pre-training-large-language-models