Instruction Mining:High-Quality Instruction Data Selection for Large Language Models
Introduction
本文提出了一种通过线性规则筛选高质量数据的方案(有种套娃的感觉),目前验证指令数据的质量的方法大多数采用GPT+Few Shot 或者 微调+验证的方案,作者认为这种方法太贵了,提出了一种通过indicator过滤数据的方法,不用微调模型就可以相对评估指令数据的方案。
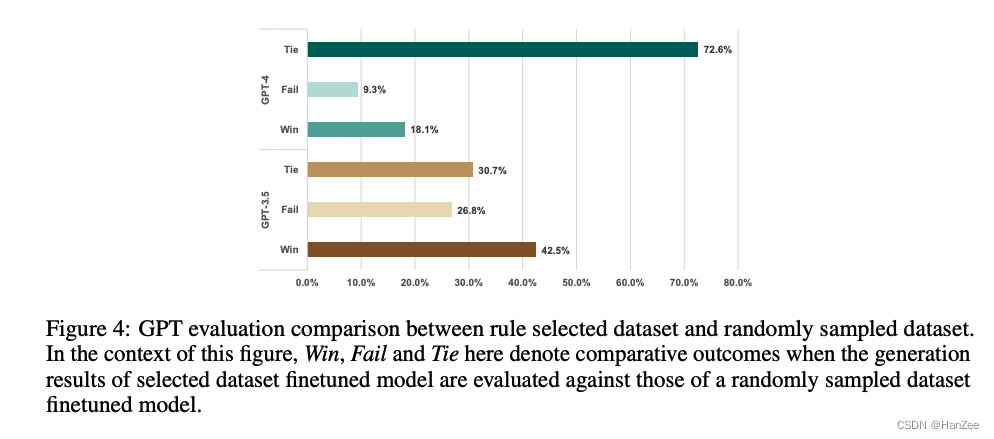
作者融合一些开源的指令数据集构成data pool,然后对比了随机sample和使用indicator过滤的方式,最终发现它有42.5的概率战胜随机采样。
Method
符号定义:数据质量Q,D数据,M模型,M撇微调后的模型,L表示损失,D-eval表示测试数据。
作者首先做了一个假设:
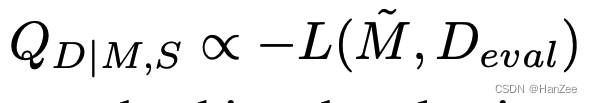
上面的公式表明指令数据的质量Q与微调后模型在验证集的损失成正比。
由于微调+推理不是那么高效,所以作者定义了一个·indicaor :=I,把这个评估的过程想成一个房价预测的过程,每个indicator就是影响房价的因素,如城市、人口,而在本文中表示指令的长度、奖励模型的分数等等。
假设它可以近似等于微调后的模型在测试集上面的Loss,也就是可以满足下面的公式。
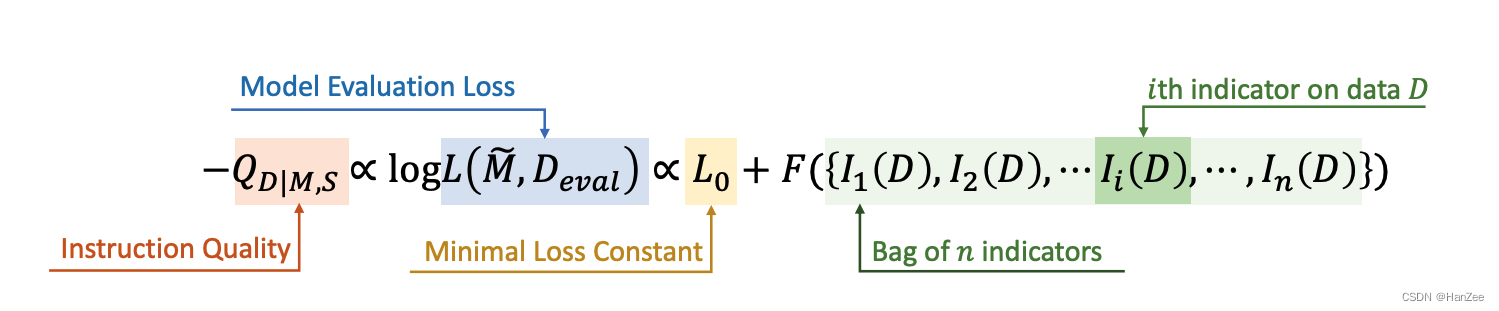
然后作者通过这种近似继续推倒
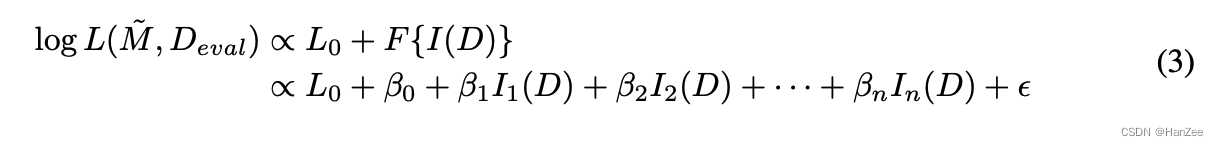
其中beta是线性回归的系数,L0与theta为常数,I(D)为数据在每个Indicator上面的数值,可以直接获得,那么Y就是估计的数据质量,而真实值用eval 上面的loss近似替代。
然后作者通过最小二乘法得到下面的权重:
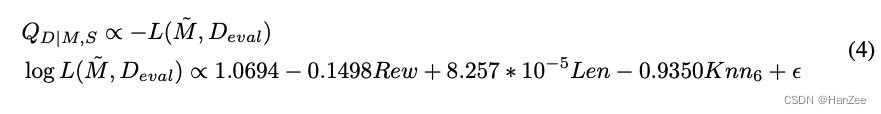
这样就可以在真实数据上筛选样本,然后下面是与真实数据上随机采样与筛选的结果对比:
参考
https://arxiv.org/pdf/2307.06290.pdf