Rasa 3.x 学习系列-Benchmarking Language Models
从字面上看,基准测试是进行测量的标准参考点。在 AI 中,基准是一个集体数据集,由资金充足的大学的行业和学术团体开发,社区已经同意用它来衡量模型的性能。例如,SNLI 是 570k条人工编写的英语句子对的集合,这些句子对被手动标记为平衡分类,标签为蕴含、矛盾和中性,用于衡量自然语言推理任务的性能。
近年来,BERT 预训练语言模型对于上下文 NLU 自然语言理解是革命性的,在推理、情感相似性、实体提取等 NLP 任务上取得出色的效果。衡量语言的性能是非常重要的,更面向应用程序,越来越多地从单任务转移到多任务,多任务基准的示例是 GLUE/BLUE 基准。
- 著名的基准测试如ImageNet、Squad和SuperGLUE
- 较老的标准是SPEC,成立于1988年,用于评估新一代计算系统性能和效率的标准化基准工具
- DARPA和NIST是语音识别和手写数据集(MNIST)的早期基准。
- 语言模型的性能是用困惑度、交叉熵和BPC来衡量
- 对于特定任务的NLP,采用NLI、相似性等测量下游任务的性能。
近期,在数据集上,模型的表现越来越好于人类,比如AlphaGo击败世界冠军, MNIST花了15年的时间来超过人类,而GLUE只花了一年时间,从而导致基准测试饱和
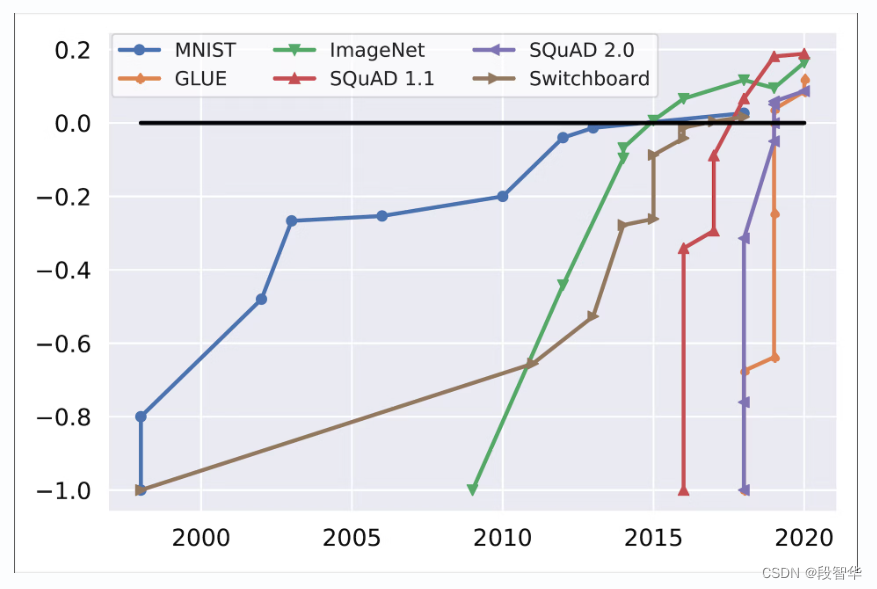
基准饱和度随时间变化 ,初始性能和人类性能分别归一化为 -1 和 0 (Kiela et al., 2021)。
在基准任务上超过人类性能的模