线性回归可以说是最简单的机器学习入门了,上一篇我们使用了一个最简单的模型,只有一个变量,只有一次方。机器很完美的给出了模型和正确的结论。
这一篇我们来看看一些复杂的情况。
所有的数据下载地址:https://gitee.com/tianyalei/machine_learning,按对应章节查找。
多个变量线性回归
人们能立即想到的一个例子就是给房子定价。房子的价格(因变量)是很多自变量 — 房子的面积、占地的大小、厨房是否有花岗石以及卫生间是否刚重装过等的结果。所以,不管是购买过一个房子还是销售过一个房子,您都可能会创建一个回归模型来为房子定价。这个模型建立在邻近地区内的其他有可比性的房子的售价的基础上(训练数据),然后再把您自己房子的值放入此模型来产生一个预期价格。
数据是这样的,house.arff:
@RELATION house @ATTRIBUTE houseSize NUMERIC @ATTRIBUTE lotSize NUMERIC @ATTRIBUTE bedrooms NUMERIC @ATTRIBUTE granite NUMERIC @ATTRIBUTE bathroom NUMERIC @ATTRIBUTE sellingPrice NUMERIC @DATA 3529,9191,6,0,0,205000 3247,10061,5,1,1,224900 4032,10150,5,0,1,197900 2397,14156,4,1,0,189900 2200,9600,4,0,1,195000 3536,19994,6,1,1,325000 2983,9365,5,0,1,230000
属性分别是房子面积(平方英尺)、占地的大小、卧室、花岗岩、卫生间数量,结果是销售价格。
这样的多维度,已经超过二维坐标系所能表达的了,我们已经很难在图上画出这样的展示效果。
从生活经验上看,我们其实也能给出一些自己的估计,譬如面积大的会贵一些、有卫生间会贵一些。但没办法形成一个有效的有规律的模型。那么就让weka来告知我们怎么来建立这个模型吧
和上一篇一样的方式,导入数据。
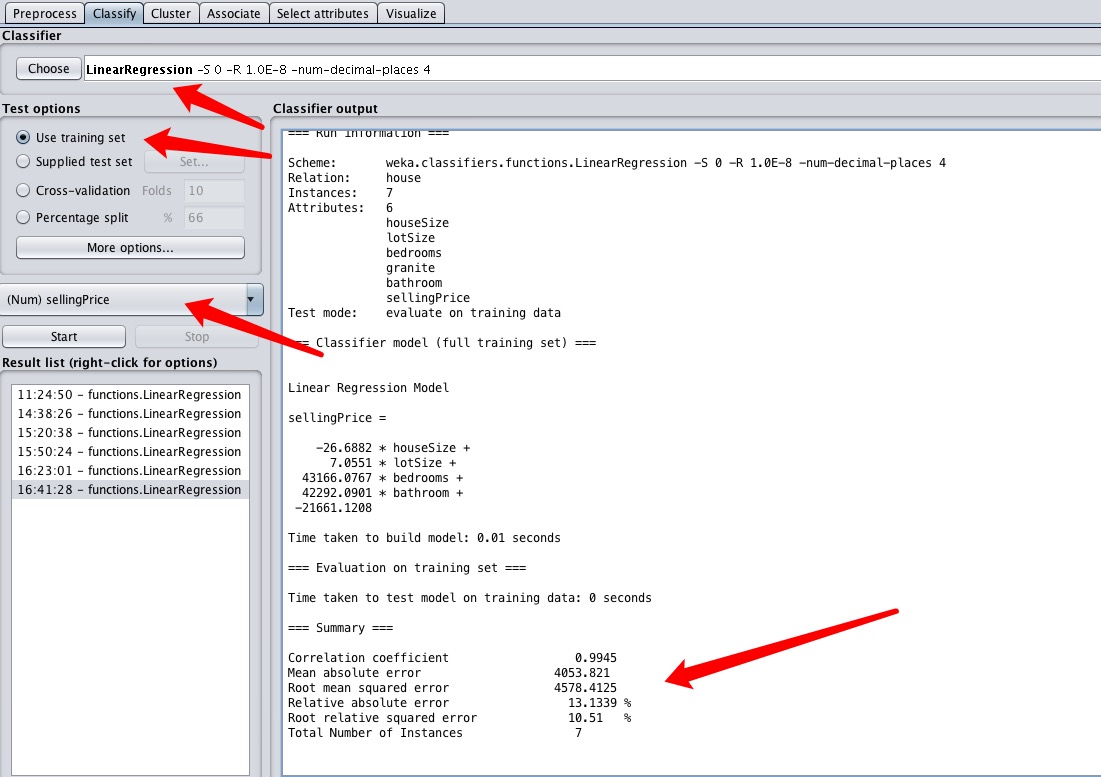
然后使用线性回归训练模型,得到如图的结果。同样的,结果的参数解释看这篇
Relative absolute error 和 Root relative squared error:
举个例子来说明:实际值为500,预测值为450,则绝对误差为50;实际值为2,预测值为1.8,则绝对误差为0.2。这两个数字50和0.2差距很大,但是表示的误差率同为10%,所以有时绝对误差不能体现误差的真实大小,而相对误差通过体现误差占真值的比重来反映误差大小,效果更佳。
一般我们评价模型好坏,主要看mean absolute error(平均相对误差)越小越好,那两个百分比越接近0越好。
通过上面的结果,和它得到的公式
sellingPrice = (-26.6882 * houseSize) +
(7.0551 * lotSize) +(43166.0767 * bedrooms) +
(42292.0901 * bathroom)
- 21661.1208
我们可以看到花岗岩这个属性没用上,说明是不是花岗岩不影响最终售价。而卧室数量和卫生间数量表现的非常强势,系数是4万多,说明对价格影响很大。而houseSize系统是负的,说明面积大了,价格反而会降低,这个很不合常理。
根据经验,我们感觉这个地方是有问题的,由于训练数据很少,所以产生误差很正常。我们来根据不合理的地方手工调整一下。由于房屋面积大的,一般卧室数量也会多,而我们已经有了卧室的属性了,这里的houseSize又表现的不太正常,所以考虑直接删掉该属性。
然后再次训练数据,看看结果
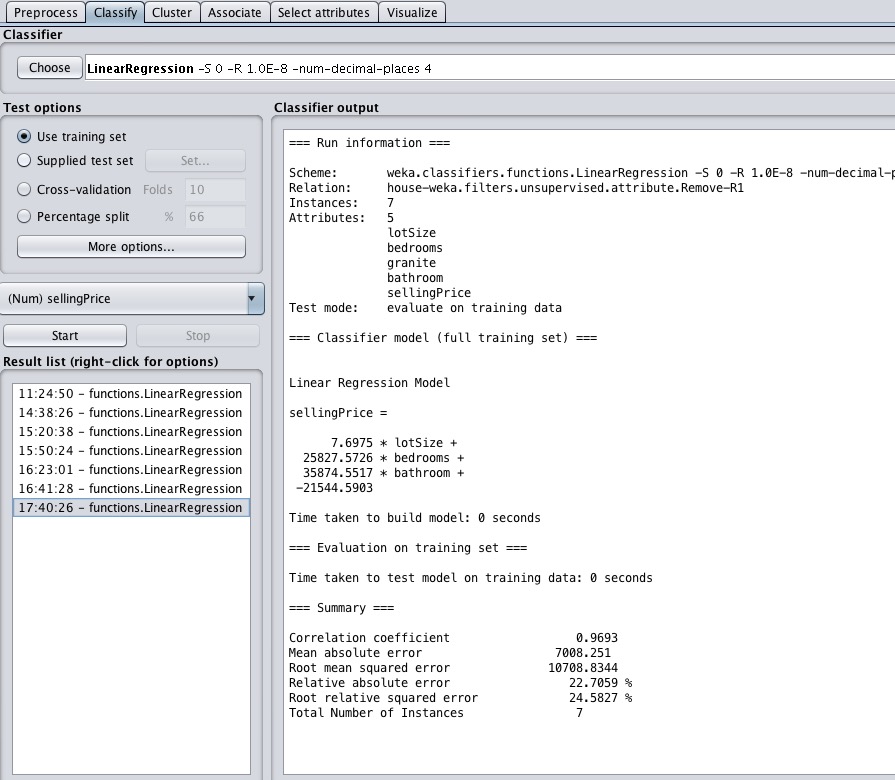
很不幸,这次的结果更差,平均误差达到了7008刀,误差率也翻了一倍,说明还不如上面的模型呢。
我们又做了一些别的尝试,发现都还不如第一个模型,虽然第一个也有不合理的地方,但勉强就是它了。这个例子由于数据量太少,所以也就这样了。
下面来看一个更好的数据源autoMpg.arff,这个示例数据文件的作用是创建一个能基于汽车的几个特性来推测其油耗(每加仑英里数,MPG)的回归模型(请务必记住,数据取自 1970 至 1982 年)。这个模型包括汽车的如下属性:汽缸、排量、马力、重量、加速度、年份、产地及制造商。此外,这个数据集有 398 行数据,这些数据足以满足我们的多种统计需求。
@relation 'autoMpg.names'
@attribute cylinders { 8, 4, 6, 3, 5}
@attribute displacement real
@attribute horsepower real
@attribute weight real
@attribute acceleration real
@attribute model { 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82}
@attribute origin { 1, 3, 2}
@attribute class real
@data
8,307,130,3504,12,70,1,18
8,350,165,3693,11.5,70,1,15
8,318,150,3436,11,70,1,18
8,304,150,3433,12,70,1,16
8,302,140,3449,10.5,70,1,17
这里可以看到cylinders、model等属性是nominal类型的,即是分类的,不是连续的数值。
我们将该数据导入到weka,同样选用线性回归——LinearRegression,对它进行挖掘运算。
weka瞬间就给出了它的结果:
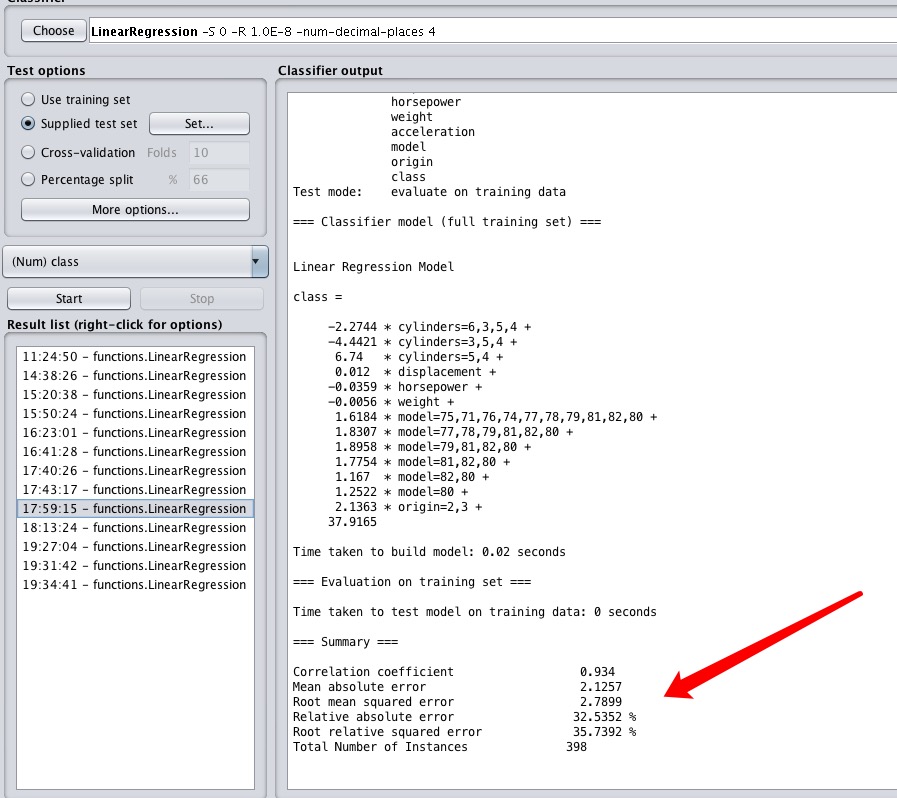
不得不感慨一下计算机的迅猛,这么一大堆数字,人眼根本无法从中得到什么有效的信息,但计算机算法瞬间就完成了。
class (aka MPG) =
-2.2744 * cylinders=6,3,5,4 +
-4.4421 * cylinders=3,5,4 +
6.74 * cylinders=5,4 +
0.012 * displacement +
-0.0359 * horsepower +
-0.0056 * weight +
1.6184 * model=75,71,76,74,77,78,79,81,82,80 +
1.8307 * model=77,78,79,81,82,80 +
1.8958 * model=79,81,82,80 +
1.7754 * model=81,82,80 +
1.167 * model=82,80 +
1.2522 * model=80 +
2.1363 * origin=2,3 +
37.9165
这是模型给出的系数。其中那是是分类的属性看起来怪怪的, -2.2744 * cylinders=6,3,5,4 这代表什么意思呢?
首先,cylinders有这么多个值{8, 4, 6, 3, 5},也就只能是这5个数中的一个。-2.2744 * cylinders=6,3,5,4 就代表当cylinders为8时,不进行该乘法运算,当是6,3,5,4时才进行该乘法。下面的那些同理。
ok,这个公式也还不算太复杂,毕竟只是个线性回归,我们来看看它的结果
=== Summary === Correlation coefficient 0.934 Mean absolute error 2.1257 Root mean squared error 2.7899 Relative absolute error 32.5352 % Root relative squared error 35.7392 % Total Number of Instances 398
均方差为2,基本上意外着,每个预测会差2加仑左右,本来油耗18的,可能预测为16、20,好像不太美好。下面的误差率更是达到30%以上。
我们可以下个结论,这个模型虽然有效,但误差有点飘,只能给65分。倘若能将油耗误差优化到0.5以内,误差率优化到5%以内,那么这个模型就比较满意了,就完全可以作为实际生活中的预测标准。
下一篇我们来把这个模型优化到所述的目标值。
参考文章:https://www.ibm.com/developerworks/cn/opensource/os-weka1/