我们来看看逻辑回归处理样本数据的案例,假如说要分类的样本长这样
所有的数据下载地址:https://gitee.com/tianyalei/machine_learning,按对应章节查找。
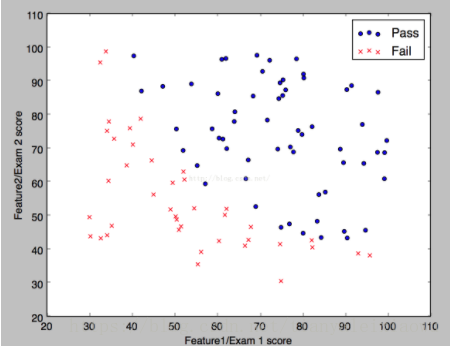
这是一个最简单的二维平台线性关系,数据集是data1.csv。
长这个样子:
a,b,result 34.62365962451697,78.0246928153624,0 30.28671076822607,43.89499752400101,0 35.84740876993872,72.90219802708364,0 60.18259938620976,86.30855209546826,1 79.0327360507101,75.3443764369103,1 45.08327747668339,56.3163717815305,0
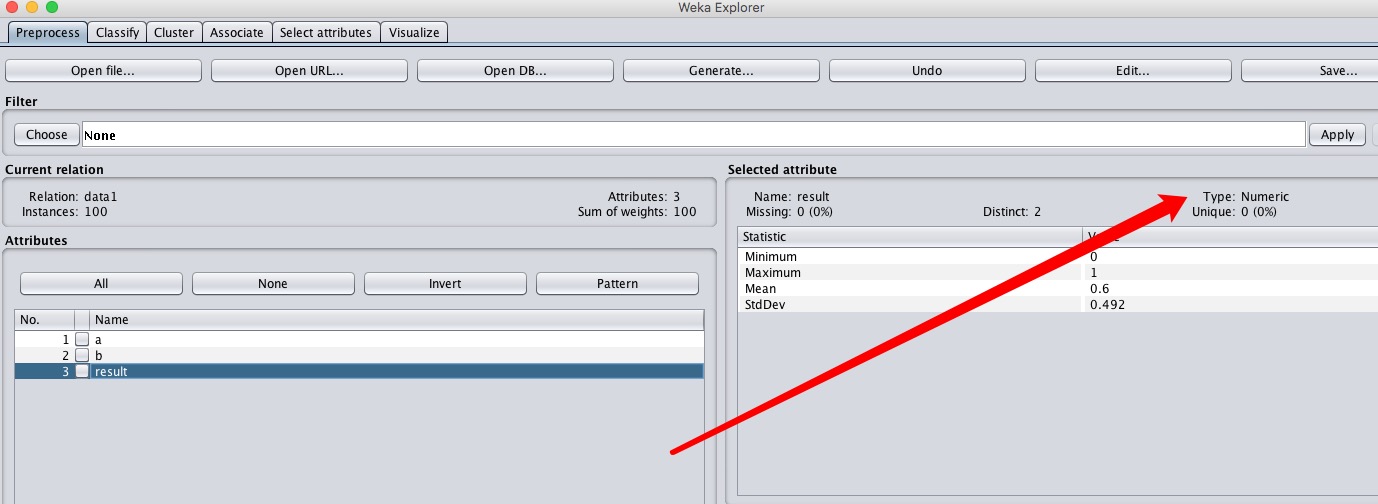
导入到weka中后,我们需要修改一下result的类型,可以看到现在它是numeric,是数值型,我们需要将它转为nominal类型,即分类型。
我们点击右上角的save,保存为arff文件,然后打开arff,将result属性改成这样保存,并重新打开这个arff。
@attribute result {0,1}
也可以使用Filter,在Choose找到unsupervised(无监督)—— attribute找到numericToNominal,然后点击Choose右边的框,来设置参数。
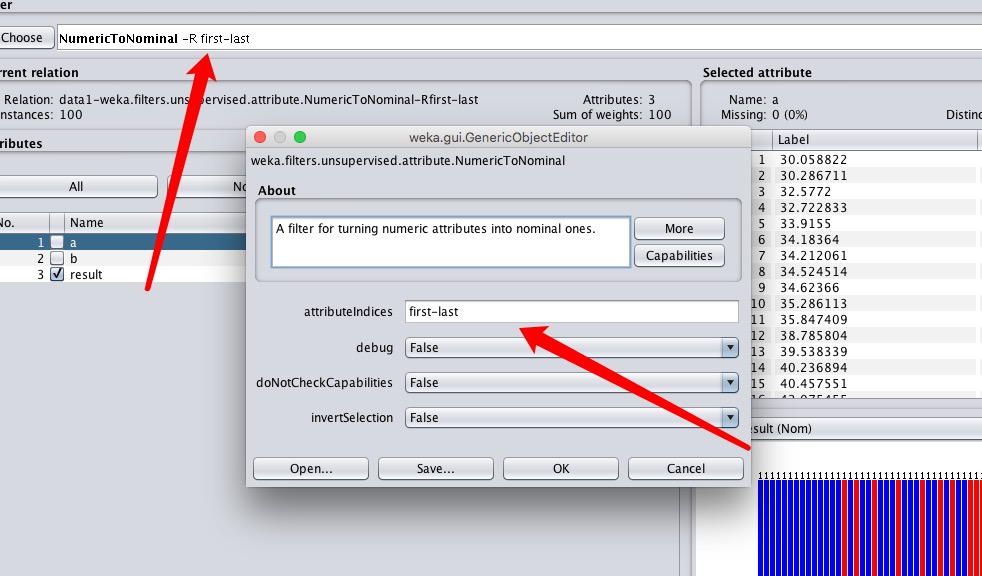
我们把first-last改成3,代表只对第3个属性使用该Filter、然后点击Filter栏的apply。
处理过后,当我们点击a、b时,右下角的预览图就会明确给出不同的范围内,结果为1和0的比例。
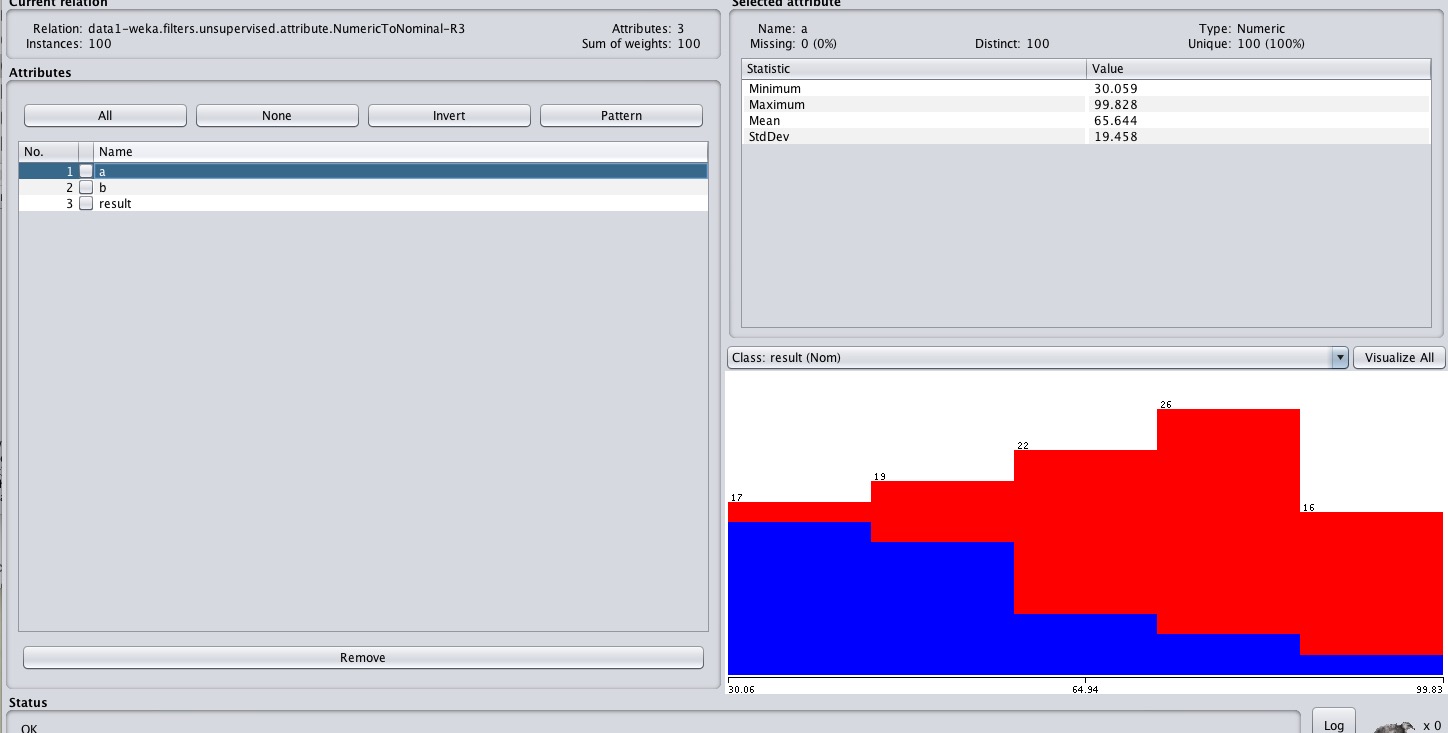
红的为1,蓝的为0.可以明显的看出,随着x的增大,结果为1的比例越来越大。
OK,下面开始上算法。找到logistic,
我们选择Cross-validation,点击start,看看结果。

来解释结果:
Odds Ratios代表胜率,解释看这篇,我也搞不懂这玩意有啥用。
主要还是看Summary和Matrix,每个代表的涵义看这篇。
我只说重要的,成功率是90%,也就是共100个数,有90个预测对了。
TP代表本来为true,机器预测也为true的概率。可以看到本来为0的有0.875被成功预测为0,本来为1的有0.917被预测为1.平均是0.9,也就是90%。
Recall召回率,又称查全率。表示识别正确的实例数,占该类别的实例的总数。由于该实例不存在空值,所有和TP相等。
ROC Area越接近于1,代表预测结果越好。
下面的Matrix代表:
有35个本来为0的被成功预测为0,有5个本来为0的被预测错误。
有55个本来为1的本成功预测为1,有5个本来为1的被预测错误。
所以正确率90%。