日志贴,有错拜托评论区指正~
附上李宏毅老师对transformer的讲解:
李宏毅2020机器学习深度学习(完整版)国语_哔哩哔哩_bilibili
关键的原理性问题
1、attention背景(没那么重要):
seq2seq任务(如翻译、对话等),输入一个序列得到一个序列,常用RNN实现,单向RNN可以看到序列当前位置及以前的内容、得到当前结果,双向RNN则可以看遍整个序列得到每一个结果。但是RNN不利于并行化,高度的并行化CNN又不能看遍序列,所以提出了self-attention layer.常见attention functions分为additive attention和dot-product attention,后者即softmax(QKT)V,便于矩阵并行化所以更优。
2、我之前不明所以以为transformer和attention是一个东西...实则不然。
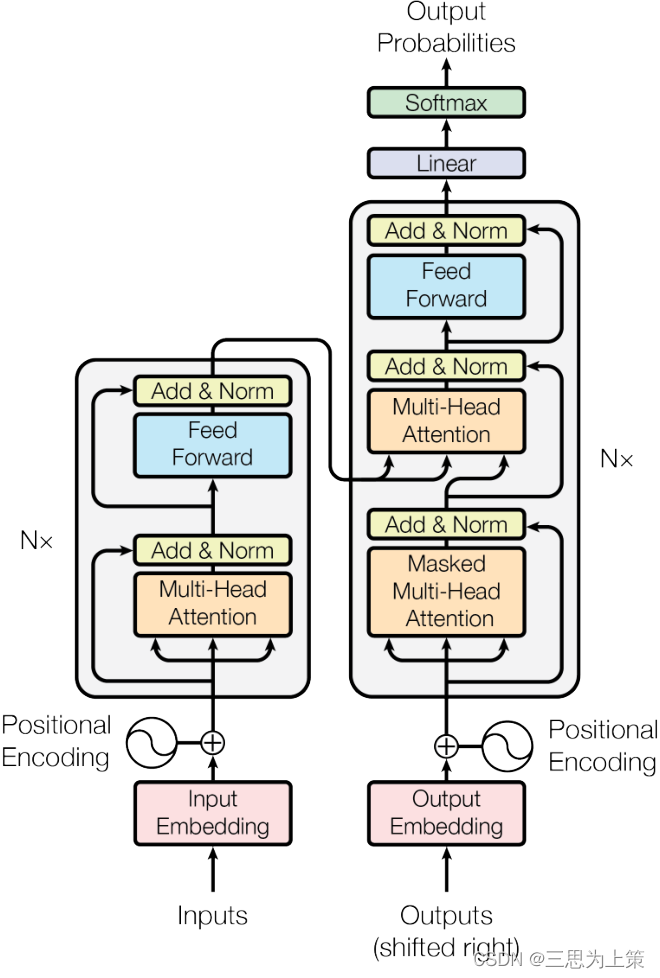
如图,是transformer的结构,由一个encoder(左)和一个decoder(右)组成,而encoder、decoder内部包含了attention layer,除了attention layer还有FFN(feed forward network,即线性+激活)
把encoder和decoder拆开用,多个encoder组合就是BERT模型,多个decoder组合就是GPT模型。
3、为什么transformer起源于NLP,在CV领域也用得很好?
嗯,这个是我项目答辩时候被老师问住的问题......我想说大白话,transformer在NLP很好用,于是就被拿来CV试试结果人家真的很好用...怕被老师骂,最终讷讷不得言。
Transformer在CV界火的原因是?_公众号机器学习与生成对抗网络的博客-CSDN博客
——也许这个问题的答案可以参考这个博主的文章。
在我导师看来,在当下的CV,attention层就应该和卷积层一样成为基础知识,被当作基本的层来使用。卷积更提取局部特征,attention则加强全局联系,扩大感受野。按照李宏毅老师的说法,CNN是简化版的self-attention,卷积只attend人工划定的感受野;self-attention先找出相关的像素,即自动学出感受野的形状和大小。
怎么将transformer用在CV里面呢?就是把图像也看作序列一样,将H x W x F的图像改为HW x F的维度,即可看作HW个F维向量。对于高像素图,通过打patch的操作将原图切作更小像素级的图像块送入attention层中进行计算。
4、Position Encoding
由于self-attention没有position information,所以加上通过学习得到的PE(维度和embedding的维度一样)来区分query的不同位置,或者说对相对位置进行表达。NLP中这个向量能决定当前词的位置,或者说在一个句子中不同的词之间的距离;CV中就是确定某个像素点的所在行列位置。
代码实现
(我用的是cuda10.2,torch1.10.0,python3.8.12,不同版本调用的代码可能不一样)
multihead_attn = torch.nn.MultiheadAttention(d_model, nhead, dropout)
out, attention_map = multihead_attn(query, key, value, attn_mask, key_padding_mask)1、torch.nn.MultiheadAttention代码所在位置:torch\nn\modules\activation.py
(1)__init__函数中,必选输入参数有embed_dim和num_heads。
默认情况下q,k,v的embedding维度需要一样,即q,k的维度分别为(L, B, embed_dim)与(S, B, embed_dim),否则应当输入特殊的参数kdim和vdim,即k维度为(S, B, kdim).
无论q,k,v的embedding维度一致与否,都会通过线性变换,变作同样的embed_dim维度,只是线性变换权重要分开放。
class MultiheadAttention(Module):
def __init__(self, embed_dim, num_heads, dropout=0., bias=True, add_bias_kv=False, add_zero_attn=False,
kdim=None, vdim=None, batch_first=False, device=None, dtype=None) -> None:
factory_kwargs = {'device': device, 'dtype': dtype}
super(MultiheadAttention, self).__init__()
self.embed_dim = embed_dim
self.kdim = kdim if kdim is not None else embed_dim
self.vdim = vdim if vdim is not None else embed_dim
self._qkv_same_embed_dim = self.kdim == embed_dim and self.vdim == embed_dim
self.num_heads = num_heads
self.dropout = dropout
self.batch_first = batch_first
self.head_dim = embed_dim // num_heads
assert self.head_dim * num_heads == self.embed_dim, "embed_dim must be divisible by num_heads"
# embed_dim必须能被num_heads整除
# 以下proj_weight记作A
if self._qkv_same_embed_dim is False:
self.q_proj_weight = Parameter(torch.empty((embed_dim, embed_dim), **factory_kwargs))
self.k_proj_weight = Parameter(torch.empty((embed_dim, self.kdim), **factory_kwargs))
self.v_proj_weight = Parameter(torch.empty((embed_dim, self.vdim), **factory_kwargs))
self.register_parameter('in_proj_weight', None)
else:
self.in_proj_weight = Parameter(torch.empty((3 * embed_dim, embed_dim), **factory_kwargs))
self.register_parameter('q_proj_weight', None)
self.register_parameter('k_proj_weight', None)
self.register_parameter('v_proj_weight', None)
# 以下in_proj_bias记作b
if bias:
self.in_proj_bias = Parameter(torch.empty(3 * embed_dim, **factory_kwargs))
else:
self.register_parameter('in_proj_bias', None)
# forward过程第一步按公式y = xA^T + b对输入的q,k,v进行线性变换(2)关于NonDynamicallyQuantizableLinear这个类,仅仅是为了避免在编写不当量化的注意力层脚本时触发一个不明显的错误。这里的out_proj是初始化了embed_dim到embed_dim的线性变化层的权重和偏差,用来对attention最后结果输出前做一次线性变换。
self.out_proj = NonDynamicallyQuantizableLinear(embed_dim, embed_dim, bias=bias, **factory_kwargs)
if add_bias_kv:
self.bias_k = Parameter(torch.empty((1, 1, embed_dim), **factory_kwargs))
self.bias_v = Parameter(torch.empty((1, 1, embed_dim), **factory_kwargs))
else:
self.bias_k = self.bias_v = None
self.add_zero_attn = add_zero_attn
self._reset_parameters()
# 让attention要训的参数好好初始化
def _reset_parameters(self):
if self._qkv_same_embed_dim:
xavier_uniform_(self.in_proj_weight)
else:
xavier_uniform_(self.q_proj_weight)
xavier_uniform_(self.k_proj_weight)
xavier_uniform_(self.v_proj_weight)
if self.in_proj_bias is not None:
constant_(self.in_proj_bias, 0.)
constant_(self.out_proj.bias, 0.)
if self.bias_k is not None:
xavier_normal_(self.bias_k)
if self.bias_v is not None:
xavier_normal_(self.bias_v)
def __setstate__(self, state):
# Support loading old MultiheadAttention checkpoints generated by v1.1.0
if '_qkv_same_embed_dim' not in state:
state['_qkv_same_embed_dim'] = True
super(MultiheadAttention, self).__setstate__(state)(3)forward函数
关于参数和输出的注释。
def forward(self, query: Tensor, key: Tensor, value: Tensor, key_padding_mask: Optional[Tensor] = None,
need_weights: bool = True, attn_mask: Optional[Tensor] = None) -> Tuple[Tensor, Optional[Tensor]]:
r"""
Args:
# 如果__init__时batch_first=True,则q、k、v的B在第一个维度,否则如下所示:
query: (L, B, E_q)
key: (S, B, E_k)
value: (S, B, E_v)
key_padding_mask: If specified, a mask of (B, S) indicating which elements within key to ignore for the purpose of attention. Binary and byte masks are supported.
For a binary mask, a True value indicates that the corresponding key value will be ignored for the purpose of attention. For a byte mask, a non-zero value indicates that the corresponding key value will be ignored.
need_weights: Default: True.
attn_mask: If specified, a 2D or 3D mask preventing attention to certain positions. Must be of shape (L, S) or (B\cdot\text{num\_heads}, L, S).
A 2D mask will be broadcasted across the batch while a 3D mask allows for a different mask for each entry in the batch.
Binary, byte, and float masks are supported. For a binary mask, a True value indicates that the corresponding position is not allowed to attend. For a byte mask, a non-zero value indicates that the corresponding position is not allowed to attend. For a float mask, the mask values will be added to the attention weight.
Outputs:
- **attn_output** - Attention outputs (L, B, E)或(B, L, E)
- **attn_output_weights** - Attention output weights (B, L, S) when need_weights=True
"""具体实现依靠F.multi_head_attention_forward
if self.batch_first:
query, key, value = [x.transpose(1, 0) for x in (query, key, value)]
# 保证q,k,v的B一直在第二个维度
# 将前面初始化好的权重偏差以及Q/K/V、mask传入更底层的函数,得到输出的最终结果和中间结果
if not self._qkv_same_embed_dim:
# 如果要用embedding维度不一样的k/v,需要令F.multi_head_attention_forward
# 的输入参数use_separate_proj_weight=True
attn_output, attn_output_weights = F.multi_head_attention_forward(
query, key, value, self.embed_dim, self.num_heads,
self.in_proj_weight, self.in_proj_bias,
self.bias_k, self.bias_v, self.add_zero_attn,
self.dropout, self.out_proj.weight, self.out_proj.bias,
training=self.training,
key_padding_mask=key_padding_mask, need_weights=need_weights,
attn_mask=attn_mask, use_separate_proj_weight=True,
q_proj_weight=self.q_proj_weight, k_proj_weight=self.k_proj_weight,
v_proj_weight=self.v_proj_weight)
else:
attn_output, attn_output_weights = F.multi_head_attention_forward(
query, key, value, self.embed_dim, self.num_heads,
self.in_proj_weight, self.in_proj_bias,
self.bias_k, self.bias_v, self.add_zero_attn,
self.dropout, self.out_proj.weight, self.out_proj.bias,
training=self.training,
key_padding_mask=key_padding_mask, need_weights=need_weights,
attn_mask=attn_mask)
if self.batch_first:
return attn_output.transpose(1, 0), attn_output_weights
else:
return attn_output, attn_output_weights2、F.multi_head_attention_forward的实现代码位于torch\nn\functional.py中
(1)第一段无重点
def multi_head_attention_forward(
query: Tensor,
key: Tensor,
value: Tensor,
embed_dim_to_check: int,
num_heads: int,
in_proj_weight: Tensor,
in_proj_bias: Optional[Tensor],
bias_k: Optional[Tensor],
bias_v: Optional[Tensor],
add_zero_attn: bool,
dropout_p: float,
out_proj_weight: Tensor,
out_proj_bias: Optional[Tensor],
training: bool = True,
key_padding_mask: Optional[Tensor] = None,
need_weights: bool = True,
attn_mask: Optional[Tensor] = None,
use_separate_proj_weight: bool = False,
q_proj_weight: Optional[Tensor] = None,
k_proj_weight: Optional[Tensor] = None,
v_proj_weight: Optional[Tensor] = None,
static_k: Optional[Tensor] = None,
static_v: Optional[Tensor] = None,
) -> Tuple[Tensor, Optional[Tensor]]:
tens_ops = (query, key, value, in_proj_weight, in_proj_bias, bias_k, bias_v, out_proj_weight, out_proj_bias)
# 这个看不懂,暂且跳过不影响
if has_torch_function(tens_ops):
return handle_torch_function(
multi_head_attention_forward,
tens_ops,
query,
key,
value,
embed_dim_to_check,
num_heads,
in_proj_weight,
in_proj_bias,
bias_k,
bias_v,
add_zero_attn,
dropout_p,
out_proj_weight,
out_proj_bias,
training=training,
key_padding_mask=key_padding_mask,
need_weights=need_weights,
attn_mask=attn_mask,
use_separate_proj_weight=use_separate_proj_weight,
q_proj_weight=q_proj_weight,
k_proj_weight=k_proj_weight,
v_proj_weight=v_proj_weight,
static_k=static_k,
static_v=static_v,
)
# set up shape vars
tgt_len, bsz, embed_dim = query.shape
src_len, _, _ = key.shape
assert embed_dim == embed_dim_to_check, \
f"was expecting embedding dimension of {embed_dim_to_check}, but got {embed_dim}"
if isinstance(embed_dim, torch.Tensor):
# embed_dim can be a tensor when JIT tracing
head_dim = embed_dim.div(num_heads, rounding_mode='trunc')
else:
head_dim = embed_dim // num_heads
assert head_dim * num_heads == embed_dim, f"embed_dim {embed_dim} not divisible by num_heads {num_heads}"
# 这里再次规定了embed_dim必需能被num_heads整除,否则会报错。 (2)in_projection:将q,k,v都做一次线性变换,无论先前如何,变换后都是同样的emdding维度。
# use_separate_proj_weight=True时,是不同embedding维度的kv输入
if use_separate_proj_weight:
# allow MHA to have different embedding dimensions when separate projection weights are used
assert key.shape[:2] == value.shape[:2], \
f"key's sequence and batch dims {key.shape[:2]} do not match value's {value.shape[:2]}"
# kv的sequence和batch维度必须一致,即前两个维度必须都是(S,B)
else:
assert key.shape == value.shape, f"key shape {key.shape} does not match value shape {value.shape}"
# 计算in-projection
if not use_separate_proj_weight:
q, k, v = _in_projection_packed(query, key, value, in_proj_weight, in_proj_bias)
else:
assert q_proj_weight is not None, "use_separate_proj_weight is True but q_proj_weight is None"
assert k_proj_weight is not None, "use_separate_proj_weight is True but k_proj_weight is None"
assert v_proj_weight is not None, "use_separate_proj_weight is True but v_proj_weight is None"
if in_proj_bias is None:
b_q = b_k = b_v = None
else:
b_q, b_k, b_v = in_proj_bias.chunk(3)
q, k, v = _in_projection(query, key, value, q_proj_weight, k_proj_weight, v_proj_weight, b_q, b_k, b_v)(2.1)_in_projection_packed和 _in_projection函数
见注释,前者是对embedding维度相同的q/k/v进行线性变换;后者是对维度不同的做。
def _in_projection_packed(
q: Tensor,
k: Tensor,
v: Tensor,
w: Tensor,
b: Optional[Tensor] = None,
) -> List[Tensor]:
E = q.size(-1)
if k is v:
if q is k:
# q=k=v,做的是self-attention,可以直接将(3E,E)的权重矩阵w与(L,B,E)的q送入linear,
# linear的做法是q*w^T+b,所以得到结果(L,B,3E)。
# 再用chunk在最后一维均分3块,得到3个(L,B,E)大小的q、k、v.
return linear(q, w, b).chunk(3, dim=-1)
else:
# k=v, encoder-decoder attention,则k、v的linear变换可合并,q单独做
w_q, w_kv = w.split([E, E * 2])
if b is None:
b_q = b_kv = None
else:
b_q, b_kv = b.split([E, E * 2])
return (linear(q, w_q, b_q),) + linear(k, w_kv, b_kv).chunk(2, dim=-1)
else:
# q/k/v各不同,则先将w分3块,再分别做linear
w_q, w_k, w_v = w.chunk(3)
if b is None:
b_q = b_k = b_v = None
else:
b_q, b_k, b_v = b.chunk(3)
return linear(q, w_q, b_q), linear(k, w_k, b_k), linear(v, w_v, b_v)
def _in_projection(
q: Tensor,
k: Tensor,
v: Tensor,
w_q: Tensor,
w_k: Tensor,
w_v: Tensor,
b_q: Optional[Tensor] = None,
b_k: Optional[Tensor] = None,
b_v: Optional[Tensor] = None,
) -> Tuple[Tensor, Tensor, Tensor]:
# embedding维度上q,k,v不同,权重矩阵单独存入,检验输入输出大小是否符合后,分别做linear
Eq, Ek, Ev = q.size(-1), k.size(-1), v.size(-1)
assert w_q.shape == (Eq, Eq), f"expecting query weights shape of {(Eq, Eq)}, but got {w_q.shape}"
assert w_k.shape == (Eq, Ek), f"expecting key weights shape of {(Eq, Ek)}, but got {w_k.shape}"
assert w_v.shape == (Eq, Ev), f"expecting value weights shape of {(Eq, Ev)}, but got {w_v.shape}"
assert b_q is None or b_q.shape == (Eq,), f"expecting query bias shape of {(Eq,)}, but got {b_q.shape}"
assert b_k is None or b_k.shape == (Eq,), f"expecting key bias shape of {(Eq,)}, but got {b_k.shape}"
assert b_v is None or b_v.shape == (Eq,), f"expecting value bias shape of {(Eq,)}, but got {b_v.shape}"
return linear(q, w_q, b_q), linear(k, w_k, b_k), linear(v, w_v, b_v)(3)检验mask输入符合数据类型和维度大小的要求否
# prep attention mask
if attn_mask is not None:
if attn_mask.dtype == torch.uint8:
warnings.warn("Byte tensor for attn_mask in nn.MultiheadAttention is deprecated. Use bool tensor instead.")
attn_mask = attn_mask.to(torch.bool)
else:
assert attn_mask.is_floating_point() or attn_mask.dtype == torch.bool, \
f"Only float, byte, and bool types are supported for attn_mask, not {attn_mask.dtype}"
# ensure attn_mask's dim is 3
if attn_mask.dim() == 2:
correct_2d_size = (tgt_len, src_len)
if attn_mask.shape != correct_2d_size:
raise RuntimeError(f"The shape of the 2D attn_mask is {attn_mask.shape}, but should be {correct_2d_size}.")
attn_mask = attn_mask.unsqueeze(0)
elif attn_mask.dim() == 3:
correct_3d_size = (bsz * num_heads, tgt_len, src_len)
if attn_mask.shape != correct_3d_size:
raise RuntimeError(f"The shape of the 3D attn_mask is {attn_mask.shape}, but should be {correct_3d_size}.")
else:
raise RuntimeError(f"attn_mask's dimension {attn_mask.dim()} is not supported")
# prep key padding mask
if key_padding_mask is not None and key_padding_mask.dtype == torch.uint8:
warnings.warn("Byte tensor for key_padding_mask in nn.MultiheadAttention is deprecated. Use bool tensor instead.")
key_padding_mask = key_padding_mask.to(torch.bool)
(4)k,v concat bias_k,bias_v
# add bias along batch dimension (currently second)
if bias_k is not None and bias_v is not None:
# bias_k和bias_v在nn.MultiheadAttention中初始化为(1,1,E)大小的参数
assert static_k is None, "bias cannot be added to static key."
assert static_v is None, "bias cannot be added to static value."
k = torch.cat([k, bias_k.repeat(1, bsz, 1)]) # (S+1, B ,E)
v = torch.cat([v, bias_v.repeat(1, bsz, 1)])
if attn_mask is not None: # attention mask大小(L,S)或(?,L,S)
attn_mask = pad(attn_mask, (0, 1))
# pad操作是在mask最后一维上做padding,左侧一头不添,右侧一头添1。默认用0来pad。
# 维度变为(L,S+1)
if key_padding_mask is not None:
key_padding_mask = pad(key_padding_mask, (0, 1))
else:
assert bias_k is None
assert bias_v is None(5)根据head数目改变q,k,v维度
# reshape q, k, v for multihead attention and make em batch first
q = q.contiguous().view(tgt_len, bsz * num_heads, head_dim).transpose(0, 1)
# (B*H, L, E/H)
if static_k is None:
k = k.contiguous().view(k.shape[0], bsz * num_heads, head_dim).transpose(0, 1)
#(B*H, S, E/H)或(B*H, S+1, E/H)
else:
# TODO finish disentangling control flow so we don't do in-projections when statics are passed
assert static_k.size(0) == bsz * num_heads, \
f"expecting static_k.size(0) of {bsz * num_heads}, but got {static_k.size(0)}"
assert static_k.size(2) == head_dim, \
f"expecting static_k.size(2) of {head_dim}, but got {static_k.size(2)}"
k = static_k
if static_v is None:
v = v.contiguous().view(v.shape[0], bsz * num_heads, head_dim).transpose(0, 1)
# 同k
else:
# TODO finish disentangling control flow so we don't do in-projections when statics are passed
assert static_v.size(0) == bsz * num_heads, \
f"expecting static_v.size(0) of {bsz * num_heads}, but got {static_v.size(0)}"
assert static_v.size(2) == head_dim, \
f"expecting static_v.size(2) of {head_dim}, but got {static_v.size(2)}"
v = static_v(6)add zero attention
对mask做一些处理
# add zero attention along batch dimension (now first)
if add_zero_attn:
zero_attn_shape = (bsz * num_heads, 1, head_dim)
k = torch.cat([k, torch.zeros(zero_attn_shape, dtype=k.dtype, device=k.device)], dim=1)
# k(B*H, S, E/H)->(B*H, S+1, E/H) or ?
v = torch.cat([v, torch.zeros(zero_attn_shape, dtype=v.dtype, device=v.device)], dim=1)
if attn_mask is not None:
attn_mask = pad(attn_mask, (0, 1))
if key_padding_mask is not None:
key_padding_mask = pad(key_padding_mask, (0, 1))
# update source sequence length after adjustments
src_len = k.size(1)
# S or S+1 or S+2? 默认情况下add_bias_kv=add_zero_attn=False,此处仍为S。
# merge key padding and attention masks
if key_padding_mask is not None:
assert key_padding_mask.shape == (bsz, src_len), \
f"expecting key_padding_mask shape of {(bsz, src_len)}, but got {key_padding_mask.shape}"
key_padding_mask = key_padding_mask.view(bsz, 1, 1, src_len). \
expand(-1, num_heads, -1, -1).reshape(bsz * num_heads, 1, src_len)
# key_mask(B*H, 1, S), attn_mask(B*H,L,S)
if attn_mask is None:
attn_mask = key_padding_mask
elif attn_mask.dtype == torch.bool:
attn_mask = attn_mask.logical_or(key_padding_mask)
# key_mask码掉的区域attn_mask也码掉
else:
attn_mask = attn_mask.masked_fill(key_padding_mask, float("-inf"))
# convert mask to float
if attn_mask is not None and attn_mask.dtype == torch.bool:
new_attn_mask = torch.zeros_like(attn_mask, dtype=torch.float)
new_attn_mask.masked_fill_(attn_mask, float("-inf"))
attn_mask = new_attn_mask
# adjust dropout probability,只有训练时设置dropout,推理时不用。
if not training:
dropout_p = 0.0(7)用_scaled_dot_product_attention做attention
attn_output, attn_output_weights = _scaled_dot_product_attention(q, k, v, attn_mask, dropout_p)
attn_output = attn_output.transpose(0, 1).contiguous().view(tgt_len, bsz, embed_dim)
# (L,B,E)
attn_output = linear(attn_output, out_proj_weight, out_proj_bias)
if need_weights:
# average attention weights over heads
attn_output_weights = attn_output_weights.view(bsz, num_heads, tgt_len, src_len)
# attn_output_weights(B*H,L,S)->(B,H,L,S)->(B,L,S)
return attn_output, attn_output_weights.sum(dim=1) / num_heads
else:
return attn_output, None(7.1)_scaled_dot_product_attention
def _scaled_dot_product_attention(
q: Tensor,
k: Tensor,
v: Tensor,
attn_mask: Optional[Tensor] = None,
dropout_p: float = 0.0,
) -> Tuple[Tensor, Tensor]:
B, Nt, E = q.shape
q = q / math.sqrt(E)
# (B*H, L, E/H) x (B*H, E/H, S) -> attn(B*H, L, S)
attn = torch.bmm(q, k.transpose(-2, -1))
if attn_mask is not None:
attn += attn_mask # attn(B*H, L, S)
# 在attention score上加attn_mask,mask的部分加负无穷大的数,经softmax后为0
attn = softmax(attn, dim=-1) # attn(B*H, L, S)
# 在最后一个维度上做softmax
if dropout_p > 0.0:
attn = dropout(attn, p=dropout_p)
# (B*H, L, S) x (B*H, S, E/H) -> (B*H, L, E/H)
output = torch.bmm(attn, v)
return output, attn