前言
纵观神经网络的发展历程,从最原始的MLP,到CNN,到RNN,到LSTM,GRU,再到现在的Attention机制,人们不断的在网络里面加入一些先验知识,使得网络不过于“发散”,能够朝着人们希望的方向去发展。
这些先验知识是指:局部视野知识、序列递归知识、结构递归知识,已经长短时的记忆。现在,人们加入了注意力这种先验知识。
本文将介绍应用在NLP领域的attention机制,包括传统的attention机制以及最新的transformer机制。
啥子叫注意力?
注意力机制可以看做一种通用的思想,是指人在工作的是注意力往往会集中在整个场景中的某些焦点上。
举个例子哈,大家在中学做语文的阅读理解的时候,有一个常见的题目就是找整篇文章的中心句。这个时候,我们往往都把注意力集中在开头段、结尾段,中间的内容不是说不重要,但是在找中心句的时候,我们往往把注意力偏重于开头结尾。这就是一种注意力的体现。
再举个例子:

这是一种街景图,假设现在我们处在这个场景中,我想找周围有没有超市,那么对于这么一个映入我眼睑的图像,我肯定会认为超市应该在街道的两边,不会在空中。于是,我会把我的注意力集中在前方的左右两边的商店。
又比如,还是在这个场景中,假设开车在这条道路上,急着去见妹纸,那么我的注意力自然就是红绿灯咯。
这两个例子基本就能体现出注意力机制的核心思想:对于一个复杂的输入,不同的问题会把注意力侧重于不同的地方。
那再看看在机器翻译的一个小小的attention的例子。
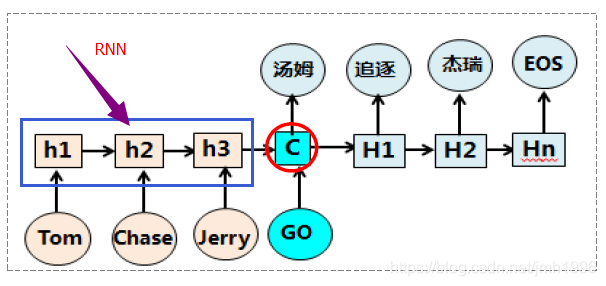
这是一个很典型的基于RNN网络的机器翻译模型,模型先依次往网络输入 Tom,Chase,Jerry,然后最后得到待翻译句子的向量表达
,这个
理应结合了输入的所有信息。然后翻译的时候,“汤姆”就基于
给计算出来了。
但是,我们隐隐约约感受到这样的模型似乎在翻译成“汤姆”的时候,把Tom chase Jerry 这三个词都视为同等重要来翻译,但实际上 这个词的翻译的 注意力应该在“Tom”这个词的附近。说的更直白一些,“汤姆”这个翻译结果对输入各个词的关注度应该有所侧重,如果用权重衡量的话,Tom 可能占用了0.7的关注度,其他两个词可能分别占用0.2和0.1的关注度。
基本思想就是这样子的了,通过关注度的高低大小来体现注意力的倾向。
注意力机制核心思想
假设, 中 表示输入的一部分, 表达输入的一部分。现在在某个任务的时候,我们给输入的各个 有个打分 ,那些任务高度关注的 打分就高。那么应该怎么做?
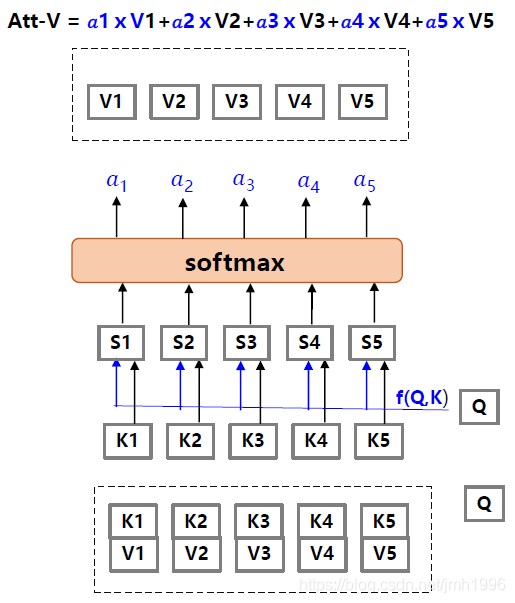
如上图所示,做的方法很简单的,首先
表示一个与当前任务有关的矩阵,它可以协助选择出那个
的权重大。
于是先拿
和
做一次
运算得到不同
,然后在对这些
进行归一化,得到对应的规范权重。最后,在依这些权重计算
的线性组合
。
通常,K和V是相等的。
而这个加权后
的线性组合
就是传说中的注意力值,这个值就对
这几个值有所侧重。
我们再看打分函数
一般是那些函数:
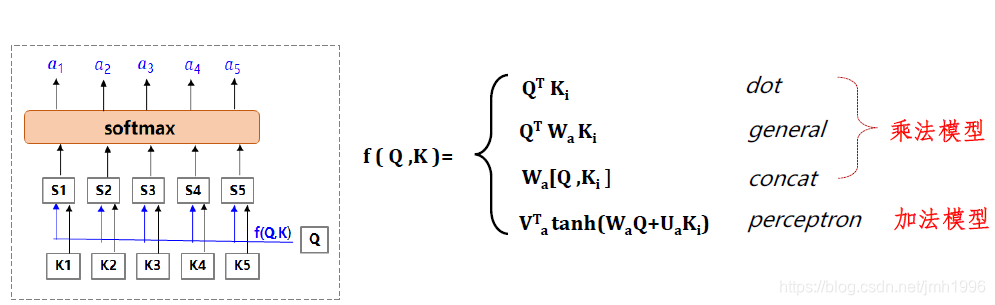
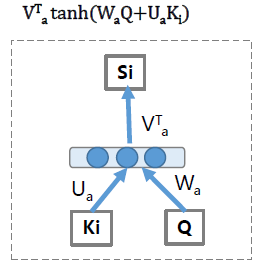
它可以是个标注向量内积,也可以是椭圆内积,或者concat,当然也可以专门设计一个小型的MLP来完成这个f的功能。
注意力的分类
求注意力的时候,不同分配限制会有不同的注意力。
例如:
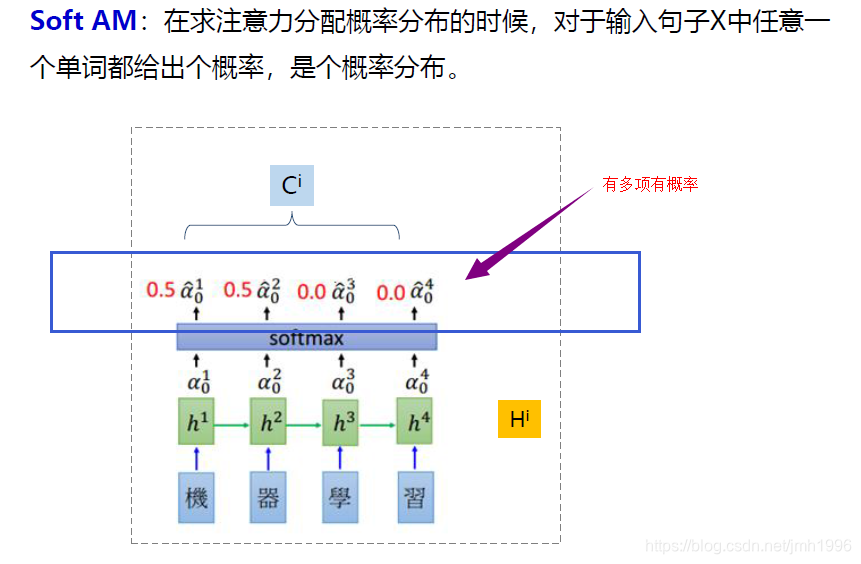
软注意力
对概率的分配没有任何限制。
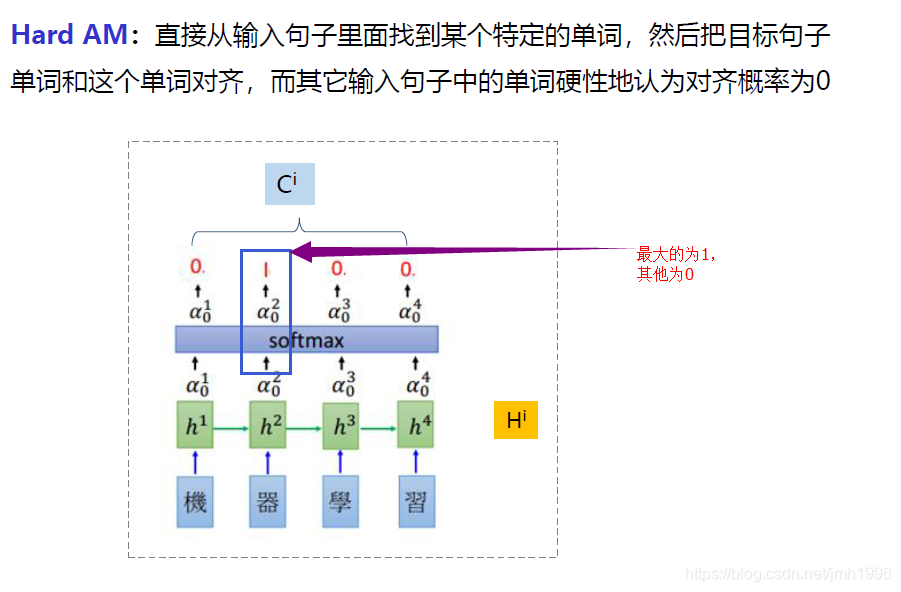
硬注意力:
在软注意力的基础上对概率分配添加某种限制,例如:限制概率最大的那个 为1,其他强制改为0。
然后考虑计算Attention是基于输入的全部还是局部又分为全局注意力。
全局注意力
Decoder段在计算Attention是考虑Encoder的所有词。
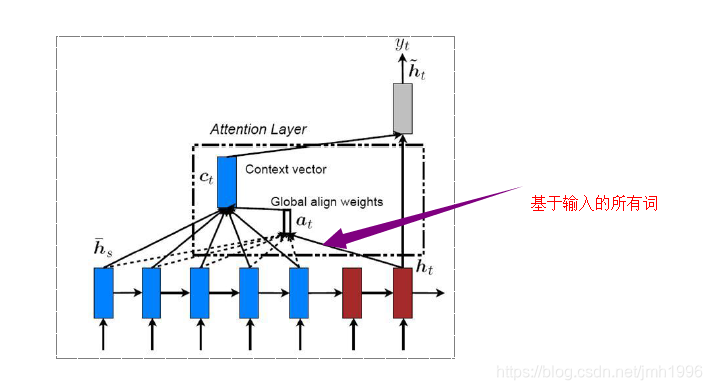
这样得到的注意力值Att-V 是全局输入向量的依各列相应概率值的线性组合。
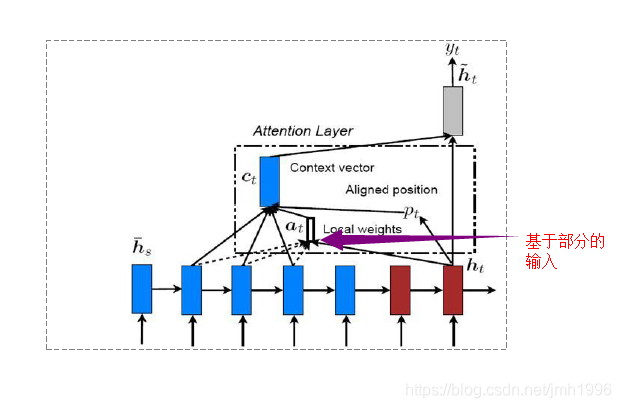
局部注意力
与全局注意力形成对比的是,为了加快训练速度,可以设置一个窗口,使得对于输入的窗口内的向量进行打分,然后求这些窗口内的向量的线性组合。
Attention的具体应用
见下一篇博客,专门解读2015年attention机制用于机器翻译的句嵌入表示的论文。