Attention详细讲解请看
transformer详细讲解请看
多头注意力流程手稿
这里直接以例子来说,详细的讲解可以看开头的链接。
我们有3条记录,两个特征,如下所示,其中x1代表“性别”,x2代表“设备品牌”:
x1 x2
男 华为
男 小米
女 苹果
● batch_size = 3
● fields = 2
● emb_dim = 6
● head_num = 2
则输入维度为:[3, 2, 6]
以一个batch为例讲解多头注意力的流程,如下图:
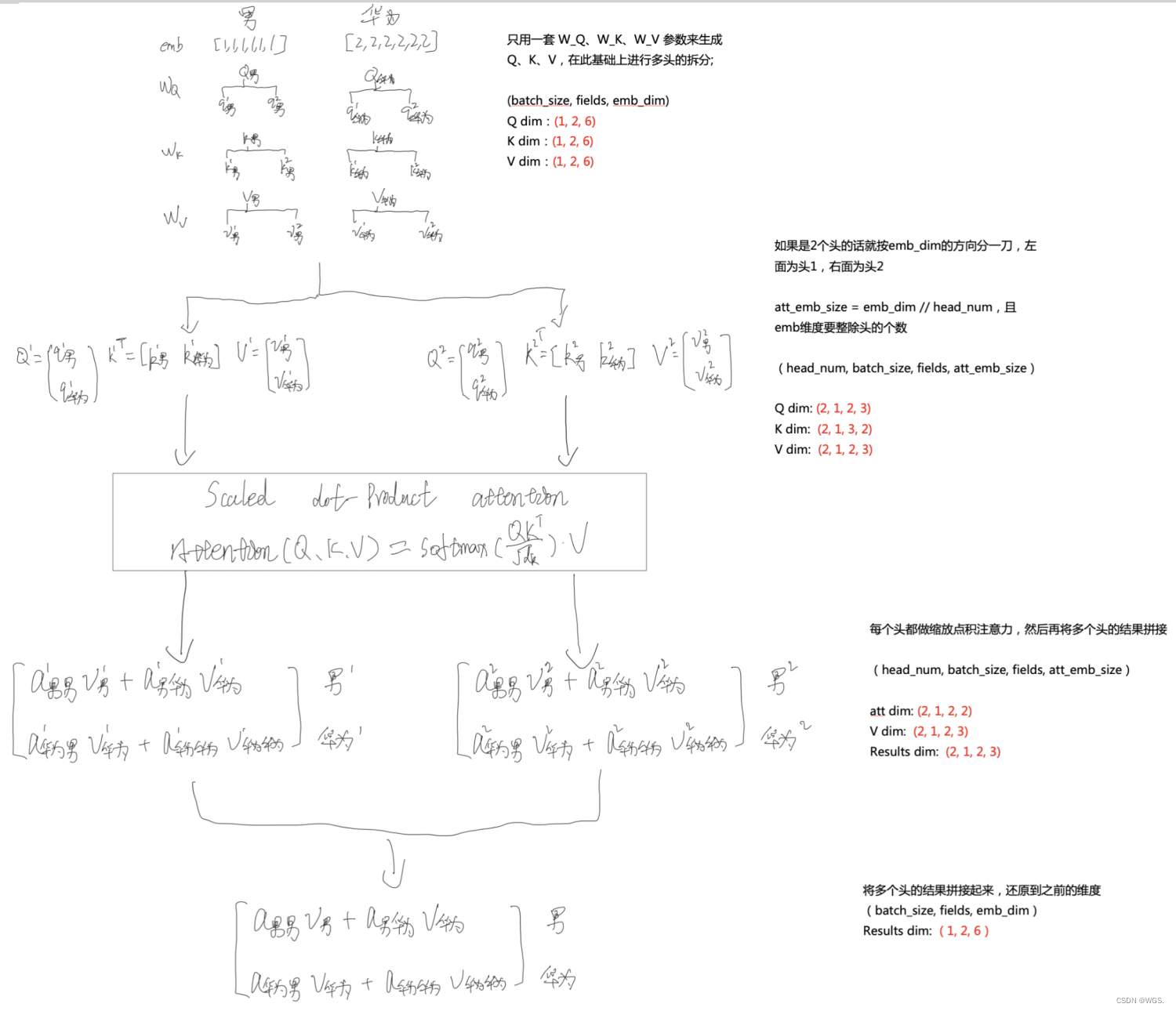
分头前后tensor如下:
tensor([[[-1.7435, -1.0348, -0.8986, -0.3036, 2.5530, 0.0273],
[ 2.0777, 0.9267, 1.0873, 0.4455, -1.9582, -0.0131]]])
tensor([[[[-1.7435, -1.0348, -0.8986],
[ 2.0777, 0.9267, 1.0873]]],
[[[-0.3036, 2.5530, 0.0273],
[ 0.4455, -1.9582, -0.0131]]]])
torch 实现多头注意力
# coding:utf-8
# @Email: [email protected]
# @Time: 2022/7/25 2:45 下午
# @File: multi_att_demo.py
import pandas as pd, numpy as np
import torch
from torch import nn
import torch.nn.functional as F
class MultiheadAttention(nn.Module):
def __init__(self, emb_dim, head_num, scaling=True):
super(MultiheadAttention, self).__init__()
self.emb_dim = emb_dim
self.head_num = head_num
self.scaling = scaling
self.att_emb_size = emb_dim // head_num
assert emb_dim % head_num == 0, "emb_dim must be divisible head_num"
self.W_Q = nn.Parameter(torch.Tensor(emb_dim, emb_dim))
self.W_K = nn.Parameter(torch.Tensor(emb_dim, emb_dim))
self.W_V = nn.Parameter(torch.Tensor(emb_dim, emb_dim))
# 初始化, 避免计算得到nan
for weight in self.parameters():
nn.init.xavier_uniform_(weight)
def forward(self, inputs):
# inputs_emb: [3, 2, 6]
'''1. 线性变换生成Q、K、V'''
# dim: [batch_size, fields, emb_size]
# [3, 2, 6] * [6, 6] = [3, 2, 6]
querys = torch.tensordot(inputs, self.W_Q, dims=([-1], [0]))
keys = torch.tensordot(inputs, self.W_K, dims=([-1], [0]))
values = torch.tensordot(inputs, self.W_V, dims=([-1], [0]))
# # 等价于 matmul
# querys = torch.matmul(inputs, self.W_Q)
# keys = torch.matmul(inputs, self.W_K)
# values = torch.matmul(inputs, self.W_V)
'''2. 分头'''
# dim: [head_num, batch_size, fields, emb_size // head_num]
# [3, 2, 6] --> [2, 3, 2, 3]
querys = torch.stack(torch.split(querys, self.att_emb_size, dim=2))
keys = torch.stack(torch.split(keys, self.att_emb_size, dim=2))
values = torch.stack(torch.split(values, self.att_emb_size, dim=2))
'''3. 缩放点积注意力'''
# dim: [head_num, batch_size, fields, emb_size // head_num]
# Q * K^T / scale : [2, 3, 2, 3] * [2, 3, 3, 2] = [2, 3, 2, 2]
inner_product = torch.matmul(querys, keys.transpose(-2, -1))
# # 等价于
# inner_product = torch.einsum('bnik,bnjk->bnij', querys, keys)
if self.scaling:
inner_product /= self.att_emb_size ** 0.5
# Softmax归一化权重
attn_w = F.softmax(inner_product, dim=-1)
# 加权求和, attention结果与V相乘,得到多头注意力结果
# [2, 3, 2, 2] * [2, 3, 2, 3] = [2, 3, 2, 3]
results = torch.matmul(attn_w, values)
'''4. 拼接多头空间'''
# dim: [batch_size, fields, emb_size]
# [2, 3, 2, 3] --> [1, 3, 2, 6] --> [3, 2, 6]
results = torch.cat(torch.split(results, 1, ), dim=-1)
results = torch.squeeze(results, dim=0)
results = F.relu(results)
return results
def dt2():
'''
x1 x2
男 华为
男 小米
女 苹果
--- encoder
x1 x2
0 0
0 1
1 2
+ batch_size = 3,
+ fields = 2, 有2个特征,
+ emb_dim = 6,
+ head_num = 2, 分为2个头,每个头的att_emb_size为3
则输入为:[3, 2, 6]
'''
# data = pd.DataFrame({'x1': [0, 0, 1], 'x2': [0, 1, 2]})
data = pd.DataFrame({
'x1': [0], 'x2': [0]})
sparse_fields = data.max().values + 1
sparse_fields = sparse_fields.astype(np.int32) # [2, 3]
tensor = torch.Tensor(data.values).long()
print(tensor)
offsets = np.array((0, *np.cumsum(sparse_fields)[:-1]), dtype=np.longlong) # [0, 2]
tensor = tensor + tensor.new_tensor(offsets).unsqueeze(0)
print(tensor)
emb_layer = nn.Embedding(sum(sparse_fields) + 1, embedding_dim=6)
tensor_emb = emb_layer(tensor)
print(tensor_emb.shape)
net = MultiheadAttention(emb_dim=6, head_num=2, scaling=True)
output = net.forward(tensor_emb)
print(output.shape)
print(output)