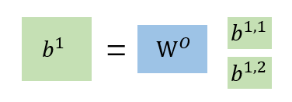自用,笔记整理。
self-attention模型输入的xi先做embedding得到ai每个xi都分别乘上三个不同的w得到q、k、v。
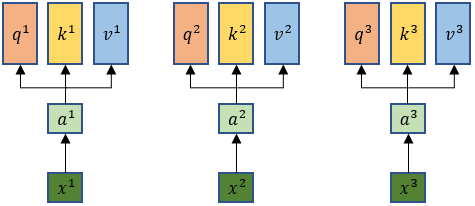
其中: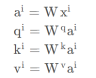
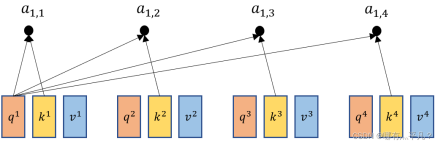
拿每个qi去对每个ki做点积得到a1,i,其中d是q和k的维度。
![]()
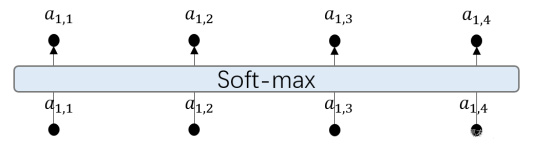
再把a1,i经过一个Soft-max之后得到
![]()
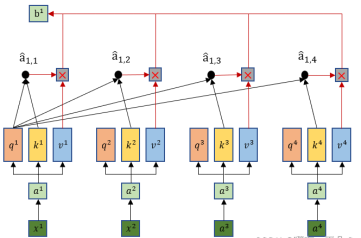
接下来把得出第一个输出b1同理可得到所有bi
![]()
那么self attention是这么做平行化的呢?
将a穿起来合并成矩阵I与wq相乘,得到q们,组成矩阵Q,同理得到K,V
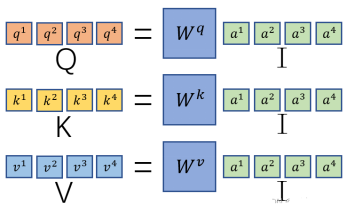
对于a1,1只要将矩阵和矩阵相乘就行。然后对每一列做一个soft-max得到带帽的a矩阵
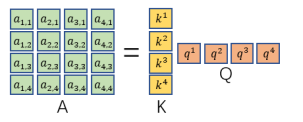
最后将带帽a与所有v构成的矩阵V相乘即可输出。
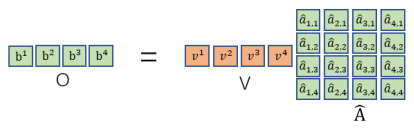
总结:

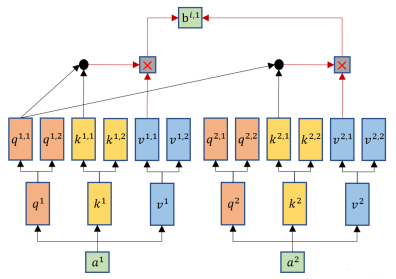
self-attention的变形——Multi-head Self-attention
Multi-head Self-attention跟self-attention一样都会生成q、k、v,但是Multi-head Self-attention会再将q、k、v分裂出多个q1,2(这里举例分裂成两个),然后它也将q跟k去进行相乘计算,但是只跟其对应的k、v进行计算,比如q1,1只会与k1,1 、k2,1进行运算,然后一样的乘以对应的v得到输出b1,1。
![]()