paper:Channel Distillation: Channel-Wise Attention for Knowledge Distillation
official implementation:https://github.com/zhouzaida/channel-distillation
存在的问题
- 教师模型传递的知识不够好,学生模型无法准确地从教师模型学习到最重要的信息。
- 教师模型的预测并不完全是正确的,在训练过程中,如果完全参考教师模型的输出,教师模型的错误预测会对学生模型产生不利的影响。
- 教师模型和学生模型结构不同,如果总是让教师模型来监督学生模型,就会使学生模型无法找到自己的优化空间。
本文的创新点
为了解决上述三个问题,本文提出了一些优化方法
- 提出了一种新的知识蒸馏方法,通过通道蒸馏(Channel-Wise Distillation, CD)将知识传递给学生,以便学生可以更高效的提取特征。
- 为了避免教师模型的错误输出对学生的负面影响,提出了引导知识蒸馏(Guided Knowledge Distillation, GKD),只使用教师模型的正确输出来对学生模型进行监督。
- 最后,提出了Early Decay Teacher(EDT)在训练过程中逐步减小蒸馏损失的权重,确保学生模型可以找到自己的优化空间。
方法介绍
Channel Distillation
本文受到SENet的启发,在SENet中,channel-wise attention使模型能够学习每个通道的权重,然后将权重与原始的通道相乘,那些重要通道的特征被增强,不重要的通道特征被减弱,从而使特征的提取更具方向性,网络的预测能力更好。每个通道的权重计算如下
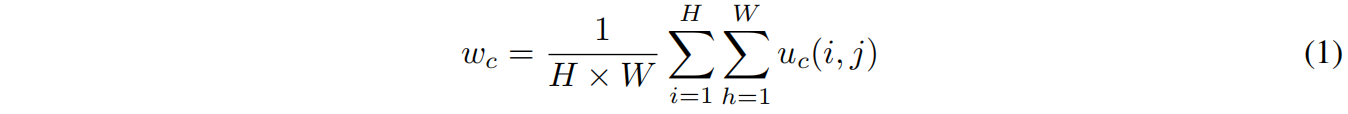
其中 \(w_{c}\) 是 \(c^{th}\) 通道的权重,\(H,W\) 是特征图的空间维度,\(u_{c}(i,j)\) 是激活值。
feature map的每个通道对应一种视觉模式visual pattern,但每个通道视觉模式的重要性是不同的。因为教师模型的性能优于学生模型,作者认为教师模型学习到的视觉模式更加准确,因此希望学生去学习教师模型的视觉模式。具体而言,使用全局平均池化GAP来计算每个通道的重要性,它代表了每个通道的注意力信息attention information。然后将每个通道的注意力信息作为知识,传递给学生模型。通常教师模型和学生模型的层数是不同的,作者只在特征图分辨率降低的层进行通道蒸馏,如果通道数不匹配,采用1x1卷积将学生模型的通道数增加到与教师模型相同。CD loss的定义如下
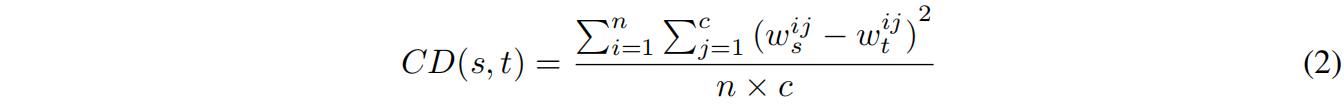
其中 \(CD(s,t)\) 表示教师和学生模型之间的CD损失,\(w_{ij}\) 表示 \(i^{th}\) 样本 \(j^{th}\) 通道的权重,\(c\) 表示通道数。
Guided Knowledge Distillation
本文提出的GKD是在KD的基础上设计的,KD的思想是计算教师模型和学生模型的预测分布,通过逐渐减小它们之间的差异,使得学生的输出分布逐渐接近教师。KD的计算公式如下
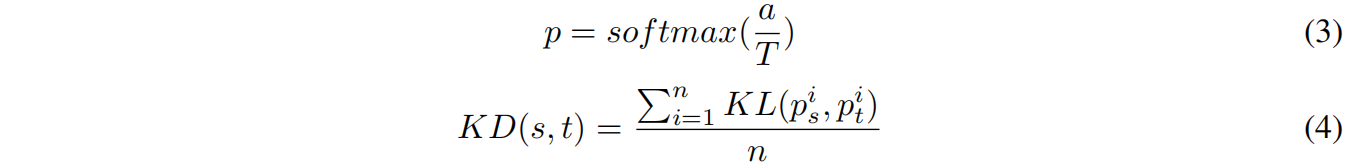
其中 \(p\) 是由logit \(a\) 计算的概率分布,\(T\) 是温度。\(n\) 是batch size。\(KD(s,t)\) 是 \(p^{i}_{s}\) 和 \(p^{i}_{t}\) 之间的KL散度的平均值。
尽管教师模型的预测结果更加准确,但仍然有一些错误的预测。当教师预测错误时,将错误知识传递给学生,这会降低学生的表现。因此作者在KD的基础上进行改进得到了GKD,具体而言只对教师模型预测正确的样本的KD损失进行反向传播而忽略预测错误的样本的KD损失,GDK的定义如下
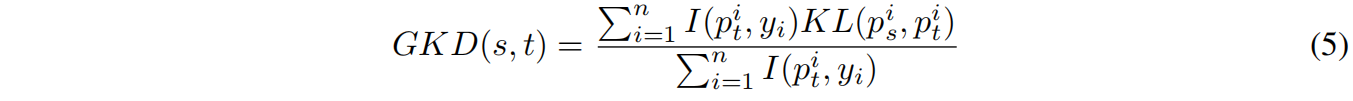
其中 \(I\) 是一个indicator function,当教师模型的输出等于label时 \(I(p^{i}_{t},y)\) 等于1,否则为0。例如,假设一个batch种有 \(n\) 个样本,教师模型只预测对了其中 \(n_{1}\) 个,GKD就只计算这 \(n_{1}\) 个样本的KD损失。
Early Decay Teacher
On the Efficacy of Knowledge Distillation这篇文章中提出蒸馏的影响并不总是积极的,在训练的早期,蒸馏可以帮助学生的训练,但在训练的后期会抑制学生的学习,因此在合适的时间停止教师模型的监督有助于学生模型的学习。实验结果表明,在某个epoch,交叉熵损失反而会开始上升,最好在这个节点停止教师模型的监督,但在实际应用中直接停止教师模型的监督比较困难,因此作者提出了一种相对较缓和的做法,随着学习率的降低逐步降低蒸馏损失的权重,定义如下
![]()
其中 \(\alpha\) 是蒸馏损失的初始权重,\(\lambda\) 是一个常量系数,\(n_{e}\) 表示完整训练过程中的 \(n^{th}\) epoch,\(n\) 是一个经验值,表示减小损失权重的epoch数量。
我们只减小CD损失的权重,对于GKD损失,因为它只传递正确的知识,因此整个训练过程中都不减小它的权重。
完整的损失函数如下
![]()
实验结果
表1、2分别是在ImageNet和CIFAR 100数据集上与原始KD的结果对比,可以看出,本文提出的三点创新CD、GKD、EDT都对学生模型的精度提高有帮助,当将三者结合起来时精度最高。
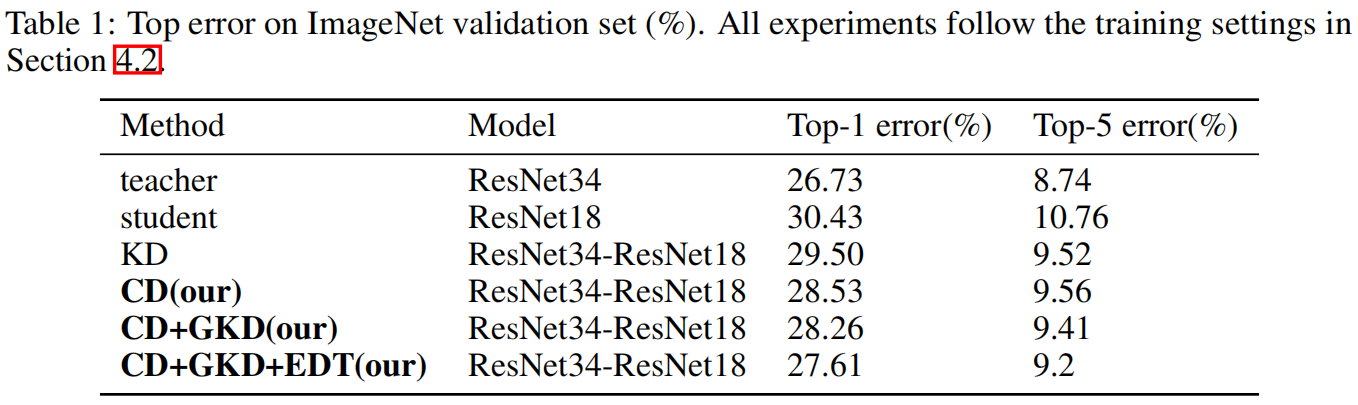

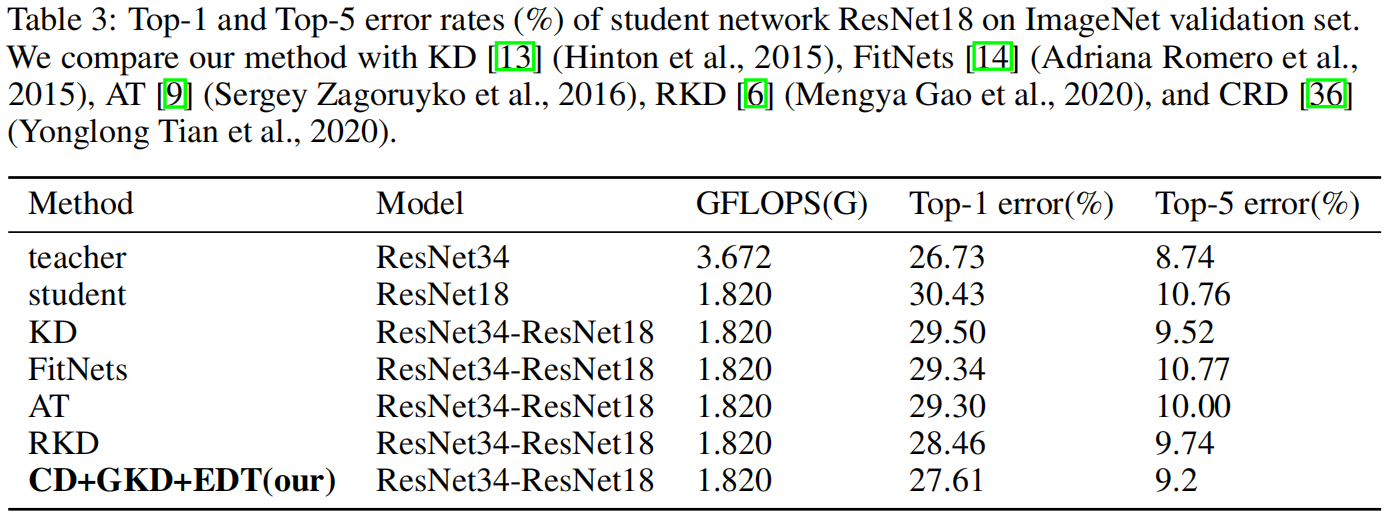
表3是与其它蒸馏方法的精度对比,可以看出CD+GKD+EDT取得了最优的性能。
代码解析
CD损失代码如下
import torch
import torch.nn as nn
class CDLoss(nn.Module):
"""Channel Distillation Loss"""
def __init__(self):
super().__init__()
def forward(self, stu_features: list, tea_features: list):
loss = 0.
for s, t in zip(stu_features, tea_features):
s = s.mean(dim=(2, 3), keepdim=False)
t = t.mean(dim=(2, 3), keepdim=False)
loss += torch.mean(torch.pow(s - t, 2))
return loss
GKD损失代码如下
class KDLossv2(nn.Module):
"""Guided Knowledge Distillation Loss"""
def __init__(self, T):
super().__init__()
self.t = T
def forward(self, stu_pred, tea_pred, label):
s = F.log_softmax(stu_pred / self.t, dim=1)
t = F.softmax(tea_pred / self.t, dim=1)
t_argmax = torch.argmax(t, dim=1)
mask = torch.eq(label, t_argmax).float()
count = (mask[mask == 1]).size(0)
mask = mask.unsqueeze(-1)
correct_s = s.mul(mask)
correct_t = t.mul(mask)
correct_t[correct_t == 0.0] = 1.0
loss = F.kl_div(correct_s, correct_t, reduction='sum') * (self.t**2) / count
return loss
EDT代码如下
def adjust_loss_alpha(alpha, epoch, factor=0.9, loss_type="ce_family", loss_rate_decay="lrdv1", dataset_type="imagenet"):
"""Early Decay Teacher"""
if dataset_type == "imagenet":
if loss_rate_decay == "lrdv1":
return alpha * (factor ** (epoch // 30))
else: # lrdv2
if "ce" in loss_type or "kd" in loss_type:
return 0 if epoch <= 30 else alpha * (factor ** (epoch // 30))
else:
return alpha * (factor ** (epoch // 30))
else: # cifar
if loss_rate_decay == "lrdv1":
return alpha
else: # lrdv2
if epoch >= 160:
exponent = 2
elif epoch >= 60:
exponent = 1
else:
exponent = 0
if "ce" in loss_type or "kd" in loss_type:
return 0 if epoch <= 60 else alpha * (factor**exponent)
else:
return alpha * (factor**exponent)