class Attention(nn.Module):
def __init__(self, dim, num_heads=8, qkv_bias=False, qk_scale=None, attn_drop=0., proj_drop=0.):
super().__init__()
self.num_heads = num_heads
head_dim = dim // num_heads
# NOTE scale factor was wrong in my original version, can set manually to be compat with prev weights
self.scale = qk_scale or head_dim ** -0.5
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)#用于设置网络中的全连接层的,全连接层的输入和输出一般都设置成二维张量,形状通常为[batch_size,size]
self.attn_drop = nn.Dropout(attn_drop)#随机将输入张量中部分元素设置为0,对于每次前向调用,被设置为0的元素都是随机的
self.proj = nn.Linear(dim, dim)#dim=192
self.proj_drop = nn.Dropout(proj_drop)
def forward(self, x):
B, N, C = x.shape#这里的B =? N=197?C=192?
qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
q, k, v = qkv[0], qkv[1], qkv[2] # make torchscript happy (cannot use tensor as tuple)
attn = (q @ k.transpose(-2, -1)) * self.scale
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn)
x = (attn @ v).transpose(1, 2).reshape(B, N, C)
x = self.proj(x)
x = self.proj_drop(x)
return x
Transformer结构分析
1.输入

2.计算Q,K,V
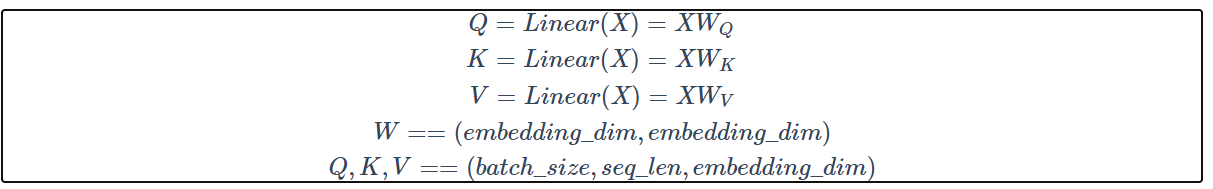
3.处理多头
将最后一维(embedding_dim)拆成h份,需要保证embedding_dim能够被h整除。每个tensor的最后两个维度表示一个头,QKV各自都有h个头,接下来需要把这些头分别进行计算

4.计算
按顺序取出上图中一组QKV,计算

(1)计算得到各个字之间的关系(相似度).这里的d的维度是
(batch_size, h, seq_len, embedding_dim) * (batch_size, h, embedding_dim, seq_len)==>(batch_size, h, seq_len, seq_len)。QKV分别有 batch_size * h 个矩阵,可以认为是在一个(batch_size, h)的棋盘中,每个位置放置了一个大小为(seq_len, embedding_dim)的矩阵。这里的前两个维度不变只是把棋盘中对应位置的矩阵拿出来做矩阵乘法,并把结果再放回到棋盘中。
(2)用mask矩阵遮盖掉超出句子长度的部分。将句子中用来pading的字符全部替换成 inf, 这样 计算softmax的时候它们的值会为0,就不会参与到接下来与V的计算当中
(3) dk 是为了改变已经偏离的方差。我的理解是,由于矩阵转置后相乘会有很多内积运算,而内积运算将dk个数相加时会改变数据的分布。而这个分布的趋势是 mean=0,variance=dk。为了使方差回归到1,把所有结果都除上一个dk−−√,这样求平方时会抵消已有的方差dk
# 均值为0,方差为1
a = np.random.randn(2,3000)
b = np.random.randn(3000,2)
c = a.dot(b)
print(np.var(a))
print(np.mean(c))
print(np.var(c))
# 1.0262973662546435
# 25.625943965792157
# 1347.432397285718
To illustrate why the dot products get large, assume that the components of q and k are independent random variables with > mean 0 and variance 1. Then their dot product, q⋅k=∑dki=1qiki, has mean 0 and variance dk.
(4)计算各个词义所占的比例 d⋅v,按照权重融合了各个字的语义。最后将多个头的结果拼接成一个完成的embedding作为self-attendion的输出。
(batch_size, h, seq_len, seq_len) * batch_size, h, seq_len, embedding/h
部分代码如下:
# (batch, seq_len, h, embed/head) -> (batch, h, seq_len, embed/head)
q = self.qry(y).view(y.size(0), y.size(1), self.head, -1).transpose(1, 2)
k = self.key(x).view(x.size(0), x.size(1), self.head, -1).transpose(1, 2)
v = self.val(x).view(x.size(0), x.size(1), self.head, -1).transpose(1, 2)
d = torch.matmul(q, k.transpose(-2, -1)) / math.sqrt(k.size(-1)) # 相似度 (batch , h, seq, seq)
d = d.masked_fill(m, -float('inf')) # 把所有为true的地方替换成inf,这里是遮盖掉句子内部的pad
a = F.softmax(d, dim=-1) # (batch , h, seq, seq)
# (batch , h, seq_len, seq_len) * (batch, h, seq_len, embedding/h)
# => (batch, h, seq_len, embedding/h)
# => (batch, seq_len, h, embedding/h)
c = torch.matmul(a, v).transpose(1, 2)
# (batch, seq_len, embedding)
c = c.contiguous().view(c.size(0), c.size(1), -1)