写在前面
目前采用编码器-解码器 (Encode-Decode) 结构的模型非常热门,是因为它在许多领域较其他的传统模型方法都取得了更好的结果。这种结构的模型通常将输入序列编码成一个固定长度的向量表示,对于长度较短的输入序列而言,该模型能够学习出对应合理的向量表示。然而,这种模型存在的问题在于:当输入序列非常长时,模型难以学到合理的向量表示。这个问题限制了模型的性能,尤其当输入序列比较长时,模型的性能会变得很差。解决方法是将encoder的历史状态视作随机读取内存,这样不仅增加了源语言的维度,而且增加了记忆的持续时间(LSTM只是短时记忆)。
Attention机制
Attention机制的基本思想是,打破了传统编码器-解码器结构在编解码时都依赖于内部一个固定长度向量的限制。
Attention机制的实现是通过保留LSTM编码器对输入序列的中间输出结果,然后训练一个模型来对这些输入进行选择性的学习并且在模型输出时将输出序列与之进行关联。
更为通俗的一种解释是,attention机制就是将encoder的么一个隐藏状态设定一个权重,根据权重的不同决定decoder输出更侧重于哪一个编码状态。
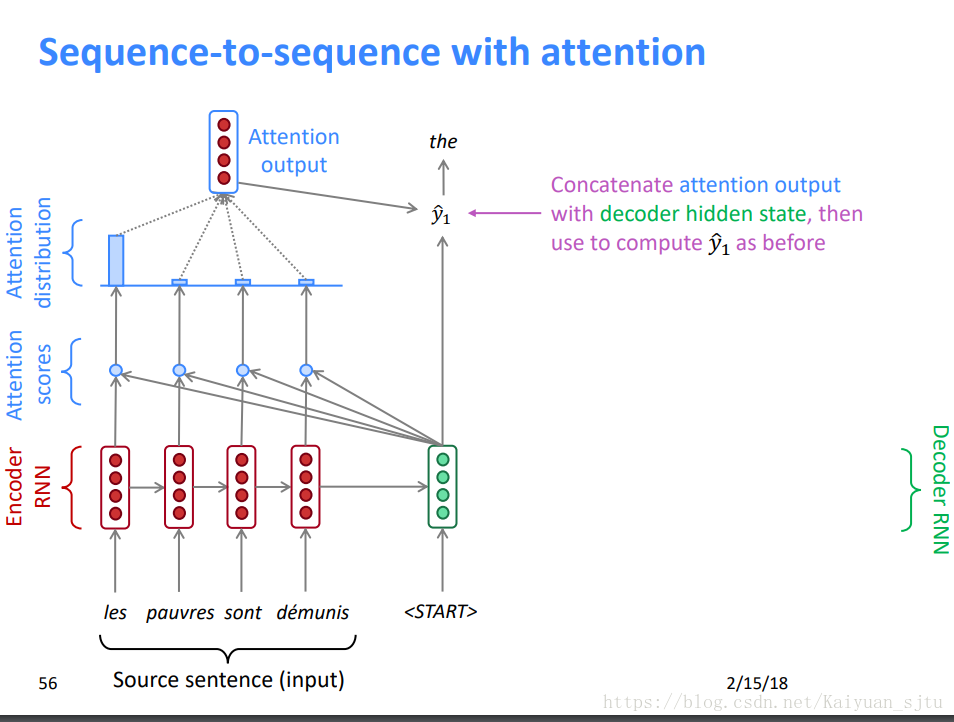
下面直接上图来看看attention机制的流程。
约定encoder hidden states:h1,h2,...,hn; 第t时刻decoder hidden state:St;
-
由encoder hidden states和decoder hidden state 计算每个encoder状态对应的attention score Et
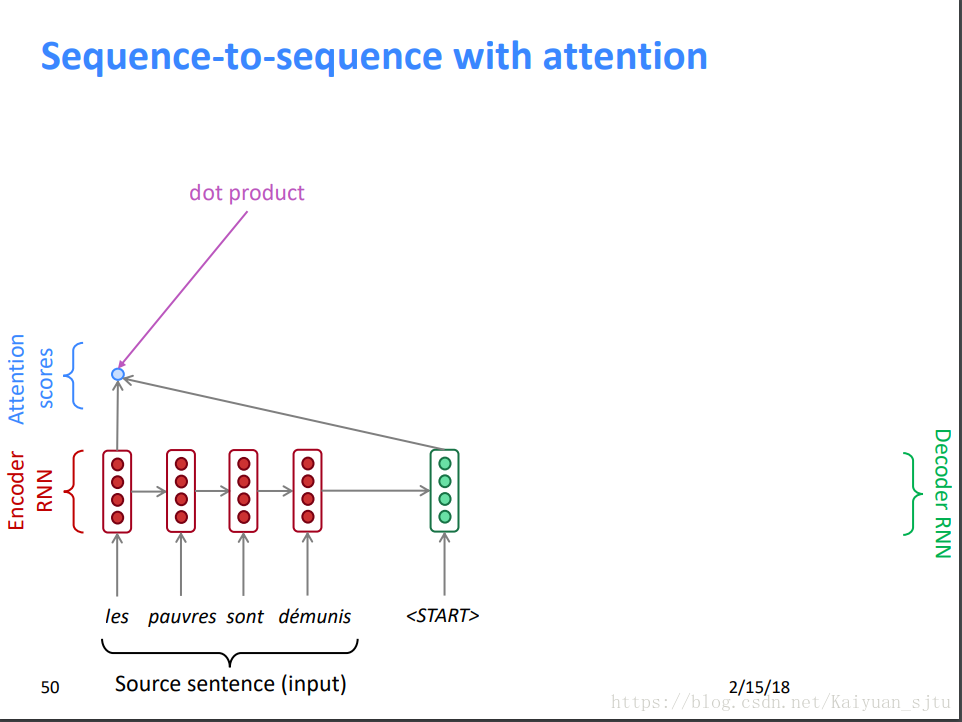

2.
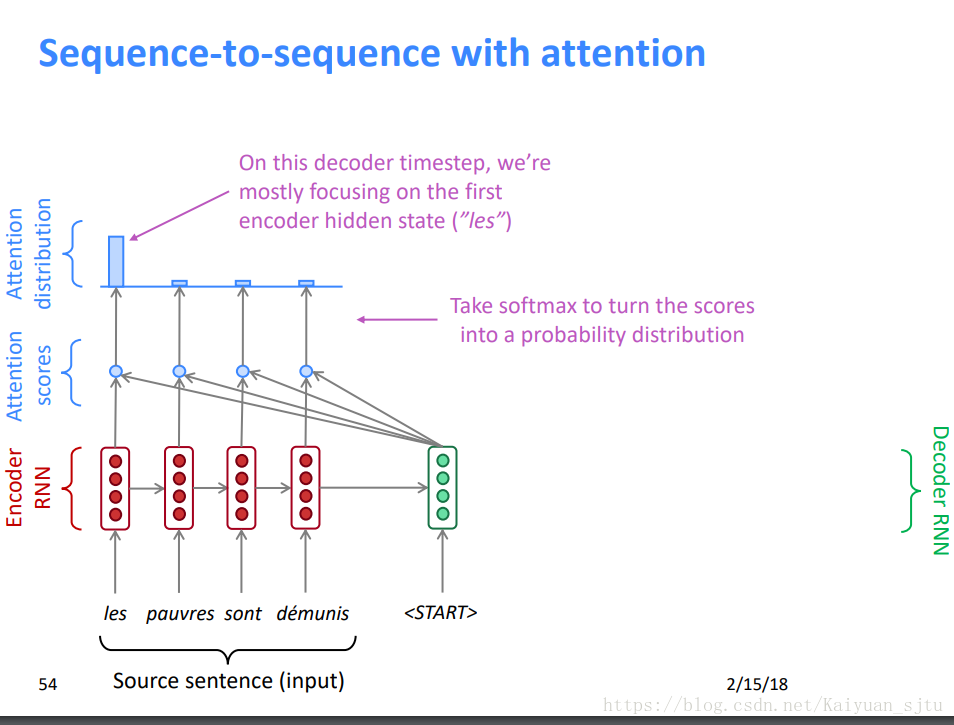
2.将Et softmax化后得到attention分布

3.将attention分布与encoder hidden state 相乘后相加得到attention vector
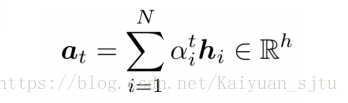
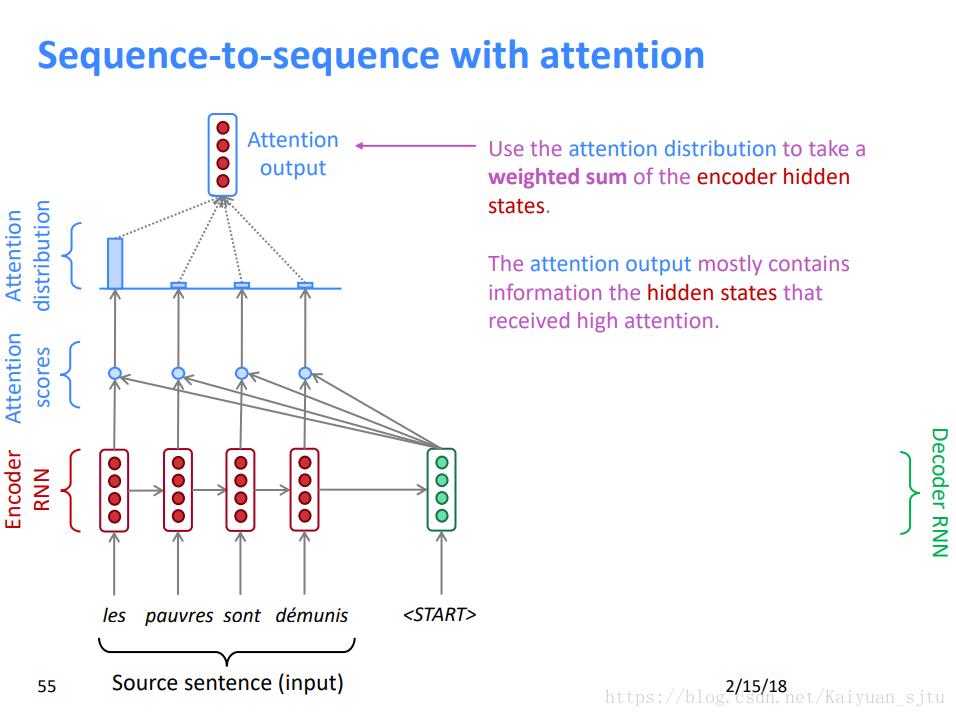
4.将attention vector与decoder hidden state 作为输入计算得出输出

参考资料
Attention and memory in deep learning and NLP
Survey on Attention-based Models Applied in NLP