Ov Seg - a Hugging Face Space by facebookDiscover amazing ML apps made by the community![]() https://huggingface.co/spaces/facebook/ov-seghttps://gitee.com/leeguandong/ov-seg/blob/main/open_vocab_seg/modeling/clip_adapter/adapter.py
https://huggingface.co/spaces/facebook/ov-seghttps://gitee.com/leeguandong/ov-seg/blob/main/open_vocab_seg/modeling/clip_adapter/adapter.py![]() https://gitee.com/leeguandong/ov-seg/blob/main/open_vocab_seg/modeling/clip_adapter/adapter.py分割一切后,SAM又能分辨类别了:Meta/UTAustin提出全新开放类分割模型让模型知道分割之后物体的类别,也不难。
https://gitee.com/leeguandong/ov-seg/blob/main/open_vocab_seg/modeling/clip_adapter/adapter.py分割一切后,SAM又能分辨类别了:Meta/UTAustin提出全新开放类分割模型让模型知道分割之后物体的类别,也不难。http://mp.weixin.qq.com/s?__biz=MzIwMTc4ODE0Mw==&mid=2247616891&idx=2&sn=a1dfad359c90d4e9d842230e9b1790db&chksm=96ebd6fba19c5fedd6a848caa8771840ec3a9ecc98fb7896e6358d916de94c0edba0fc409b51&mpshare=1&scene=24&srcid=04162WE9ctPSQ6qY1mDZn8VT&sharer_sharetime=1681605145081&sharer_shareid=72612fe2642f85b9e226cd89f212cc14#rd可以尝试一下作者放在hugging face上的demo,其中的sam版本很强,能处理很多问题,我之前对接过一个业务需求,甲方给了一个200个label,基本没有标注数据,希望对一些影视作品,电视剧网剧之类中的一些物体做识别,后续可能挖爆品挂商品链。这件事要是走标注数据就没得做了,但是本文通过改良clip,使用sam生成mask,将mask和text prompt(标签)做余弦相似度计算,即可获取目标。
1.动机
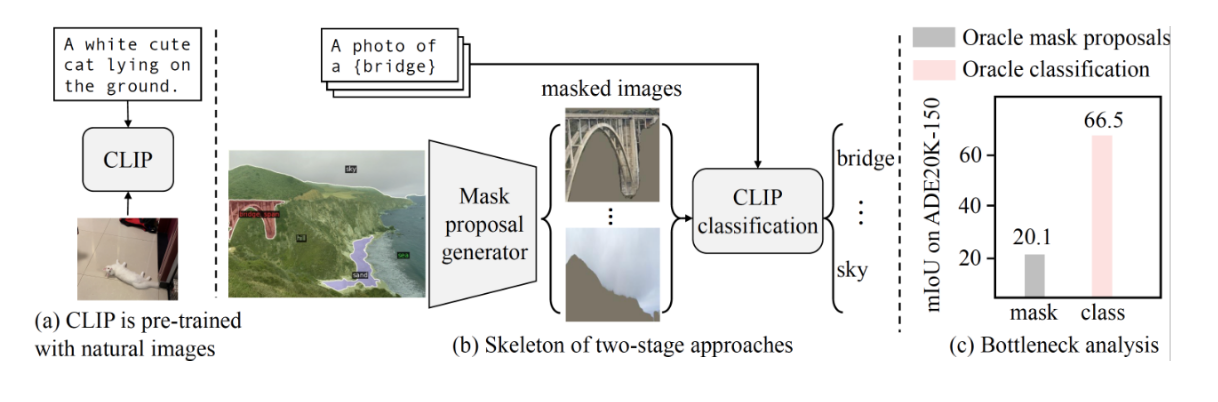
最近的两阶段方法首先生成不同类别的mask,然后利用clip对掩码区域进行分类,但是目前的性能瓶颈在clip上,因为它对mask图像表现不佳,最初训练clip的多为一幅图和一段文字的对应,clip使用很少的数据增强在自然图像上进行预训练的,输入的mask与自然图像存在巨大的差异。因此作者自然而然的想法是微调clip。
2.方法
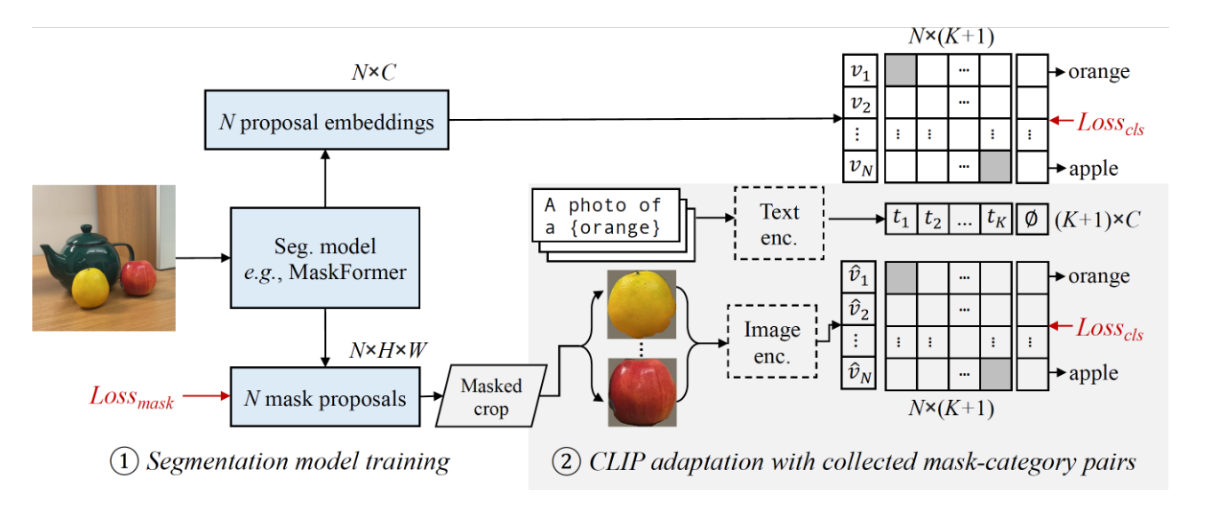
首先训练修改后的maskformer作为开放词汇分割的基线,然后从图像标题中收集多样的mask-text对,来训练clip。mask-text数据对可以从coco中收集。
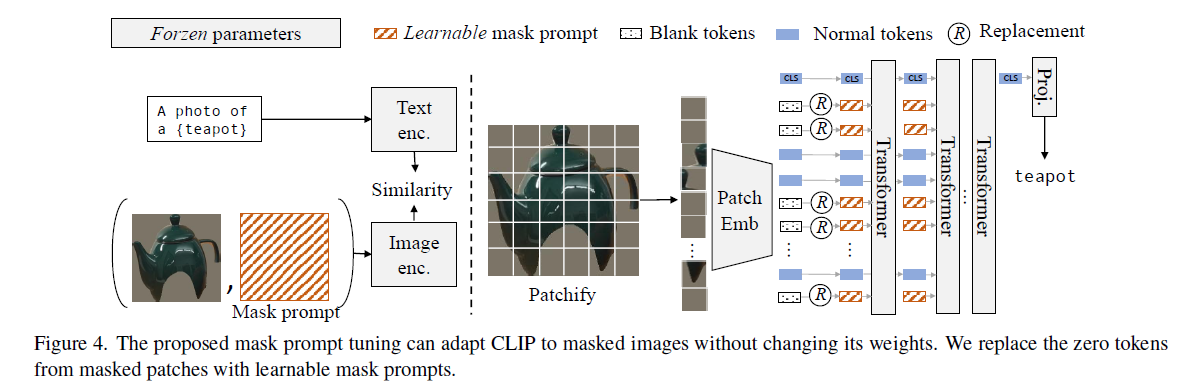
我看代码时,作者把maskformer和clip放到一起训练了,但是在hugging face开源出来的是sam+clip,clip肯定有单独训练版本的。
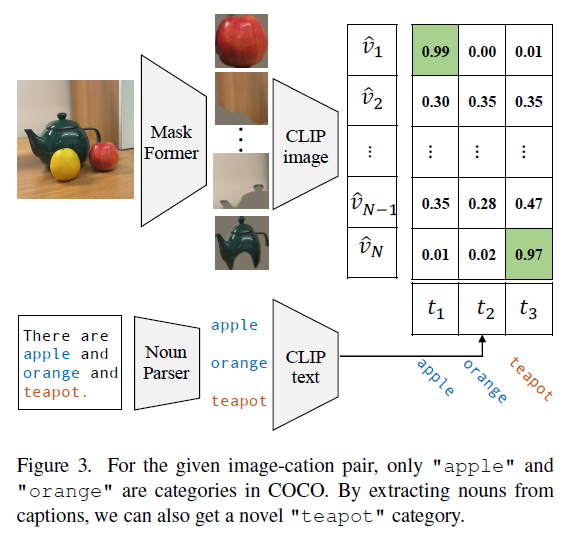
3.代码
class ClipAdapter(nn.Module):
def __init__(self, clip_model_name: str, mask_prompt_depth: int, text_templates: PromptExtractor):
super().__init__()
self.clip_model = build_clip_model(clip_model_name, mask_prompt_depth)
self.text_templates = text_templates
self.text_templates.init_buffer(self.clip_model)
self.text_feature_buffer = {}
def forward(self, image: torch.Tensor, text: List[str], **kwargs):
image = self._preprocess_image(image, **kwargs)
text_feature = self.get_text_features(text) # k,feat_dim
image_features = self.get_image_features(image)
return self.get_sim_logits(text_feature, image_features)
def _preprocess_image(self, image: torch.Tensor):
return image
def _get_text_features(self, noun_list: List[str]):
left_noun_list = [
noun for noun in noun_list if noun not in self.text_feature_buffer
]
if len(left_noun_list) > 0:
left_text_features = self.text_templates(
left_noun_list, self.clip_model
)
self.text_feature_buffer.update(
{
noun: text_feature
for noun, text_feature in zip(
left_noun_list, left_text_features
)
}
)
return torch.stack([self.text_feature_buffer[noun] for noun in noun_list])
def get_text_features(self, noun_list: List[str]):
return self._get_text_features(noun_list)
def get_image_features(self, image: torch.Tensor):
image_features = self.clip_model.visual(image)
image_features = image_features / image_features.norm(dim=-1, keepdim=True)
return image_features
def get_sim_logits(
self,
text_features: torch.Tensor,
image_features: torch.Tensor,
temperature: float = 100,
):
return temperature * image_features @ text_features.T
def normalize_feature(self, feat: torch.Tensor):
return feat / feat.norm(dim=-1, keepdim=True)代码也很简单,推理时就是计算mask和text的余弦值,选最大的返回即可。
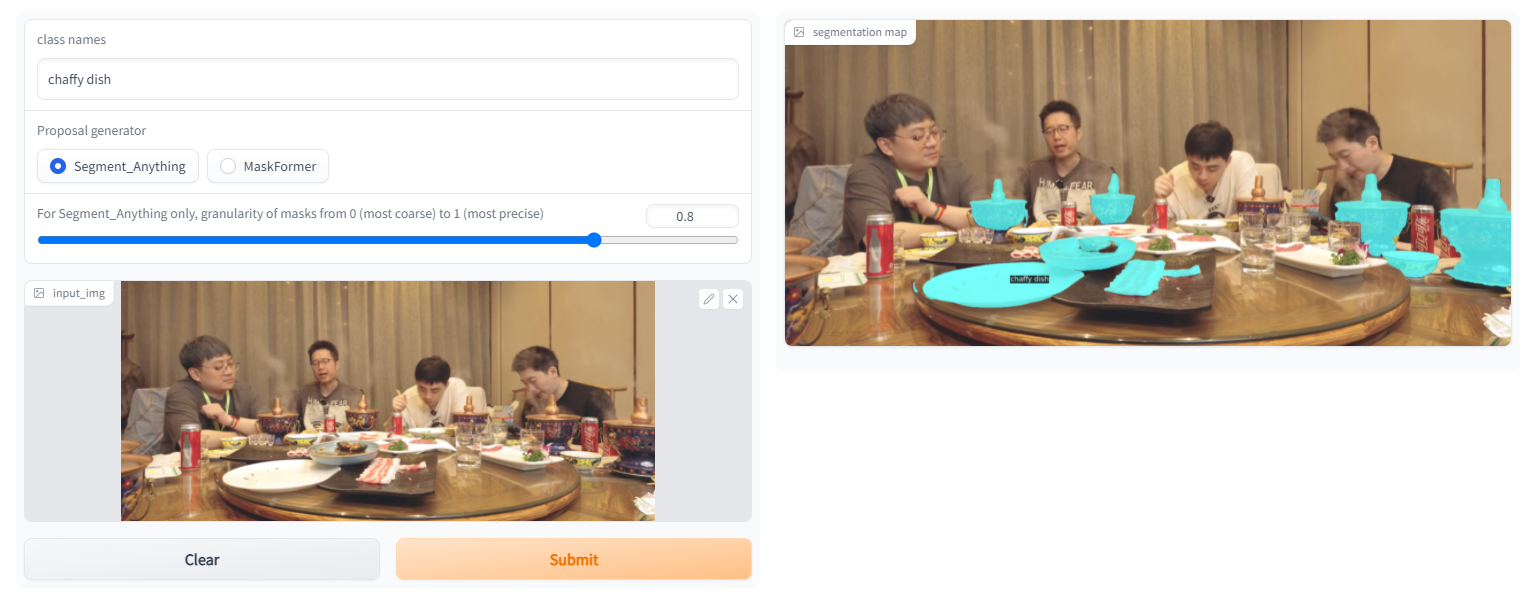
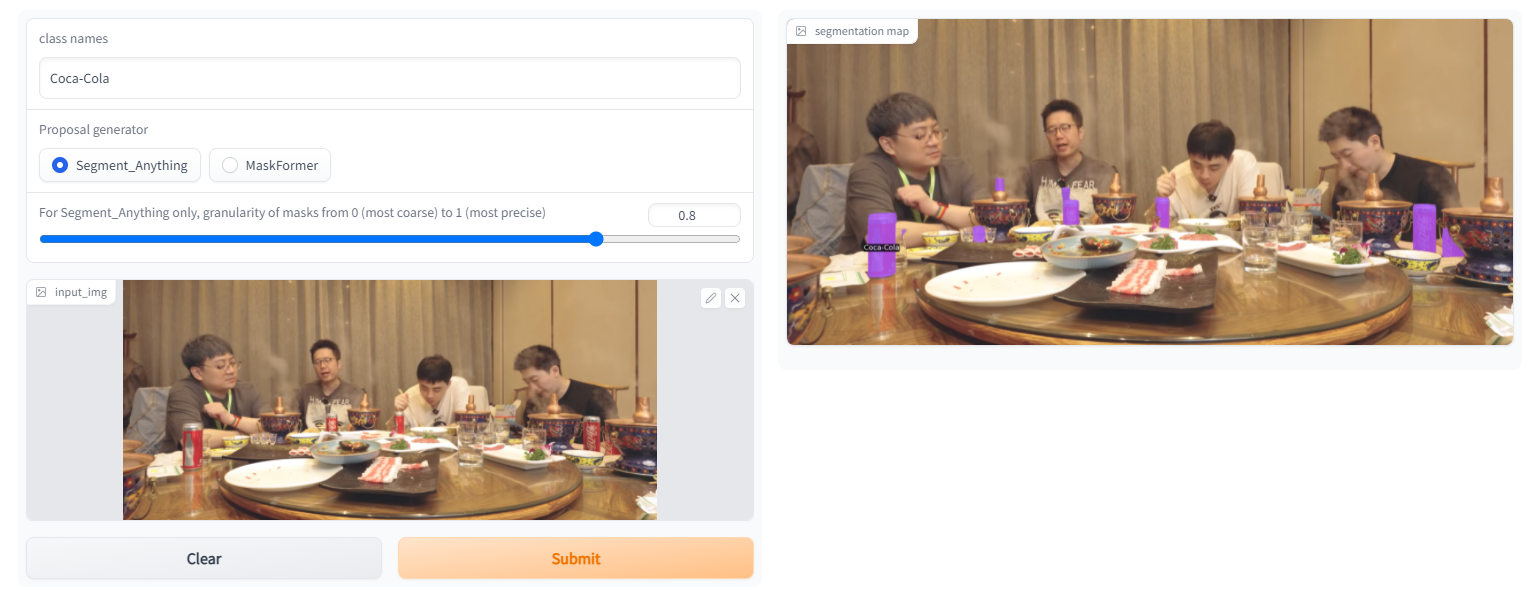
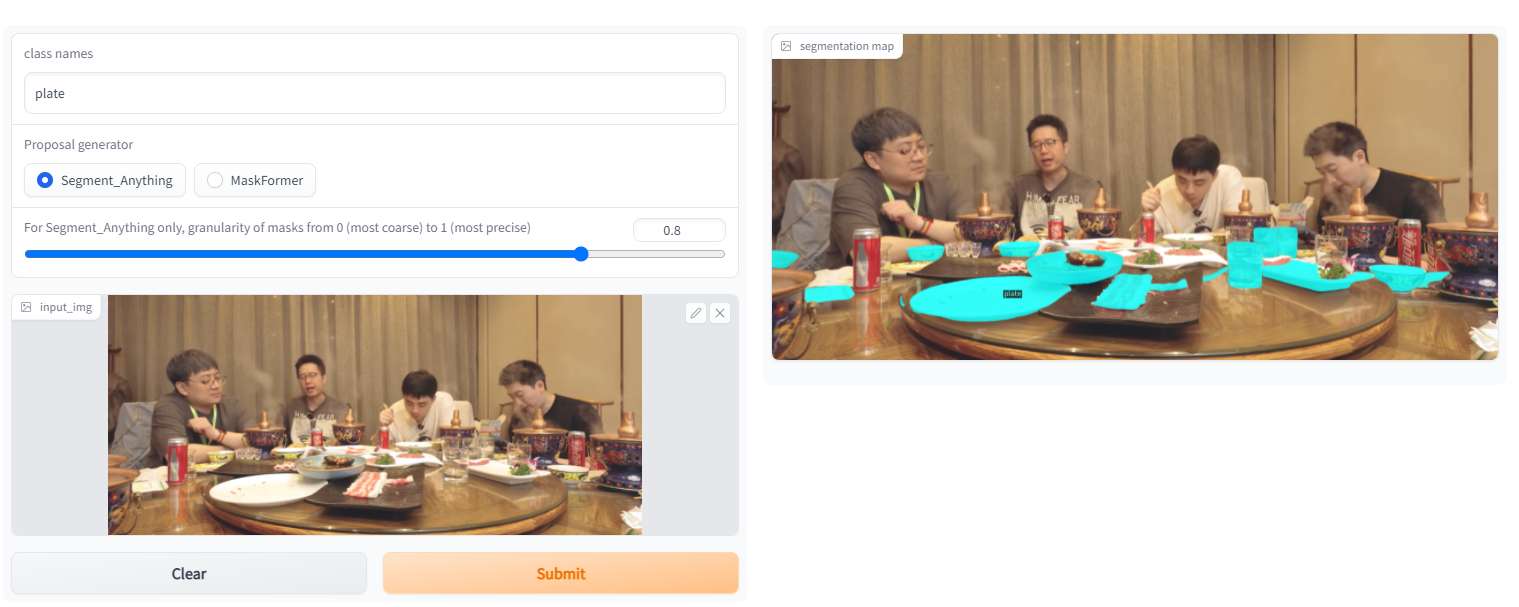
4.示例