
Title: OVO: Open-Vocabulary Occupancy
Paper: https://arxiv.org/pdf/2305.16133.pdf
Code: https://github.com/dzcgaara/OVO-Open-Vocabulary-Occupancy
导读
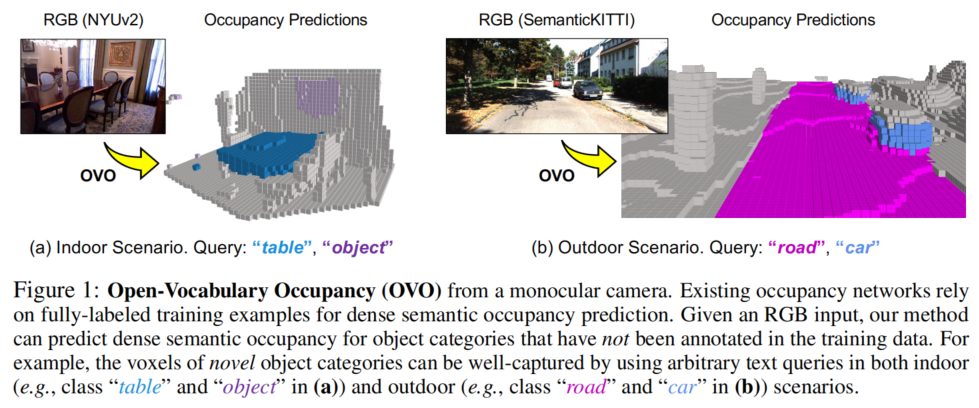
语义占据地图预测旨在推断自动驾驶载体在三维环境中安全操作所需的密集几何和语义信息。现有的占据预测方法几乎完全依赖于人工标注的体素数据进行训练。尽管这些数据质量很高,但生成这种三维标注是费时费力的,限制了其在训练数据集中只能用于少数特定对象类别。为了解决这个限制,本文提出了一种新颖的方法,称为开放词汇占据(Open Vocabulary Occupancy,OVO),它可以在训练过程中预测任意类别的语义占据,而无需3D标注。论文方法的关键点在于:(1)从预训练的二维开放词汇分割模型到三维占据网络的知识蒸馏,以及(2)像素-体素滤波以生成高质量的训练数据。得到的框架简单、紧凑,并且与大多数最先进的语义占据预测模型兼容。在NYUv2和SemanticKITTI数据集上,OVO与监督式语义占据预测方法相比具有竞争性的性能。此外,论文还进行了广泛的分析和消融研究,以提供对所提出框架设计的深入理解。
Open-Vocabulary
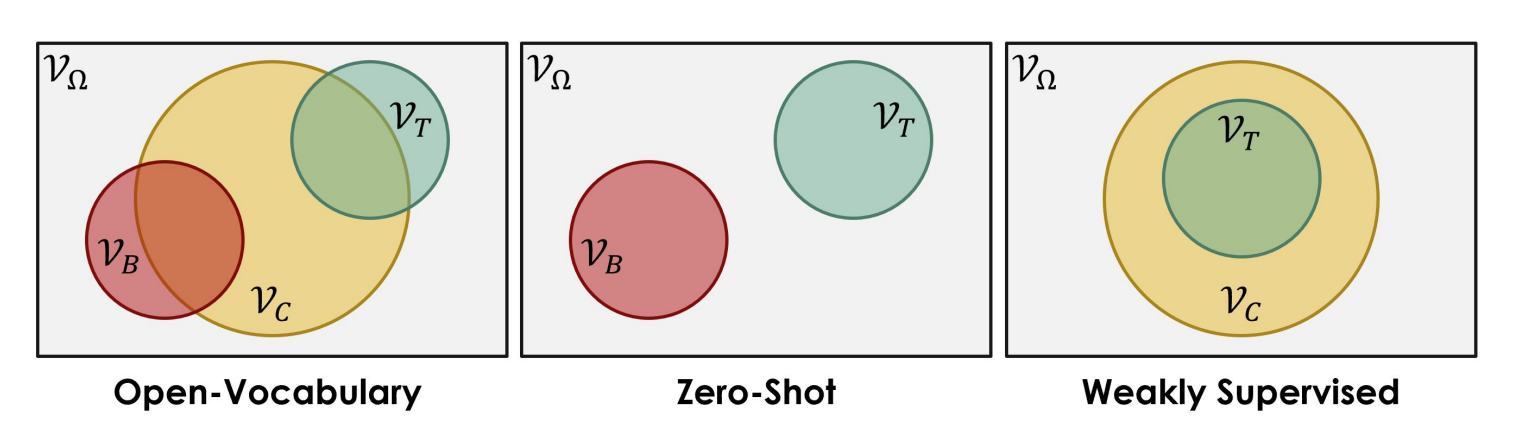
**Open-Vocabulary:**Open-Vocabulary方法旨在处理具有大量类别的任务,并不受固定词汇表的限制。它允许模型在训练和推理阶段处理未知的类别,从而具有更广泛的应用范围。
**Zero-Shot:**Zero-Shot方法是一种针对新类别的检测问题的训练方法。在训练阶段,模型只接触到一部分基础类别的数据,然后通过学习类别之间的关系,使得模型能够在测试阶段检测到从未见过的目标类别。
**Weakly Supervised:**Weakly Supervised方法是指在训练过程中使用较弱的监督信号。通常情况下,它们只使用部分标注数据或者使用较粗糙的标签信息。这种方法通常用于解决标注数据难以获取或成本较高的问题。
贡献
本文的主要贡献如下:
- 论文提出了一种面向语义占据任务的模型无关方法,称为开放词汇占据(OVO)。据研究者所知,这是首次尝试将开放词汇方法应用于占据任务领域。
- 论文引入了用于知识蒸馏的新颖特征对齐目标,这些目标来自现成的二维开放词汇模型。论文表明,针对训练的高质量体素选择是OVO成功的关键。
- 论文提出的框架在NYUv2和SemanticKITTI数据集上取得了具有竞争力的结果,展示了OVO框架和二维到三维蒸馏方法在解决复杂占据任务方面的有效性。
方法
在本文中,提出了一个针对开放词汇量的占据任务的模型无关框架。为了验证所提的方法,论文使用了MonoScene作为占据网络,使用CLIP文本编码器进行文本蒸馏,以及使用LSeg作为开放词汇图像编码器进行视觉蒸馏。LSeg能够预测与相应像素标签的文本embeddings对齐的像素embeddings。
通过特征对齐来进行知识蒸馏

图2展示了论文的整体框架。主要包含四个组件:(1) 一个2D网络( E 2 D E_{2D} E2D),从输入图像中提取2D特征,(2) 一个2D到3D特征转换模块,将2D表示提升到3D空间,(3) 一个3D网络( E 3 D E_{3D} E3D),通过学习场景内的语义关系来优化3D特征图,和 (4)一个占据头部,用于推断3D特征图中每个体素的几何和语义信息。文章的重点是**给定一个预训练的2D开放词汇分割模型,如何将其识别任意物体类别的知识融入到3D占据网络中?**本文详细介绍了三种对齐技术,以实现这一目标。
Voxel-to-Pixel Alignment
Voxel-to-pixel对齐是OVO中的一个关键模块,它使得体素特征能够模拟LSeg生成的2D特征,从而能够利用文本embedding来推断体素的类别。首先,通过筛选3D backbone网络生成的体素特征,得到有效的体素。然后,将这些有效的体素输入到3D蒸馏模块中,以将3D特征的维度与2D特征对齐。接下来,根据3D特征和2D特征之间的相似性计算出 L vox-pix L_{\text{vox-pix}} Lvox-pix。
Voxel-to-Text alignment
论文离线生成文本embedding,通过将类别文本与提示模板(例如,“一张{category}的照片”)输入文本编码器 E t e x t E_{text} Etext 进行编码。然后,计算体素embedding和文本embedding之间的余弦相似度。最后,应用 softmax 激活函数生成最终的预测结果。论文的目标是训练体素embedding,使其可以通过文本embedding进行分类。如图2所示,它用文本embedding替代了可学习的分类器。只有基础类别的文本embedding被用于训练。对于那些在基础类别中没有匹配到任何真实标签的体素,它们被分配到背景类别。体素到文本对齐的损失函数可以表示为 L vox-text L_{\text{vox-text}} Lvox-text。
Pixel-to-Pixel Alignment
像素对像素对齐旨在将来自教师图像编码器 E s e g E_{seg} Eseg的知识传递给学生编码器 E 2 D E_{2D} E2D。LSeg预测的这些像素的类别可以属于基础类别或新类别,因为网络具有泛化能力。具体而言,首先使用2D蒸馏将2D backbone生成的图像特征的维度提升。然后,对从Lseg获得的2D特征图和蒸馏后的图像特征进行2D像素对像素对齐,对齐损失为 L pix-pix L_{\text{pix-pix}} Lpix-pix。
Final Loss
最终的损失为:
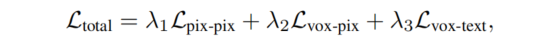
训练体素选择

由于图像中的视点范围、对象遮挡和二维模型预测中的不准确性,直接使用坐标映射创建样本对可能会导致大量不正确的配对关联。论文设计了三种策略,只保留高质量的体素,如图3所示。
- Image Range Filter:基于几何关系,根据相机姿态确定的2D投影范围之外的3D空间中的体素将被排除。
- Occlusion Filter:这个策略旨在解决遮挡问题,通过选择性地过滤掉具有大量遮挡的体素。由于语义信息完全来自体素,消除那些被其他体素遮挡的体素,因为它们无法对场景的语义理解做出贡献。
- Label Consistency Filter:为了消除LSeg中的不准确预测,开发了额外的滤波过程,以消除具有与其相应的2D像素不一致的语义标签的体素。
实验
论文在两个流行的**室内(NYUv2)和室外(SemanticKITTI)**语义占用预测基准上进行了实验。
Results on NYUv2
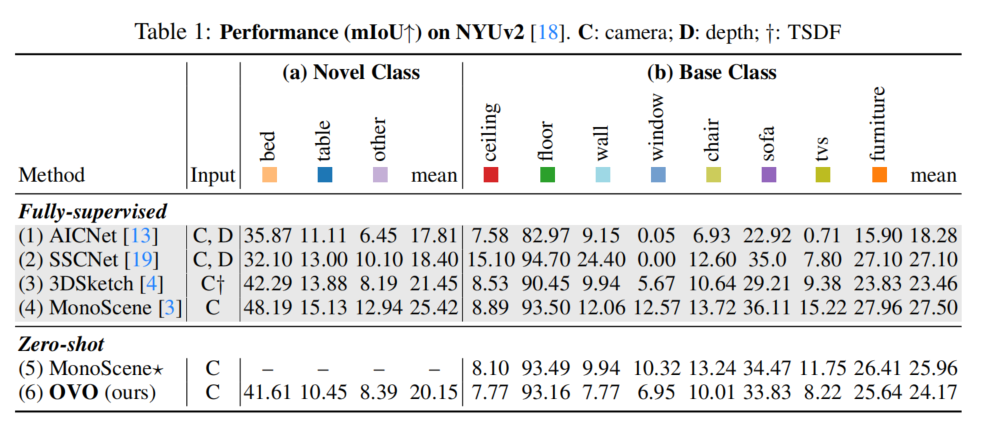
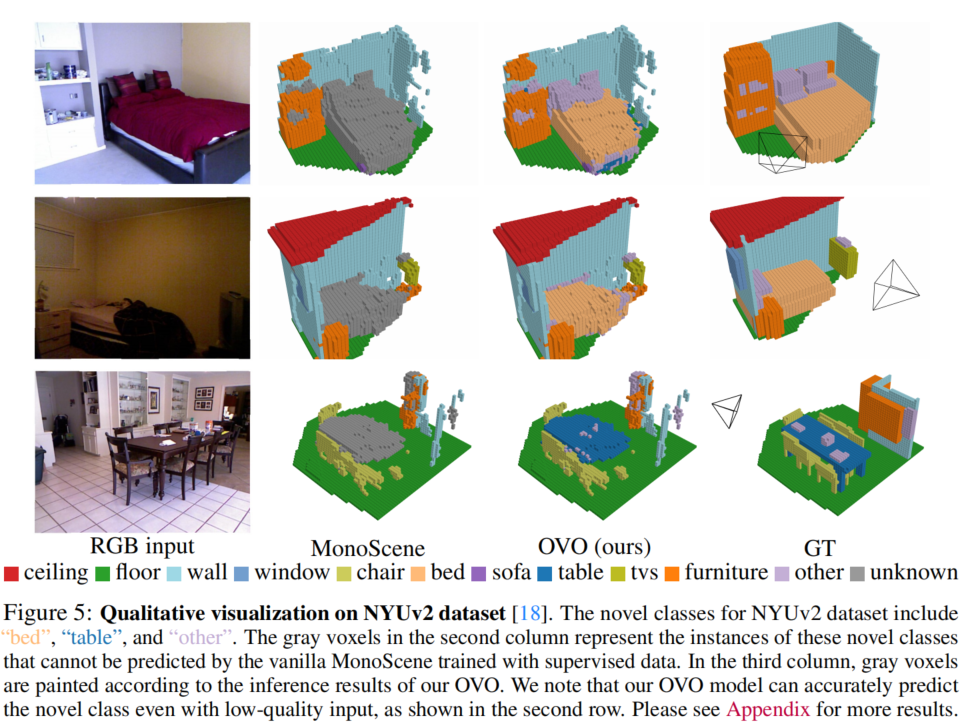
论文在NYUv2数据集上评估了OVO的性能,并将结果列在表1中。可以发现,在新颖类别上,OVO取得了竞争性的结果,甚至优于一些使用深度信息的监督方法。尽管在基础类别中略有性能下降,但通过实验证明这并不是由于论文的模型设计引起的,而可能是标签合并过程的影响。
Results on SemanticKITTI


论文在SemanticKITTI数据集上验证了OVO,并将结果列在表2中。实验结果再次表明,OVO方法在新颖类别上超过了AICNet和3DSketch,同时在基础类别上取得了可比较的结果,证明了论文方法在不同场景中的稳健性和泛化性。
总结
大多数现有的语义占据网络需要完全注释的体素数据来进行模型训练。在本文中,引入了开放词汇占据(Open Vocabulary Occupancy,简称OVO),它允许在训练过程中无需3D标注来进行未见过物体类别的语义占据预测。实质上,OVO是简单且与模型无关的。作为这一方向的首次尝试,研究者希望OVO能够为未来的研究提供baseline,并发挥优势。一个局限性是OVO依赖于体素级的语义预测,但在实例级别上没有进行优化,可能导致偶尔出现一个物体内部的不一致预测。未来的工作将探索体素分组技术,以提高实例级别上体素标签的整体一致性。