论文信息
name_en: PaLM-E: An Embodied Multimodal Language Model
name_ch: Palm-E:具身多模态语言模型实现
paper_addr: http://arxiv.org/abs/2303.03378
date_read: 2023-03-11
date_publish: 2023-03-06
tags: [‘深度学习’,‘多模态’]
author: Danny Driess等,谷歌
code: https://palm-e.github.io
读后感
Embodied一般译作“具身”,是一种基于身体经验和感知的认知学科,旨在研究人类知觉、思想和行动的相互作用。
自然语言模型包含了大量关于世界的内化知识,但是不“落地”,本文通过多模态接入了视频,传感器,将大模型学到的知识应用于机器人领域,进一步解决世界中的交互问题。PaLM-E直接产生动作的计划,从而让机器人以规划过程。
将字,图,传感器的结果等都Embedding映射到同一空间,在对模型结构改动小的情况下,同时使用了多模态数据。
文中还测试了将训练不同任务的训练数据放一起训练后三个模型效果都有提升,即举一返三的效果。
介绍
提出了多模态语言模型,将现实世界中连续的传感器数据接入语言模型,从而建立了词语和感知之间的联系。对将其运用到序列机器人操作规划、视觉问答和字幕等任务中。联合训练互联网中的语言,视觉和视觉语言领域,跨领域的多样化联合训练,提升了模型效果。训练的最大模型有 562B 参数,包含540B语言参数和22B视觉参数。
将从语言数据中学到的表征与现实世界的视觉和物理传感器模态联系起来,对于解决计算机视觉和机器人的现实问题至关重要。其具体方法是:将图像和状态等输入嵌入到与语言标记相同的隐空间中,并由基于Transformer的LLM的自注意力层以与文本相同的方式进行处理。
文章主要贡献如下:
- 提出并证明了一个通用的、可迁移学习的、多具身决策智能体,可以通过将具身数据混合到多模态大数据中进行训练。
- 使用视觉-语言模型解决具身推理问题。
- 提出神经网络结构,支持多模态token。
- 除了具身相关功能,PaLM-E在视觉和语言领域效果也不错。
- 展示了缩放语言模型大小可以在较少灾难性遗忘的情况下实现多模态微调。
Palm-E:具身多模态语言模型
PaLM-E的主要架构思想是在预训练语言模型的语言嵌入空间中注入连续的、具身的观测,如图像、状态估计或其他传感器模态。
PaLM-E是一个仅有解码器的LLM,在给定前缀或提示的情况下,自动生成文本补充。
具体方法如下,其输入形式如下:
sentence is Q: What happened between <img 1> and <img 2>?
其中img1/img2是图片嵌入。输出可以是问题的答案,或者文本形式生成的、由机器人执行的决策序列。
只有解码器的 LLMs
和GPT一样,这里的生成模型也只使用了Transformer的解码层,它根据前文中的词生成后面的词:
p ( w 1 : L ) = ∏ l = 1 L p L M ( w l ∣ w 1 : l − 1 ) p(w_{1:L}) = \prod\limits_{l=1}^{L} p_{\mathrm{LM}}(w_{l} \mid w_{1:l-1}) p(w1:L)=l=1∏LpLM(wl∣w1:l−1)
由于LLM是自回归的,因此预训练的模型可以用前缀w1:n作为条件,而不需要改变架构:
p ( w n + 1 : L ∣ w 1 : n ) = ∏ l = n + 1 L p L M ( w l ∣ w 1 : l − 1 ) p(w_{n+1:L}|w_{1:n}) = \prod\limits_{l=n+1}^{L} p_{\mathrm{LM}}(w_{l} \mid w_{1:l-1}) p(wn+1:L∣w1:n)=l=n+1∏LpLM(wl∣w1:l−1)
其中的前缀或提示w1:n提供了上下文,提示符可以包含LLM应该解决的任务的描述或者示例。
Token嵌入空间
上式中的w指自然语言中的离散的单词,一般通过γ将其映射到嵌入空间。
x i = γ ( w i ) ∈ R k x_i = γ(w_i) ∈ R^k xi=γ(wi)∈Rk
多模态句子:连续观察的注入
图片被注入嵌入空间时,跳过了离散token层,直接映射到嵌入空间X,训练编码器φ,用于实现具体的转换:

需要注意的是,单个观测Oj通常被编码为多个嵌入向量;另外,不同传感器可能使用不同编码器φ。
具身输出:机器人控制回路
为了将模型的文本输出和机器人的动作联系起来,文中区分了两种情况:
- 如果任务只能通过输出文本来完成,例如在具身问答或场景描述任务中,模型的输出直接是任务的解。
- 如果需要输出计划或者控制任务,PaLM-E会生成低级命令的文本。需要注意的是,它必须根据训练数据和提示自行确定哪些技能可用,并且不使用其他机制来约束或过滤其输出。它们不能解决长时任务或复杂指令,因此,PaLM-E被集成到一个控制回路中,其预测的决策由机器人通过低级策略执行,从而产生新的观测值,根据这些观测值,PaLM-E可以在必要时重新规划(一步一步预测)。
不同传感器模态的输入和场景表示
不同类型数据使用不同的方法映射到嵌入空间,数据包含:ViTs来转换2D图像,OSRT转换3D场景的表征;除了全局表征,还设计了以物体为中心的tokens来表征场景中的物体(将图片映射到不同物体)。
另外,PaLM-E需要在其生成的计划中引用对象,也就是场景中的物体,它们常常可以用自然语言中的属性来描述;有时更为复杂,比如场景中很多同一颜色的块;因此,设计了对象相关的提示:
Object j is <obj-j>, 使得PaLM-E中可使用obj-j来引用对象。
训练方法
训练数据包含连续的观测数据I,文本w,以及索引信息n;文本包含前缀ni以构成多模态句子,预测结果只包含文本。使用交叉熵作为损失函数,在每个非前缀token上计算损失。
模型包含三部分:观测数据编码器,映射器和自然语言模型,考虑到LLM存在大量推理信息,尽量冻结LLM,只对其它模型调参。
实验
图-1展示了具身模型的功能:

主要实验了三种机器人场景:Task and Motion Planning, Tabletop Manipulation, Mobile Manipulation,同时它还具体之前模型的视觉问答能力 Visual Q&A,以及自然语言处理能力 Language Only Tasks。
文中 6.1-6.4 介绍了机器人任务(略…)
通用型vs专用型(迁移)
实验了使用多种任务“全混合”共同训练模型。可以看到通过多任务训练,模型在各个任务中都得到了显著提升。

数据效率
与现有的大规模语言或视觉语言数据集相比,机器人数据的丰富程度明显较低。上述迁移机制有助于PaLM - E从机器人领域极少的训练样本中求解机器人任务。
保留语言能力
用两种方法:
- 一种是冻结LLM,只对其它模型调参,可以看到,冻结后效果不如调参好,但效果也可达到74.3%。
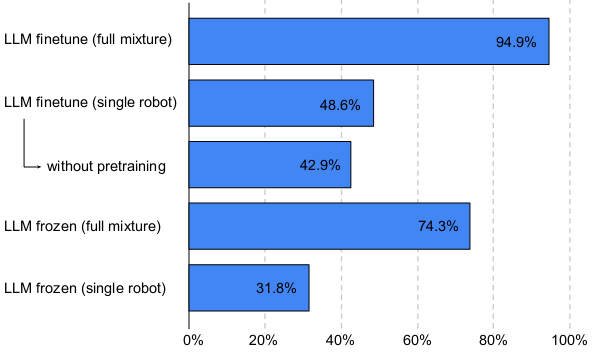
- 另一种是训练端到端的模型,两种方法都可用。端到端训练时,随着模型规模的增加,模型保留了更多的原始语言性能。可以看到,在562B模型的自然语言处理性能损失只有3.9%。

实验还证明:在普通的视觉和自然语言任务中,加入了具身能力的模型的能力也没有太大损失。
自然语言模型给机器人带来了具身推理能力,在结合了之前其它能力的情况下(如场景表示能力),使PaLM-E成为了通才。