Fully-Convolutional Siamese Networks for Object Tracking
这是ECCVw 2016的一篇论文,和staple同出于牛津组。提出一种基于全卷积孪生网络的基本追踪算法模型,能够超实时的帧率达到很高的精度。
项目网页 http://www.robots.ox.ac.uk/~luca/siamese-fc.html
开源代码: https://github.com/bertinetto/siamese-fc
出发点
针对tracking问题,传统方法仅通过在线学习目标外观模型来解决,如TLD,Struck,KCF等算法。但这类 online-only approach 只从跟踪视频本身进行学习,限制了可以学到的模型的丰富性,得到的模型相对简单。
而目前基于深度学习的方法,要不就是采用 shallow methods(如:correlation filters)利用网络的中间表示作为 feature;要不就是执行 SGD 算法来微调多层网络结构。但是,利用 shallow 的方法并不能充分发挥 end-to-end 训练的优势,采用 SGD 的方法来微调也无法达到实时的要求。
将DL用于tracking中,有两点制约其发展:
1、训练数据的稀缺。由于跟踪目标事先未知,只能通过最初的框选定,无法预先准备大量训练数据。
2、实时的约束。对于跟踪问题来说,基于DL的做法虽然能有效提升模型的丰富度,能够很好的提升跟踪的效果,但是在时效性这一方面却做的很差,因为DL复杂的模型往往需要很大的计算量,尤其是当使用的DL模型在跟踪的时候需要对模型进行更新的话,需要在线SGD调整网络参数,限制了速度,可能使用GPU都没法达到实时。
SiameseFC分别针对这两点,利用ILSVRC15 数据库中用于目标检测的视频来训练模型(离线训练),在跟踪时,不更新模型(也就没有fine-tuning),保证速度够快。成为了使用了CNN进行跟踪,同时又具有很高的效率的跟踪算法。并因其速度很快,效果很好,成为之后很多算法(例如CFNet、DCFNet)的baseline。
简要介绍
本文将一个全卷积 Siamese 网络嵌入到一个简单的跟踪算法中,使其跟踪效果很好,速度很快(58fps)。该 Siamese 网络使用的训练数据是 ILSVRC15 数据库中用于目标检测的视频。
针对任意目标跟踪问题,一般使用在线学习策略来学习合适的跟踪模型,但在使用了CNN模型后,由于需要Stochastic Gradient Descent 在线更新网络权重参数,导致速度很慢。本文提出的CNN算法是离线学习的。
算法原理
学习任意物体的跟踪可以通过相似性学习来解决,在深度学习中,我们一般使用 Siamese 网络来学习深度相似性函数。
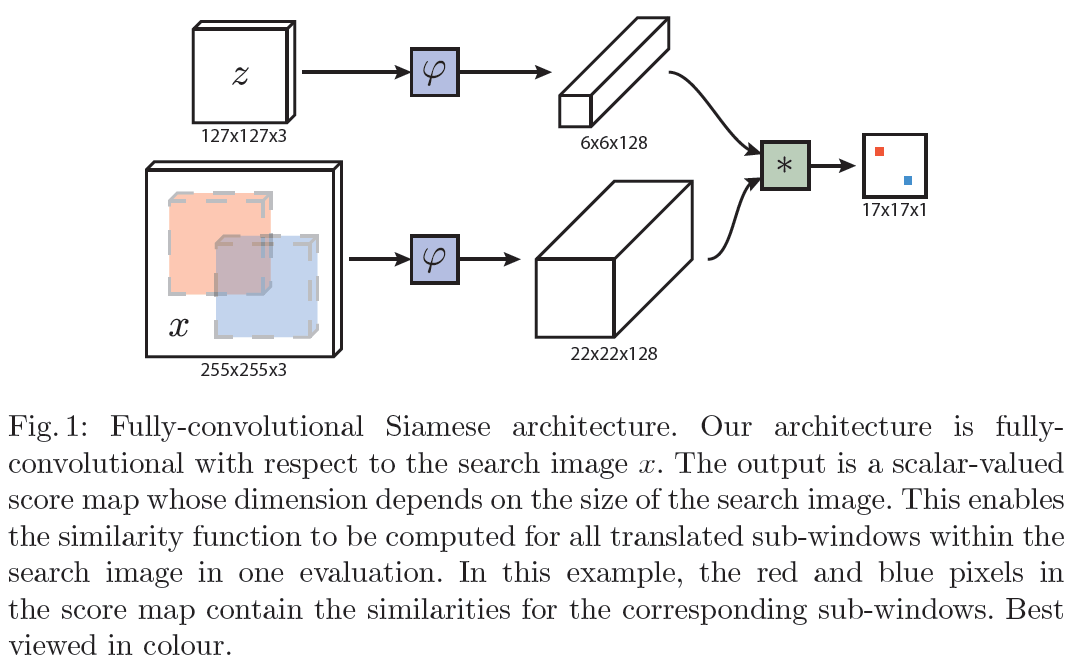
图中z代表的是模板图像,算法中使用的是第一帧的groundtruth;x代表的是search region,代表在后面的待跟踪帧中的候选框搜索区域;ϕ代表的是一种特征映射操作,将原始图像映射到特定的特征空间,文中采用的是CNN中的卷积层和pooling层;6*6*128代表z经过ϕ后得到的特征,是一个128通道6*6大小feature,同理,22*22*128是x经过ϕ后的特征;后面的*代表卷积操作,让22*22*128的feature被6*6*128的卷积核卷积,得到一个17*17的score map,代表着search region中各个位置与模板相似度值。
总体来说,卷积网络将search image作为整体输入,直接计算两个输入图像的feature map的相似度匹配,节省了计算。计算得到相似度最高的位置,并反向计算出目标在原图中的位置。
算法本身是比较搜索区域与目标模板的相似度,最后得到搜索区域的score map。其实从原理上来说,这种方法和相关性滤波的方法很相似。其在搜索区域中逐个的对目标模板进行匹配,将这种逐个平移匹配计算相似度的方法看成是一种卷积,然后在卷积结果中找到相似度值最大的点,作为新的目标的中心。
上图所画的ϕ其实是CNN中的一部分,并且两个ϕ的网络结构是一样的,这是一种典型的孪生神经网络,并且在整个模型中只有conv层和pooling层,因此这也是一种典型的全卷积(fully-convolutional)神经网络。
具体实现
损失函数
在训练模型的时肯定需要损失函数,并通过最小化损失函数来获取最优模型。本文算法为了构造有效的损失函数,对搜索区域的位置点进行了正负样本的区分,即目标一定范围内的点作为正样本,这个范围外的点作为负样本,例如图1中最右侧生成的score map中,红色点即正样本,蓝色点为负样本,他们都对应于search region中的红色矩形区域和蓝色矩形区域。文章采用的是logistic loss,具体的损失函数形式如下:
对于score map中每个点的损失:
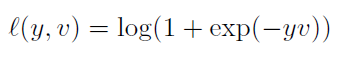
其中v是score map中每个点真实值,y∈{+1,−1}是这个点所对应的标签。
如上图网络结构中所示,6*6和22*22的feature map“卷积”得到17*17的score map。对于每个score map,计算其loss为每个卷积得到的6*6小图的loss的均值。即:
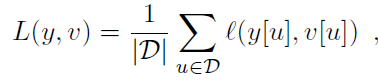
这里的u∈D代表score map中的位置。 卷积网络的参数由SGD方法最小化上图损失函数得到。
训练所用数据库
与以前的算法不一样的是,训练所用的数据库并不是传统的VOT,ALOV,OTB这三个跟踪benchmark,而是ILSVRC(ImageNet Large Scale Visual Recognition Challenge)中用于视频目标检测中的视频,这个数据集一共有4500个videos,视频的每一帧都有标记的groundtruth。而VOT,ALOV,OTB这三个数据集加起来也就不到500个视频。
实际上要先对这些数据进行处理,主要包括:
1. 扔掉一些类别: snake,train,whale,lizard 等,因为这些物体经常仅仅出现身体的某一部分,且常在图像边缘出现;
2. 排除太大 或者 太小的物体;
3. 排除离边界很近的物体。
网络结构
用模板的CNN特征与搜索图像的特征进行卷积,得到整个图像的相似图。网络结构如下:(有的博客中说整个网络结构类似与AlexNet,但是没有最后的全连接层,只有前面的卷积层和pooling层。 )
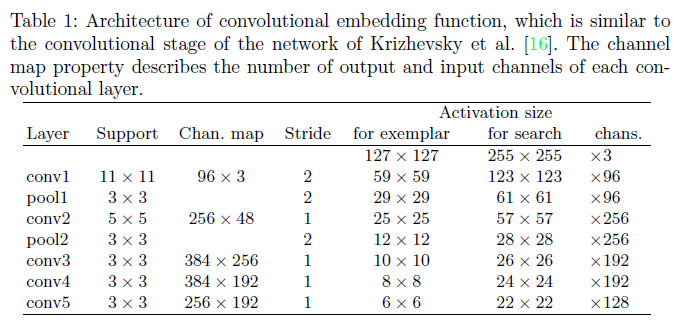
整个网络结构入上表,其中pooling层采用的是max-pooling,每个卷积层后面都有一个ReLU非线性激活层,但是第五层没有。另外,在训练的时候,每个ReLU层前都使用了batch normalization,用于降低过拟合的风险。
image情况
训练中,从标注视频数据库中提取exemplar和search image对,均以目标为中心。从两帧相隔T帧以上的图像中选取(exemplar和search image从不同帧中挑出)。每个image中目标的scale被无损纵横比地归一化。如果结果在以目标为中心的半径为R的圆内则记为positive。
tips:像图中所示的那样,对图像进行填充,而不会损失物体尺寸上的信息。

一些实现细节
- 训练采用的优化算法就是batch SGD,batch大小是8
- 跟踪时直接对score map进行线性插值,将17*17的score map扩大为272*272,这样原来score map中响应值最大的点映射回272*272目标位置。
评测结果
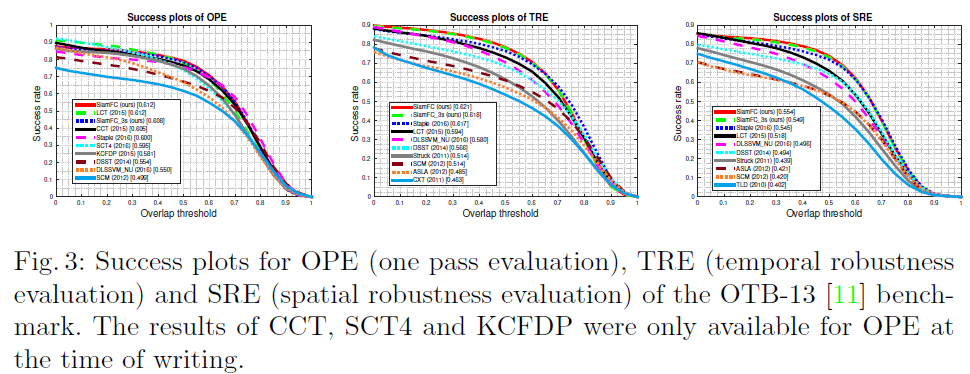
OTB2013数据库上测试对比
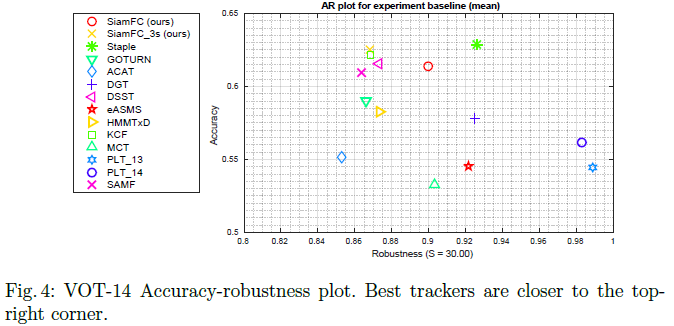
VOT14数据库上测试对比
VOT15数据库上测试对比