论文标题:PaLM-E: An Embodied Multimodal Language Model
论文作者:Danny Driess, Fei Xia, Mehdi S. M. Sajjadi, Corey Lynch, Aakanksha Chowdhery, Brian Ichter, Ayzaan Wahid, Jonathan Tompson, Quan Vuong, Tianhe Yu, Wenlong Huang, Yevgen Chebotar, Pierre Sermanet, Daniel Duckworth, Sergey Levine, Vincent Vanhoucke, Karol Hausman, Marc Toussaint, Klaus Greff, Andy Zeng, Igor Mordatch, Pete Florence
论文原文:https://arxiv.org/abs/2303.03378
论文出处:ICML 2023
论文被引:247(2023/10/15)
论文代码:https://palm-e.github.io
Summary
提出背景
大型语言模型(LLMs)在现实世界中推理的局限性在于基础问题:虽然在海量文本数据上训练 LLM 可能会产生与我们的物理世界相关的表征,但将这些表征与现实世界中的视觉和物理传感器模态连接起来,对于解决计算机视觉和机器人学中更广泛的基础现实世界问题至关重要。
SayCan(Do as i can, not as i say: Grounding language in robotic affordances,2022)将 LLM 的输出与学习到的机器人策略(robotic policies)和功能可用性函数(affordance functions)连接起来以做出决策,但其局限性在于 LLM 本身只提供文本输入,这对于许多场景的几何配置非常重要的任务来说是不够的。
最先进的视觉语言模型是在典型的视觉语言任务(如 VQA)中训练出来的,无法直接解决机器人推理任务。
本文做法
提出了具身语言模型 PaLM-E,该模型直接纳入了来自具身智能体(embodied agent)的传感器模态的连续输入,从而使语言模型本身能够在现实世界中为顺序决策做出更有依据的推断。
- 图像和状态估计等输入信息被嵌入到与语言标记相同的潜在嵌入中,并由基于Transformer的 LLM 的自注意力层以与文本相同的方式进行处理。
- 从预先训练好的 LLM 开始,通过编码器注入连续输入。这些编码器经过端到端训练,以自然文本的形式输出连续的决策,而这些文本可以通过调节低层次策略的方式由具身智能体(embodied agent)进行解释,或者给出具身问题的答案。
本文贡献
- 1)提出并证明了可以通过在多模态大型语言模型的训练中混合具身数据来训练通用的、迁移学习的、多具身决策智能体(multi-embodiment decision-making agent)。
- 2)证明了虽然目前最先进的通用视觉语言模型开箱即用(zero-shot),但并不能很好地解决具身推理问题,而本文的 PaLM-E 是高效具身推理器的通用视觉语言模型。
- 3)在研究如何以最佳方式训练此类模型时,引入了新颖的架构理念,如神经场景表征(neural scene representations)和实体标签多模态标记(entity-labeling multimodal tokens)。
- 4)PaLM-E 作为一种具身推理器(embodied reasoner),也是一种具有定量能力的视觉和语言通才。
- 5)证明了语言模型大小的缩放可实现多模态微调,减少灾难性遗忘(catastrophic forgetting)。
本文结论
建议将图像等多模态信息注入预先训练好的 LLM 的嵌入空间,从而建立一个具身语言模型。
- PaLM-E 是一种能够在模拟和现实世界中控制不同机器人的单一模型,同时还能定量地胜任一般的 VQA 和图像描述任务。特别是将神经场景表征(即 OSRT)纳入模型的新颖架构理念,即使没有大规模数据,也特别有效。
- PaLM-E 是在多种机器人体现形式的不同任务以及一般视觉语言任务的混合物上进行训练的。这种多样化的训练可以将视觉语言领域的知识转移到具体化的决策制定中,从而使机器人规划任务能够高效地实现数据化。
- 冻结语言模型是实现完全保留语言能力的通用型多模态模型的可行途径,但我们也发现了另一条使用非冻结模型的途径:扩大语言模型的规模可显著减少灾难性遗忘,同时成为一个具身智能体。
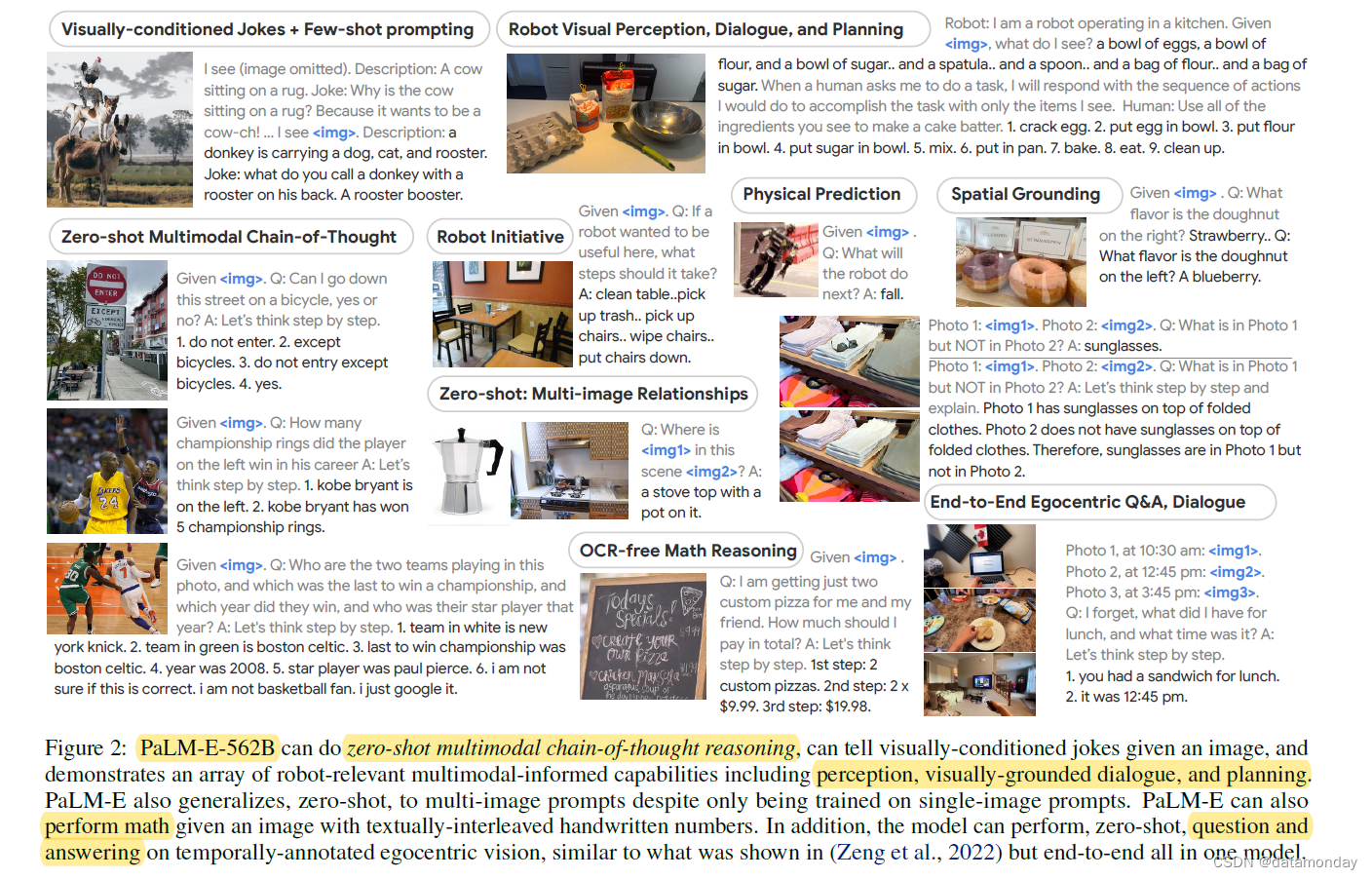
- PaLM-E-562B 展示了新出现的能力,如多模态思维链推理,以及对多幅图像进行推理的能力,尽管它只接受过单幅图像提示的训练。
相关工作
1)通用视觉语言建模:整合图像的方法各不相同。
- Flamingo(Flamingo: a Visual Language Model for Few-Shot Learning, 2022)通过一种直接关注单个上下文图像的机制来增强预训练语言模型。
- Frozen(Multimodal Few-Shot Learning with Frozen Language Models,2021) 通过冻结 LLM 的反向传播来优化视觉编码器参数。
- PaLI: A Jointly-Scaled Multilingual Language-Image Model, 2022
2)动作输出模型:将视觉和语言输入结合在一起,以实现直接行动预测的目标。下述研究中,语言的作用被描述为任务规范。
- Instruction-driven history-aware policies for robotic manipulations,2022
- Perceiver-Actor: A Multi-Task Transformer for Robotic Manipulation,2022
- BC-Z: Zero-Shot Task Generalization with Robotic Imitation Learning,2022
- Learning Language-Conditioned Robot Behavior from Offline Data and Crowd-Sourced Annotation,2022
- Interactive Language: Talking to Robots in Real Time,2022
- RT-1: Robotics Transformer for Real-World Control at Scale,2022
- 探索了与 PaLM-E 类似的多模态提示:VIMA: General Robot Manipulation with Multimodal Prompts
- 输出行动中是一个通用的多具身代理:Gato(A Generalist Agent,2022)
3)具身任务规划中的LLM:以往的研究侧重于理解自然语言目标,而PalLM-E是将自然语言作为规划(planning)表征。LLMs 包含大量关于世界的内化知识 (Bommasani et al., 2021),但如果没有基础(grounding),生成的计划可能无法执行。PaLM-E 经过训练后可直接生成计划,而无需依赖辅助模型作为基础(grounding)。
- 利用 LLM 生成的指令与符合条件的指令集之间的语义相似性:Language Models as Zero-Shot Planners: Extracting Actionable Knowledge for Embodied Agents (2022b)
- 功能可用性函数(affordance functions):Do As I Can, Not As I Say: Grounding Language in Robotic Affordances (2022)
- 视觉反馈(visual feedback):Inner Monologue: Embodied Reasoning through Planning with Language Models (2022)
- 生成世界模型(generating world models):
- Do embodied agents dream of pixelated sheep?: Embodied decision making using language guided world modelling (2023)
- PIGLeT: Language Grounding Through Neuro-Symbolic Interaction in a 3D World (2021)
- 通过图形和地图进行规划:
- LM-Nav: Robotic Navigation with Large Pre-Trained Models of Language, Vision, and Action (2022)
- Visual Language Maps for Robot Navigation (2022)
- 视觉解释:Describe, Explain, Plan and Select: Interactive Planning with Large Language Models Enables Open-World Multi-Task Agents (2023)
- 程序生成:
- Code as Policies: Language Model Programs for Embodied Control (2022)
- ProgPrompt: Generating Situated Robot Task Plans using Large Language Models (2022)
- 向提示注入信息(injecting information into the prompt):Socratic Models: Composing Zero-Shot Multimodal Reasoning with Language (2022)
PaLM-E 以文本形式生成高级指令,模型能自然而然地以自身预测为条件,并直接利用其参数中蕴含的世界知识。这不仅能实现具身推理,还能实现问题解答。
具体方法
PaLM-E 使用 PaLM (2022) 作为预训练语言模型,并将其应用于具身(Embodied)任务。
PaLM-E 的主要架构思想是将连续、具体的观察结果(如图像、状态估计或其他传感器模态)注入预训练语言模型的语言嵌入空间。具体做法是将连续观察结果编码成一串向量,其维度与语言标记的嵌入空间相同。因此,连续信息将以类似于语言标记的方式注入语言模型。
PaLM-E 是一种仅用于解码器的 LLM,它能根据前缀(prefix)或提示(prompt)自回归地生成文本补全。PaLM-E 是一个生成模型,以多模态句子为输入,生成文本。如果任务只需输出文本即可完成,例如在具身问答或场景描述任务中,那么模型的输出就直接被视为任务的解决方案。如果 PaLM-E 被用来解决一个具体化的规划或控制任务,它就会生成为低级命令(command)创造条件的文本。
PaLM-E 的输入由文本和(多个)连续观察结果组成。与这些观察结果相对应的多模态标记与文本交错在一起,形成多模态句子(multi-modal sentences)。这种多模态句子的一个例子是:Q: What happened between <img 1> and <img 2>? 其中 <img i> 表示图像的嵌入。PaLM-E 的输出是由模型自动递归生成的文本,可以是问题的答案,也可以是 PaLM-E 以文本形式生成的、应由机器人执行的决策序列。当PaLM-E受命生成决策或计划时,我们假设存在一个低层次的策略或计划器,可以将这些决策转化为低层次的行动。
PaLM-E 被集成到一个控制环(control-loop)中,机器人通过低级策略执行其预测决策,从而产生新的观察结果,PaLM-E 能够根据这些观察结果在必要时重新规划。
1)Prefix-decoder-only LLMs
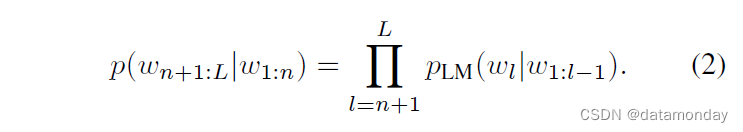
前缀或提示 w1:n 为 LLM 继续预测后续标记 wn+1:L(输入的文本数据)提供了上下文。这通常用于推理,以引导模型的预测。例如,提示可以包含对 LLM 应解决的任务的描述,或类似任务的所需文本补全示例。这里的前缀或提示部分不参与损失函数计算。
2)Token embedding space
标记 wi 是固定词汇(fixed vocabulary) W 的元素,词汇 W 是一个离散的有限集合,它对应于自然语言中的(子)词。在内部,LLM 通过 γ : W → X 将 wi 嵌入一个词标记嵌入空间 X ⊂ Rk,即 pLM(wl|x1:l-1),xi = γ(wi) ∈ Rk。映射 γ 通常表示为大小为 k × |W| 的大型嵌入矩阵,并进行端到端训练。
3)Multi-modal sentences: injection of continuous observations
通过跳过离散标记层,直接将连续观察结果映射到语言嵌入空间 X,可以将图像观察结果等多模态信息注入 LLM。为此,训练一个编码器 φ : O → X q φ : O → \mathcal{X}^q φ:O→Xq,将(连续)观测空间 O 映射到 X 中的 q 多向量序列。然后,这些向量与正常嵌入的文本标记交错(interleaved),形成 LLM 的前缀。这意味着前缀中的每个向量 xi 都是由单词标记嵌入器(word token embedder) γ 或编码器 φi 形成的:

一个观测值 Oj 通常会被编码成多个嵌入向量。可以在前缀的不同位置交错使用不同的编码器 φi,以组合来自不同观测空间的信息等。
4)Input & Scene Representations for Different Sensor Modalities
1’ 不同模态到语言空间的映射:为每个编码器 φ : O → X φ : \mathcal{O} → \mathcal{X} φ:O→X 提出了不同的架构选择,以便将相应的模态映射到语言嵌入空间。
- 状态估计向量(state estimation vectors)
- 用于二维图像特征的Vision Transformers (ViTs):
- An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale, 2020
- Chen 等人(2022 年)提出的 40 亿参数模型 ViT-4B:Pali: A jointly-scaled multilingual language-image model, 2022
- 以及类似的 220 亿参数模型 ViT22B,这两种模型都在图像分类方面进行了预训练:Scaling Vision Transformers to 22 Billion Parameters, 2023
- 我们进一步研究了从头开始端到端训练的 ViT 标记学习器(ViT token learner,ViT + TL)架构:TokenLearner: What Can 8 Learned Tokens Do for Images and Videos? 2021
- 三维感知目标场景表示Transformer(OSRT):
- OSRT(Object Scene Representation Transformer, 2022)是一种不需要真实标签(ground-truth)分割的替代方法:它不依赖关于目标的外部知识,而是通过架构中的归纳偏差以无监督的方式发现目标。
- 基于 SRT(Scene Representation Transformer: Geometry-Free Novel View Synthesis Through Set-Latent Scene Representations,2022b),OSRT 通过新颖的视图合成任务(view synthesis task),在域内数据上学习以三维为中心的神经场景表征。
2‘ 实体参考(Entity Referrals)
在很多情况下,包括我们的大部分实验,场景中的目标都可以通过自然语言的一些独特属性识别出来。但是,也有一些场景中的目标不容易用几个词就能用语言识别出来,例如,如果桌子上有多个颜色相同、位置不同的积木块。对于以目标为中心的表征(如 OSRT),我们会对输入提示中与目标相对应的多模态标记(tokens)进行如下标注:Object 1 is <obj_1>... Object j is <obj_j>。这样,PaLM-E 就能在生成的输出句子中通过 obj_1 形式的特殊标记来引用对象。
实验设计
PaLM-E 大多数架构都由三部分组成:编码器 φ ~ \tilde{φ} φ~,投影器 ψ ψ ψ 和 LLM p L M p_{LM} pLM。
考虑了三种不同机器人的各种机器人(移动)操纵任务,包括仿真机器人和两个不同的真实机器人。探讨了不同输入表示法的性能、泛化和数据效率。
三个机器人环境(图 1):机器人必须操纵(抓取(grasp)和堆叠(stack))物体的
-
任务和动作规划域(Task and Motion Planning domain,TAMP)
-
桌面操作环境(table-top pushing environment)
-
移动操作域(mobile manipulation domain)
模型基线
- 最先进的视觉语言模型 PaLI(PaLI: A Jointly-Scaled Multilingual Language-Image Model,2022):该模型未在体现机器人数据上进行过训练
- SayCan 算法(Do As I Can, Not As I Say: Grounding Language in Robotic Affordances,2022 年):该算法提供了 oracle affordances(功能可用性)。
实验结果
表 7 中的 state 表示状态估计的编码器。本文中使用的是一个 MLP。
表 7 中的 state(w/o entity referrals) 表示状态估计的编码器,但不使用 Entity Referral 技术。
对于场景中的 3-5 个物体(与训练集中的物体数量相同),大多数输入表征的表现都差不多。然而,当目标数量增加时,使用预先训练好的 LLM 会大大提高性能,尤其是在实体推荐(entity referrals)方面。SayCan 使用的是 oracle affordance functions,在解决这种环境问题时遇到了困难,因为功能可用性函数只能限制当前可能发生的事情,但信息量不足以让 LLM 在 TAMP 环境中构建长期计划。
如果我们对所有其他机器人环境以及通用视觉语言数据集(ViT-4B 通用型)进行联合训练,那么 ViT-4B 的性能就会提高一倍以上。这表明,不同机器人环境和任务之间存在明显的迁移效应。最后,使用 OSRT 作为输入表示法可以获得最佳性能,这证明了三维感知物体表示法的优势。
对互联网尺度的视觉和语言进行联合训练,能为机器人规划提供更有效的模型,尤其是在每个任务只有 10 个演示的小样本情况下。
开放讨论
在多模态训练过程中保留模型语言能力的两种途径。其中
- 一种方法是冻结 LLM,只训练输入编码器,这是建立具身语言模型的可行途径,尽管这种方法在机器人任务中偶尔会遇到困难(表 2)。
- 另一种方法是对整个模型进行端到端训练,随着模型规模的扩大,模型的原始语言性能会得到显著提高(图 6)。
Abstract
大型语言模型(LLMs)已被证明可以执行复杂的任务。然而,要在现实世界中实现通用推理(general inference),例如解决机器人问题,就需要解决基础问题(challenge of grounding)。我们提出了具身语言模型(embodied language models),将真实世界的连续的传感器模态直接纳入语言模型,从而建立词语与感知之间的联系。我们的具身语言模型的输入是多模态句子,这些句子交错了视觉、连续状态估计和文本输入编码。我们结合预先训练好的大型语言模型,对这些编码进行端到端训练,以完成多个具身任务(embodied tasks),包括顺序机器人操作规划(sequential robotic manipulation planning,)、视觉问题解答和描述(captioning)。我们的评估结果表明,PaLM-E 作为一个单一的大型多模态模型,可以在多个模态上通过多种观察模态(observation modalities)完成各种模态推理任务,而且还表现出积极的迁移性:该模型受益于跨互联网规模语言、视觉和视觉语言领域的不同联合训练。我们最大的模型 PaLM-E-562B 有 562B 个参数,除了在机器人任务上接受过训练外,还是一个视觉语言通才(visual-language generalist),在 OK-VQA 上的表现达到了最先进水平,并且随着规模的扩大还能保持通才语言能力。
1. Introduction

大型语言模型(LLMs)在各个领域都表现出强大的推理能力,包括对话(Glaese等人,2022年;Thoppilan等人,2022年)、逐步推理(Wei等人,2022年;Kojima等人,2022年)、数学问题求解(Lewkowycz等人,2022年;Polu等人,2022年)和代码编写(Chen等人,2021年a)。然而,这类模型在现实世界中推理的局限性在于基础(grounded)问题:虽然在海量文本数据上训练 LLM 可能会产生与我们的物理世界相关的表征,但将这些表征与现实世界中的视觉和物理传感器模态连接起来,对于解决计算机视觉和机器人学中更广泛的基础现实世界问题至关重要 (Tellex et al., 2020)。以前的工作 (Ahn et al., 2022) 将 LLM 的输出与学习到的机器人策略(robotic policies)和功能可用性函数(affordance functions)连接起来以做出决策,但其局限性在于 LLM 本身只提供文本输入,这对于许多场景的几何配置非常重要的任务来说是不够的。此外,在我们的实验中,我们发现目前最先进的视觉语言模型是在典型的视觉语言任务(如视觉问题解答(VQA))中训练出来的,无法直接解决机器人推理任务。
在本文中,我们提出了具身语言模型(embodied language models),该模型直接纳入了来自具身智能体(embodied agent)的传感器模态的连续输入,从而使语言模型本身能够在现实世界中为顺序决策做出更有依据的推断。图像和状态估计等输入信息被嵌入到与语言标记相同的潜在嵌入中,并由基于Transformer的 LLM 的自注意力层以与文本相同的方式进行处理。我们从预先训练好的 LLM 开始,通过编码器注入连续输入。这些编码器经过端到端训练,以自然文本的形式输出连续的决策,而这些文本可以通过调节低层次策略的方式由具身智能体(embodied agent)进行解释,或者给出具身问题的答案。我们在各种环境中对该方法进行了评估,比较了不同的输入表示(例如,针对视觉输入的标准 ViT 编码与以目标为中心的 ViT 编码),在训练编码器时冻结语言模型与微调语言模型,并研究了在多个任务上进行联合训练是否能实现迁移。
为了研究该方法的广度,我们对三个机器人操纵领域(其中两个在现实世界中是闭环的),标准视觉语言任务(如 VQA 和图像描述)以及语言任务进行了评估。我们的研究结果表明,与在单个任务中训练模型相比,多任务训练能提高性能。我们的研究表明,这种任务间的迁移(transfer)可以为机器人任务带来很高的数据效率,例如,可以显著提高从少量训练示例中学习的成功率,甚至可以对新的目标组合或未见过的目标进行单样本或零样本泛化。
我们将 PaLM-E 扩展到 562B 参数,整合了 540B PaLM(Chowdhery 等人,2022 年)LLM 和 22B Vision Transformer (ViT)(Dehghani 等人,2023 年),据我们所知,这是目前报道的最大的视觉语言模型。PaLM-E-562B 在 OK-VQA (Marino et al., 2019) 基准测试中取得了最先进的性能,而无需依赖特定任务的微调。尽管不是我们实验的重点,但我们也发现(图 2),PaLM-E-562B 表现出了广泛的能力,包括零样本多模态思维链(CoT)推理、小样本提示、无 OCR 数学推理和多图像推理,尽管它只在单图像示例上进行了训练。零样本 CoT (Kojima et al., 2022), 最初只是一个语言概念,现在已经通过特定任务程序在多模态数据上得到了展示 (Zeng et al., 2022),但据我们所知,它并不是通过端到端模型实现的。
概括我们的主要贡献,
- 1)我们提出并证明了可以通过在多模态大型语言模型的训练中混合具身数据来训练通用的、迁移学习的、多具身决策智能体(multi-embodiment decision-making agent)。
- 2)我们证明虽然目前最先进的通用视觉语言模型开箱即用(zero-shot)并不能很好地解决具身推理问题,但我们可以训练出同时也是高效具身推理器的通用视觉语言模型。
- 3)在研究如何以最佳方式训练此类模型时,我们引入了新颖的架构理念,如神经场景表征(neural scene representations)和实体标签多模态标记(entity-labeling multimodal tokens)。
- 4)最后,除了关注 PaLM-E 作为一种具身推理器(embodied reasoner)之外,我们还证明了 PaLM-E 也是一种具有定量能力的视觉和语言通才。
- 5)证明了语言模型大小的缩放可实现多模态微调,减少灾难性遗忘(catastrophic forgetting)。
2. Related Work
General vision-language modeling。在大型语言模型(Brown 等人,2020 年;Devlin 等人,2018 年)和视觉模型(Dosovitskiy 等人,2020 年)取得成功的基础上,近年来人们对大型视觉语言模型(VLMs)的兴趣与日俱增 (Li et al., 2019; Lu et al., 2019; Hao et al., 2022; Gan et al., 2022)。与前者不同,VLMs 能够同时理解图像和文本,可应用于视觉问题解答(Zhou 等,2020;Zellers 等,2021b)、图像描述(Hu 等,2022)、光学字符识别(Li 等,2021)和物体检测(Chen 等,2021b)等任务。整合图像的方法各不相同。例如,Alayrac 等人(2022)通过一种直接关注单个上下文图像的机制来增强预训练语言模型。相比之下,PaLM-E 将图像和文本表示为潜在向量的 “多模态句子”,从而可以在句子的任何部分灵活处理多个图像。与我们的研究更密切相关的是 Frozen (Tsimpoukelli et al., 2021),该研究通过冻结 LLM 的反向传播来优化视觉编码器参数 (Lu et al., 2021)。在这项工作的启发下,我们通过引入其他输入模式(如神经场景表示(neural scene representations)),在更广的范围内研究了这一设计,在 VQAv2 基准测试中,我们提出的方法比 Frozen 优胜 45% 以上。更重要的是,我们证明了 PaLM-E 不仅适用于感知任务,也适用于具身任务(embodied tasks)。
Actions-output models。之前的研究主要集中在将视觉和语言输入结合在一起,以实现直接行动预测的目标 (Guhur et al., 2022; Shridhar et al., 2022b;a; Zhang & Chai, 2021; Silva et al., 2021; Jang et al., 2022; Nair et al., 2022; Lynch et al., 2022; Brohan et al., 2022)。在这些方法中,VIMA (Jiang et al., 2022) 探索了与 PaLM-E 类似的多模态提示。在这些研究中,语言的作用被描述为任务规范(task specification)可能最为恰当。相比之下,PaLM-E 以文本形式生成高级指令;这样一来,模型就能自然而然地以自身预测为条件,并直接利用其参数中蕴含的世界知识。正如我们的实验所证明的那样,这不仅能实现具身推理(embodied reasoning),还能实现问题解答(question answering)。在输出行动的工作中,最相似的可能是 Gato (Reed et al., 2022) 中提出的方法,它与 PaLM-E 一样,都是通用的多具身代理(generalist multi-embodiment agent)。与 Gato 不同的是,我们展示了不同任务间的正迁移(positive transfer),模型受益于跨领域的多样化联合训练。
LLMs in embodied task planning。已有多种方法被提出来用于在具身领域利用 LLMs。虽然许多研究都侧重于理解自然语言目标(Lynch & Sermanet, 2020; Shridhar et al., 2022a; Nair et al., 2022; Lynch et al., 2022),但将自然语言作为规划(planning)表征的研究较少,而这正是本研究的重点。LLMs 包含大量关于世界的内化知识 (Bommasani et al., 2021),但如果没有基础(grounding),生成的计划可能无法执行。一种研究方法是利用提示,直接从 LLM 中引出一系列指令,具体方法包括
- 利用 LLM 生成的指令与符合条件的指令集之间的语义相似性:Language Models as Zero-Shot Planners: Extracting Actionable Knowledge for Embodied Agents (2022b)
- 功能可用性函数(affordance functions):Do As I Can, Not As I Say: Grounding Language in Robotic Affordances (2022)
- 视觉反馈(visual feedback):Inner Monologue: Embodied Reasoning through Planning with Language Models (2022)
- 生成世界模型(generating world models):
- Do embodied agents dream of pixelated sheep?: Embodied decision making using language guided world modelling (2023)
- PIGLeT: Language Grounding Through Neuro-Symbolic Interaction in a 3D World (2021)
- 通过图形和地图进行规划:
- LM-Nav: Robotic Navigation with Large Pre-Trained Models of Language, Vision, and Action (2022)
- Visual Language Maps for Robot Navigation (2022)
- 视觉解释:Describe, Explain, Plan and Select: Interactive Planning with Large Language Models Enables Open-World Multi-Task Agents (2023)
- 程序生成:
- Code as Policies: Language Model Programs for Embodied Control (2022)
- ProgPrompt: Generating Situated Robot Task Plans using Large Language Models (2022)
- 向提示注入信息(injecting information into the prompt):Socratic Models: Composing Zero-Shot Multimodal Reasoning with Language (2022)
相比之下,PaLM-E 经过训练后可直接生成计划,而无需依赖辅助模型作为基础(grounding)。这反过来又能将预训练 LLM 中存储的丰富语义知识直接整合到规划流程中。
除少数例外情况外,许多这些研究中使用的 LLM 参数都是按原样使用,无需进一步训练。
- 在 LID (Li et al., 2022) 中,这一限制被放宽,LLM 参数被微调,以生成用于生成高级指令(instructions)的规划网络。
- Skill Induction and Planning with Latent Language (2021) 解决了同时对两个 LLM 进行微调这一更具挑战性的任务:一个是生成高级指令的规划网络,另一个是选择行动的低级策略网络。
对于 PaLM-E,我们的兴趣既不同又互补:我们研究的是一种通用的、跨多种模态的多具身模型。
3. PaLM-E: An Embodied Multimodal Language Model
PaLM-E 的主要架构思想是将连续、具体的观察结果(如图像、状态估计或其他传感器模态)注入预训练语言模型的语言嵌入空间(language embedding space)。具体做法是将连续观察结果编码成一串向量,其维度与语言标记的嵌入空间相同。因此,连续信息将以类似于语言标记的方式注入语言模型。PaLM-E 是一种仅用于解码器的 LLM,它能根据前缀(prefix)或提示(prompt)自回归地生成文本补全。我们称自己的模型为 PaLM-E,因为我们使用 PaLM (Chowdhery et al., 2022) 作为预训练语言模型,并将其应用于具身(Embodied)任务。
PaLM-E 的输入由文本和(多个)连续观察结果组成。与这些观察结果相对应的多模态标记与文本交错在一起,形成多模态句子(multi-modal sentences)。这种多模态句子的一个例子是:Q: What happened between <img 1> and <img 2>? 其中 <img i> 表示图像的嵌入。PaLM-E 的输出是由模型自动递归生成的文本,可以是问题的答案,也可以是 PaLM-E 以文本形式生成的、应由机器人执行的决策序列。当PaLM-E受命生成决策或计划时,我们假设存在一个低层次的策略或计划器,可以将这些决策转化为低层次的行动。先前的工作已经讨论了训练这种低级策略的各种方法(Lynch & Sermanet, 2020; Brohan et al.)。下面,我们将更正式地介绍我们的方法。
Decoder-only LLMs.
纯解码器大语言模型(LLM)是一种生成模型,其训练目的是预测一段文本 w1:L = (w1, … , wL) 的概率 p(w1:L),该文本由 wi ∈ W 标记序列(sequence of tokens)表示:
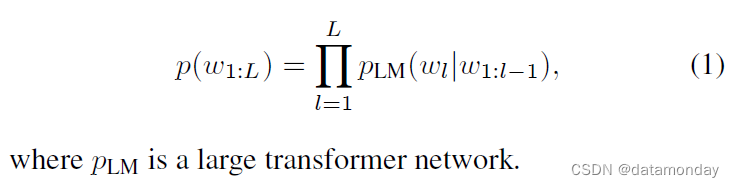
Prefix-decoder-only LLMs.
由于 LLM 是自回归模型,预训练模型可以以前缀 w1:n 为条件,而无需改变结构
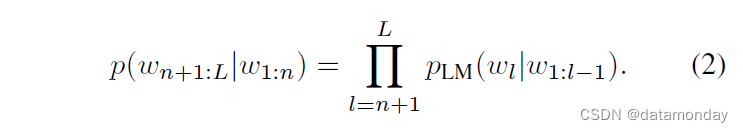
前缀或提示 w1:n 为 LLM 继续预测后续标记 wn+1:L 提供了上下文。这通常用于推理,以引导模型的预测。例如,提示可以包含对 LLM 应解决的任务的描述,或类似任务的所需文本补全示例。
Token embedding space.
标记 wi 是固定词汇(fixed vocabulary) W 的元素,词汇 W 是一个离散的有限集合,它对应于自然语言中的(子)词。在内部,LLM 通过 γ : W → X 将 wi 嵌入一个词标记嵌入空间 X ⊂ Rk,即 pLM(wl|x1:l-1),xi = γ(wi) ∈ Rk。映射 γ 通常表示为大小为 k × |W| 的大型嵌入矩阵,并进行端到端训练。在我们的例子中,|W| = 256 000(Chowdhery et al.)
Multi-modal sentences: injection of continuous observations.
通过跳过离散标记层(discrete token level),直接将连续观察结果映射到语言嵌入空间 X,可以将图像观察结果等多模态信息注入 LLM。为此,我们会训练一个编码器 φ : O → X q φ : O → \mathcal{X}^q φ:O→Xq,将(连续)观测空间 O(详见第 4 章)映射到 X 中的 q 多向量序列。然后,这些向量与正常嵌入的文本标记交错(interleaved),形成 LLM 的前缀。这意味着前缀中的每个向量 xi 都是由单词标记嵌入器(word token embedder) γ 或编码器 φi 形成的:

请注意,一个观测值 Oj 通常会被编码成多个嵌入向量。可以在前缀的不同位置交错使用不同的编码器 φi,以组合来自不同观测空间的信息等。以这种方式将连续信息注入 LLM,可以重复使用其现有的位置编码。与其他 VLM 方法(PaLI: A Jointly-Scaled Multilingual Language-Image Model, 2022)不同的是,观察嵌入不是插入固定位置,而是动态地放置在周围文本中。
Embodying the output: PaLM-E in a robot control loop.
PaLM-E 是一个生成模型,以多模态句子为输入,生成文本。为了将该模型的输出与体现联系起来,我们区分了两种情况。如果任务只需输出文本即可完成,例如在具身问答(embodied question answering)或场景描述任务中,那么模型的输出就直接被视为任务的解决方案。
另外,如果 PaLM-E 被用来解决一个具体化的规划或控制任务,它就会生成为低级命令(command)创造条件的文本。特别是,我们假设可以从一些(少量)词汇中获取可执行低级技能的策略,而 PaLM-E 的成功计划必须由一系列此类技能组成。请注意,PaLM-E 必须根据训练数据和提示自行决定哪些技能是可用的,而不会使用其他机制来限制或过滤其输出。虽然这些策略是以语言为条件的,但它们并不能解决长期任务或接收复杂指令。因此,PaLM-E 被集成到一个控制环(control-loop)中,机器人通过低级策略执行其预测决策,从而产生新的观察结果,PaLM-E 能够根据这些观察结果在必要时重新规划。从这个意义上说,PaLM-E 可以被理解为一种高级策略,对低级策略进行排序和控制。
4. Input & Scene Representations for Different Sensor Modalities
在本节中,我们将介绍纳入 PaLM-E 的各种模态,以及如何设置编码器。我们为每个编码器 φ : O → X φ : \mathcal{O} → \mathcal{X} φ:O→X 提出了不同的架构选择,以便将相应的模态映射到语言嵌入空间。我们研究了
- 状态估计向量(state estimation vectors)
- 用于二维图像特征的Vision Transformers (ViTs):
- An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale, 2020
- PaLI: A Jointly-Scaled Multilingual Language-Image Model, 2022
- TokenLearner: What Can 8 Learned Tokens Do for Images and Videos?, 2021
- 三维感知目标场景表示Transformer(OSRT):Object Scene Representation Transformer, 2022
除了全局表示输入场景的编码器外,我们还考虑了以目标为中心的表示法(object-centric representations),这种表示法能将观测结果分解为代表场景中单个目标的标记。
State estimation vectors.
状态向量,例如来自机器人或物体的状态估计,也许是最简单的 PaLM-E 输入。让 s ∈ RS 成为描述场景中物体状态的向量。例如,s 可以包含这些物体的姿态、大小、颜色等。然后,MLPφstate 将 s 映射到语言嵌入空间。
Vision Transformer (ViT).
ViT φ ~ V i T \tilde{φ}_{ViT} φ~ViT (Dosovitskiy et al., 2020) 是一种 Transformer 架构,它将图像 I I I 映射到若干标记嵌入(token embedding) x ~ 1 : m = φ ~ V i T ( I ) ∈ R m × k ~ \tilde{x}_{1:m} = \tilde{φ}_{ViT}(I) ∈ \mathbb{R}^{m× \tilde{k}} x~1:m=φ~ViT(I)∈Rm×k~ 。我们考虑了几种变体,包括
- Chen 等人(2022 年)提出的 40 亿参数模型 ViT-4B:Pali: A jointly-scaled multilingual language-image model, 2022
- 以及类似的 220 亿参数模型 ViT22B,这两种模型都在图像分类方面进行了预训练:Scaling Vision Transformers to 22 Billion Parameters, 2023
- 我们进一步研究了从头开始端到端训练的 ViT 标记学习器(ViT token learner,ViT + TL)架构:TokenLearner: What Can 8 Learned Tokens Do for Images and Videos? 2021
请注意,ViT 嵌入的维度 k ~ \tilde{k} k~ 不一定与语言模型的维度相同。因此,我们将每个嵌入投影到 x i = φ V i T ( I ) i = ψ ( φ ~ V i T ( I ) i ) x_i = φ_{ViT}(I)_i = ψ( \tilde{φ}_ViT(I)_i) xi=φViT(I)i=ψ(φ~ViT(I)i) 中,其中 ψ ψ ψ 是学习到的仿射变换(affine transformation)。
Object-centric representations.
与语言不同,视觉输入并不是预先结构化为有意义的实体和关系:虽然 ViT 可以捕捉语义,但其表示结构类似于静态网格,而不是目标实例(object instances)的集合。这对与预先训练过符号的 LLM 接口,以及解决需要与物理目标(physical objects)互动的具身推理(embodied reasoning)都提出了挑战。因此,我们还探索了结构化编码器(structured encoders),其目的是在将视觉输入注入 LLM 之前将其分离为不同的对象。给定真实标签的目标实例掩码(ground-truth object instance masks) Mj,我们可以将 ViT 的表示分解为目标 j 的 x 1 : m j = φ V i T ( M j ◦ I ) x^j_{1:m} = φ_{ViT}(M_j ◦ I) x1:mj=φViT(Mj◦I)。
Object Scene Representation Transformer (OSRT).
OSRT(Object Scene Representation Transformer,2022a)是一种不需要真实标签(ground-truth)分割的替代方法:它不依赖关于目标的外部知识,而是通过架构中的归纳偏差以无监督的方式发现目标(Object-Centric Learning with Slot Attention,2020)。基于 SRT(Scene Representation Transformer: Geometry-Free Novel View Synthesis Through Set-Latent Scene Representations,2022b),OSRT 通过新颖的视图合成任务(view synthesis task),在域内数据上学习以三维为中心的神经场景表征。其场景表征由目标槽(object slots)$o_j = \bar{φ}{OSRT}(I{1:v})j ∈ \mathbb{R} ^{\bar{k}} $ 组成。我们用 MLP ψ ψ ψ 将每个槽(slot)投影到 x 1 : m j = ψ ( φ ˉ O S R T ( I 1 : v ) j ) x^j_{1:m} = ψ( \bar{φ}_{OSRT}(I_{1:v})_j) x1:mj=ψ(φˉOSRT(I1:v)j) 中。需要注意的是,单个目标总是被标记为多个嵌入,即 OSRT 的 ψ : R k ˉ → R m × k ψ : \mathbb{R}^{\bar{k}} → \mathbb{R}^{m×k} ψ:Rkˉ→Rm×k 映射为多个嵌入(m-many embeddings)。
Entity referrals.
对于具身规划任务(embodied planning tasks),PaLM-E 必须能够在其生成的规划中引用目标。在很多情况下,包括我们的大部分实验,场景中的目标都可以通过自然语言的一些独特属性识别出来。但是,也有一些场景中的目标不容易用几个词就能用语言识别出来,例如,如果桌子上有多个颜色相同、位置不同的积木块。对于以目标为中心的表征(如 OSRT),我们会对输入提示中与目标相对应的多模态标记(tokens)进行如下标注:Object 1 is <obj_1>... Object j is <obj_j>。这样,PaLM-E 就能在生成的输出句子中通过 obj_1 形式的特殊标记来引用对象。在这种情况下,我们假设底层策略(low-level policies)也对这些标记进行操作。
5. Training Recipes
PaLM-E 在 D = ( I 1 : u i i , w 1 : L i i , n i ) i = 1 N D ={(I^i_{1:u_i}, w^i_{1:L_i}, n_i)}^N_{i=1} D=(I1:uii,w1:Lii,ni)i=1N 形式的数据集上进行训练,其中每个示例 i 由 u i u_i ui-many 连续观测值 I j i I^i_j Iji,文本 w 1 : L i i w^i_{1:L_i} w1:Lii 和索引 n i n_i ni 组成。尽管这是一个纯解码器模型,但文本包括由多模态句子构成的索引 ni 之前的前缀部分,以及仅包含文本标记的预测目标。因此,损失函数是在单个非前缀标记(non-prefix tokens) w n i + 1 : L i i w^i_{ {n_i}+1:L_i} wni+1:Lii 的平均交叉熵损失。为了在模型中形成多模态句子,我们在文本中加入了一些特殊的标记,这些标记会被文本中这些标记所在位置的编码器嵌入向量所替代。我们将 PaLM-E 建立在经过预训练的 PaLM 8B、62B 和 540B 参数变体的基础上,将其作为仅用于解码器的 LLM,并通过输入编码器向其中注入连续观察结果。这些编码器要么是预训练的,要么是从头开始训练的,见第 4 章。我们将
- 8B LLM 与 4B ViT 结合称为 PaLM-E12B
- 62B LLM + 22B ViT 称为 PaLM-E-84B
- 540B LLM + 22B ViT 称为 PaLM-E-562B
Variation with Model freezing.
我们的大多数架构都由三部分组成:编码器 φ ~ \tilde{φ} φ~,投影器 ψ ψ ψ 和 LLM p L M p_{LM} pLM。在训练 PaLM-E 时,一种方法是更新所有这些部分的参数。然而,如果有适当的提示,LLMs 会显示出令人印象深刻的推理能力(Chain of Thought Prompting Elicits Reasoning in Large Language Models,2022 年)。因此,我们研究了是否有可能冻结 LLM 并只训练输入编码器,如果有可能,不同模态编码器的比较情况如何。在这种情况下,编码器必须生成嵌入向量,使被冻结的 LLM 以观察结果为基础,同时向 LLM 传播关于具身(embodiment)能力的信息。与普通软提示(The Power of Scale for Parameter-Efficient Prompt Tuning,2021 年)相比,这种编码训练可以理解为一种输入条件软提示(Multimodal Few-Shot Learning with Frozen Language Models,2021 年)。在使用 φOSRT 的实验中,我们也冻结了槽表征,即只更新作为 OSRT 与 LLM 接口的小投影器 ψ。
Co-training across tasks.
在实验中,我们研究了在各种不同数据上对模型进行联合训练的效果。“full mixture”,见附录 A,主要由来自不同任务的各种互联网规模的视觉和语言数据组成。采样频率的设置使得full mixture 中只有 8.9% 是具身数据,而且每个具身数据都有多个任务。
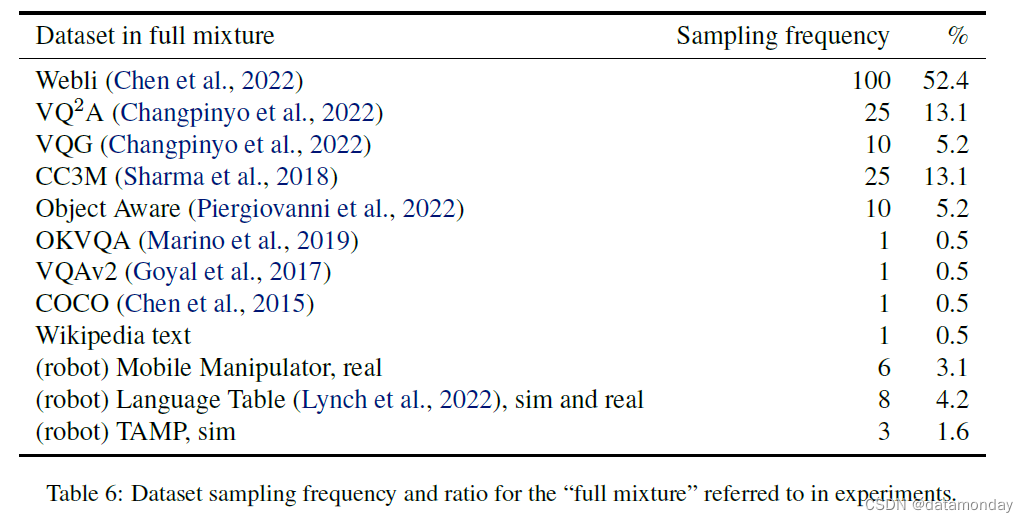
6. Experiments
我们的实验考虑了三种不同机器人的各种机器人(移动)操纵任务,包括仿真机器人和两个不同的真实机器人。有关 PaLM-E 在这些任务中的能力展示视频,请参阅 https://palm-e.github.io。虽然这不是我们工作的重点,但我们也评估了 PaLM-E 在一般视觉语言任务中的表现,如视觉问题解答 (VQA)、图像描述和语言建模任务。
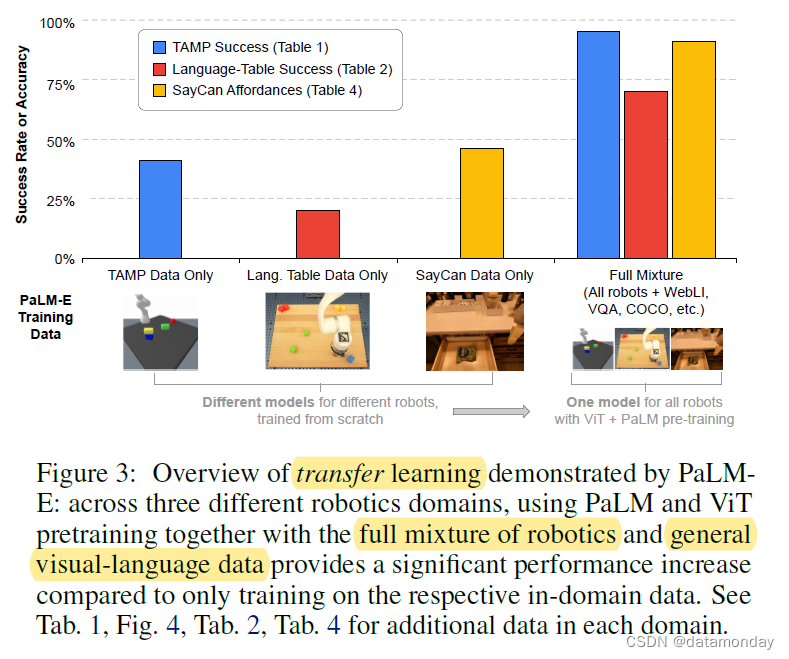
我们将实验研究分为两大类。首先,我们比较了第 4 章中的不同输入表示法的性能、泛化和数据效率。第二类实验主要针对一种架构,即主要的 PaLM-E 版本,它由预先训练好的 ViT 和 PaLM 语言模型组成,以原始图像作为连续输入。在这里,我们展示了一个单一的模型,该模型是在多种任务和不同机器人的混合数据集上训练的,可以同时在所有这些任务中实现高性能。最重要的是,我们还研究了在这些数据集上进行联合训练是否能实现迁移(图 3):尽管任务和机器人各不相同,但通过在混合任务上进行训练,单个任务的性能会有所提高。我们研究了协同训练策略和模型参数大小对性能、泛化和数据效率的影响。最后,我们还考虑了冻结 LLM 并只训练将视觉注入 LLM 的 ViT 是否可行的问题。
作为基线,我们考虑了
- 最先进的视觉语言模型 PaLI(PaLI: A Jointly-Scaled Multilingual Language-Image Model,2022):该模型未在体现机器人数据上进行过训练
- SayCan 算法(Do As I Can, Not As I Say: Grounding Language in Robotic Affordances,2022 年):该算法提供了 oracle affordances(功能可用性)。
6.1. Robot Environments / Tasks

我们的三个机器人环境(图 1)包括
- 机器人必须操纵(抓取(grasp)和堆叠(stack))物体的任务和动作规划域(Task and Motion Planning(TAMP)domain)
- 桌面操作环境(table-top pushing environment)
- 移动操作域(mobile manipulation domain)
在每个领域中,PaLM-E 都是根据该领域的专家数据进行训练的。在许多情况下,每个任务的数据量都很稀少。TAMP 任务涉及大量可能计划的组合,许多决策序列是不可行的。PaLM-E 必须生成由多个步骤组成、具有复杂决策边界的计划。多目标桌面推演环境(multi-object tabletop pushing environment)取自公开的 Language-Table 数据集(Interactive Language: Talking to Robots in Real Time,2022),具有挑战性,因为它包括多个对象、大量语言和复杂的推演动态。对于 TAMP 和语言表(Language-Table)环境,PaLM-E 都必须对物体的姿态进行推理。仅仅知道桌子上有哪些物体或知道它们之间的大致关系是不够的,有关场景几何的更细粒度的细节对于解决任务非常重要。最后,我们考虑了一个与 SayCan(2022)类似的移动操纵领域,在该领域中,机器人必须在厨房环境中完成各种任务,包括寻找抽屉中的物品、拾取物品并将其交给人类。对于所有领域,我们都考虑了这些环境中的规划和 VQA 任务。对于移动操作和语言表环境,PaLM-E 被集成到控制环中,以便在真实世界中执行计划,并在出现外部干扰或底层控制策略失效时调整计划。
6.2. TAMP Environment
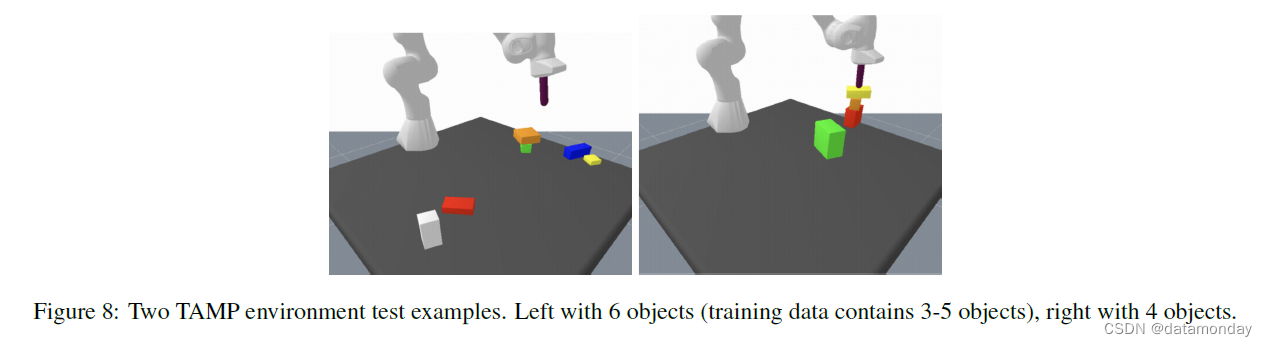
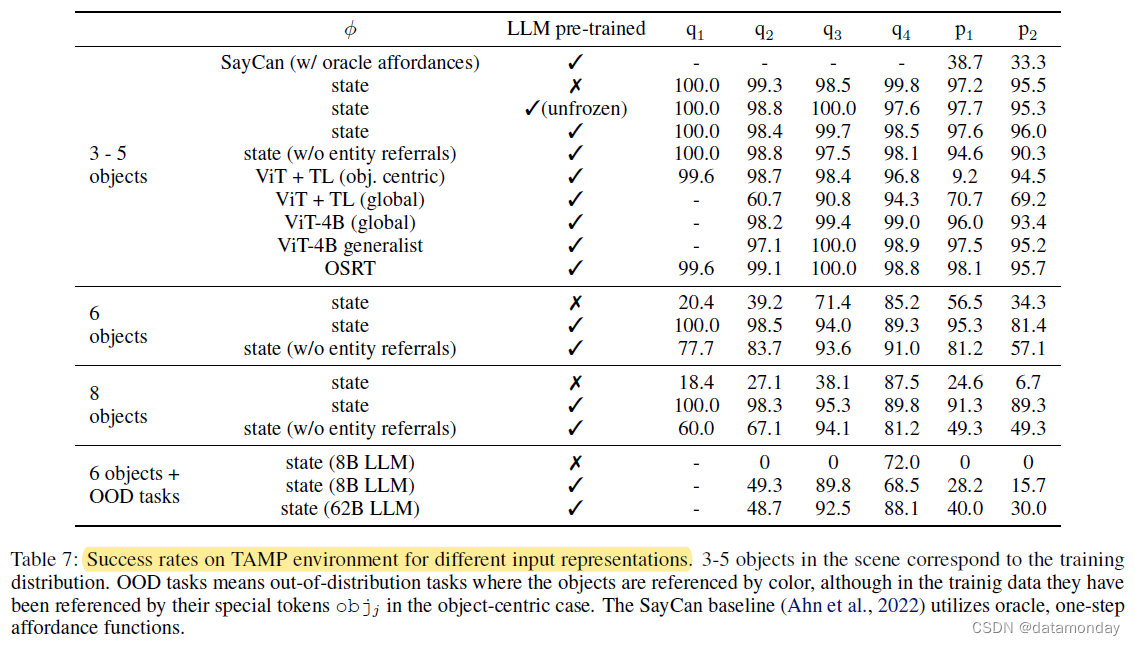
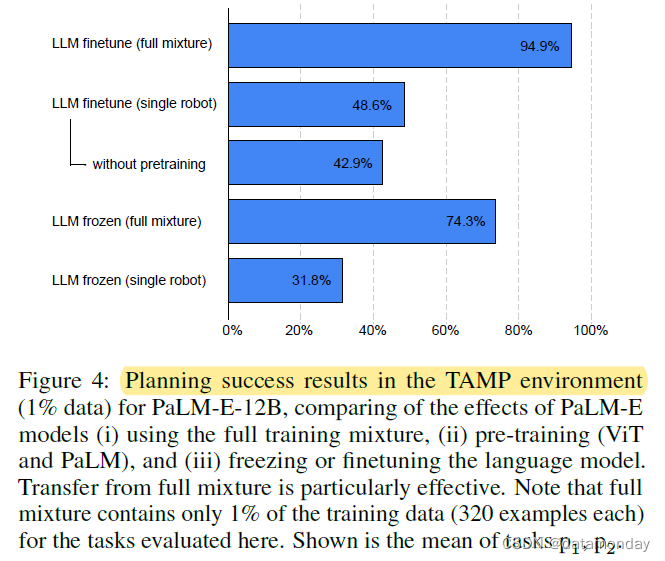
表 7(附录)显示了 TAMP 环境下的规划成功率和 VQA 性能。表 7(附录)显示了 TAMP 环境下的规划成功率和 VQA 性能。在这些实验中,LLM 被冻结(预训练 LLM)。对于表 7 中报告的结果,输入表征是经过训练的。在表 7 中报告的结果中,输入表征是在包含 96,000 个 TAMP 环境训练场景的数据集上进行训练的,即混合物中没有其他数据。对于场景中的 3-5 个物体(与训练集中的物体数量相同),大多数输入表征的表现都差不多。然而,当目标数量增加时,使用预先训练好的 LLM 会大大提高性能,尤其是在实体参考(entity referrals)方面。此外,我们还发现,与 8B 变体相比,62B LLM 的分布外泛化效果更好,而未经预训练的 LLM 则基本上没有分布外泛化效果。SayCan 使用的是 oracle affordance functions(功能可用性函数),在解决这种环境问题时遇到了困难,因为功能可用性函数只能限制当前可能发生的事情,但信息量不足以让 LLM 在 TAMP 环境中构建长期计划。
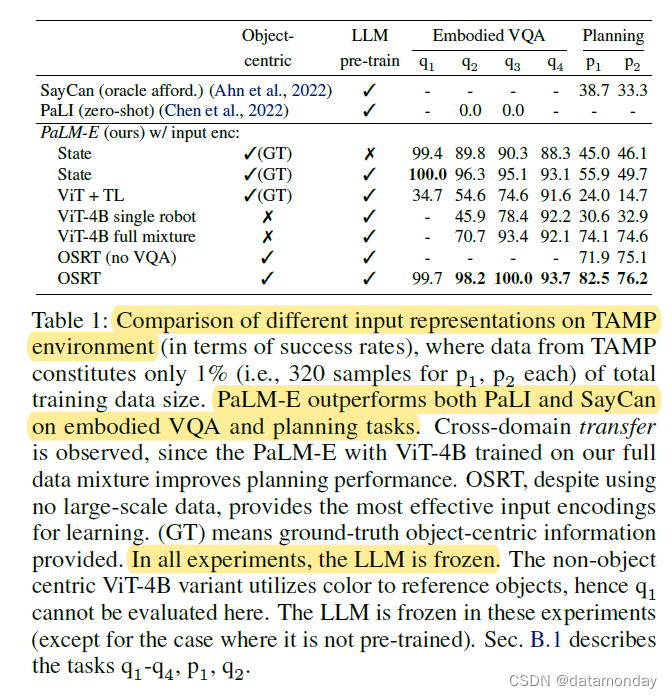
表 1 显示了在对 1% 的数据集进行训练时,3-5 个目标的结果,这相当于两个规划任务各只有 320 个示例。在这里,我们可以看到输入表征之间存在显著差异,尤其是在规划任务中。首先,预训练 LLM 有利于状态输入的低数据机制。其次,ViT 的两个变体(ViT+TL、ViT-4B)在解决数据量较少的规划任务时表现都不好。但是,如果我们对所有其他机器人环境以及通用视觉语言数据集(ViT-4B 通用型)进行联合训练,那么 ViT-4B 的性能就会提高一倍以上。这表明,不同机器人环境和任务之间存在明显的迁移效应。最后,使用 OSRT 作为输入表示法可以获得最佳性能,这证明了三维感知物体表示法的优势。我们还观察到另一个迁移实例:当我们移除 TAMP VQA 数据,只对 640 个规划任务示例进行训练时,性能会出现(轻微)下降。在机器人数据上训练的最先进的视觉语言模型 PaLI (Chen et al., 2022) 无法解决任务。我们只在 q2(桌面上左/右/中的物体)和 q3(垂直物体关系)上对其进行了评估,因为这些任务与典型的 VQA 任务最为相似。
In the global version, we consider the following three VQA tasks:

as well as the two planning tasks

6.3. Language-Table Environment

表 2 报告了语言表环境(Interactive Language: Talking to Robots in Real Time,2022 年)长期任务(long-horizon tasks)的成功率。PaLM-E 被集成到一个控制回路中,该回路将长期任务和当前图像作为输入,并输出底层策略指令。我们发现,对互联网尺度的视觉和语言进行联合训练,能为机器人规划提供更有效的模型,尤其是在每个任务只有 10 个演示的小样本情况下。将 12B 模型扩展到 84B 模型后,3 项任务中的 2 项都有所改进。与 TAMP 环境一样,SayCan 和零样本 PaLI 均无效,无法解决测试中最简单的任务。
Real Robot Results and Few-Shot Generalization.
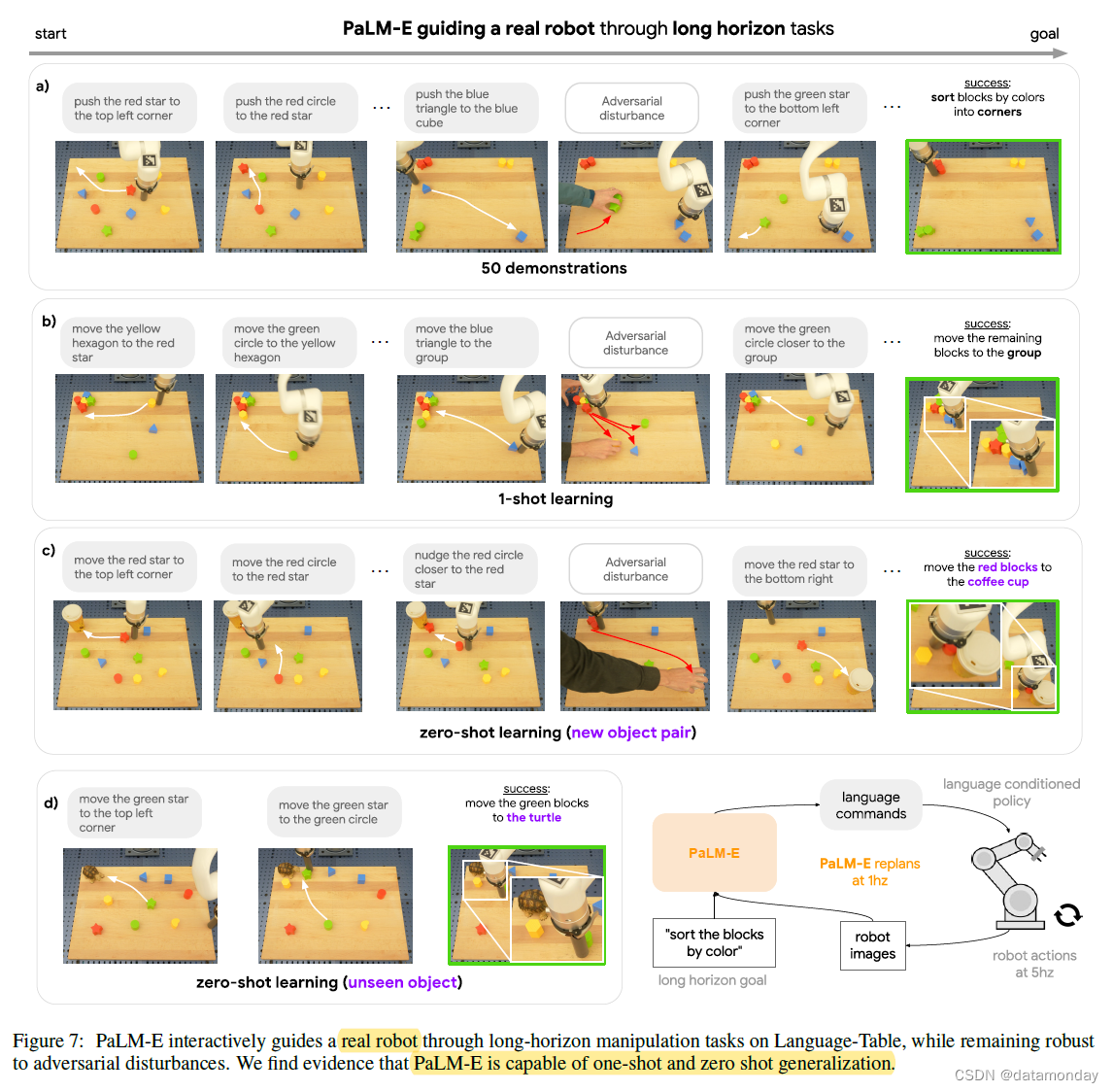
在图 7 a)中,我们看到 PaLM-E 能够引导真实机器人完成多阶段桌面操作任务,同时对对抗性干扰(adversarial disturbances)保持鲁棒性。给定观察到的图像和一个长期目标,例如 “sort the blocks by colors into corners”,PaLM-E 以 1 Hz 的频率输出语言子目标,而(Interactive Language: Talking to Robots in Real Time,2022)的策略则以 5 Hz 的频率输出低级机器人动作,其由人类在环路中互动指导子目标和修正。

在图 5,b)中,我们看到 PaLME 能够进行单样本学习和零样本学习。在这里,我们对 PaLM-E 进行了微调,在 100 个不同的长期任务中,每个任务都有一个训练示例,例如 "“put all the blocks in the center”、“remove the blue blocks from the line”。我们还发现,PaLM-E 还能在涉及新物体对的任务(图 7,c)和涉及原始机器人数据集或微调数据集中未见过的物体(如 toy turtle)的任务(图 5,d)中实现零样本泛化。
6.4. Mobile Manipulation Environment
我们展示了 PaLM-E 在各种具有挑战性的移动操纵任务中的表现。我们大致沿用了 SayCan(2022)的设置,即机器人需要根据人类的指令规划一连串导航和操纵动作。例如,给定指令 "I spilled my drink, can you bring me something to clean it up?",机器人需要规划一个包含 "1. Find a sponge, 2. Pick up the sponge, 3. Bring it to the user, 4. Put down the sponge." 的序列。受这些任务的启发,我们开发了三个用例来测试 PaLM-E 的具身推理能力:
- 可用性预测(affordance prediction)
- 故障检测(failure detection)
- 长期规划(long-horizon planning)
底层策略来自 RT-1(RT-1: Robotics Transformer for Real-World Control at Scale,2022),它是一个 transformer 模型,可接收 RGB 图像和自然语言指令,并输出终端执行器控制命令。
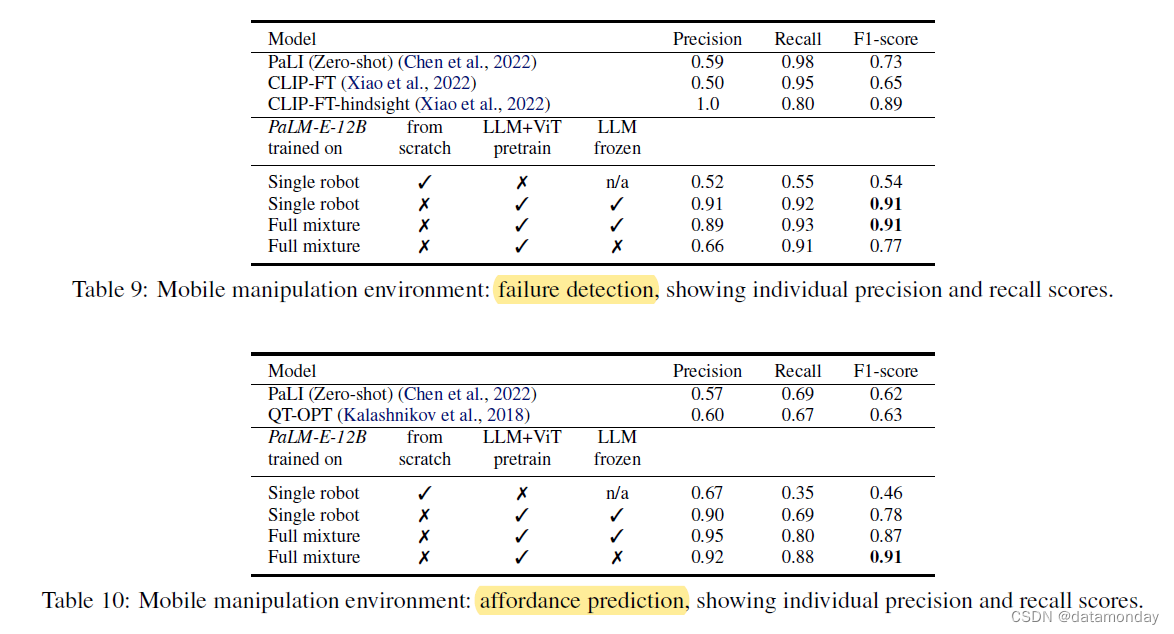
Affordance prediction.
我们研究了 PaLM-E 在可用性预测(affordance prediction)方面的性能,即是否可以在当前环境中执行低级策略的技能。这可以表述为 VQA 问题 Given <img>. Q: Is it possible to <skill> here?。PaLM-E 优于 PaLI(零样本),以及使用 QT-OPT 训练的值函数的阈值(表4)。

Failure detection.
对于机器人进行闭环规划(closed-loop planning),检测故障也很重要,如 (Huang et al., 2022c) 所示。多模态提示为 Given <img>. Q: Was <skill> successful?。表 4 显示 PaLM-E 在该数据集上优于 PaLI(零样本),以及 CLIP 的微调版本。PaLM-E 也优于(Robotic skill acquisition via instruction augmentation with visionlanguage models,2022)提出的算法, 它利用了两个使用事后重新标记数据训练的 CLIP 模型。这种方法可以访问比我们的方法更多的信息,并且是专门为解决该数据集的故障检测而设计的。
Real robot results: Long-horizon planning.
最后,我们使用 PaLM-E 为移动操作任务端到端执行具身规划。此任务的提示结构是 Human: <instruction> Robot: <step history>. I see <img>.。PaLM-E 被训练以生成计划的下一步,以所采取的步骤的历史和场景的当前图像观察为条件。在解码每个步骤后,我们将它们映射到 SayCan 定义的低级策略。这个过程以自回归方式完成,直到 PaLM-E 输出 “terminate”。我们使用 SayCan 的运行来训练模型,其中包含 2912 个序列。我们定性地评估了真实厨房中的模型,发现即使在对抗性扰动下,该模型也可以进行长期移动操作任务(图 5)。
6.5. Performance on General Visual-Language Tasks
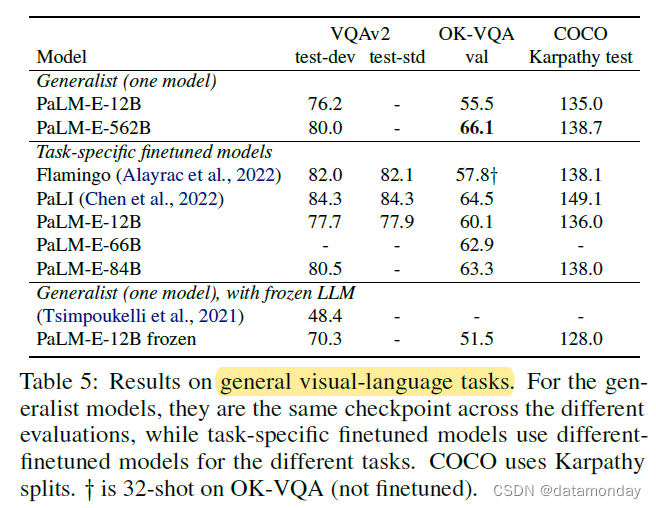
虽然这不是我们工作的重点,但我们在表 5 中报告了一般视觉语言任务的结果,包括
- OK-VQA:OK-VQA: A Visual Question Answering Benchmark Requiring External Knowledge,2019
- VQA v2:Making the V in VQA Matter: Elevating the Role of Image Understanding in Visual Question Answering,2017
- COCO captions:Microsoft COCO Captions: Data Collection and Evaluation Server,2017。
单个通用 PaLM-E-562B 模型在 OK-VQA 上达到了所报告的最高数值,包括优于专门针对 OK-VQA 进行微调的模型。据我们所知,与(Multimodal Few-Shot Learning with Frozen Language Models,2021)相比,PaLM-E 在 VQA v2 上通过冻结 LLM 达到了最高性能。这表明,PaLM-E不仅是机器人任务中的具身推理器,也是具有竞争力的视觉语言通才。
6.6. Performance on General Language Tasks
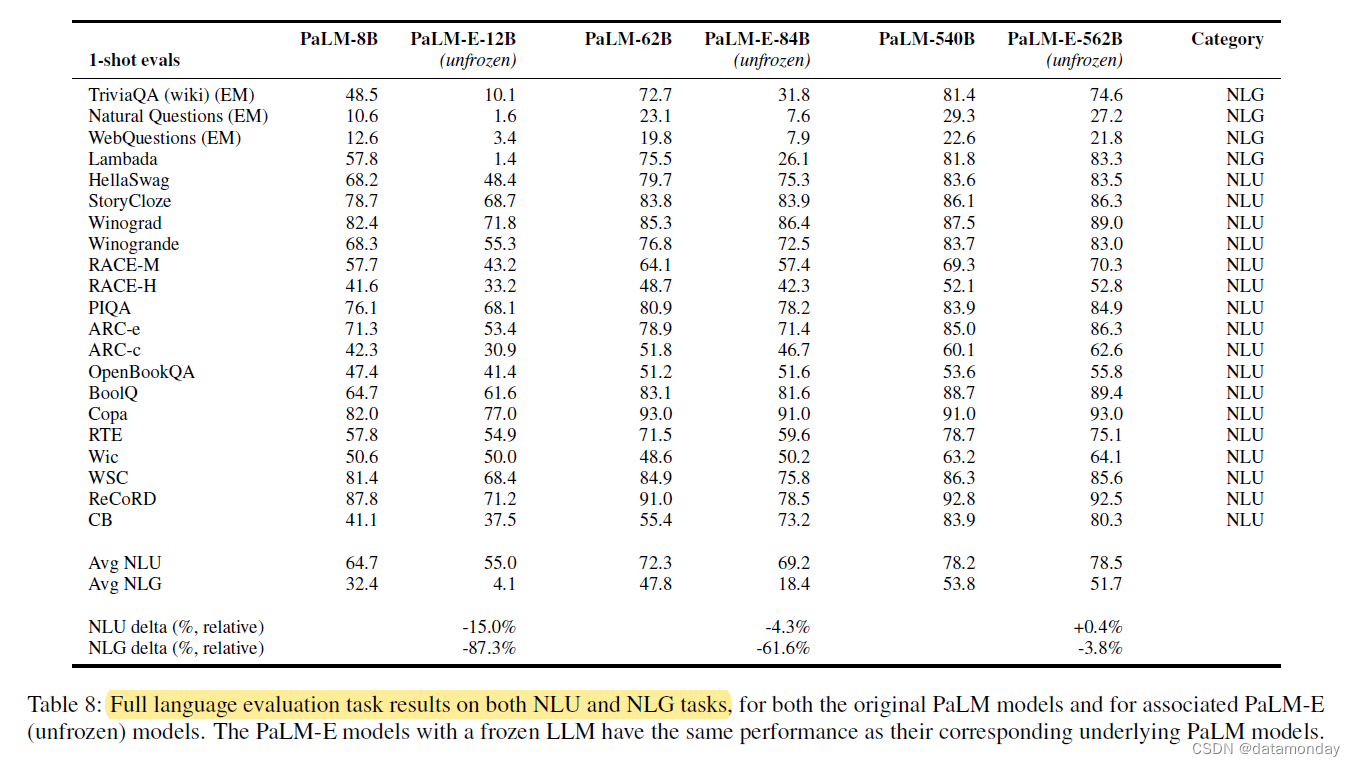
表 8 报告了 PaLM-E 在自然语言理解(NLU)和自然语言生成(NLG)任务的 21 个通用语言基准上的平均性能。表 8 报告了 PaLM-E 在自然语言理解(NLU)和自然语言生成(NLG)任务的 21 个通用语言基准上的平均性能。值得注意的趋势是,随着模型规模的扩大,语言能力的灾难性遗忘会大大减少。如图 6 所示,最小的模型(PaLM-E-12B)在多模态训练期间有 87.3% 的 NLG 性能(相对值)下降,而最大的模型(PaLM-E-562B)仅有 3.9% 的性能下降。

7. Summary of Experiments & Discussion
Generalist vs specialist models – transfer.
如图 3 所示,我们在这项工作中展示了几个迁移实例,即同时在不同任务和数据集上训练 PaLM-E,与单独在不同任务上训练的模型相比,性能显著提高。在图 4 中,对 “full mixture” 进行联合训练的性能提高了一倍多。在表 在表 9 中,如果我们添加 LLM/ViT 预训练,并在完 full mixture 上进行训练,而不是仅在移动操作数据上进行训练,我们就能看到性能的显著提高。对于表 2 中的语言表实验,我们观察到类似的行为。
Data efficiency.
与现有的海量语言或视觉语言数据集相比,机器人数据的丰富程度要低得多。正如上一段所讨论的,我们的模型表现出迁移性,这有助于 PaLM-E 从机器人领域的极少数训练示例中解决机器人任务,例如语言表中的 10 到 80 个示例或 TAMP 中的 320 个示例。OSRT 的结果显示了使用几何输入表示法的另一个数据效率实例。未来工作的一个大有可为的机会是将其与受益于大规模视觉数据的方法相结合。
Retaining language capabilities.
我们展示了在多模态训练过程中保留模型语言能力的两种途径。其中
- 一种方法是冻结 LLM,只训练输入编码器,这是建立具身语言模型的可行途径,尽管这种方法在机器人任务中偶尔会遇到困难(表 2)。
- 另一种方法是对整个模型进行端到端训练,随着模型规模的扩大,模型的原始语言性能会得到显著提高(图 6)。
8. Conclusion
我们建议将图像等多模态信息注入预先训练好的 LLM 的嵌入空间,从而建立一个具身语言模型。实验表明,在一般的 VQA 和图像描述任务中训练出来的现成的最先进的视觉语言模型不足以胜任具身推理任务,而且最近提出的通过可用性(affordances)能力建立语言模型的建议也有局限性。为了克服这些局限性,我们提出了 PaLM-E,这是一种能够在模拟和现实世界中控制不同机器人的单一模型,同时还能定量地胜任一般的 VQA 和图像描述任务。特别是将神经场景表征(即 OSRT)纳入模型的新颖架构理念,即使没有大规模数据,也特别有效。PaLM-E 是在多种机器人体现形式的不同任务以及一般视觉语言任务的混合物上进行训练的。重要的是,我们已经证明,这种多样化的训练可以将视觉语言领域的知识转移到具体化的决策制定中,从而使机器人规划任务能够高效地实现数据化。尽管我们的研究结果表明,冻结语言模型是实现完全保留语言能力的通用型多模态模型的可行途径,但我们也发现了另一条使用非冻结模型的途径:扩大语言模型的规模可显著减少灾难性遗忘,同时成为一个具身智能体。我们最大的模型 PaLM-E-562B 展示了新出现的能力(emergent capabilities),如多模态思维链推理,以及对多幅图像进行推理的能力,尽管它只接受过单幅图像提示的训练。