这个系列已经更文一些了,如果有新的文章会继续补充:
- 基于LLMs的多模态大模型(Visual ChatGPT,PICa,MM-REACT,MAGIC)
- 基于LLMs的多模态大模型(Flamingo, BLIP-2,KOSMOS-1)
- 基于LLMs的多模态大模型(MiniGPT-4,LLaVA,mPLUG-Owl,InstuctBLIP,X-LLM)
本篇文章先放一些比较杂的延伸和应用的文章,后面形成分支了再单独开,目前主要是PALM-E,ArtGPT-4,VPGTrans 等。
Pathways Language Model with Embodied
PALM-E是博主很关心的文章之一,它是一个562B的视觉语言模型(PaLM-540B + ViT-22B),有个是目前全球最大的视觉语言模型了。同时它将集成到机器人控制中,即多模态具身智能,这将为目前已经很强大的模型们加上机器人的手臂。关于多模态具身智能可以看博主以往的博文,不再赘述:传送门:具身智能综述和应用(Embodied AI)。

模型结构如下图中间部分所示,PaLM-E主要是将连续的具身观察,如图像、状态估计或其他传感器模态一起输入到语言模型中。因此模型的输入会变成:
Give <emb> ... <img> A: How to grasp blue block?
这里对多模态输入的处理跟前几篇博文中的方法类似,也是什么模态用什么编码器先token化,然后再把大家拼在一起,然后用PaLM-E来当解码器,去自回归地生成文本。生成的文本便可以去执行动作,
A: First. grasp yellow block and ...
然后与真实世界做交互。

从论文结果上看,PaLM-E完全支持zero-shot和cot。不过目前还只放出了paper和demo,具体的细节暂时不太清楚。但至少PALM-E向我们展示了,多模态LMs+world grounding是真的很有前景(pr:欢迎感兴趣的朋友私信我一起来做)。
- paper:PaLM-E: An Embodied Multimodal Language Model
- arxiv:https://arxiv.org/abs/2303.03378v1
- github:https://palm-e.github.io
ArtGPT-4: Artistic Vision-Language Understanding with Adapter-enhanced MiniGPT-4
ArtGPT-4是一类延伸模型,其主要基于MiniGPT-4,然后垂类解决它在艺术图片理解方面的问题。
模型结构如下图所示,主要通过Adapter-enhanced MiniGPT-4的策略做adapter tuning。如图主要对Vicuna的线性层和激活函数做tuning,以使模型能够更好地捕捉复杂的细节并理解艺术图像的含义,一个vicuna backbone可以被改装成如下结构:

训练数据集来自于ChatGPT创建的高质量图像文本对,总共 3500 对的高质量数据集。然后在Tesla A100 设备上使用大约 200 GB 的图像文本对训练2 小时。它除了改进图像理解之外,还能够生成视觉代码,包括美观的 HTML/CSS 网页等,具有更多的艺术天赋。
arxiv:https://arxiv.org/pdf/2305.07490.pdf
github:https://github.com/DLYuanGod/ArtGPT-4
VPGTrans: Transfer Visual Prompt Generator across LLMs
目前从头开始训练视觉-语言模型(VL-LLM)需要耗费大量资源,因此在前一篇博文中也基本都是把现有的语言模型和视觉模型拼接起来,这种方法虽然减少了训练消耗,但linear layers(projector)或者视觉模块(VPG)也往往是需要训练的。因此这篇文章的VPGTrans主要是一个提效方法,可以对现有的模型进行迁移来得到VL-LLM。相比于从头训练视觉模块,该方法可以将 BLIP-2 FlanT5-XXL 的训练开销从 19000+ 人民币缩减到不到 1000 元,如下图所示。
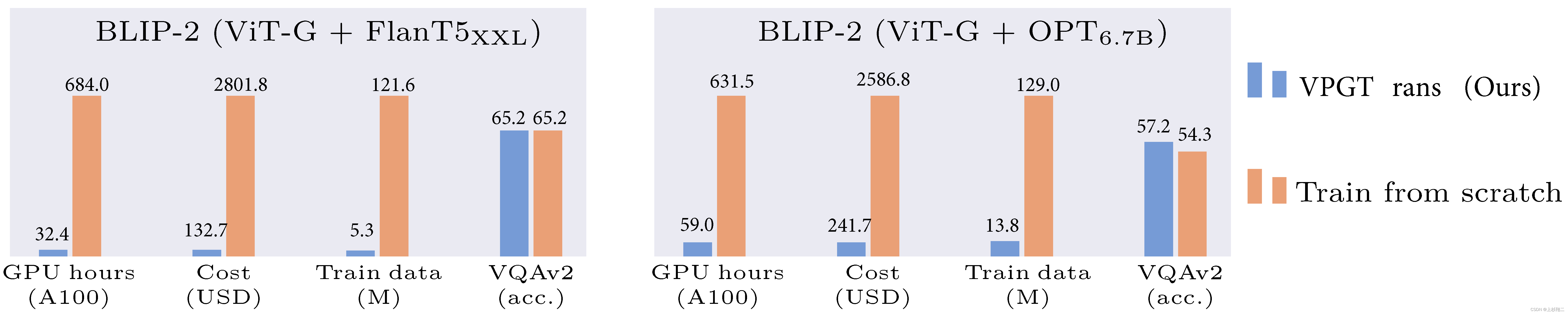
VPGTrans主要探索了两种类型的VPG的迁移:
- 跨LLM大小迁移(TaS):比如从OPT-2.7B到OPT-6.7B,其意义在于可以先在小的LLM上调参,然后再扩展到大LLM。
- 跨LLM类型迁移(TaT):比如从OPT到FlanT5,其意义在于可以快速切换不同的LLMs。
然后作者们做了一些探索实验,有一些有趣的发现:
- 直接继承VPG可以加速收敛,但加速有限+会掉点。
- 先warm-up projector 做3 epoch可以防止掉点+加速收敛。
- 词向量转化器初始化可以加速3 epoch到2 eopch,这个是很有意思的。作者们认为VPG是通过把图像转化为LLM可以理解的soft prompt,而soft prompt和词向量其实是非常相似的,因此作者们训练了一个图片到图片的词向量转化器(一个线性层),然后利用它来做projector的初始化。
- 5倍超大学习率可以加速收敛(主要是projector参数不复杂不容易崩)。
因此VPGTrans最终的训练结构如下图所示,
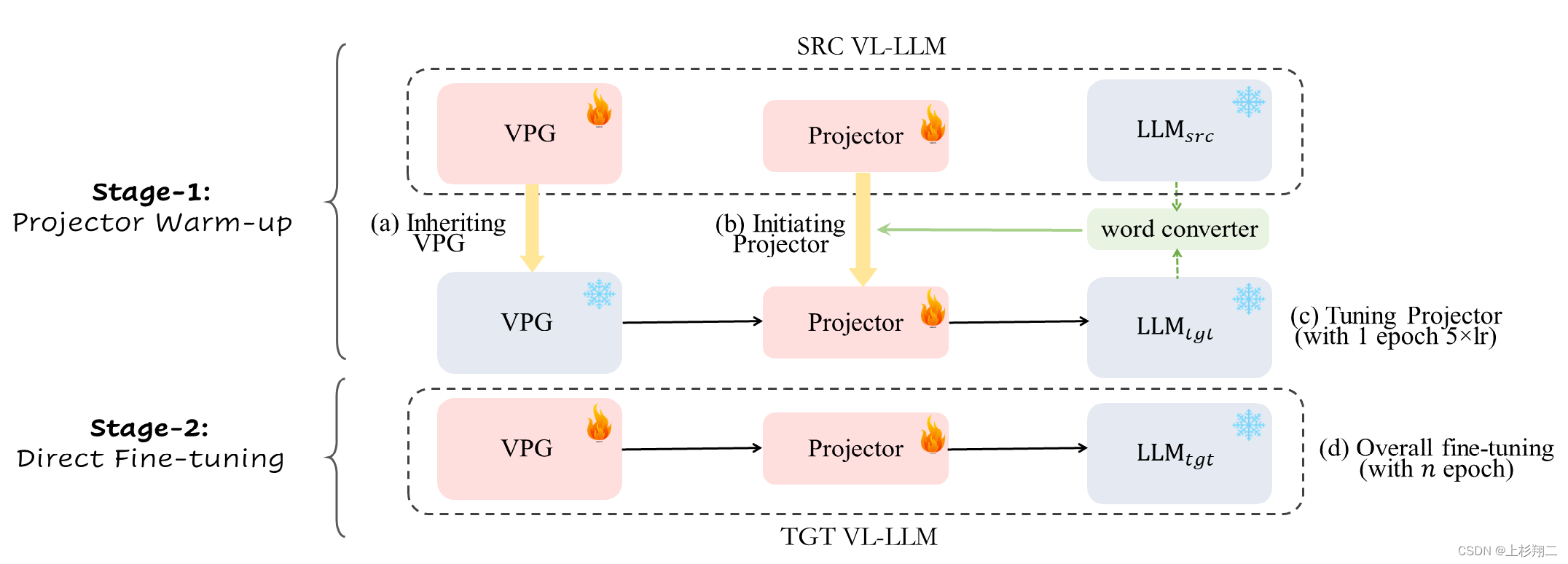
该方法同样分为两个阶段:
- 第一阶段:使用词向量转化器和原有projector进行融合作为新projector的初始化,然后用5倍学习率训练新projector 1 epoch。
- 第二阶段:直接正常训练VPG和projector。
demo:https://vpgtrans.github.io/
paper:https://arxiv.org/pdf/2305.01278.pdf
code:https://github.com/VPGTrans/VPGTrans