Introduction
R-CNN中,通过在原图先抠取出很多的像素块,再分别单独进行特征抽取的方式来一个个生成proposal,很低效:

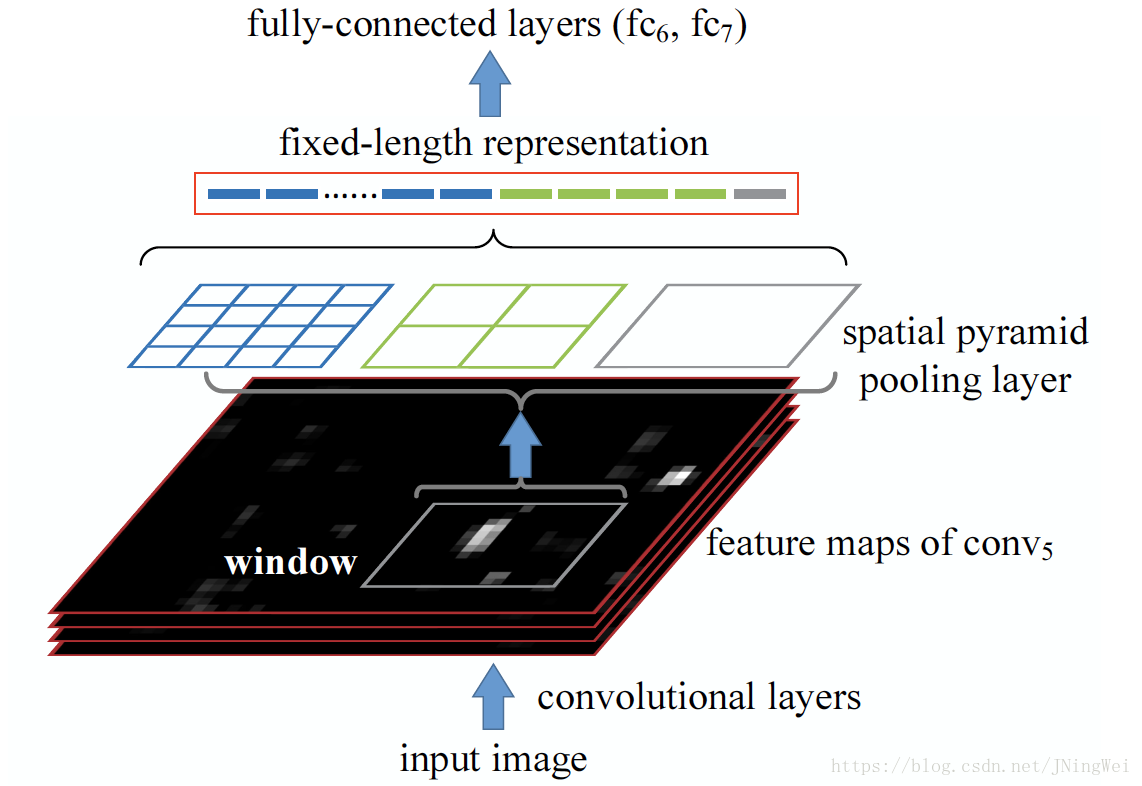
SPPNet则改成了直接先对整张图片进行特征抽取。再在这一大张feature map上,接上一个SPP layer:

和R-CNN一样,SPPNet的输入也包括两部分:
- 1batch的输入图像
- selective search算法对应每个输入图像生成的一系列proposal
另外,SPPNet还设计了全新的SPP layer,通过“池化”方式来统一“proposal的size”。
而在R-CNN中,则是通过“warp”方式来统一“proposal的size”。
该layer详细结构如下图红框部分:
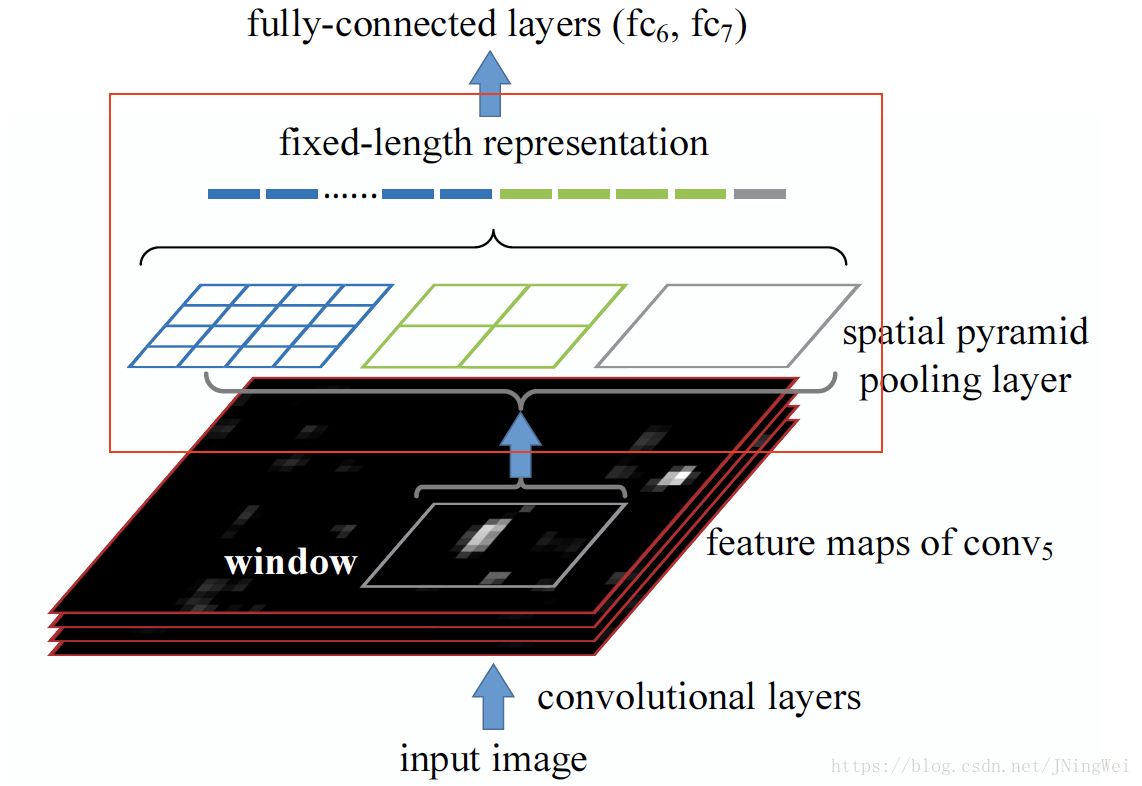
假设最后一个卷积层输出的feature map tensor的size为
,那么红框部分其实就是 滑窗size 为
的 average pooling:
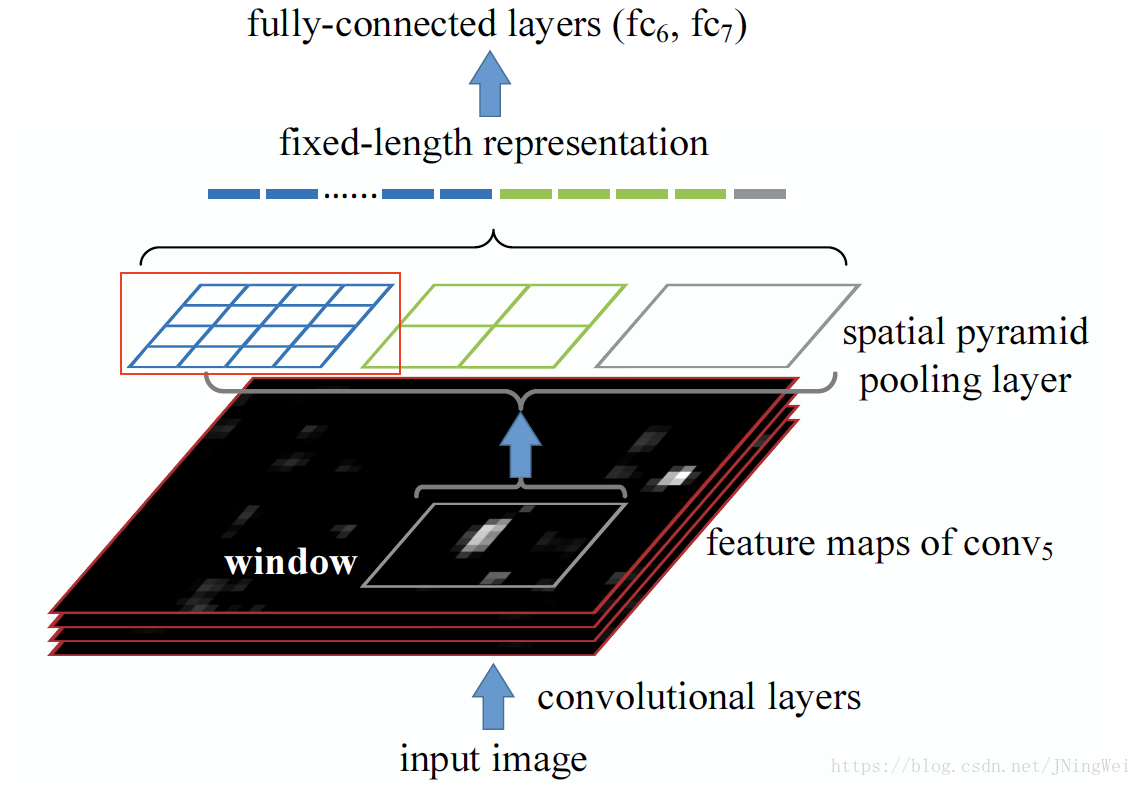
将该size的滑窗滑过全feature map tensor所pooling得到的tensor,沿channel方向一根根抽取出来,头尾拼接:
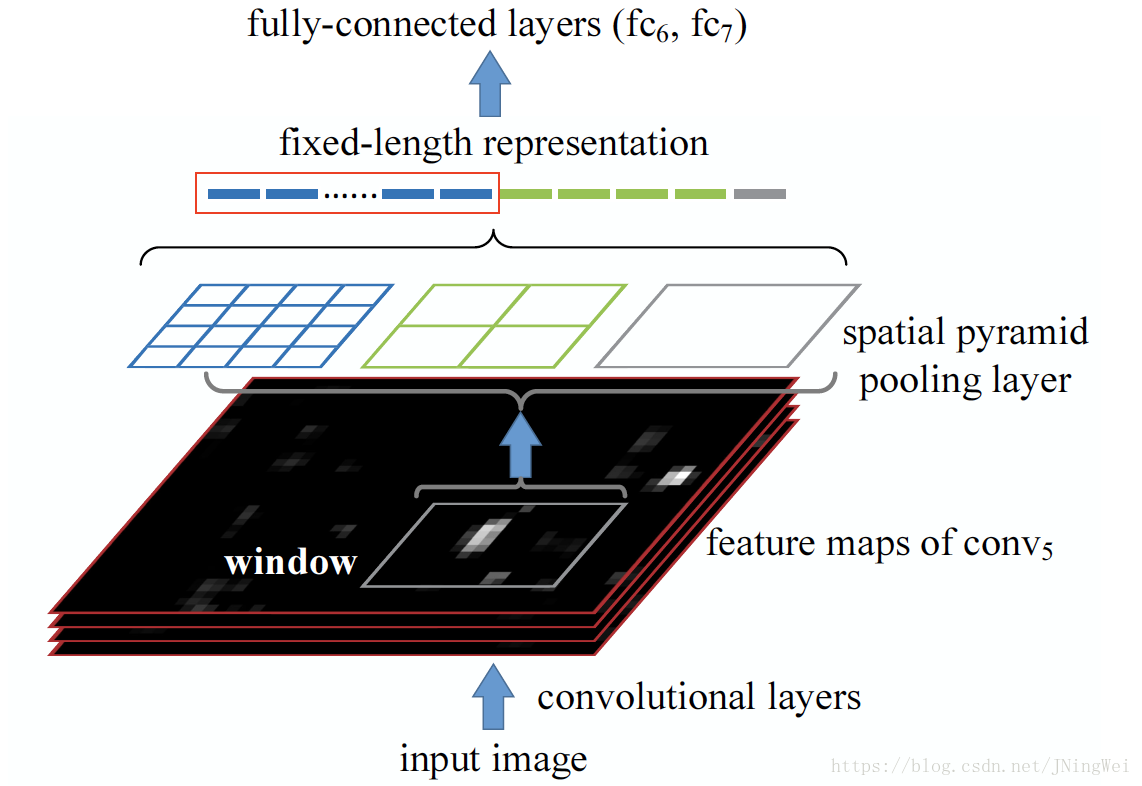
再用 的滑窗 和 的滑窗 在同一张feature map tensor上进行average pooling 。
其中,后者 (红框部分) 相当于 global average pooling (全局平均池化) :
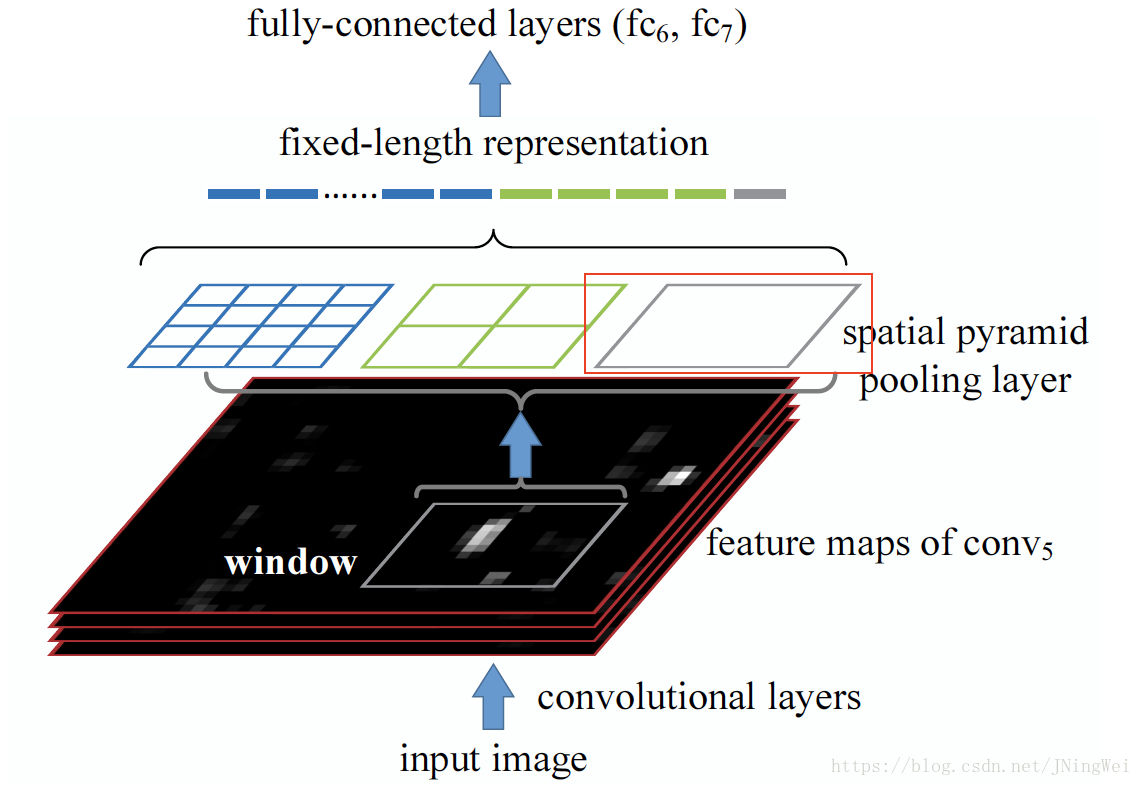
最后,三种size的average pooling会生成
根vector。
把这些vector头尾相接,并送入fc6层,即完成了SPP layer的使命:
Innovation
SPPNet有两个最大的创新点:特征抽取共享化、SPP layer。
特征抽取共享化 :大大简化了原本R-CNN设计中的巨大计算量,让原本需要分别单独进行特征抽取的各proposal可以放在一块,一起一次性完成特征抽取。后续所有的检测网络,无不继承了此思想。可以说,SPPNet推动了Detection的发展。
SPP layer :该layer可以 适应任意size和宽高比的输入图像。
Result
在VOC 2007上的结果:
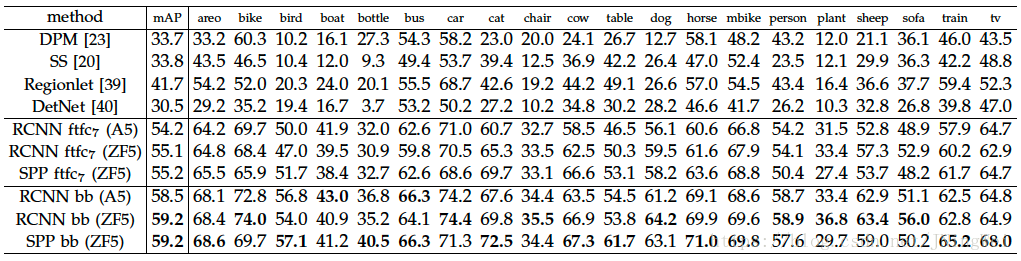
SPPNet检测效果图:

Thinking
SPPNet是一个被人忽视的杰出贡献。正是SPPNet,第一次提出了网络前半部分的 特征抽取共享化 。几个月之后的 Fast R-CNN 正是吸收了这部分的核心精华并进行了进一步的改进。
SPP layer有着明显的缺陷。因为其设计阻断了梯度下降的反向传播,使得下层的conv部分无法被从后往前update。该缺陷在Fast R-CNN中被修正。
[1] Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
[2] 深度学习: global pooling (全局池化)