分类和回归的区别在于输出变量的类型上。 通俗理解定量输出是回归,或者说是连续变量预测; 定性输出是分类,或者说是离散变量预测。如预测房价这是一个回归任务; 把东西分成几类, 比如猫狗猪牛,就是一个分类任务。
首先准备数据(MNIST库),MNIST库是手写体数字库,差不多是这样子的
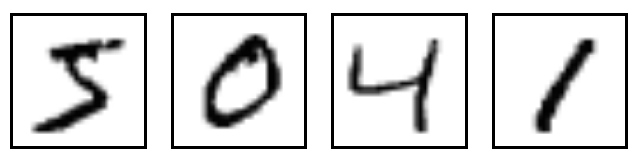
数据中包含55000张训练图片,每张图片的分辨率是28×28,所以我们的训练网络输入应该是28×28=784个像素数据。
import tensorflow as tf
import numpy as np
from tensorflow.examples.tutorials.mnist import input_data
import matplotlib.pyplot as plt
# number 1 to 10 data
mnist = input_data.read_data_sets('MNIST_data',one_hot=True) # 如果没有这个数据包会去网上帮你下载下来。
def add_layer(inputs,in_size,out_size,activation_function=None): # 输入值,输入的大小,输出的大小,激励函数
Weights = tf.Variable(tf.random_normal([in_size,out_size])) #定义矩阵 随机变量生成初始的时候会比全0的好
# 定义weights为一个in_size行, out_size列的随机变量矩阵
biases = tf.Variable(tf.zeros([1,out_size]) + 0.1) # 推荐初始值不为0
Wx_plus_b = tf.matmul(inputs,Weights) + biases
# 当激励函数为None时,输出就是当前的预测值——Wx_plus_b
# 不为None时,就把Wx_plus_b传到activation_function()函数中得到输出。
if activation_function is None: # 线性关系,就不需要再加非线性方程
outputs = Wx_plus_b
else:
outputs = activation_function(Wx_plus_b)
return outputs
def compute_accuracy(v_xs,v_ys):
global prediction # 定义全局变量
y_pre = sess.run(prediction, feed_dict={xs: v_xs}) # 用xs生成预测值 1行10列,介于0、1之间的数
correct_prediction = tf.equal(tf.argmax(y_pre, 1), tf.argmax(v_ys, 1)) # 概率最大值的位置是不是等于真是数据中1的位置
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32)) # 计算这组数据到底多少对的多少错的
result = sess.run(accuracy, feed_dict={xs: v_xs, ys: v_ys})
return result # 输出百分比
xs = tf.placeholder(tf.float32,[None,784]) # 每一张图片有784个像素点
ys = tf.placeholder(tf.float32,[None,10]) # 有十个数字输出
# 调用add_layer函数搭建一个最简单的训练网络结构,只有输入层和输出层。
prediction = add_layer(xs,784,10,activation_function=tf.nn.softmax) # softmax用来做分类
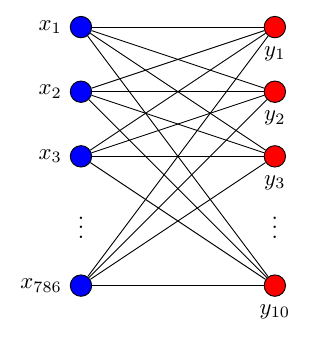
# 其中输入数据是784个特征,输出数据是10个特征,激励采用softmax函数,网络结构图是这样子的
cross_entropy = tf.reduce_mean(-tf.reduce_sum(ys*tf.log(prediction),
reduction_indices=[1])) # loss函数(即最优化目标函数)选用交叉熵函数。交叉熵用来衡量预测值和真实值的相似程度
train_step = tf.train.GradientDescentOptimizer(0.5).minimize(cross_entropy)
# train方法采用梯度下降法 优化器 目标,最小化误差
init = tf.global_variables_initializer()
sess = tf.Session()
sess.run(init)
for i in range(2000):
batch_xs,batch_ys = mnist.train.next_batch(100) # 现在开始train,从下载好的database每次只取100张图片,免得数据太多训练太慢。
sess.run(train_step,feed_dict={xs:batch_xs,ys:batch_ys})
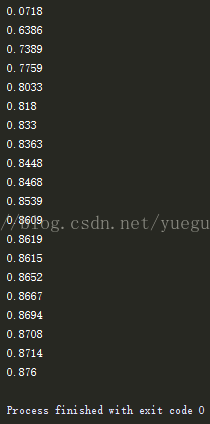
if i % 50 ==0:
print(compute_accuracy(mnist.test.images,mnist.test.labels))
plt.show()神经网络结构图:
运行结果: