系列文章目录
提示:这里可以添加系列文章的所有文章的目录,目录需要自己手动添加
例如:第一章 Python 机器学习入门之pandas的使用
提示:写完文章后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
前言
提示:这里可以添加本文要记录的大概内容:
例如:随着人工智能的不断发展,机器学习这门技术也越来越重要,很多人都开启了学习机器学习,本文就介绍了机器学习的基础内容。
提示:以下是本篇文章正文内容,下面案例可供参考
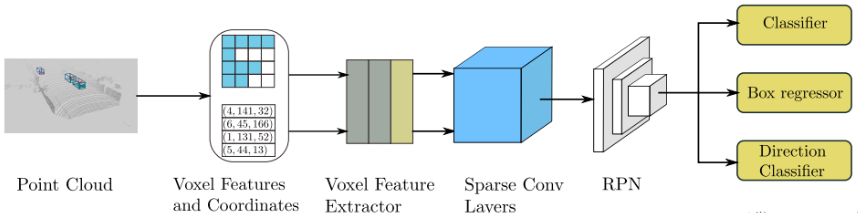
一、SECOND(Sensors 2018)
题目:SECOND: Sparsely Embedded Convolutional Detection
论文:https://www.mdpi.com/1424-8220/18/10/3337
代码:https://github.com/traveller59/second.pytorch
1、前言
SECOND是基于 Voxel按anchor-based 的点云检测方法,整体结构和实现接近 VoxelNet,改进了中间层的3D卷积,采用稀疏卷积来完成,提高了训练的效率和网络推理的速度,同时解决了VoxelNet中角度预测中,因为物体完全反向和产生很大loss的情况;同时,SECOND还提出了GT_Aug的点云数据增强。
2.MeanVFE (voxel特征编码)
经过对点云数据进行Grouping操作后得到三份数据:
1、所有的voxel shape为(N,5,4) ; 5为每个voxel最大的点数,4为每个point的数据:x,y,z,reflect intensity
2、每个voxel的位置坐标 shape(N, 3)
3、每个voxel中有多少个非空点 shape (N)
1.原文中分别对车、自行车和行人使用了不同的网络结构,PCDet仅使用一种结构训练三个类别。
2.在kitti数据集的实现中,点云的范围为[0, -40, -3, 70.4, 40, 1],超出部分会被裁剪, 此处以OpenPCDet中的统一规范坐标为准:
x向前,y向左,z向上,旋转角从x到y逆时针为正。
3.原论文中的每个voxel的长宽高为0.2,0.2,0.4且每个voxel中采样35个点,在PCDet的实现中每个voxel的长宽0.05米,高0.1米且
每个voxel采样5个点;同时在Grouping的过程中,一个voxel中点的数量不足5个的话,用0填充至5个。
N为非空voxel的最大个数,训练过程中N取16000,推理时取40000。
在新的实现中,去掉了原来Stacked Voxel Feature Encoding,直接计算每个voxel内点的平均值,当成这个voxel的特征.
(Batch16000, 5, 4) --> (Batch16000, 4)
class MeanVFE(VFETemplate):
def __init__(self, model_cfg, num_point_features, **kwargs):
super().__init__(model_cfg=model_cfg)
voxel_features, voxel_num_points = batch_dict['voxels'], batch_dict['voxel_num_points']
# 求每个voxel内 所有点的和
# eg:SECOND shape (Batch*16000, 5, 4) -> (Batch*16000, 4)
points_mean = voxel_features[:, :, :].sum(dim=1, keepdim=False)
# 正则化项, 保证每个voxel中最少有一个点,防止除0
normalizer = torch.clamp_min(voxel_num_points.view(-1, 1), min=1.0).type_as(voxel_features)
# 求每个voxel内点坐标的平均值
points_mean = points_mean / normalizer
# 将处理好的voxel_feature信息重新加入batch_dict中
3、VoxelBackBone8x
在VoxelNet中采用3D卷积提取特征,计算量太大,进行了改进:
submanifold卷积 将输出位置限制为在且仅当相应的输入位置处于活动状态时才处于活动状态。 这避免了太多的激活位置的产生,从而导致后续卷积层中速度的降低。
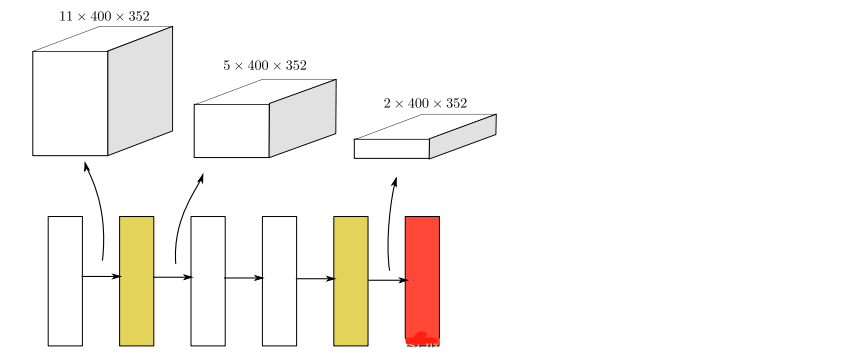
黄色代表作者自己提出的稀疏卷积,白色代表submanifold卷积,红色代表sparse-to-dense层
代码在:pcdet/models/backbones_3d/spconv_backbone.p
class VoxelBackBone8x(nn.Module):
def __init__(self, model_cfg, input_channels, grid_size, **kwargs):
super().__init__()
self.model_cfg = model_cfg
norm_fn = partial(nn.BatchNorm1d, eps=1e-3, momentum=0.01)
self.sparse_shape = grid_size[::-1] + [1, 0, 0]
self.conv_input = spconv.SparseSequential(
spconv.SubMConv3d(input_channels, 16, 3, padding=1, bias=False, indice_key='subm1'),
norm_fn(16),
nn.ReLU(),
)
block = post_act_block
self.conv1 = spconv.SparseSequential(
block(16, 16, 3, norm_fn=norm_fn, padding=1, indice_key='subm1'),
)
self.conv2 = spconv.SparseSequential(
# [1600, 1408, 41] <- [800, 704, 21]
block(16, 32, 3, norm_fn=norm_fn, stride=2, padding=1, indice_key='spconv2', conv_type='spconv'),
block(32, 32, 3, norm_fn=norm_fn, padding=1, indice_key='subm2'),
block(32, 32, 3, norm_fn=norm_fn, padding=1, indice_key='subm2'),
self.conv_out = spconv.SparseSequential(
# [200, 150, 5] -> [200, 150, 2]
spconv.SparseConv3d(64, 128, (3, 1, 1), stride=(2, 1, 1), padding=last_pad,
bias=False, indice_key='spconv_down2'),
norm_fn(128),
nn.ReLU(),
def forward(self, batch_dict):
"""
Args:
batch_dict:
batch_size: int
vfe_features: (num_voxels, C)
voxel_coords: (num_voxels, 4), [batch_idx, z_idx, y_idx, x_idx]
Returns:
batch_dict:
encoded_spconv_tensor: sparse tensor
"""
# voxel_features, voxel_coords shape (Batch * 16000, 4)
voxel_features, voxel_coords = batch_dict['voxel_features'], batch_dict['voxel_coords']
batch_size = batch_dict['batch_size']
# 根据voxel坐标,并将每个voxel放置voxel_coor对应的位置,建立成稀疏tensor
input_sp_tensor = spconv.SparseConvTensor(
# (Batch * 16000, 4)
features=voxel_features,
# (Batch * 16000, 4) 其中4为 batch_idx, x, y, z
indices=voxel_coords.int(),
# [41,1600,1408] ZYX 每个voxel的长宽高为0.05,0.05,0.1 点云的范围为[0, -40, -3, 70.4, 40, 1]
spatial_shape=self.sparse_shape,
# 4
batch_size=batch_size
)
"""
稀疏卷积的计算中,feature,channel,shape,index这几个内容都是分开存放的,
在后面用out.dense才把这三个内容组合到一起了,变为密集型的张量
spconv卷积的输入也是一样,输入和输出更像是一个 字典或者说元组
注意卷积中pad与no_pad的区别
"""
# # 进行submanifold convolution
# [batch_size, 4, [41, 1600, 1408]] --> [batch_size, 16, [41, 1600, 1408]]
x = self.conv_input(input_sp_tensor)
# [batch_size, 16, [41, 1600, 1408]] --> [batch_size, 16, [41, 1600, 1408]]
x_conv1 = self.conv1(x)
# [batch_size, 16, [41, 1600, 1408]] --> [batch_size, 32, [21, 800, 704]]
x_conv2 = self.conv2(x_conv1)
# [batch_size, 32, [21, 800, 704]] --> [batch_size, 64, [11, 400, 352]]
x_conv3 = self.conv3(x_conv2)
# [batch_size, 64, [11, 400, 352]] --> [batch_size, 64, [5, 200, 176]]
x_conv4 = self.conv4(x_conv3)
# for detection head
# [200, 176, 5] -> [200, 176, 2]
# [batch_size, 64, [5, 200, 176]] --> [batch_size, 128, [2, 200, 176]]
out = self.conv_out(x_conv4)
其中block为稀疏卷积构建:
def post_act_block(in_channels, out_channels, kernel_size, indice_key=None, stride=1, padding=0,
conv_type='subm', norm_fn=None):
# 后处理执行块,根据conv_type选择对应的卷积操作并和norm与激活函数封装为块
if conv_type == 'subm':
conv = spconv.SubMConv3d(in_channels, out_channels, kernel_size, bias=False, indice_key=indice_key)
elif conv_type == 'spconv':
conv = spconv.SparseConv3d(in_channels, out_channels, kernel_size, stride=stride, padding=padding,
bias=False, indice_key=indice_key)
elif conv_type == 'inverseconv':
conv = spconv.SparseInverseConv3d(in_channels, out_channels, kernel_size, indice_key=indice_key, bias=False)
else:
raise NotImplementedError
m = spconv.SparseSequential(
conv,
norm_fn(out_channels),
nn.ReLU(),
)
return m
4、HeightCompression (Z轴方向压缩)
前面VoxelBackBone8x得到的tensor是稀疏tensor:[batch_size, 128, [2, 200, 176]]
这里需要将原来的稀疏数据转换为密集数据;同时将得到的密集数据在Z轴方向上进行堆叠,因为在KITTI数据集中,没有物体会在Z轴上重合;同时这样做的好处有:
1.简化了网络检测头的设计难度
2.增加了高度方向上的感受野
3.加快了网络的训练、推理速度
最终得到的BEV特征图为:(batch_size, 128*2, 200, 176) ,这样就可以将图片的检测思路运用进来了。
5、BaseBEVBackbone
在获得类图片的特征数据后,需要在BEV的视角上提取特征:分别对特征图进行不同尺度的下采样、上采用、通道维度拼接。
下采样分支一:(batch_size, 1282, 200, 176) --> (batch,128, 200, 176)
下采样分支二:(batch_size, 1282, 200, 176) --> (batch,128, 200, 176)
反卷积分支一:(batch, 128, 200, 176) --> (batch, 256, 200, 176)
反卷积分支二:(batch, 256, 100, 88) --> (batch, 256, 200, 176)
最终将结构在通道维度上进行拼接的特征图维度:(batch, 256 * 2, 200, 176)
代码在:pcdet/models/backbones_2d/base_bev_backbone.py
6、AnchorHeadSingle
经过BaseBEVBackbone后得到的特征图为(batch, 256 * 2, 200, 176);在SECOND中,作者提出了方向分类,将原来VoxelNet的两个预测头上增加了一个方向分类头,来解决角度训练过程中一个预测的结果与GTBox的方向相反导致大loss的情况(框架图中最后三个黄色模块)
3D世界中,各类物体大小相对固定,将KITTI数据集中每个类别的平均长宽高作为anchor大小,同时每个类别的anchor都有两个方向角为0度和90度,则特征图上像素点含6个anchor(3类*2)。
1.anchor的类别尺度大小(单位:米):
分别是车 [3.9, 1.6, 1.56],anchor的中心在Z轴的-1米、
人[0.8, 0.6, 1.73],anchor的中心在Z轴的-0.6米、
自行车[1.76, 0.6, 1.73],anchor的中心在Z轴的-0.6米
2.每个anchro都有被指定两个个one-hot向量,一个用于方向分类,一个用于类别分类;还被指定一个7维的向量
用于anchor box的回归,分别是(x, y, z, l, w, h, θ)其中θ为PCDet坐标系下物体的朝向信息。
最终可以得到3个类别的anchor,维度都是[z, y, x, num_size, num_rot, 7],其中num_size是
每个类别有几个尺度(1个);num_rot为每个anchor有几个方向类别(2个);7维向量表示为
[x, y, z, dx, dy, dz, rot](每个anchor box的信息)。
代码在:pcdet/models/dense_heads/target_assigner/anchor_generator.py
7. 数据增强
SECOND提出了对GT进行采样截取,生成GT的Database,该方法在后续的很多网络中都得到了使用。(后续被称为GT_AUG)。该方法加速了网络的收敛速度,提升了最终精度。
1.首先,先对数据集中的标签和对应的box内的点云数据进行截取来创建database
2.其次,在训练的点云帧上随机从database中采样一部分GT,放入该帧中
3.对所有的GT进行碰撞检测,防止放入的GT会相互碰撞,产生不可能在物理世界中出现的结果,删除碰撞GT
二、Point RCNN(CVPR2019)
论文:PointRCNN: 3D Object Proposal Generation and Detection from Point Cloud
Two-stage detector (Faster R-CNN!)
1.第一阶段:proposal generation 自底向上的预选框生成
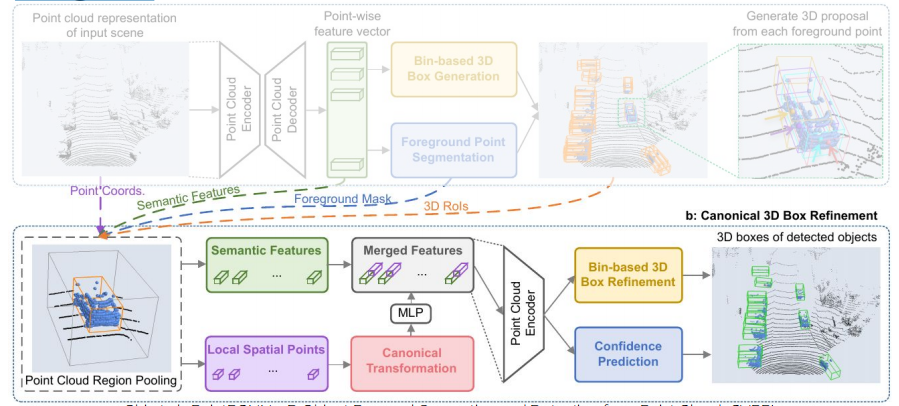
这个阶段有两个功能:分割前景点,生成预选框。
先用pointnet提取点云的特征。输入是(bs, n, 3)的点云,输出是(bs, n, 128)的特征。后接一个前景点分割网络(图中蓝色)和一个box生成网络(图中黄色)。
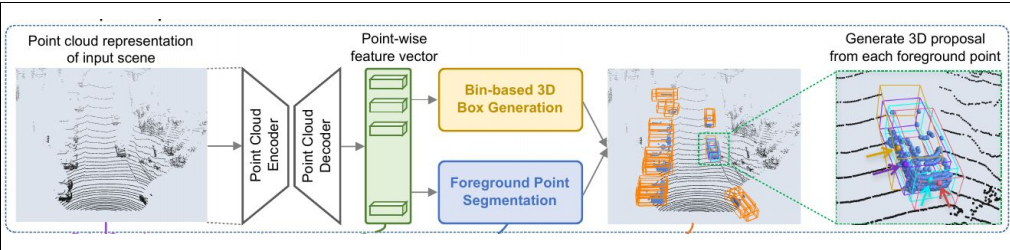
前景点分割网络:由两个卷积层组成。输入(bs, n, 128)的特征,输出(bs, n, 1)的mask。1表示这个点属于前景点的概率,值越大,则它属于前景点的概率越高。加一个sigmoid限制到(0,1),然后用focal loss计算损失。
box生成网络:由两个卷积层组成。输入是(bs, n, 128)的特征,输出是(bs, n, 76)。对于3d目标的bounding box,需要7个量来表示:box中心点(x,y,z), box的长,宽,高(w,h,l),俯视图的旋转角ry。这里用基于bin的预测方法使76个维度特征来代表这7个量,如下图左所示。
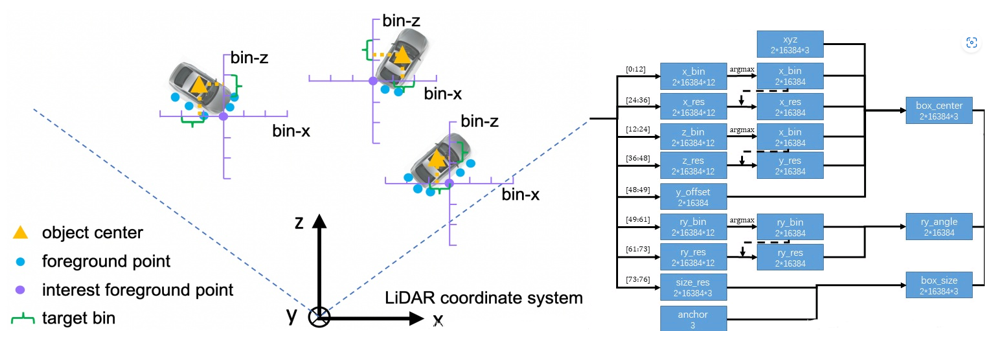
筛选:这一步网络的输出是(bs, n, 76),即对场景中的每一个点,预测一个bounding box。为减少冗余,所结合之前分割的mask,只考虑前景点的预测结果。再使用了NMS算法来进一步减少bounding box。 在相机 0~40m距离内的bounding box,先取得分类得分最高的6300个,然后计算bird view IOU,把IOU大于0.85的都删掉,到这里bounding box 又少了一点。然后再取得分最高的210个。在距离相机40~80m的范围内用同样的方法取90个。这样第一阶段结束的时候只剩下300个bounding box了。再进行第二阶段置信度打分和bounding box优化。
2. 第二阶段:再筛选和优化bounding box
输入:300个proposal bounding box,即(bs,300,7)。然后用sample和设置阈值的方法把bbox减少到128个。把在每个bounding box proposal 内部的点聚集起来,得到大小(bs,m,512,c)的数据。m表示每个batch中有多少个bounding box(比如128), 512表示每个bounding box里面有多少个point。然后进行数据增强操作。
接下来把每个bounding box内的points转换到局部坐标系(canonical 转换)下。如下图。
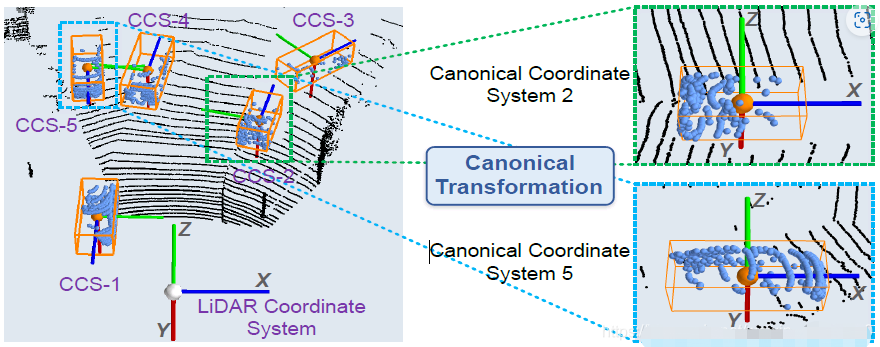
具体就是,新坐标系的坐标原点是bbox的中心点。并且让新的x轴和这个bbox头部平行。第二阶段会结合第一阶段预测的到的大小为(bs,n,128)的feature。
把大小为(bs,n,1)的mask,每个点距离相机的距离,每个点的反射强度(从雷达相机直接可以得到的值),每个点的坐标(x,y,z),全部concat在一起,上采样到128维度,和第一阶段预测的128维global feature结合为256维新特征。
用pointnet++的SA module(是一个采样,分组,特征提取模块)继续对这个特征进行卷积操作,得到一个(m,1,512)的特征,表示一个场景中有m个bounding box, 一个512维的point来代表这个bbox。
最后分别接一个reg_layer和一个cls_layer(conv1d)改变特征通道。得到(m,46)的bbox相关的预测结果和(m,1)的置信度结果。这46特征也是基于bin的预测,只是现在0-6表示x_bin,从而得到128个bounding box。结合预测得到的confidence筛选出最后的bounding box。PointRCNN检测结果如下图所示。
result:

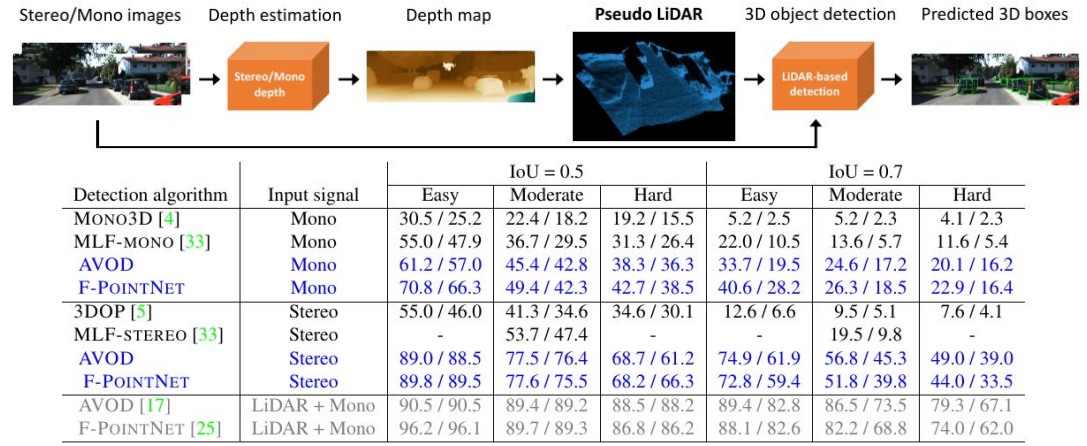
三、深度估计的雷达成像(检测 CVPR2019)
题目:Pseudo-LiDAR from Visual Depth Estimation
四、3DBoNet(检测+实例分割 NeurIPS2019)
论文链接:https://arxiv.org/abs/1906.01140
代码链接:https://github.com/Yang7879/3D-BoNet (tensorFlow)
1.核心思想
利用逐点多层感知机(MLP),直接预测3D边框,同时预测边框内各个点的二分标志,即判断它是属于物体还是属于背景。因此有 两个组成部分,一是3D边框预测网络,二是框内点分类网络。3D-BoNet不仅是单阶段、无锚点、端到端的系统,而且相比于传统思路效率大幅度提高,因为它不需要非极大值抑制(NMS)、特征采样、聚类、投票等后处理操作。
2.主要算法
传统方法缺点:实例分割在此之前主要有两类,第一类是基于候选目标框的算法(Proposal-based methods),这类方法通常先生成大量的候选框,然后依赖于两阶段的训练和昂贵的非极大值抑制等操作来对密集的候选框进行选择,缺点自然是运算量特别大。第二类是无候选目标框的算法(Proposal-free methods),这类方法的核心思想是为每个点学习一个分类,然后再通过聚类方法来将属于同一个实例的点聚集到一起,缺点最终聚类到一起的实例目标性比较差,而且后处理步骤的时间成本也比较高。
改进思路:首先不使用候选框,但为了提高目标性,不能放弃边界框,所以可以直接预测边界框,设计了一种边界框关联的方法,把预测和真值关联在一起,完成关联,后续的损失值设计等步骤就好做了。最后再对回归的边界框内的点做一个二分类,把背景点去掉,就可以得到实例分割的结果了。
流程:首先提取全局特征,直接使用这个全局特征来预测边界框。与此同时,提取点的特征,待边界框回归结束以后,某些点就会落入对应的框中,这样就可以进行二值分类,分割出实例目标。

训练时,边界框的关联(真值与预测值)是本文重点,可以分为以下几步:
1分配预测框给最近的真值框
2 计算顶点之间的欧式距离、交并比、交叉熵
3计算损失函数
4反向估计
完成了边界框的回归,剩下的最后一步就是背景点的剔除了,具体流程图下图所示。即根据点特征和边界框的得分,对框内的点进行二分类.


ScanNet 上实验结果:
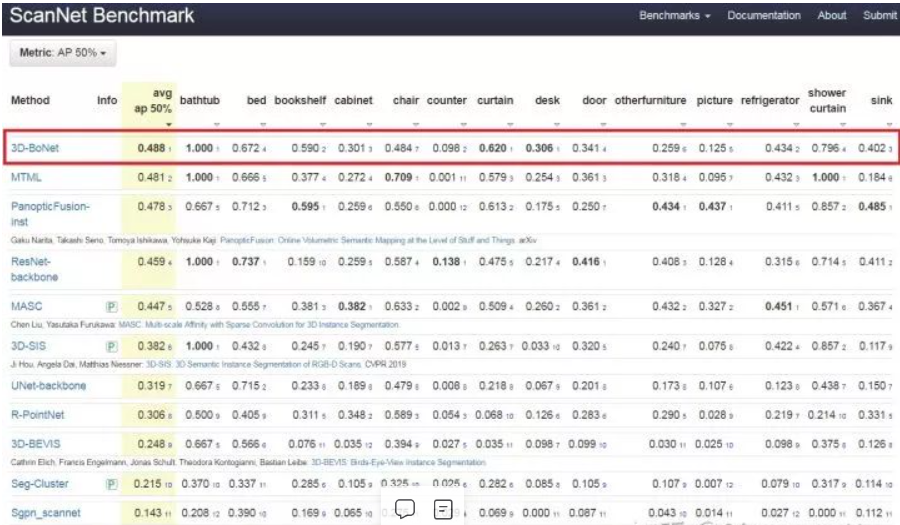
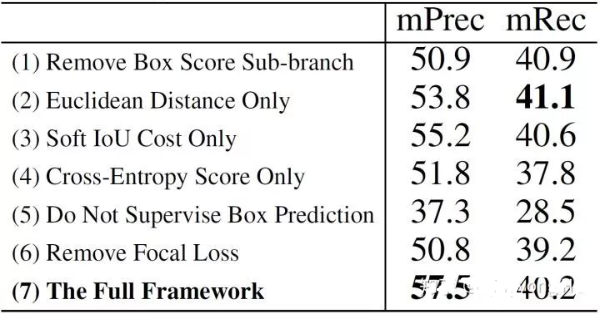
消融实验:
五、PV-RCNN(CVPR 2020)
PV-RCNN: Point-Voxel Feature Set Abstraction for 3D Object Detection(港中文、商汤)
论文:https://arxiv.org/pdf/1912.13192.pdf
代码:https://github.com/sshaoshuai/PCDet
1.摘要
本文的特征提取方式:集合了 3D voxel卷积 和基于点特征的 pointnet SA 方式。因为3D voxel卷积高效,但会损失位置信息,而point-based的方法感受野可变,但FPS(最远点采样)效率低,因此结合了这两种检测方法的优点。
该方法是一个两阶段的方法, 第一阶段提proposals,第二阶段为refine
在每一个3D proposals内平均的采样一些Grid-point,然后再通过P2的FPS最远点采样的方法得到该Grid_point周围的点,再通过结合去进一步refine最后的proposals
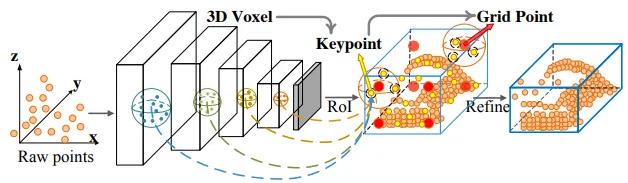
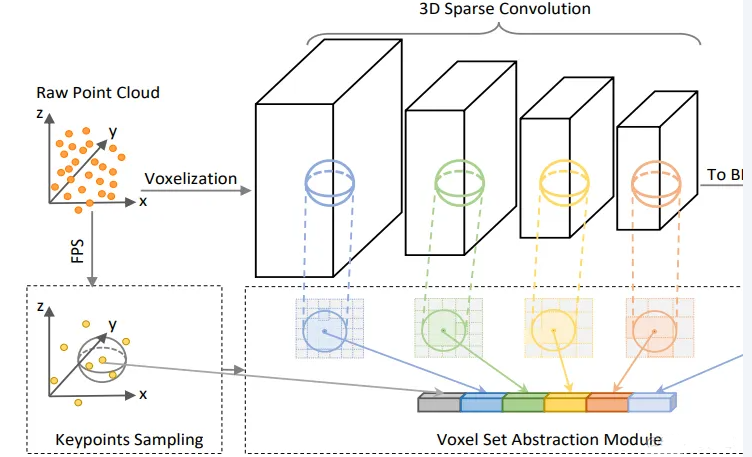
2.3D Voxel SA:voxel-to-keypoint scene encoding step
在 VoxelBackBone8x 中,分别得到了1x,2x, 4x, 8x 的voxel-wise feature volumes,Voxel SA操作会分别在这些尺度的voxel-wise feature volumes上进行,得到4个尺度的voxel编码特征。如下图:
VSA的实现与PointNet++的SA操作相同,只不过将操作对象从原始点云中的点换成了voxel-wise feature。
对每一个关键点,首先确定他在第K层上,半径为Rk邻域内的非空voxel,将这些非空voxel组成voxel-wsie的特征向量集合;然后将不同尺度上相同关键点获取的voxel-wsie的特征向量拼接在一起,并使用一个简单的PointNet网络来融合该关键点不同尺度的特征,公式如下:

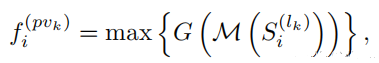
其中,M(·)代表在k层中固定半径内voxel 特征集合中的随机采样操作(每个集合中最大采样16或32个voxel-wise feature);G(·)代表多层感知网络(MLP),来编码voxel-wise的特征和相对位置。max(·)操作取每个voxel set中特征最大的voxel-wise feature。
同时,每一层的R_k设置如下(单位:米),用于聚合不同的感受野信息:
1x : [0.4, 0.8] ,采样数[16, 16],MLP维度[[16, 16], [16, 16]]
2x : [0.8, 1.2],采样数[16, 32],MLP维度[[32, 32], [32, 32]]
3x : [1.2, 2.4],采样数[16, 32],MLP维度[[64, 64]], [64, 64]]
4x : [2.4, 4.8],采样数[16, 32],MLP维度[[64, 64], [64, 64]]
得到的特征为: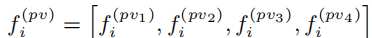
3.Extended VSA
在对每层3D卷积的输出进行VSA操作后,为了学习到的特征更丰富,作者扩展了VSA模块;在原来VSA模块的特征上,加了来自原点的SA特征和来自堆叠后BEV视角的双线性插值特征,如下图:
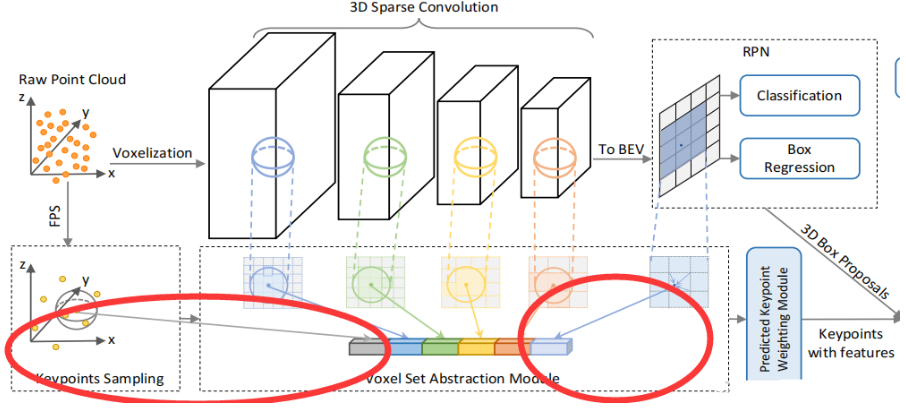
最终的公式为: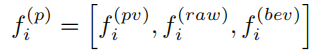
加入Extended VSA的好处:
1、来自原点的SA操作可以弥补因为voxelization导致的量化损失
2、来自BEV视角的插值SA操作拥有更大的Z轴(高度)感受野
BEV插值代码:
x_idxs = (keypoints[:, 1] - self.point_cloud_range[0]) / self.voxel_size[0]
# 得到该关键点对应的voxel的y坐标 shape : (2048*batch,)
y_idxs = (keypoints[:, 2] - self.point_cloud_range[1]) / self.voxel_size[1]
# x坐标除下采样倍数 shape : (2048*batch,)
x_idxs = x_idxs / bev_stride
# y坐标除下采样倍数 shape : (2048*batch,)
y_idxs = y_idxs / bev_stride
for k in range(batch_size): # 逐帧进行插值操作
bs_mask = (keypoints[:, 0] == k) # 当前帧点云的mask
cur_x_idxs = x_idxs[bs_mask] # 取出属于当前帧关键点的x坐标
cur_y_idxs = y_idxs[bs_mask] # 取出属于当前帧关键点的y坐标
# 对当前帧的BEV特征图进行维度转换 (C, 200, 176) --> (200, 176, C)
cur_bev_features = bev_features[k].permute(1, 2, 0)
# 通过双线性插值获得关键点的特征 shape (2048, C)
point_bev_features = bilinear_interpolate_torch(cur_bev_features, cur_x_idxs, cur_y_idxs)
# 结果放入列表中
point_bev_features_list.append(point_bev_features) # 将通过插值得到的关键点特征在第0维度进行拼接 (2048*batch, C)
point_bev_features = torch.cat(point_bev_features_list, dim=0) # (N1 + N2 + ..., C)
4、PointHeadSimple Predicted Keypoint Weighting
被最远点采样(FPS)算法选取出来的关键点是均匀的分布在点云中的,这就意味着有一部分的关键点并没有落在GT_box内,他们就代表了背景;作者在这里认为,属于前景的关键定应该主导box的精调,所以作者在这里加入了PKW模块用于预测关键点属于前景还是背景。
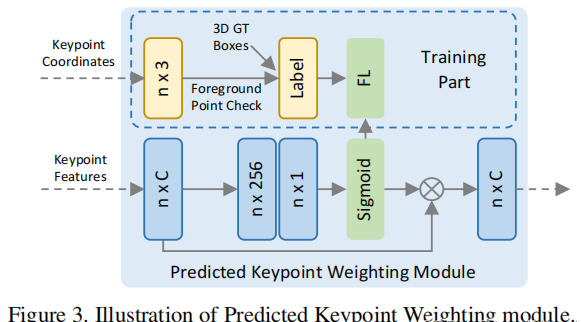
PKW模块用于 调整不同关键点特征的权重方式来实现,其中对于前背景点的分割GT值,由于在自动驾驶场景的数据集中所有的3D物体都是独立的,不会像图片中物体overlap的情况,可以直接判断一个点是否在3Dbox内即可得到前背景的类别,权重调整公式如下: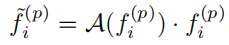
A(·)是一个三层的MLP,最终接上一个sigmoid函数来生成属于前景的置信度。
注:对于点前背景分割,PV-RCNN与PointRCNN中设置一直,对每个GTBox扩大0.2m,判断是否有关键点落在GTBox边沿,并将这个处于边沿的GTBox点不进行loss计算。
5、PVRCNNHead(二阶proposal精调)
第二阶段的refinement过程中,需要将来自ROI的特征融合关键点的特征,提升最终box预测的准确度和泛化性。作者提出了基于SA操作的keypoint-to-grid ROI feature abstraction,用于多尺度的ROI特征的编码。
在一个3D proposal中,均匀的采样6*6*6个grid point点,并采用和PointNet++中和SA一样的操作,并在
这些grid point点的多个尺度半径内分别聚合来自VSA中2048或4096个关键点特征的信息。公式如下:
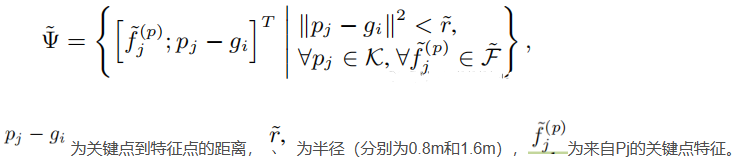 聚合后的特征采用一个简单的PointNet网络来聚合关键点特征集,产生该grid point的特征。
聚合后的特征采用一个简单的PointNet网络来聚合关键点特征集,产生该grid point的特征。
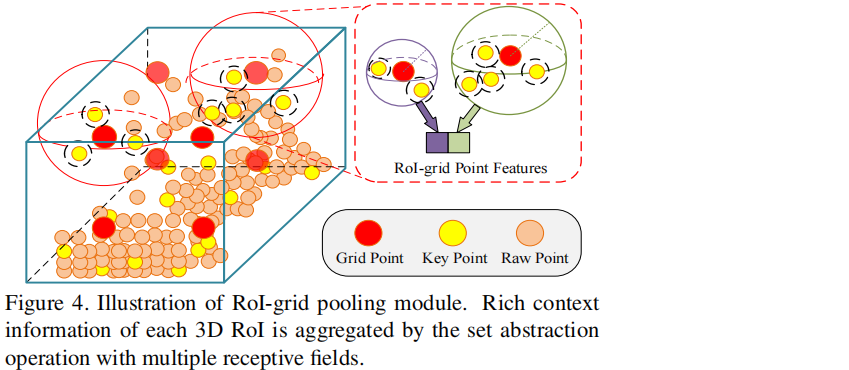
最后将不同半径大小的grid point特征,拼接 在一起,用一个两层的MLP网络将特征转换到最终的256维度,用以代表该proposal。
ROI grid Pooling操作相比于Point RCNN、Part A2、STD模型的ROI池化操作,拥有更好的感受野信息,
因为在ROI grid Pooling的时候,gridpoint包含的关键点特征可能超出了proposal本身,获取到了3D ROI
边缘的特征信息;而之前模型的ROI Pooling操作仅仅池化proposal内部的点的特征(Point RCNN),或者
池化很多无意义零点的特征(Part A2、STD)来作为ROI feature。
最终的refinement网络由两个分支构成,一个分支用于confidence预测,另外一个分支用于回归残差预测,
同时confidence的预测变成了quality-aware 3D Intersection-over-Union (IoU)
- proposal生成
根据前面一阶段得到的anchor信息,生成二阶段refinement需要的proposal;其中在训练阶段需要生成512个proposal,推理阶段生成100个proposal。得到的结果如下:
rois (batch size, 512, 7) 7-->(x, y, z, l, w, h, θ)
roi_scores (batch size, 512) 每个proposal的类别预测置信度分数
roi_labels (batch size, 512) 每个proposal的预测得到的类别
2.KITTI数据集上结果:
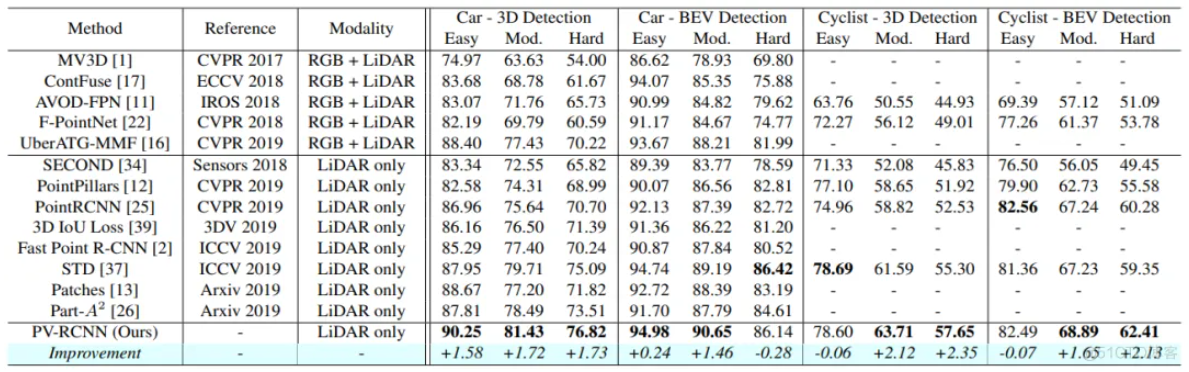
六、PV-RCNN++(CVPR 2021)
七、IA-SSD目标检测(CVPR 2022)
题目:End-to-End Multi-View Fusion for 3D Object Detection in LiDAR Point Clouds
论文:https://arxiv.org/abs/1910.06528v2
1.摘要
对于detector(即预测7自由度的三维box框,包括三维位置、三维尺寸、方向和类别标签)来说,前景点本质上比背景点更重要。基于此,论文提出了一种高效的单级基于point的3D目标检测器,称为IA-SSD:利用两种可学习的, 面向任务、实例感知 的下采样策略来分层选择属于感兴趣对象的前景点。此外,还引入了上下文质心感知模块,以进一步估计精确的实例中心。为了提高效率,论文按照 纯编码器 架构构建了IA-SSD。
由于三维点云的非结构化和无序性质,早期的工作通常首先将原始点云转换为中间规则表示,包括将三维点云投影到鸟瞰视图或正面视图的二维图像,或转换为密集的三维体素(3D-2D投影或体素化引入了量化误差),基于点的pipeline,许多重要的前景点在最终的边界框回归步骤之前被丢弃。
在kitti数据集上:
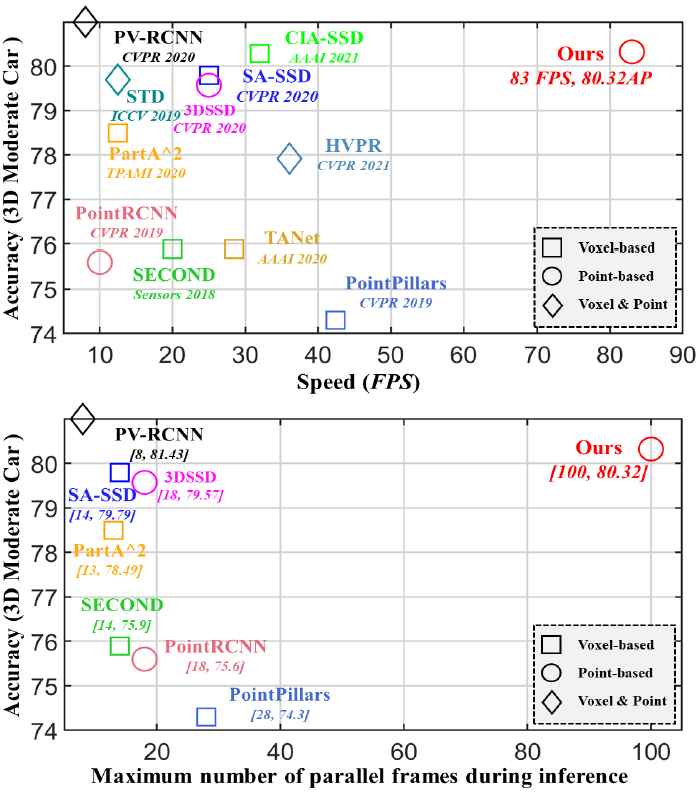
2、相关工作(综述)
1.基于Voxel方法
为了处理非结构化三维点云,基于体素的检测器通常首先将不规则点云转换为规则体素网格,这允许利用成熟的卷积网络架构。早期的工作,对输入点云进行密集体素化,然后利用卷积神经网络学习特定的几何模式。然而,效率是这些方法的主要限制之一,因为计算和内存成本随着输入分辨率呈立方体增长。为此,Yan等人[49]通过利用3D子流形稀疏卷积[9],提出了一种称为SECOND的高效架构。通过减少对空体素的计算,计算和存储效率显著提高。此外,提出了PointPillars,以进一步将体素简化为pillars (即仅在平面中进行体素化)。
现有的方法大致可分为单级检测器[7,11,54,55,57,58]和两级检测器[4,36–39,53]。尽管简单有效,但由于空间分辨率降低和结构信息不足,尤其是对于具有稀疏点的小对象,它们通常无法实现令人满意的检测性能。为此,SA-SSD通过引入辅助网络来利用结构信息。Ye等人[54]介绍了一种混合体素网络(HVNet),用于集中和投影多尺度特征图,以获得更好的性能。郑等人[58]提出了置信IoU感知(CIA-SSD )网络来提取空间语义特征,用于目标检测。相比之下,两级检测器可以获得更好的性能,但计算/存储成本较高。Shi等人[39]提出了一种两级检测器,即Part-A2,它由Part-aware和聚合模块组成。Deng等人[5]通过引入完全卷积网络来扩展PV-RCNN[36],以进一步利用原始点云的体积表示并同时进行细化。
总的来说,基于体素的方法可以实现良好的检测性能和良好的效率。然而,体素化不可避免地引入量化损耗。为了补偿预处理阶段的结构失真,需要在[20,25,27,28,35]中引入复杂的模块设计,这反过来会大大降低最终检测效率。此外,考虑到复杂的几何结构和各种不同的对象,在实践中确定最佳分辨率并不容易。
2.基于Point方法
与基于体素的方法不同,基于点的方法[30,38,52]直接从非结构化点云学习几何,进一步为感兴趣的对象生成特定proposal。考虑到3D点云的无序性,这些方法通常采用PointNet[31]及其变体[22、32、33、45、47],使用对称函数聚合独立的逐点特征。Shi等人[38]提出了PointRCNN,一种用于3D对象检测的两阶段3D区域proposal框架。该方法首先从分割的前景点生成对象建议,然后利用语义特征和局部空间线索回归高质量的三维边界框。Qi等人[30]介绍了VoteNet,这是一种基于深度Hough投票的单级point 3D检测器,用于预测实例质心。受2D图像中单级检测器[21]的启发,Yang等人[52]提出了一种3D单级检测(3DSSD)框架,而关键是融合采样策略,包括特征和欧几里德空间上的最远点采样。PointGNN[40]是一个将图形神经网络推广到3D对象检测的框架。
基于点的方法直接在原始点云上操作,无需任何额外的预处理步骤(如体素化),因此通常直观直观。然而,基于点的方法的主要瓶颈是学习能力不足和效率有限。
3.Point-Voxel方法
为了克服基于点的方法(即不规则和稀疏的数据访问、较差的内存局部性[23])和基于体素方法(如量化损失)的缺点,已经开始使用几种方法[3、16、36、37、53]从3D点云学习点-体素联合表示。PV-RCNN【36]及其后续工作[37]从体素抽象网络中提取逐点特征,以细化从三维体素主干生成的proposal。
HVPR[29]是一种单级3D探测器,通过引入高效内存模块以增强基于点的功能,从而在准确性和效率之间提供更好的折衷。Qian等人[34]提出了一种轻量级区域聚合细化网络(BANet)通过局部邻域图构造,产生更精确的box边界预测。
3.创新点
梗概: 首先将输入的激光雷达点云送入网络以提取逐点特征,然后进行拟议的实例感知下采样,以逐步降低计算成本,同时保留信息丰富的前景点。学习的潜在特征进一步输入到上下文质心感知模块,以生成实例建议并回归最终边界框。
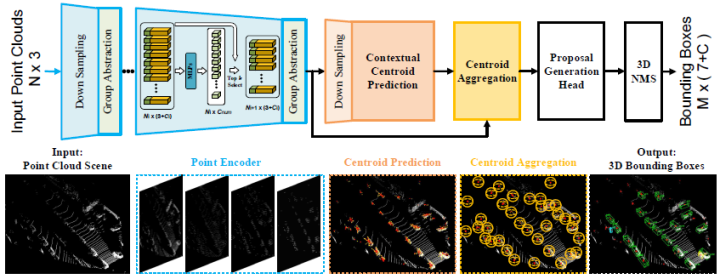
1.实例感知下采样策略
在 计算效率 和 前景点的保留 之间实现理想的权衡。为此,论文首先进行了一项实证研究,以定量评估不同的抽样方法,并遵循常用的编码体系结构(即具有4个编码层的PointNet++[32]),评估了随机点采样[14]、基于欧几里德距离的FPS(D-FPS)[32]和特征距离(Feat FPS)[52]等方法。
实验显示,在多次随机下采样操作后,实例召回率显著下降,表明大量前景点已被删除。D-FPS和Feat FPS在早期阶段都实现了相对较好的实例召回率,但在最后一个编码层也无法保留足够的前景点。因此,精确检测感兴趣的目标仍然是一项挑战,特别是对于行人和骑自行车的人等小目标,在这些小目标中只剩下极有限的前景点。
为了尽可能多地保留前景点,论文利用每个点的潜在语义,因为随着分层聚合在每个层中运行,学习的点特征可能包含更丰富的语义信息。根据这一思想,论文通过将前景语义先验合并到网络训练管道中,提出了以下两种面向任务的采样方法:
Class-aware Sampling
该采样策略旨在学习每个点的语义,从而实现选择性下采样。为了实现这一点,论文引入了额外的分支来利用潜在特征中丰富的语义。通过将两个MLP层附加到编码层,以进一步估计每个点的语义类别:
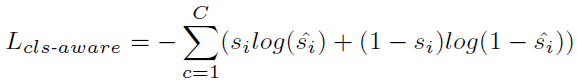
C表示类别数,si表示one-hot标签,si^表示预测Logit。在推理过程中,具有前k个前景分数的点被保留,并被视为馈送到下一编码层的代表点(为保留更多的前景点,实现了较高的实例召回率)。

Centroid-aware Sampling
考虑到实例中心估计是最终目标检测的关键,进一步提出了一种质心感知下采样策略,为更接近实例质心的点赋予更高的权重。将实例i的soft point mask定义如下:
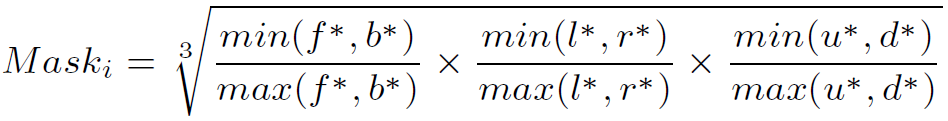
其中f∗, b∗, l∗, r∗, u∗, d∗ 分别表示点到边界框的6个surface(前、后、左、右、上和下)的距离。在这种情况下,靠近长方体质心的点可能具有更高的mask score(最大值为1),而位于surface上的点的mask分数为0。在训练期间,soft point mask将用于根据空间位置为边界框内的点指定不同的权重,因此将几何先验隐含地纳入网络训练。
将soft point mask与前景点的损失项相乘,以便为中心附近的点分配更高的概率。注意,在推理过程中不再需要box,如果模型训练充分,只需在下采样后保留得分最高的前k个点。
2.上下文实例质心感知
上下文质心预测
受2D图像中上下文预测成功的启发[6,51],论文试图利用边界框周围的上下文线索(质心预测)。遵循[30]明确预测偏移量∆ c到实例中心,并添加了正则化项以最小化质心预测的不确定性,质心预测损失公式如下:
基于质心的实例聚合
对于移位代表(质心)点,进一步利用PointNet++模块学习每个实例的潜在表示。将相邻点转换为局部规范坐标系,然后通过共享MLP和对称函数聚合点特征。
Proposal Generation Head
将聚集的质心点特征输入到提案生成头中,预测具有带有类别的bounding box。论文将proposal编码为具有位置、规模和方向的多维表示。最后,所有proposal都通过具有特定IoU阈值的3D-NMS后处理进行过滤。
4.实验细节
为了提高效率,论文基于单级编码器体系结构构建了IA-SSD。SA层[32]用于提取逐点特征,并使用具有递增半径组的多尺度分组([0.2,0.8]、[0.8,1.6]、[1.6,4.8])来稳定地提取局部几何特征。考虑到早期层中包含的有限语义,在前两个编码层中采用D-FPS,然后是所提出的实例感知下采样。256个代表点特征被馈送到上下文质心预测模块中,然后是三个MLP层(256→256→3) 以预测实例质心。最后,添加分类和回归层(三个MLP层)以输出语义标签和相应的边界框。
八、SST(CVPR2022)
题目:Embracing Single Stride 3D Object Detector with Sparse Transformer,【CASIA,UIUC,CMU】
代码: https://github.com/TuSimple/SST
论文: https://arxiv.org/pdf/2112.06375.pdf
0.摘要
作者发现,3D目标检测方法中提取特有下采样的操作(如PointPillars),特征图变小,导致信息损失;采用Transformer 无下采样,attention机制也适合稀疏点云操作。
做法:
1.点云体素化(或者Pillars化),将每个体素当作一个token,输入Transformer;
2.Regional Grouping:临近的token分为一个Group,Group内token做self-attention交互
3.Region Shift,再做self-attention,合并为一个block(共有6个):
4.后接一个检测头进行检测。
Group尺寸是3.84m×3.84m×6m,Pillars尺寸是0.32m×0.32m×6m
Group内做局部self-attention,是因为3D点云空间中,目标相对于整个点云很小,因此不需要很大的全局特征,只需局部特征。
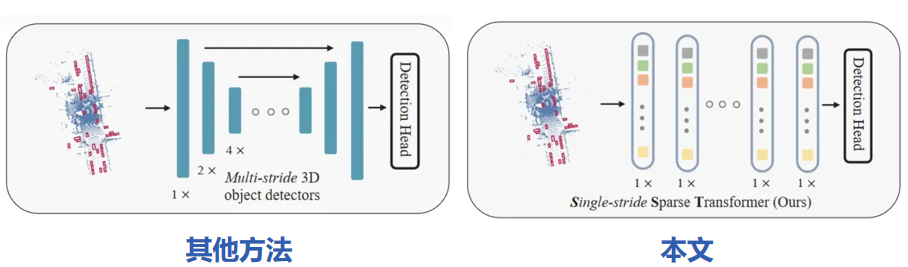
下采样算子的丢弃导致两个问题:1)计算成本的增加; 2)感受野的减少。前者限制了对实时系统的适用性,后者阻碍了对象识别的能力。对于计算的问题,稀疏卷积似乎是一个解决方案,但体素之间的稀疏连接使得感受野的下降更加严重。对于感受野问题,膨胀卷积对小对象不友好,较大的内核导致无法承受的计算开销在单步架构中。
注意力机制是个更好的选择:1)可以捕捉长距离的上下围信息,拥有更大的感受野.2)适合稀疏点云数据。
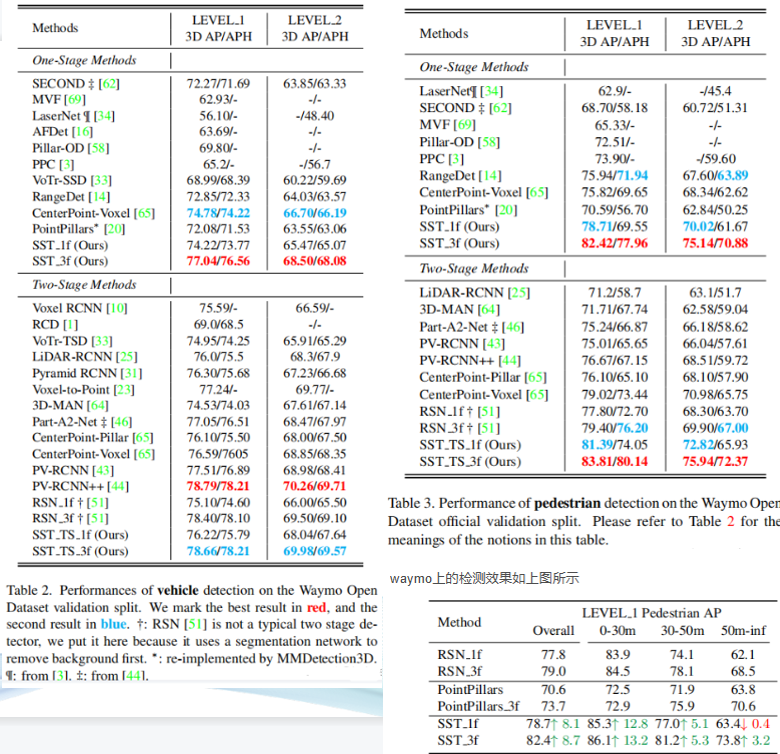
因此,我们将体素化的 3D 空间划分为许多局部区域,并在每个区域内应用自我注意。最终,这种称为稀疏区域注意 (SRA) 的局部注意机制享有两全其美。通过堆叠 SRA 层,我们使单步网络可行,并获得了一个Transformer风格的网络,称为单步稀疏Transformer (SST)。在大规模的 Waymo 开放数据集上进行实验,验证分割上的 83.8 LEVEL 1 AP
1.消融实验(证明下采样损失精度)
选择MMDetection3D框架中的PointPillars作为base model,在waymo数据集上进行测试。
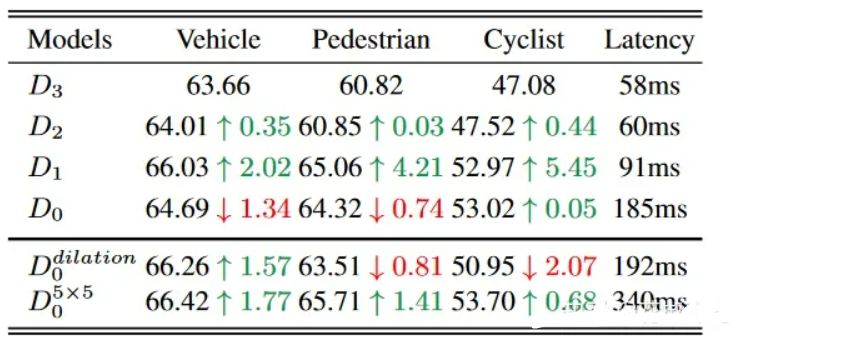
在标准 PointPillars 模型 D2 的基础上,我们将其扩展为另外三个变体:D3、D1 和 D0,它们仅在网络步长上有所不同。从 D3 到 D0,每个模型的四个阶段的步长集合是{1, 2, 4, 8}, {1, 2, 4, 4}, {1, 2, 2, 2} 和 {1,1, 1, 1},分别。由于四个阶段的输出特征图将通过类似 FPN 的模块上采样到原始分辨率,因此我们的修改不会改变检测头中特征图的分辨率。除了特征图的分辨率,所有四个模型都具有相同的超参数。为了减少内存开销,我们将卷积层中的过滤器数量从 256 更改为 128。结果如表 1 所示。 D3 到 D1在不断提升,并且从 D2 到 D1 有显着提升。从 D3 到 D1 的性能提升支持了我们的动机,即更小的步幅更适合 3D 检测。但从D1到D0,车辆性能下降明显,而行人性能下降幅度较小,自行车的性能不断上升。 D0 的有限感受野阻碍了从 D1 到 D0 的性能提升,因为行人和自行车比车辆的尺寸更小。
为验证推测,增加了两个变种,膨胀卷积核5*5卷积核。采用膨胀卷积的汽车检测精度提高,行人和自行车降低,证明提高感受野的同时会损失细节上的信息。更大尺寸的卷积核会对所有类型的检测精度有提升,但是速度慢。足够的感受野至关重要。
2.Methodology
- Overall Architecture
目前来看,single stride architecture feasible 的关键就是充足的感受野和可接受的计算量。卷积架构很难同时满足上述两个要求。构建的SST(Single-stride Sparse Transformer ),如下图所示:
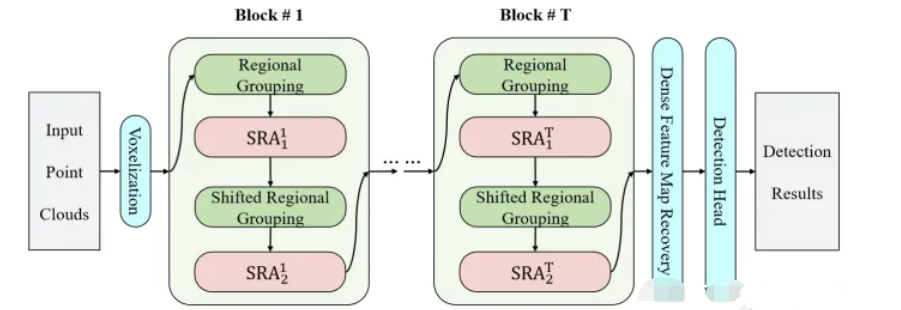
每个voxel看作一个token.:首先将体素化的 3D 空间划分为固定大小的非重叠group。然后将稀疏注意 (SRA) 应用于每个group。为处理分散于不同区域的对象并捕获有用的局部上下文,采用了区域移位,其灵感来自 Swin-Transformer中的移位窗口。主干保留了体素的数量以及它们的空间位置,从而满足单步属性,并且可以与主流检测头集成
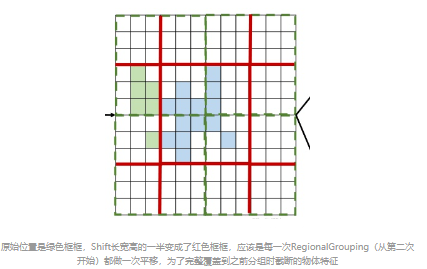
- Regional Grouping
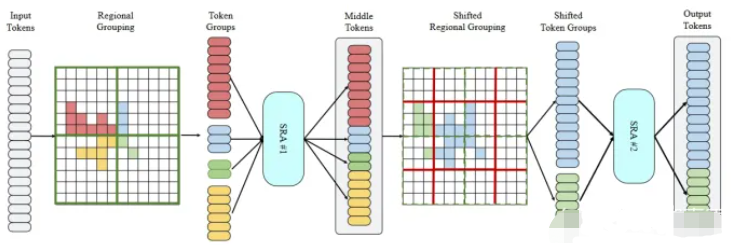
给定输入体素tokens,区域分组将 3D 空间划分为不重叠的区域,以便自我注意仅与来自相同区域的标记交互。区域分组不仅保持了足够的感受野,而且避免了全局注意力中昂贵的计算开销。我们在上图中直观地说明了这一点。每个区域分组根据输入标记的物理位置将其分成组,其中属于相同区域(绿色矩形)的标记被分配到同一组。
- Sparse Regional Attention
稀疏区域注意 (SRA) 对来自同一个区域分组的区域稀疏体素tokens 进行操作。对于一组tokens F 及其对应的空间 (x, y, z) 坐标I,SRA 遵循以下常规 self attention操作
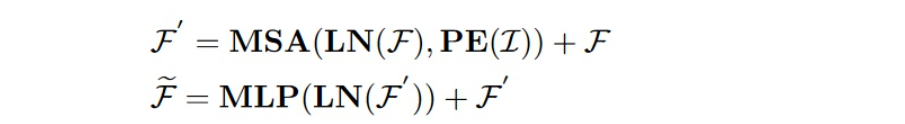
其中PE(·)代表绝对位置编码函数,MSA(·)代表Multi-head Self-Attention,LN(·)代表Layer Normalization。这种 SRA 方式很好地利用了点云的稀疏性,因为它只计算具有实际 LiDAR 点的体素。
区域批处理以实现高效执行 :由于点云的稀疏性,每个group的有效tokens 数量各不相同。为了利用并行计算,我们将具有相似数量tokens 的group批处理在一起。在实践中,如果一个group包含 N个 token ,满足
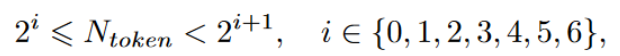
然后我们将tokens 数量填充为 2i+1。使用填充tokens ,我们可以将所有group分成几个批次,然后并行处理同一批次中的所有区域。由于填充的tokens 在计算中被屏蔽,它们对其他有效tokens 没有影响。这样,在当前流行的深度学习框架中很容易实现高效的 SRA 模块,而无需像稀疏卷积中所做的工程努力
- Region Shift
虽然 SRA 可以覆盖相当大的区域,但仍有一些对象不可避免地被分组截断。为了解决这个问题并聚合有用的上下文,我们在设计中进一步使用了 Region Shift,这类似于 Swin Transformer 中用于信息通信的移位机制。假设group分组中的区域大小为 (lx, ly , lz ),Region Shift 将原始区域移动 (lx/2, ly /2, lz /2) 并根据这组新的group对tokens 进行分组,如下图的所示。
5. Integration with Detection
为了与现有的检测器头一起融合,SST 根据其空间位置将稀疏体素标记放回密集特征图。未占用的位置用零填充。由于 LiDAR 仅捕获物体表面上的点,3D 物体中心很可能位于零特征的空白位置,这对当前的检测头设计不友好。所以我们添加了两个 3 × 3 的卷积来填充对象中心的大部分空洞。
至于检测头和损失函数,为简单起见,我们采用与 PointPillars 相同的设置。具体来说,我们使用 SSD 头、smooth L1 边界框定位损失 Lloc、focal loss形式的分类损失 Lcls,以及惩罚错误方向的方向损失 Ldir。最终的损失函数是 Eq 3,其中 Np 是正样本的数量。
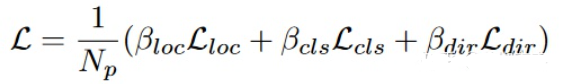 尽管我们的主为了使性能与当前的两级检测器相匹配,我们将 LiDAR-RCNN 作为我们的第二级。LiDAR-RCNN 是一个轻量级的第二阶段网络,由一个简单的 PointNet组成,用于特征提取,仅将proposal中的原始点云作为输入。
尽管我们的主为了使性能与当前的两级检测器相匹配,我们将 LiDAR-RCNN 作为我们的第二级。LiDAR-RCNN 是一个轻量级的第二阶段网络,由一个简单的 PointNet组成,用于特征提取,仅将proposal中的原始点云作为输入。
3.Experiments
Model Setup 模型以Point-Pillars为基础,将其backbone 替换为6 个连续的稀疏区域注意 (SRA) 块,每个block包含2次 attention module(应该就是两次group,第二次做shift),8头,在区域分组中,每个区域覆盖大小为 3.84m × 3.84m × 6m 的体积,采用的BEV pillar size0.32m×0.32m×6m。
九、FlatFormer(麻省理工 2023)
论文:https://arxiv.org/pdf/2301.08739.pdf
作者单位:麻省理工学院 上海交通大学 清华大学
- 论文思路:
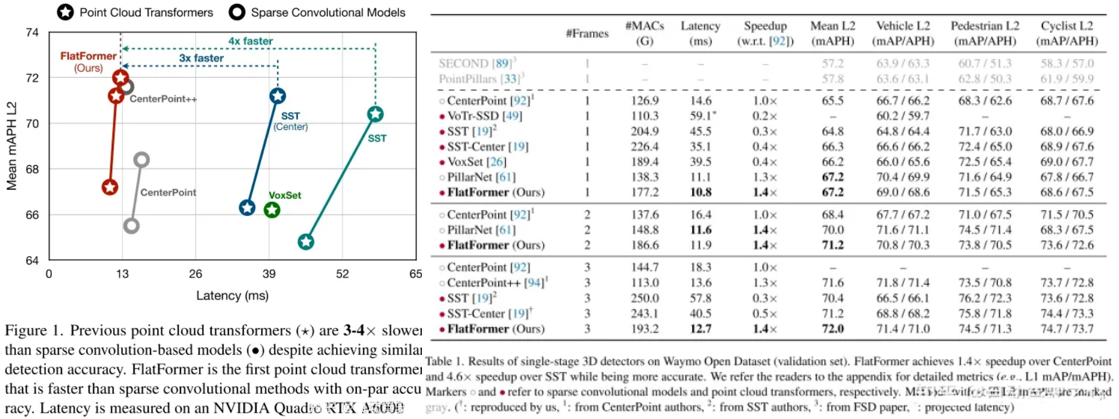
本文介绍了FlatFormer,通过交易空间邻近性(trading spatial proximity ),以获得更好的计算规律性,来缩小trans的延迟差距。本文 1.首先使用基于窗口的排序和划分点将点云扁平化(flatten)成相同大小的组(groups of equal sizes),而不是相同形状的窗口(windows of equal shapes)。这有效地避免了昂贵的结构化和填充开销。然后,本文 2.在组内应用自注意力来提取局部特征,交替排序轴从不同的方向收集特征,并移动窗口来在组间交换特征。FlatFormer在Waymo Open Dataset上提供了最先进的精度,比(transformer-based)SST加速4.6×,比(sparse convolutional)CenterPoint加速1.4×。这是第一个在边缘GPUs上实现实时性能的点云transformer,并且比稀疏卷积方法更快,同时在大规模基准测试上达到同等甚至更高的精度。
- 网络设计
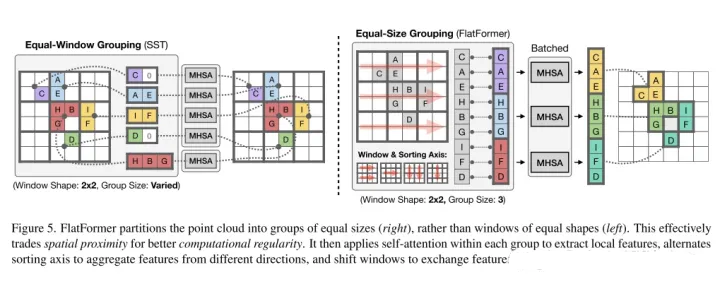
FlatFormer的基本构件是Flattened Window Attention(FWA)。如图5右所示,FWA采用基于窗口的排序来flatten点云,并将其划分为相同大小的组,而不是相同形状的窗口。这很自然地解决了组大小不平衡的问题,并避免了填充和分区开销。然后,FWA在组内应用自注意力来提取局部特征,交替使用排序轴来聚集从不同方向上的特征,并移动窗口来在组间交换特征。最后,本文提供了一个FWA的实现,进一步提高了其效率,并最小化了开销。
- 实验
十、Pillar R-CNN(2023)
1.前言
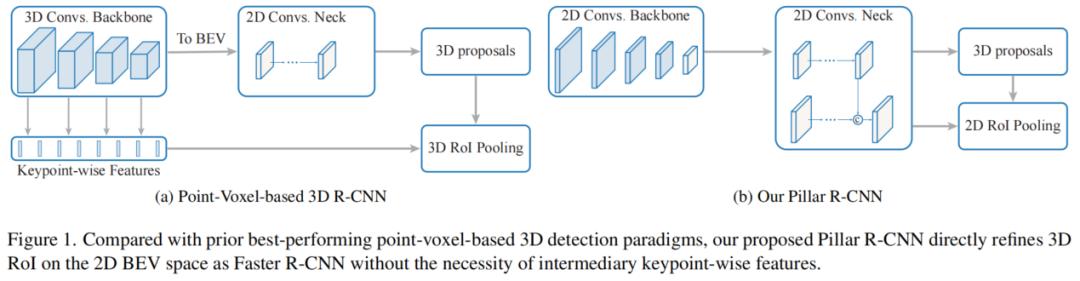
当前最先进的 两阶段3D目标检测方法 如图1所示,通常使用 基于点体素的特征学习方案来生成基于BEV的3D Proposals,然后在3D空间中进行点级框细化。在这两个阶段中,有效的关键点表示都起着主要作用。
-
开创性的PV-RCNN通过最远点采样(FPS)对原始点云进行子采样,作为中间关键点,并采用基于点的集合操作进行点体素交互。尽管PV-RCNN具有令人印象深刻的检测精度,但其点采样和邻居搜索过程耗时。
-
Voxel R-CNN认为,粗糙的3D体素而不是原始点的精确定位足以在大目标上进行精确定位。Voxel RCNN将稀疏但规则的三维体视为一组非空体素中心点,并利用加速的PointNet模块在精度和效率之间实现新的平衡。
-
PART-A2 采用了类似UNet的架构,用于更精细的体素点,并为小目标获得了更多的利润。最新的工作试图解决中间关键点的稀疏性和点密度变化问题,以提高检测精度。
总之,典型的基于点体素的3D检测器将点云转换为规则网格,用于基于BEV的3D
Proposals生成,并取决于关键点的粒度,以便进一步细化框。这不可避免地加剧了检测系统的复杂性。
从基于BEV的感知的角度来看,作者希望设计一个紧凑的R-CNN Head,在简单的Pillar上,以实现框的细化。基于三维体素的检测器,将三维特征体积转换为密集检测头的BEV表示,仅仅是鸟瞰图(BEV)表示仍然可以提供足够的3D结构信息,无需通过点级表示来恢复该上下文。 为了确认观点的正确性,作者构建了具有可管理粒度的合理池化特征图,并为每个3D Proposals裁剪该2D密集图,以进行3D RoI细化。
两阶段2D和3D检测之间的域差距
与2D不同,其中输入图像是2D密集图,点云的固有稀疏性和不规则性使其在方法上偏离了2D检测领域。主要差距可以是两阶段框架中基于3D点/体素的点云表示和过渡关键点。因此,2D检测的最新方法很难应用于3D检测。
例如,作为2D检测中的基本组件,特征金字塔网络(FPN)尚未被当前基于LiDAR的3D检测成功使用。基于Pillar的3D检测的最新进展通过在2D检测到3D检测中引入成熟的主干(如VGGNet和ResNet),部分弥补了这一差距,并取得了成功。
沿着这一研究方向,作者的目标是通过开发一种2D R-CNN型检测器,用于基于激光雷达的3D检测,从而缩小畴隙。所提出的Pillar R-CNN将基本FPN与RPN适当集成,用于小目标检测,并裁剪二维密集池化特征图,如RoIPool或RoIAlign,用于进一步的框细化,而无需使用过渡关键点表示。
2.本文方法
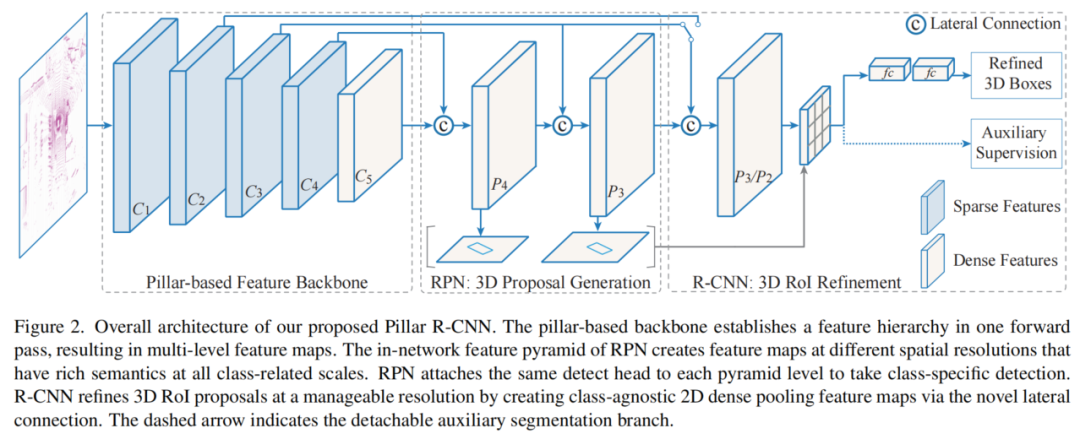
如图2所示提出的Pillar R-CNN在概念上很简单,包括两个阶段:第一阶段(RPN)产生3D Proposals,并在所有类别相关尺度上进行分类;第二阶段(R-CNN)以可管理的分辨率细化BEV平面上的3D框。
2.1、Pillar-based Backbone
Pillar R-CNN 将点云转换为规则的Pillar ,并以自下而上的方式分层处理稀疏的2D Voxel。PillarNet利用ConvNets(如VGGNet和ResNet)的2D检测优势,在一次前向传播中计算特征层次。它以自下而上的方式通过2D稀疏和密集卷积的混合创建一组低层稀疏2D柱体和高层密集特征图。用{C1,C2,C3,C4,C5}表示不同金字塔级别的多层次特征图,Pillar scales的Stride为{ 1,2,4,8,16 }。
2.2、Pyramidal Region Proposal Network
构建了金字塔(FPN)区域建议网络,以提高行人等小目标的检测精度。为了在所有类相关的尺度上构建高级语义特征图,修改了横向连接层,以有效地合并自上而下的密集图和自下而上的稀疏体。每个横向连接 合并了 来自自下而上路径和自上而下路径的相同空间大小的 稀疏特征量 和 密集特征图。
具体而言:
1.上下路径通过使用步长为2的反卷积层从更高的金字塔级别对语义更强的密集特征图进行上采样,从而产生更高分辨率的特征。
2.通过简单的连接,将上采样的密集特征图与来自其稀疏voxel的相应的密集自下而上的特征图合并。重复该过程,直到所需的多尺度特征图准备就绪。
3.在每个合并的映射上附加一个3×3卷积层,以减轻上采样的混叠效应并降低通道维数。这里,具有高级丰富语义的最后一组特征图
(称为P3 P4)在空间大小方面分别对应于{ C3,C4 }。
2.3、R-CNN via 2D RoI Pooling on BEV Plane
为了证明BEV表示保留了关键的3D结构信息,通过简单设计的横向连接层以可管理的比例构建了密集池化特征。然后,通过在BEV平面上使用Faster R-CNN-like RoI池化模块来进一步细化3D Box。作者还使用语义监督来监督每个3D Proposals的网格点,以进一步检查BEV表示的3D结构能力,并对齐PV-RCNN中使用的额外关键点分割监督分支。
1、Lateral connection layer
用于构建池化图的横向连接层的目的是以可管理的分辨率将低级别稀疏Pillar特征量和高级别密集语义特征图集成到密集池化图中。具体而言:
1.使用2D稀疏卷积层用于将所选低层Pillar从自下而上的路径降采样到期望的空间分辨率。
2.步长为2的反卷积层以自顶向下的方式对来自金字塔颈部模块的密集语义特征图进行上采样。
3.通过3×3卷积层以相同的空间分辨率合并语义更强的密集映射和空间更精确的稀疏体,构建密集池化映射。
横向连接层略微偏离了原始FPN中的逐元素相加方式,因为稀疏体积可能非常稀疏,大部分为空点。为了解决稀疏特征导致的中心特征缺失的问题,简单地应用cat和标准卷积运算来混合来自自下而上路径的特征图和来自自上而下路径的特征图。通过这种方式横向连接设计可以为空间精确但稀疏的自下而上的Pillar提供关键的语义信息。
2、Auxiliary segmentation supervision
在每个3D Proposal中附加了网格点的可分离辅助分割监督,以提高基于BEV的池化图的3D结构能力,这是受PV-RCNN中基于3D体素的结构上下文的关键点的额外分割监督的启发
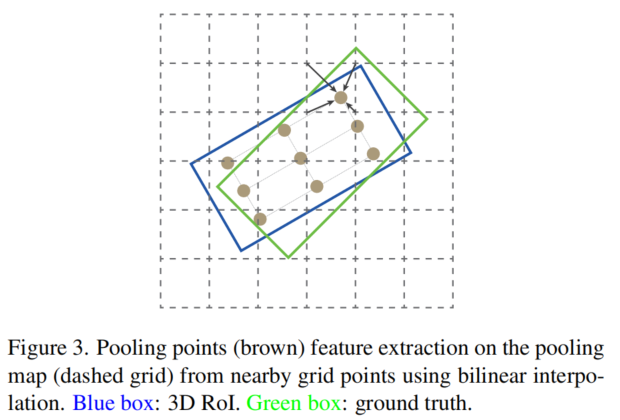
具体而言,使用具有Sigmoid函数的2层MLP来预测每个投影2D旋转RoI中每个网格点的前景/背景分数。通过识别每个网格点是在图3中投影的GT旋转框的内部还是外部,可以从3D框标注中直接生成分割层,因为3D目标在BEV平面上不重叠。
此外,辅助分段监督分支仅在训练期间使用,因此没有额外的推理计算开销。
与RoI池化和RoI Align类似,使用投影的2D旋转RoI裁剪密集池化图,以提取BEV平面上的3D RoI特征。具体而言,简单地利用双线性插值操作来对图3中每个投影的3D RoI中均匀分布的 G*G网格点进行采样。然后,通过两个256-D FC层将采样的网格点特征RG*G*G。
因此,Faster R-CNN-like 2D RoI池化模块将具有不同大小目标的每个3D RoI特征转换为固定的空间范围用于3D Proposal细化和置信度预测。值得注意的是第2个R-CNN阶段与Faster R-CNN略有不同,因为它需要在可管理的尺度上使用池化图,并通过横向连接层充分融合语义空间特征。
3.实验结果
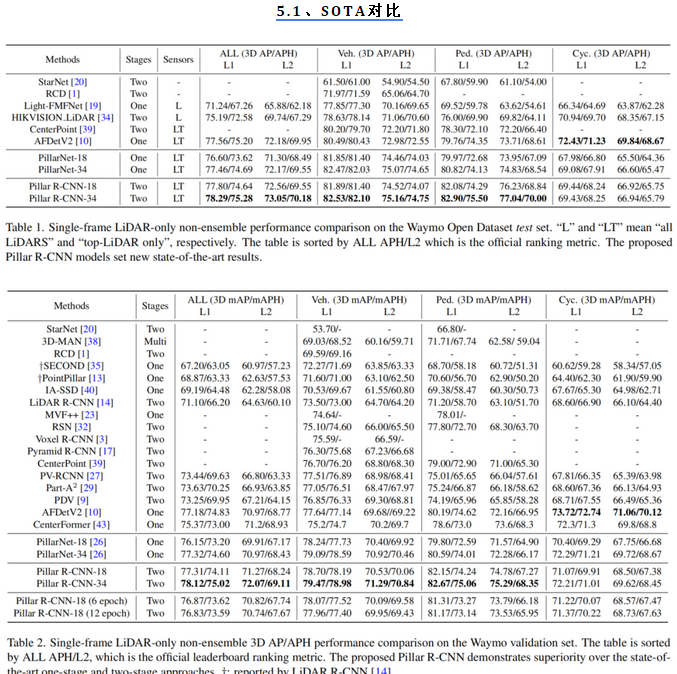
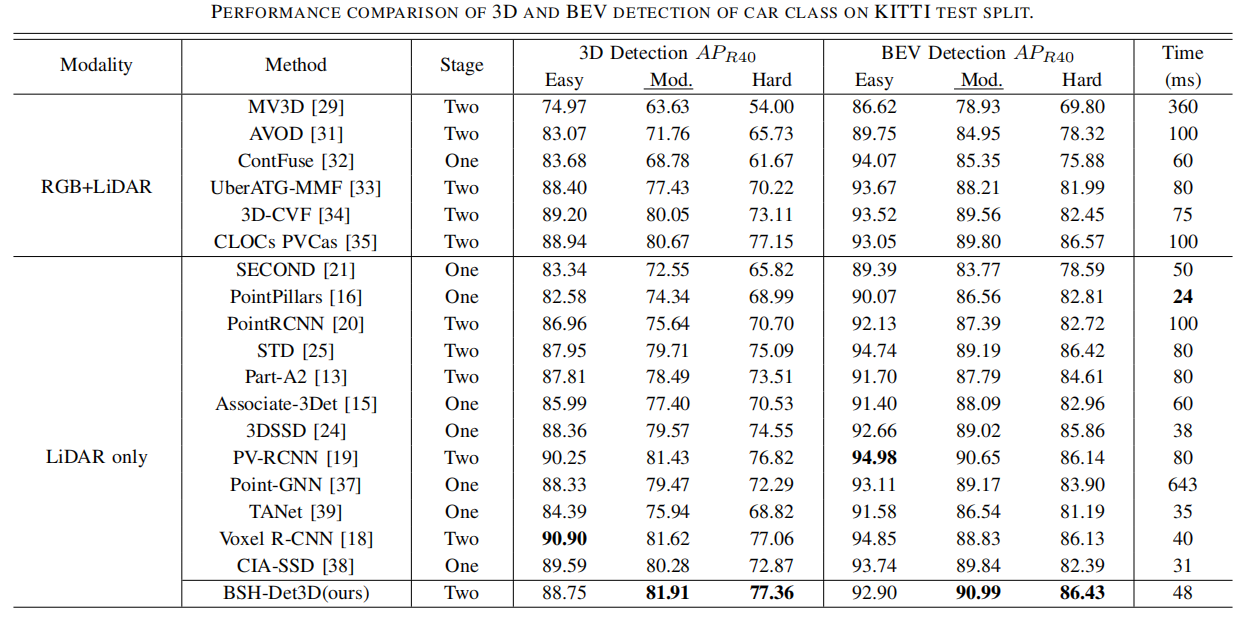
十一、BSH-Det3D(2023)
论文:https://arxiv.org/pdf/2303.02000.pdf
作者单位:东北大学 北京大学 慕尼黑工业大学 Ulster University
1.摘要
基于 激光雷达的三维目标检测 的进展显著地促进了自动驾驶和机器人技术的发展。然而,由于激光雷达传感器的局限性,物体形状在遮挡和远处区域出现恶化,这给三维感知带来了根本性的挑战。现有的方法估计了特定的三维形状,并取得了显著的性能。然而,这些方法依赖于广泛的计算和内存,导致准确性和实时性能之间的不平衡。为了解决这一挑战,我们提出了一种新的基于激光雷达的三维目标检测模型BSH-Det3D,该模型采用了一种有效的方法,通过从鸟瞰图(BEV)估计完整的形状来增强空间特征。具体来说,设计了基于柱子的形状补全(PSC)模块来预测柱子是否包含物体形状的占用概率。PSC模块为每个场景生成一个BEV形状的热图。在与热图集成后,BSH-Det3D可以提供形状恶化区域的额外信息,并生成高质量的3D建议。我们还设计了一个基于注意力的密集融合模块(ADF),以自适应地将稀疏特征与热图和原始点关联起来。ADF模块集成了点的优点,而形状知识的开销可以忽略不计。在KITTI基准测试上进行的大量实验,在准确性和速度方面实现了最先进的(SOTA)性能,证明了BSH-Det3D的效率和灵活性
2.introduction
三维点云可以提供更多的几何、形状和尺度信息,显著提高了场景感知能力。由于高精度的测量和对照明变化的鲁棒性,激光雷达传感器已被广泛用于获取自动驾驶、移动机器人和增强现实/虚拟现实中的三维点云。虽然激光雷达传感器有这些优势,但由于两个固有的限制,在点云中实现高性能检测仍然具有挑战性:
- 激光束在击中第一个物体后返回,导致遮挡物后面的形状丢失。
- 遥远的物体在其表面上只接收到几个点,所以在远距离区域的形状将是稀疏的和不完整的。
这两种限制都会导致检测过程中的形状恶化。为了解决这个问题,Xu等人[9]通过手动GroundTruth 完成整个形状,几乎所有的物体都被正确地检测到(平均精度>99%),证明了完整的形状对于高性能探测器是必不可少的。缓解形状缺失问题的一个直接方法是从先验中学习对象形状: SPG [10]和BtcDet [9]手动将点填充到标记的边界框中,并尝试恢复对象的特定形状。然而,由于它们关注于整个三维形状,这些方法的计算成本是昂贵的。其他方法将形状信息转换为特征,而不是特定的形状[13]-[15],以减少计算。然而,由于形状特征的提取和融合导致了较低的精度,这一点具有挑战性。
01.基于激光雷达的三维目标检测器
根据点云的表示方式,基于激光雷达的三维目标检测可以分为基于点的方法和基于网格的方法。基于点的方法继承了特征提取模块的成功,并提出了不同的架构来直接从原始点检测对象。PointRCNN 通过PointNENt++分割点云,并估计每个前景点的建议。STD提出了一种基于点的提案生成范式与球形锚点,以减少计算。3DSSD结合了基于特征和基于点的采样来改进分类。基于网格的3D检测器首先将原始点转移到离散的网格表示中,如体素和柱子;然后,检测器使用二维或三维卷积神经网络从网格中提取特征,并从网格单元中检测对象。VoxelNet将点云划分为三维体素,并通过体素特征提取器和三维CNN编码器网络进行进一步处理。Second引入了稀疏三维卷积,以实现高效的体素三维处理,显著提高了实时性能。Pillar 将原始点折叠成垂直的柱子。
02. 三维物体检测的形状先验
许多先进的3D探测器专注于通过使用形状先验来缓解形状缺失的问题。有一类方法试图将形状知识作为特征来学习:Part-A²应用一个part aware 阶段来获取对part location。SASSD 和allee-3Ddet旨在利用结构模块通过辅助网络来保存形状特征。然而,由于提取和融合形状特征的困难,这些方法存在精度瓶颈。另一类方法可以恢复对象的特定形状: SPG 定位前景区域,并为每个前景体素生成语义点。BtcDe可以找到与先验相似的形状,并生成新的形状点。由于对整个三维形状的估计,这些方法消耗了大量的计算和内存,导致精度和实时性能之间的不平衡。
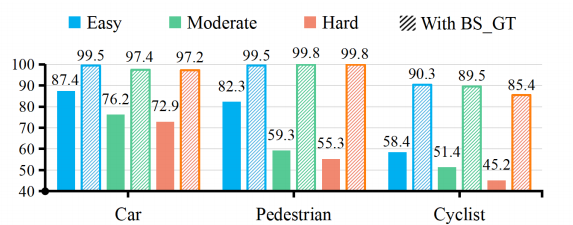
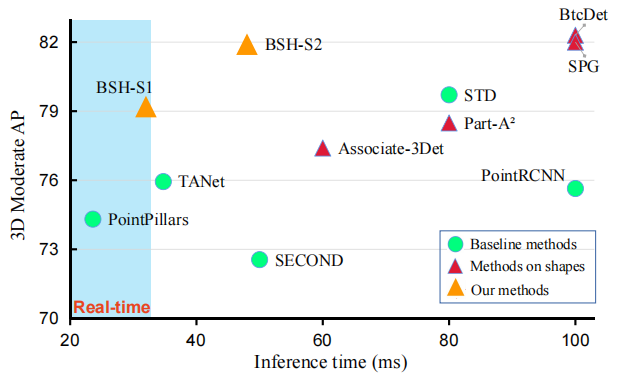
探测器如何在保持效率和灵活性的同时减轻形状的退化? 为了解决这一挑战,我们选择了基于bev的方法,因为其速度和精度性能,例如,pillar。这些方法将点编码成伪图像,并使用成熟的二维卷积来提取特征。我们进行了一项初步研究,以探索具有BEV形状的探测器的可能性。我们将GroundTruth 的BEV形状设计为热图(详见III-B)。然后,我们直接将热图与由基线检测器提取的原始点特征连接起来,训练和评估后展示了具有遮挡的汽车、行人和骑自行车者的平均精度(AP)。如图2所示,随着BEV形状热图的融合,性能显著提高,显示了利用BEV形状增强检测的潜力
- 提出了一种新的三维物体探测器,它可以学习从鸟瞰图中关联物体形状知识,增强空间特征,并为检测提供隐式指导。
- 设计了一个基于柱的形状补全模块(PSC)来估计每个场景的基于概率的形状热图,有效地减轻了形状的恶化。
- 设计了一个基于注意力的致密化融合模块(ADF),它可以适应形状和点云的稀疏特征,其开销可以忽略不计。
- 我们提出的BSH-Det3D在KITTI基准上实现了SOTA性能。我们还用不同的基线检测器来测试我们的方法,以验证其灵活性

3. Methodology
1. 模型概述
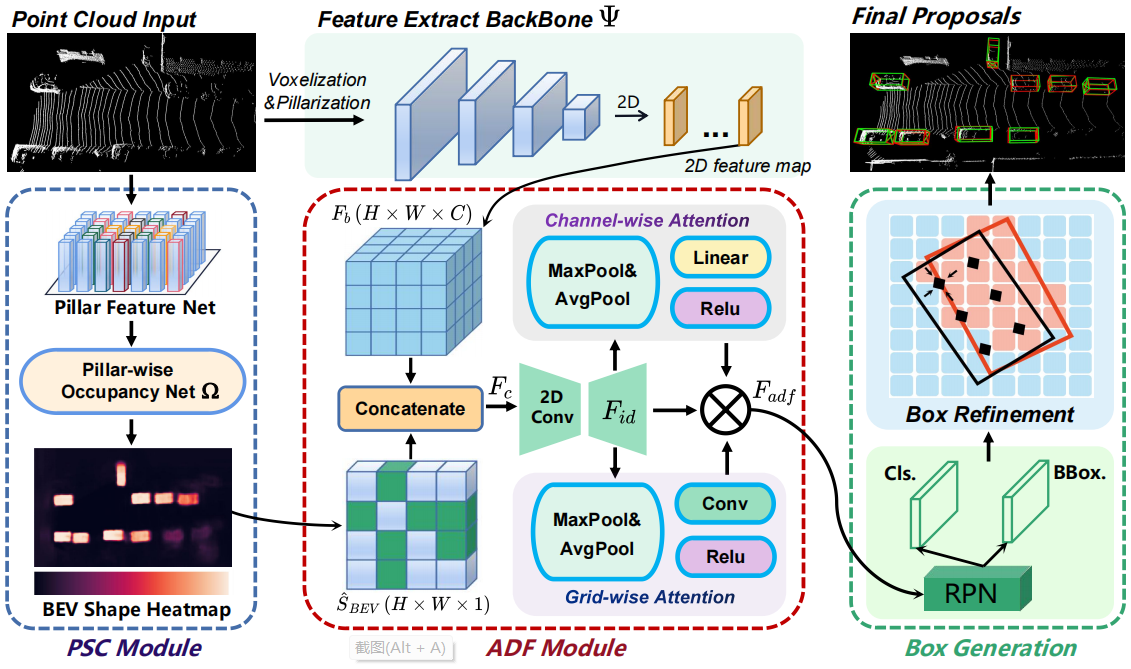
如图所示,PSC模块首先分层划分原始点,并利用pillar-wise占用网络估计BEV形状的heatmap SBEV。接下来,BSHDet3D使用一个骨干网络Ψ来提取点云的特征Fb。为了关联形状知识,ADF模块将SBEV与Ψ的输出特征连接起来,得到Fc;然后,我们使用一种基于混合注意的策略来得到融合特征Fadf。最后,Fadf被发送到一个RPN,生成3D提案。在框细化过程中,构建覆盖每个proposal的local grid,并使用形状热图聚合网格特征,以生成最终的proposal。
2.Pillar-based Shape Completion模块
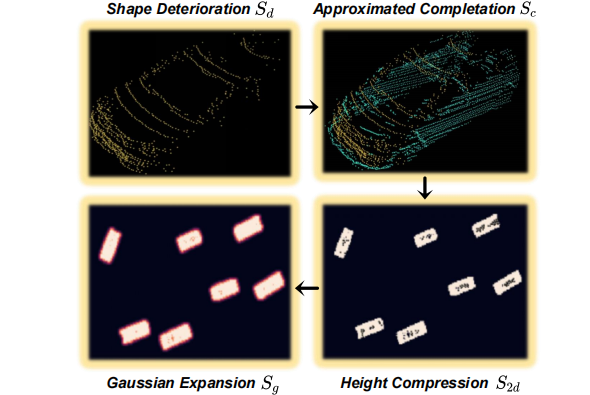
生成新的GroundTruth。BEV形状标签的生成过程如下图所示。首先,我们遵循[Behind the curtain: Learning
occluded shapes for 3d object detection]中的方法,使用基于启发式的策略,以找到数据集中与当前形状Sd最相似的前三种形状。在组装了相似的形状后,可以得到近似的三维形状Sc。接下来,我们压缩Sc的高度维数,得到相应的二维形状S2d。在S2d中,我们为包含形状的柱子设置形状占用概率P(Os)= 1,为其他的柱子设置P(Os)= 0。当多个对象被组装成Sc时,点密度发生变化,导致S2d中的空洞。为了抵消这一点,我们通过span location pxy增加了对P(Os)= 1处的S2d的积极监督,其中P(Os)= 1具有高斯核:
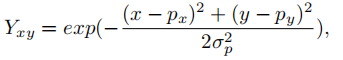
其中,σp是一个根据目标大小决定的自适应标准偏差。最后,用Sg作为BEV形状热图的地面真实标签。
BEV形状热图的估计。首先,我们采用pointpillar策略提取柱特征: PSC模块通过一个小的pointnet[22]投影到X-Y平面上的原始点来获取柱特征fp。然后,用柱状形状的占用网络Ω对fp进行处理(下图)。Ω采用自上而下的架构,使用1×、2×和4×卷积块处理fp,结合转置二维卷积进行上采样,然后连接检测头的多尺度特征。检测头采用3×3个卷积层,由ReLU和批Norm分隔。最后一个卷积层产生一个显示形状占用概率的k通道热图Yˆ(k表示对象类)。为了突出显示形状,使用阈值(≥0.5)的sigmoid函数过滤Yˆ。得到估计的BEV形状热图SˆBEV。sigmoid focal loss监督Ω的输出,如果Yxy = 1:
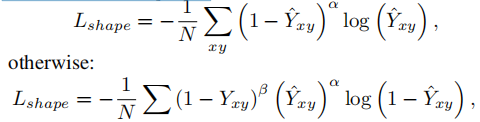
N是P(Os)=1的个数。由于PSC模块只涉及快速的二维卷积和MLP,保证了检测效率。
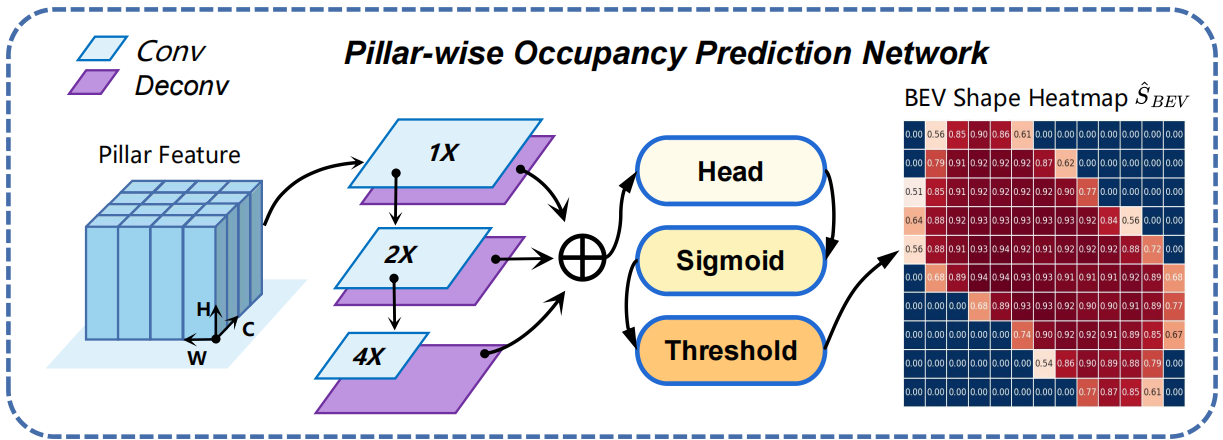
3. 基于attentin的密集化融合模块
物体形状的某些部分显著地决定了其性能,值得更多的关注。利用一种有效的基于混合注意力的ADF模块进行自适应特征细化。ADF模块,针对SˆBEV和Fb的稀疏性,拼接特征Fc首先通过二维卷积层进行密集化,使初始密集的融合特征Fid可用。ADF模块由通道注意和网格注意组成(平均池和最大池),通过求和来合并特征映射,然后是一个sigmoid函数。
4. 一阶段和两阶段的BSH-Det3D
选择关注精度或速度,backbone 采用两种方法来编码原始点。关注速度,采用pillar化;关注精度,采用voxelNet。
一阶段:RPN采用ADF模块的输出特征,基于anchor,对BEV特征图的每个像素预测两个0◦,90◦的anchor。每个proposal包含8个参数:中心坐标(xp、yp、zp)、盒子尺寸(lp、wp、hp)、偏航旋转角θp和分类置信度cp
两阶段:基于从第一阶段学习到的建议和网格特征,细化模块再次利用BEV的形状热图:每个box都需要考虑附近的几何结构,以生成准确的proposal。设计了roi-网格池策略。对于每个proposal,构建6×6×6的局部网格来捕获相邻体素特征之间的上下文信息,通过双线性插值将BEV形状热图SˆBEV汇集到附近的网格上,并通过融合多个层次的Fadf将其聚合。然后,利用MLP的两个分支来预测与iou相关的类置信度得分和三维proposal与groundtruth界框之间的残差。
总结
提示:这里对文章进行总结: