今天读的这篇是PV-RCNN。因为其把点云特征和体素特征融合起来了,觉得很有趣,固来细看一下。
PV-RCNN: Point-Voxel Feature Set Abstraction for 3D Object
效果很好,但是速度大概在13FPS左右(SECOND在40左右,pointpillar在60左右),还是比较慢的。
毕竟继承了二阶段的优点,也就要承担二阶段的缺点。
论文:https://arxiv.org/pdf/1912.13192.pdf
Code:https://github.com/sshaoshuai/PCDet
简述介绍
集成了三维体素卷积神经网络(CNN)和基于PointNet的Set abstraction,以学习更具判别力的点云特征。
提出了roi-grid 与传统的池化操作相比,RoI网格特征点编码了更丰富的上下文信息,用于准确估计对象的置信度和位置
(和faster point rcnn想法类似)
基于体素方法的优势:
其中基于体素的方法具有更高的计算效率,但是丢失了定位精度。
基于纯点方法的优势:
基于点的方法计算成本高,但是具有更大的接收域(上下文信息)
可以结合基于点和基于体素的算法优势,提高三维目标检测的性能
贡献点
1 提出了PV-RCNN框架,该框架有效地利用了基于体素和基于点的方法进行三维点云特征学习,从而在可管理的内存消耗的情况下提高了三维对象检测的性能。
2 提出了体素到关键点场景编码方案,该方案通过体素集抽象层将整个场景的多尺度体素特征编码为一个小的关键点集。这些关键点特征不仅保持了准确的位置,而且对丰富的场景上下文进行了编码,显著提高了3D检测性能。
3 为每个提议中的网格点提出了一个多尺度RoI特征抽象层,该层聚合了来自具有多个感受野的场景的更丰富的上下文信息,用于精确的框细化和置信度预测。
4 提出的方法PV-RCNN以显著的优势优于以前的所有方法,在竞争激烈的KITTI 3D检测基准中排名第一,在大规模Waymo Open数据集上也以较大的优势超过了以前的方法。(作者当时针对于竞赛时仅仅使用了pv-rcnn,且未用过多trick就达到了第一)
简述如下:
1 提出了PV-RCNN框架,基于体素和基于点,且是二阶段
2 体素到关键点场景编码方案,通过体素集抽象层,将整个场景的多尺度体素特征编码为一个小的关键点集。点集中包含了位置信息和上下文信息
3 每个提议中的网格点提出了一个多尺度RoI特征抽象层,该层聚合了来自具有多个感受野的场景的信息
4 效果好
提出了两个新的操作方式:
1 Voxel-to-keypoint scene encoding(对应voxel Set Abstraction Module) 将整个场景特征体积的所有体素汇总为少量特征关键点
2 point-to-grid RoI feature abstraction 有效地将场景关键点特征聚合到RoI网格
整体模型架构图
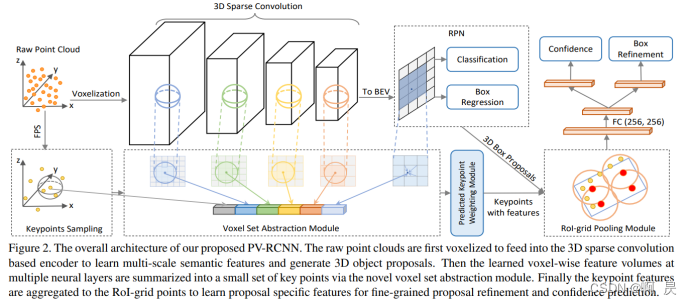
大致步骤如下:
1、将空间中的点云数据体素化,利用稀疏卷积网络进行多次的特征提取下采样。—转到–>步骤3
2、在稀疏卷积网络特征提取的每一层 使用体素特征抓取模块提取多尺度特征。–转到–>步骤4
3、将稀疏卷积网络提取的特征投影到鸟瞰图上,并利用鸟瞰图生成一阶段的目标检测结果。
4、利用体素特征抓取模块得到的多尺度特征对一阶段目标检测结果进行优化得到最终的检测结果。
一阶段 步骤1—>3
二阶段 步骤2—>4
提出了两个新的操作方式:
1 Voxel-to-keypoint scene encoding(对应voxel Set Abstraction Module) 将整个场景特征体积的所有体素汇总为少量特征关键点
2 point-to-grid RoI feature abstraction 有效地将场景关键点特征聚合到RoI网格
阶段一
点云数据体素化提取特征
以下操作对应上述的步骤一
首先将空间中的点云数据进行体素化,其中非空体素的特征被直接计算为所有内部点的逐点特征的平均值。
然后使用3D稀疏卷积提取体素层面的特征,并且通过设置Stride的方式对空间数据进行下采样,最终实现8倍的下采样。
3D稀疏卷积目前具有两种形式(子流型卷积和正常稀疏卷积),作者在论文中没有明说使用的哪种形式,但是从代码来看,是使用子流型稀疏卷积。
这一部分对应原图figure2所示:
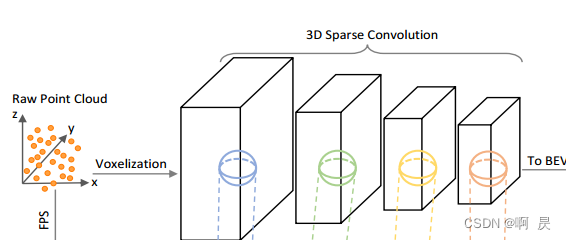
PS 子流型稀疏卷积 :只有当kernel的中心覆盖一个 active input site时,卷积输出才会被计算。代码调用 :spconv.SubMConv3d
对应论文:3D Semantic Segmentation with Submanifold Sparse Convolutional Networks
PS:稀疏卷积相关信息 参考:(2种)稀疏卷积 https://zhuanlan.zhihu.com/p/383299678
参考代码如下:github超链接,第70行所在位置
代码片段如下
self.conv_input = spconv.SparseSequential(
spconv.SubMConv3d(input_channels, 16, 3, padding=1, bias=False, indice_key='subm1'),
norm_fn(16),
nn.ReLU(),
)
block = post_act_block ##集成稀疏卷积模块 ##其中conv_type表示稀疏卷积的类型,默认为子流型卷积,设置为spconv则为正常稀疏卷积
self.conv1 = spconv.SparseSequential(
block(16, 16, 3, norm_fn=norm_fn, padding=1, indice_key='subm1'),
)
self.conv2 = spconv.SparseSequential(
# [1600, 1408, 41] <- [800, 704, 21]
block(16, 32, 3, norm_fn=norm_fn, stride=2, padding=1, indice_key='spconv2', conv_type='spconv'),
block(32, 32, 3, norm_fn=norm_fn, padding=1, indice_key='subm2'),
block(32, 32, 3, norm_fn=norm_fn, padding=1, indice_key='subm2'),
)
转为BEV进行一阶段预测
下面操作对应上面步骤3:
在卷积之后,将特征在Z轴上堆叠实现将特征图投影到2D平面,生成[W/8, L/8]的BEV图。一开始不太理解怎么进行堆叠,后来查找相关代码才了解。如下代码:
N, C, D, H, W = spatial_features.shape #(Bacth_size,channel, Depth, Height, weight)
spatial_features = spatial_features.view(N, C * D, H, W) ###(Bacth_size,channel, Height, weight)
其实就是reshape操作,将D数据(Z轴上特征)与C(体素特征)合并在一起
随后在鸟瞰图的基础上,使用anchor-based的方法生成对检测目标的Propoals和置信度打分。
小结:
这里(步骤1+步骤3)就完成了一阶段的目标检测,即有W/8,L/8个中心点,生成2*W/8 *L/8个框(因为两个垂直角度问题)
思路还是和fast point rcnn(二阶段)一样,通过一阶段简单的得到3D Bbox框。第二阶段需要进行的是对生成的区域的优化和调整。
而PV-RCNN没有像fast point rcnn 那样直接考虑对原始点云信息进行特征提取,而是继续使用体素形式的数据。
如果考虑对原始点云信息会导致时间复杂度过大,固作者这里选用体素。
阶段二
接下来将论文中的3.2 Voxel-to-keypoint Scene Encoding via Voxel Set Abstraction
所有的关键都在于 “关键点” 作为体素特征与优化网络的桥梁
Keypoint Sampling
首先在原始点中通过FPS 选择关键点(但是正如3DSSD说的那样(这篇早于3DSSD),这样提取的点多是背景点,相关信息比较少,如何解决呢?后续—>预测关键点加权模块 这个地方应该参考了fast point rcnn中 的 refinement module )
Kitti数据集中选出2048个点
Voxel Set Abstraction Module.
对从3D CNN特征量(步骤1中的几个稀疏卷积结果)到关键点的多尺度语义特征进行编码。
使用的是PointNet++中所提出的类似聚合方法。但在PN++中,每个关键点聚合的是周围原始点云中一定距离的点特征,而在VSA中,每个关键点聚合的是周围一定距离内的体素的特征。聚合完成之后放入类似于PointNet的结构进行特征提取。
最终,可以得到由步骤1中对应的四个体素块抽象集合特征。
具体的,看论文中的几个公式,及其中字母的相关定义:
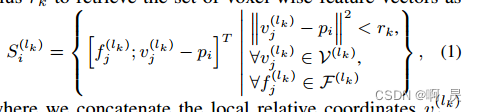
P_i:某个通过FPS提取的特征点,关键点
f_j表示步骤一中第j个体素特征(j=01,2,3)
v_j表示f_j中对应每个体素的位置
N_j 表示f_j中非空体素快个数
看公式右边, 计算 ||v_j -p_i||<r_k 这里是最终保留的体素所要满足的距离约束。注意,这里作者后续讲了设置了多个r_k来保留不同尺度信息
在看左边, 保留的是[每个符合距离约束的高维体素块 和 相对位置 (每个体素块和关键点距离差)
这样我们就得到了体素特征向量集S。接着来提取特征
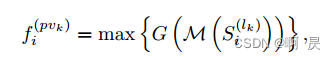 i=0,1,2,3 表示每个体素特征向量集
i=0,1,2,3 表示每个体素特征向量集
其中M表示采样, 从中只保留T_k个高维体素块及相对坐标
G: MLP 用来上采样和进行相对位置编码(位置编码这有点疑问)
Max : maxpooling 进行特征提取
Extended VSA module
作者认为2D的鸟瞰图对Z轴有着更广的感受野(毕竟对Z轴做了投影,而且是全局的,相对于前面的VSA更多的是局部的Z轴特征)
我们将关键点pi投影到2D鸟瞰坐标系,并利用双线性插值从鸟瞰特征中获得特征f(bev)i。
最终得到如下特征: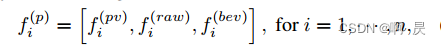
f(pv)是vsa过程得到的4个特征并进行拼接,
f(raw)是 初始点云进行fps提取的点云(进行mlp)
f(bev)是初始点云(只考虑x,y)在Bev上相对位置并双线性插值的特征
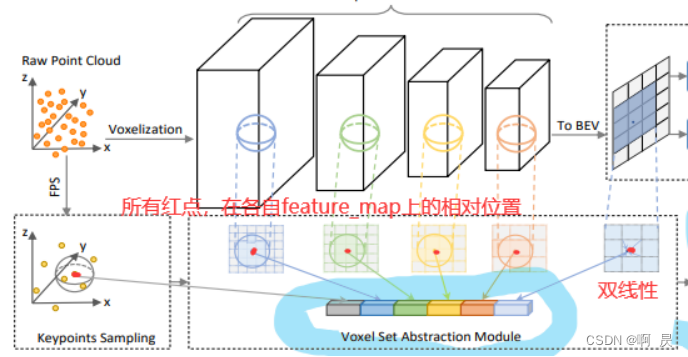
Predicted Keypoint Weighting.
很类似fast point rcnn 中的Network Structure(不同点在与这里是对特征重新加权修正, fast point rcnn是通过特征来筛选所需的 原始点云)
提取的特征点中,肯定存在只包含背景点的信息,这是我们不想要的,属于前景对象的关键点应该对提案的精确细化有更大的贡献,而来自背景区域的关键点的贡献应该更少
因此作者提出了PKW模块
通过额外监督来重新加权关键点特征。

PKW模块通过focal loss进行训练,默认超参数用于处理训练集中前景/背景点的不平衡数量。
如果详细观察可以发现其实只训练了 n256和 n1的两个mlp。
其中Predict可以看作:点云特征通过 2个mlp 并sigmoid得到概率(0–1 float)。可以看作是让两个MLP去学习判断:给出点云特征来推测对应特征点在3Dbbox中的概率。
而Label可以看作 :通过关键点坐标,再根据真实的3Dbbox。判断该点是不是在内部,得到label (0:不在内部, 1: 在内部)
这样 就可以进行 focal loss 训练。 让PKW模块实现 对特征”加权处理”。
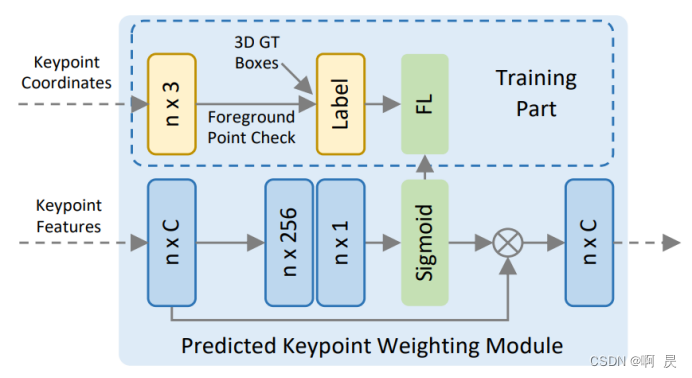
Keypoint-to-grid RoI Feature Abstraction for Proposal Refinement
作者提出RoI-grid pooling 模块以将关键点特征和RoI区域中的点结合起来。这个部分和前面的VSA模块很相似。在每个Propoals中选出 6×6×6=216 个点,称为grid points。将每个grid points视作中心点,使用PN++的方法,聚合周围一定距离内的关键点特征(同样的是多个距离阈值以获得多尺度信息)。
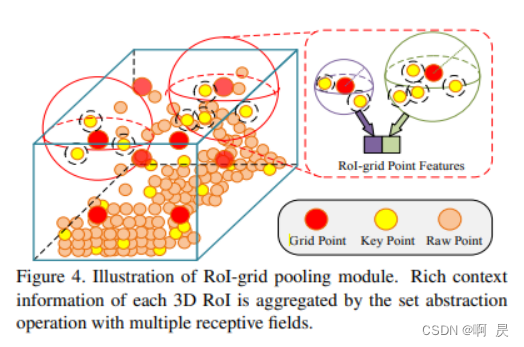
具体的,看论文中的几个公式,及其中字母的相关定义:
这里和VSA对应观看,会发现思想基本一致
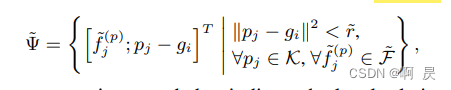
fj:关键点特征
pj:其他关键点的坐标
gi:选取的216中的某一个点坐标
看右边:球半径距离约束。 注意,这里作者后续讲了设置了多个r来保留不同尺度信息
在看左边, 保留的是[每个符合距离约束的关键点的特征 和 相对位置 (每个关键点和gi关键点距离差)
这样我们就得到了基于gi关键点的 r半径的其他关键点集ф。接着来提取特征
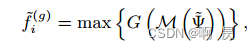
其中M表示采样, 从中只保留T_k个关键点及相对坐标
G: MLP 用来上采样和进行相对位置编码(位置编码这有点疑问)
Max : maxpooling 进行特征提取
3D Proposal Refinement and Confidence Prediction
最终就是上述特征经过MLP去预测anchor的cls和reg

LOSS
Loss_RPN
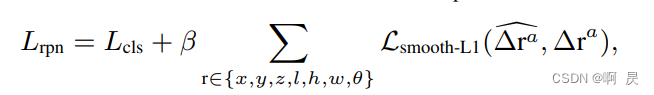
L_cls: 前景和背景的focal loss 二分类
L_reg: smooth_l1损失函数下对框的回归。其中角度的回归参考了SECOND
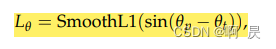
L_rcnn
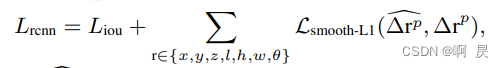
L_rcnn中L_iou
头上有波浪线的表示预测值
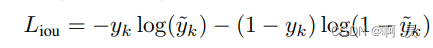
其中y_k计算如下::
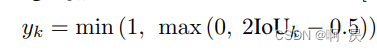
其中的IOU是第一阶段的ROI和真实3D框的IOU值。
L_rcnn中L_reg
与l_rpn中的l_reg一致。是smooth_l1损失函数下对框的回归。
实验结果
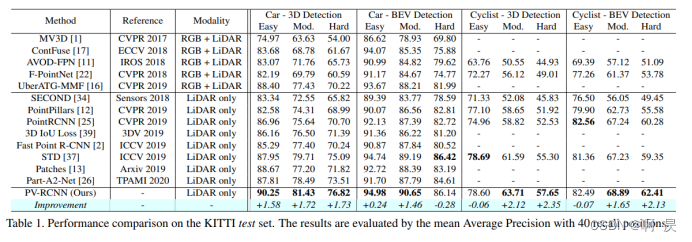
总结
作者:提出了PV-RCNN,一种从点云中精确检测三维物体的新方法。该方法使用本文提出的voxel set abstraction layer集成了多尺度3D体素CNN特征和使用PointNet采集到的特征。并且通过关键点的特征,有效的优化了一阶段检测生成的预测框和评分。在KITTI和Waymo Open数据集上取得了非常优秀的效果。与以前最先进的算法相比,本文提出的voxel-to-point和keypoint-to-grid结构有效显著的提高了三维物体检测的性能。
回顾步骤
1、将空间中的点云数据体素化,利用稀疏卷积网络进行多次的特征提取下采样。->步骤3
2、在稀疏卷积网络特征提取的每一层 使用体素特征抓取模块提取多尺度特征。—>步骤4
3、将稀疏卷积网络提取的特征投影到鸟瞰图上,并利用鸟瞰图生成一阶段的目标检测结果
4、利用体素特征抓取模块得到的多尺度特征对一阶段目标检测结果进行优化。
其中步骤四涉及了
多尺度特征VSA
特征权重优化 prediction Keypoint weighting
roi最终特征点筛选 roi feature abstraction
笔者:全文读下来,感觉通篇都是在围绕关键点做工作。从本文的贡献点即可看出来,从如何提取关键点,到如何聚合关键点周围信息,最后如何利用关键点对一阶段检测结果做优化。本文最大的创新就在这个关键点。不同于Fast Point RCNN,作者没有直接使用PointNet在原始点云上做特征提取,而是始终在体素级数据上做的特征提取。这不仅有效利用了稀疏卷积、体素化表示的优点,还加快了运算速度,也有效结合了Point-based的方法。
参考
知乎中讲解PV-RCNN挺好的文章(本人看完原论文和看的就是这个): https://zhuanlan.zhihu.com/p/435867918
欢迎指正
因为本文主要是本人用来做的笔记,顺便进行知识巩固。如果本文对你有所帮助,那么本博客的目的就已经超额完成了。
本人英语水平、阅读论文能力、读写代码能力较为有限。有错误,恳请大佬指正,感谢。
欢迎交流
邮箱:[email protected]