刚看完3DSSD,在此重新回顾整合下。
3DSSD: Point-based 3D Single Stage Object Detector
推理时间在38ms,比肩 voxel-based的SECOND。速度挺快的,效果在当时也是达到了SOTA。
论文PDF: https://arxiv.org/abs/2002.10187
Code网址: https://github.com/Jia-Research-Lab/3DSSD
基于点云的3D检测的其他论文讲解,后续有时间会继续写。
目录
简述介绍
3DSSD放弃了当时的基于点云方法中不可或缺的所有上采样层(Fp ——feature propagation)和细化阶段(refinement module),以减少巨大的计算成本。
作者新颖地在下采样过程中提出了一种融合采样策略,以使在不太具有代表性的点上进行检测变得可行。
3DSSD是单阶段无anchor的架构
三个贡献点
- 提出了一种轻量级且有效的3D的point-based的单阶段目标检测算法,命名为3DSSD。不同于目前所有的Point-based的检测算法,3DSSD移除了FP层和refinement module(为了提升速度)
- 提出了一种新颖的融合采样策略,保持不同前景实例的足够内部点,进而足够的信息用于回归和分类
- 设计了一个精巧的预测框网络,在多个数据集上跑出了接近Sota的效果,并且速度更快
PS:FP层指的是pointNet++中的类似架构
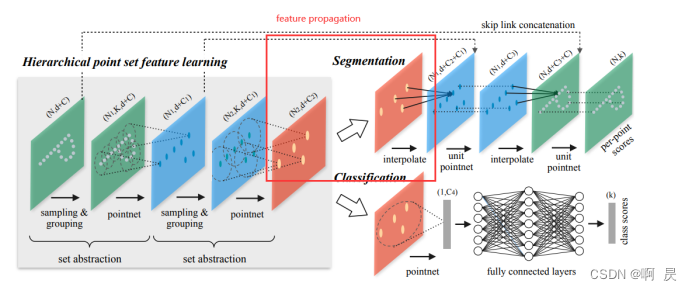
refinement module 指的是fast point rcnn中类似的架构:
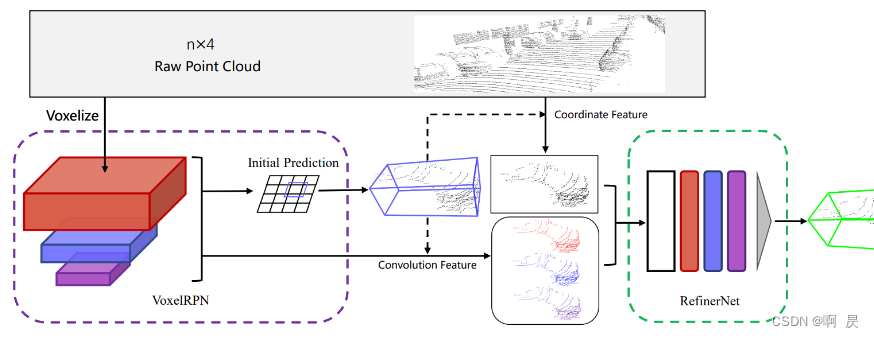
动机,决定移除FP和refinement module
作者认为两阶段算法速度太慢的重要原因是因为存在SA层、FP层和优化模块(refinement module)。三个模块所需要的运行时间如Table1所示:

其中SA层在特征提取阶段是不可或缺的,所以作者决定移除FP层和优化模块,并找到代替方案。
PS:SA层首先是PointNet++提出来的, SA层包含三部分: sampling(采样),group(分组), 局部特征提取(比如Maxpooling)
整体模型架构图
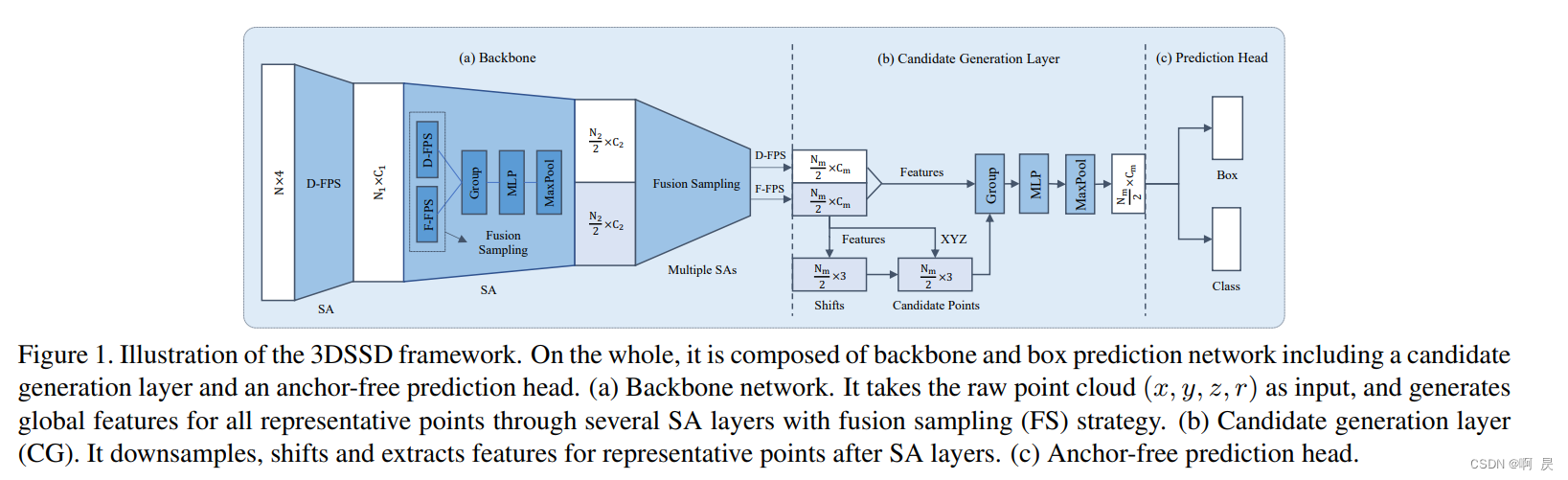
再此简单过一下,后续会详细讲解。由三部分组成:
- backbone。将初始数据特征N*4 变为 Nm *Cm 数据。其中D-FPS, F-FPS后续会讲解
- Candidate Generation Layer。对backbone得到的点再次采样
- Prediction Head 。预测bbox和cls分数
问题(D-FPS局限性)即解决方案:
作者认为以前SA模型架构中的的采样策略----FPS存在着一些局限性。
FPS算法是依靠空间距离进行点的选择(作者再此成为D-FPS),这种方法只考虑了点与点之间的相对位置关系,所以他的采样并不是均匀的,而是更有可能采集到背景点(因为背景点数量多,基数大)。因为它的数量很大,换句话说,有几个前景物体可能在这个过程中被完全擦除,使它们无法被检测到。
对于一些远程实例,它们的内部点不太可能被选择,因为它们的数量远小于背景点的数。
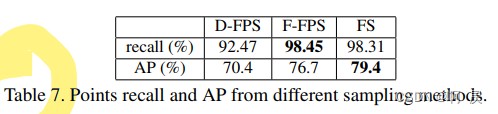
作者进行了测试,通过计算recall值----内部点在采样的代表点中幸存的实例数与实例总数之间的商:如table2所示:
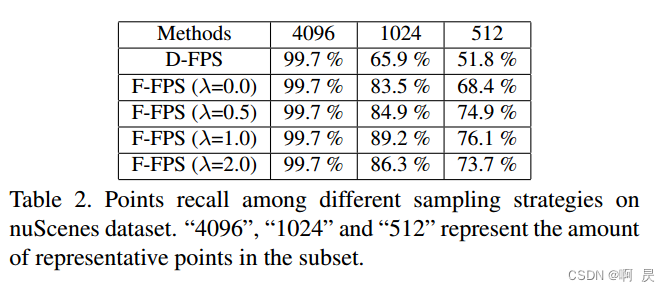
只看第一行,随着采样点的点数下降,实例物体中被采样点的比率严重下降。
比率这么低,为什么PointNet++做点云分割的任务不会太差?---->因为FP模块
在PointNet++的3.4原文中作者这样提及FP块:在集合抽象层中,对原始点集进行子采样。然而,在诸如语义点标记之类的集合分割任务中,我们希望获得所有原始点的点特征,因此引入FP块将特征从子采样点传播到原始点。 这里可以看出FP块的初始意义就是将子采样点进行"上采样",达到原始点的情况,为了弥补D-FPS进行的实例物体点的丢失的缺陷。
新的采样方式 F-FPS
作者注意到,深度神经网络可以很好地捕捉语义信息。因此,利用特征距离作为FPS中的标准,许多类似的无用负点将被大部分去除,比如大量的背景点。即使对于远程对象的点,它们也可以存活下来,因为来自不同对象的点的语义特征彼此不同。
作者又发现:仅将语义特征距离作为唯一的标准将在同一实例中保留多个点,这也引入了冗余。例如,给定一辆汽车,车窗和车轮周围的点的特征之间有很大的差异。因此,两个部分周围的点将被采样,而任何一部分中的点都是回归的信息。
为了减少冗余,增加多样性,于是作者提出了一个新的采样方式F-FPS: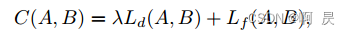
其实就是利用特征距离(Feature )和xyz三维点欧式距离(Distance )通过加权比做为FPS的标准
(如果可以的话我更愿意称之为FD-FPS,仅仅叫F-FPS还以为只根据特征之间的距离进行FPS方法)
其中λ的取值情况在上面 table 2中有所展示
PS: λ=0 表示只使用 Feature-FPS ,会发现效果比纯D-FPS效果好,说明了使用语义特征距离是有效的。
新的 Fusion Sampling方式
PS: SA块由以下组成:sampling (采样)+grouping(分组) +局部特征提取
上面讨论了新的采样方式 F-FPS(特征距离+点距离的FPS)
但单单使用这个采样方式还会有问题:正点(前景点)的数量太多了,背景点的数量太少了。这样有利于回归(生成bbox)操作,但不利于分类操作(背景点太少导致的)。
作者认为,背景点数量太少了,在进行grouping的时候,由于找不到太多的背景点,进而限制了感受野,限制了后续的局部特征提取。
那如何获得更多的背景点呢?这一答案刚好与之前分析呼应,普通的D-FPS的采样策略会带来更少的正点,也就意味着会带来更多的背景点。
于是作者提出使用FS采样策略: 即在SA层期间应用F-FPS和D-FPS,以保留更多的用于定位的正点,并保留足够的用于分类的负点。具体的,分别用F-FPS和D-FPS对Nm/ /2个点进行采样,并将这两个集合一起输入SA层中的以下分组操作。(PS:这里的N_m只最终的采样点总数)
作者后续也进行了消融实验:
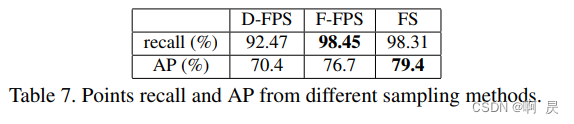
会发现 FS效果> F-FPS >D-FPS 应证了作者对单一F-FPS采样后果的分析。
简单总结:
使用F-FPS采样,会采样到更多的前景点/正点,作者认为这有利于回归的操作。但因为会采样较少的负点,所以会不利于分类的操作(不知道这里为什么作者不采用2017年提出的focal_loss的正负不平衡的分类损失来解决这个不平衡的问题)
使用D-FPS采样,会采样到较多的背景点,作者认为这有利于分类的操作,但不利于回归的操作
于是作者采用F-FPS与D-FPS一起进行,使得点的采样情况对于后续分类和回归的操作达到一个平衡。
Candidate Generation Layer
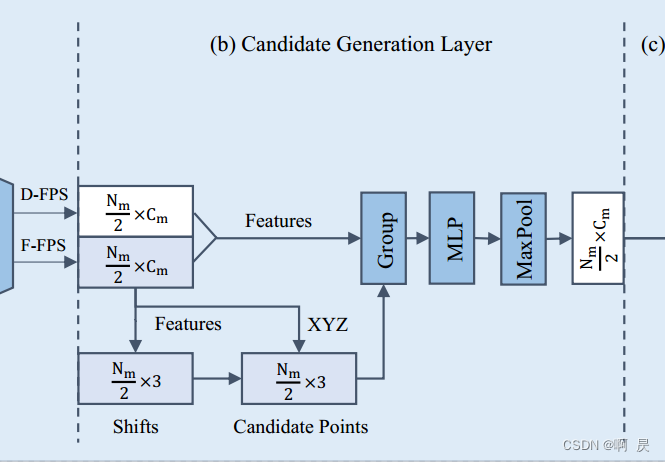
为了进一步降低计算成本并充分利用融合采样的优势,作者在预测头之前提出了一个候选生成层( Candidate Generation Layer CG)
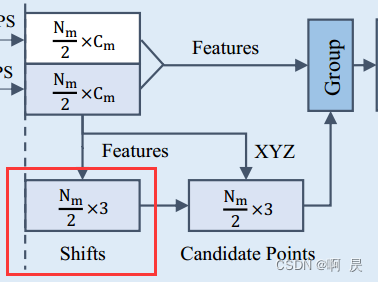
由于上面分析了F-FPS提取的采样的适合后续的回归。于是作者在CG模块这里,选取F-FPS的采样点,作为初始点XYZ,并通过Shift(偏移操作)来得到候选点。并以候选点做为中心点进行后续的group
+局部特征提取操作。

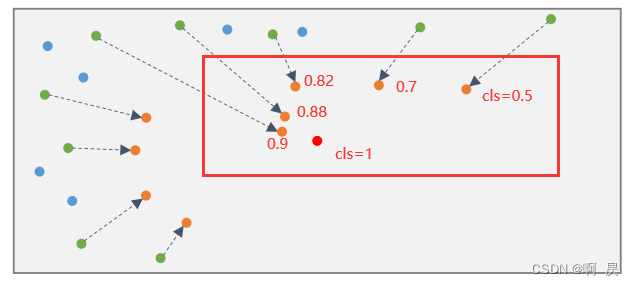
灰色的区域代表一个物体实例,红色点是其中心。蓝点表示前景点下D-FPS采样点,绿点表示前景点下F-FPS采样点。 绿点通过 Shift操作变到橙色的点即候选点。
【【【【后续的loss可以看出这里让模型学习来预测各绿点的shift 来让所有绿点最后都能转移到实例中心点(红色点)】】】】
作者这里把橙色点做为最终的pred_box中心点
接下来,作者从包含具有预定义范围阈值的D-FPS和F-FPS的点的整个代表点集中找到每个候选点的周围点。
简言之就是对于每个橙色的点,对绿色和蓝色的点进行group的操作(存在一定的范围阈值),将它们的归一化位置和语义特征连接起来作为输入,并应用MLP层来提取特征(升维),最后通maxpooling(在点个数的维度上)获得每个橙色点的group的局部特征。
然后再去进行最终的box和cls预测
简单总结:
由于是以橙色点为中心对蓝色和绿色点进行group+特征提取。
绿色的点提供了box的相关信息,最终去预测bbox的相关数据。
蓝色的点提供了较多的背景点,最终去预测cls的信息。
这也就是为什么group的原因(既有蓝点特征能去预测cls,又有绿点特征去预测bbox信息)
Anchor-free Regression Head
在回归头中,对于每个候选点(橙色点),我们预测到其对应实例的距离(Δx;Δy;Δz),以及对应实例的大小(Δl;Δw;Δh)和方向r。由于每个点都没有预先的方向,对于方向的预测是参照Point RCNN中基于Bin+offset的方法,其中N_bin被设置为12(角度是-pi到pi 所以每个Bin是30°)
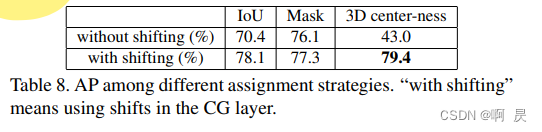
3D Center-ness Assignment Strategy
首先判断点是否在实例内部,得到l_mask(0或1)
然后引入中心度,可以看作是一种软标签,其最大目的就是让模型不去生成很多偏离目标中心的低质量bbox。
想法:假设针对于分类,实例边界上点的分类truth值应该要低于实例中心点周围的分类truth值。而不是:落入实例内部的点的分类值都是1。外部都是0.
譬如举个例子:
这一思想借鉴于FCOS(文末有相关讲解网址)。
中心度是衡量边界与目标中心的归一化距离中心度反应了某一个点到真实框中心的(标准化)距离,

如上图所示,越靠近实例中心,该中心度越大(热力图越红),越远离小(热力图越蓝)。
其计算公式如下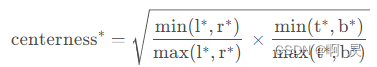
作者在此进行从2D到3D的推广:

表示候选点(橙色点)到实例3D框的中心度。其中f,b,l,r,t,d表示候选点到实例3D框前后左右上下的距离。
中心度的最终应用:
训练时: 最终分类标签就是 l_ctrnessl_mask。
测试时: 对预测bbox打分时 score_final=socre_prec中心度
Loss

1.所有点的分类损失,采用交叉熵损函数
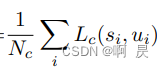
s_i: 预测分数
u_i: l_ctrness*l_mask 中心度分类标签
2.只针对于正样本的3Dbbox回归损失,其中包括loss_dist,loss_size,loss_angle,loss_corner。
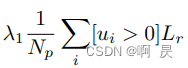
loss_dist:中心点坐标的回归的损失,采用smooth_l1损失函数
loss_size:回归bbox的whl的损失。采用smooth_l1损失函数。
loss_angle角度损失:通过Bin+residual预测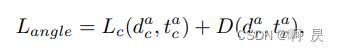
前:bin的分类损失,交叉熵损失函数
后:residual的回归损失,
loss_corner角点损失: 欧氏距离损失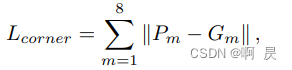
G_m: 真实框的8个角点坐标
P_m: 预测框的8个角点坐标
3.loss_shift:偏移(shift)损失,只针对于F-FPS采样的正样本
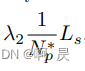
偏移(shift)损失应用在候选点生成(CG层中)的监督任务中,作者利用了smooth-l1损失函数来计算。其中,label值是蓝色点到红色点的偏移。预测值为红框中的shift值。 就是蓝色到各橙色点的值。
Kitti数据增强
- mix-up strategy 和SECOND一样
- bbox反转 -pi/4 — pi/4 并加上随机偏移 Δx,Δy,Δz
- 每个点云沿着x轴随机翻转
- 围绕z轴(向上轴)随机旋转每个点云,并重新缩放它
其他数据的相关操作没有细看,在此不做讲解。
消融实验
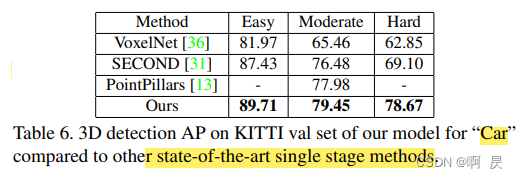
不同单阶段方法间的比较( 车 )
不同融合采样策略
CG模块中是否使用shift
5个模型推理时间的比较

3DSSD和基于体素的second的时间差不多。作者还提到如果使用tensorRT加速的话,还可以更快。
总结
- 提出了一种轻量级、高效的基于点的三维单阶段目标检测框架。
- 提出一种新的融合采样策略(F-FPS),以去除所有现有的基于点的方法中耗时的FP层和细化模块,来减少推理时间。
- 在预测网络中,为了进一步降低计算成本并充分利用下采样的代表点,设计了Candidate Generation Layer
- 提出了一个带有3D中心度标签的无锚回归头,提升模型的性能。
所有上述精细的设计使3DSSD模型在性能和推理时间方面都优于所有现有的3D单阶段检测模型。
参考:
另一篇讲解3DSSD挺好的文章: https://zhuanlan.zhihu.com/p/435541315
FOCS讲解的文章: https://blog.csdn.net/weixin_46142822/article/details/123958529
欢迎指正
因为本文主要是本人用来做的笔记,顺便进行知识巩固。如果本文对你有所帮助,那么本博客的目的就已经超额完成了。
本人英语水平、阅读论文能力、读写代码能力较为有限。有错误,恳请大佬指正,感谢。
欢迎交流
邮箱:[email protected]