点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达

论文题目:
MPPNet: Multi-Frame Feature Intertwining with Proxy Points for 3D Temporal Object Detection
论文链接:
https://arxiv.org/abs/2205.05979
代码链接:
https://github.com/open-mmlab/OpenPCDet
本文介绍收录于ECCV2022的最新多帧雷达点云目标检测框架:MPPNet(Multi-Frame Feature Intertwining with Proxy Points)。截止目前,MPPNet算法在Waymo Open Dataset 测试集榜单上排名第一,且代码已开源。为了利用多帧雷达点云信息,MPPNet引入了在物体轨迹的多帧边界框(trajectory-proposal)中均匀分布的代理点(Proxy Point),以之为媒介,在三个不同金字塔层级 (单帧层级,组内层级以及组间层级)中进行信息编码和传递,有效的利用了多帧点云蕴含的时序信息,大幅提升了3D目标检测的性能。

1. 研究背景
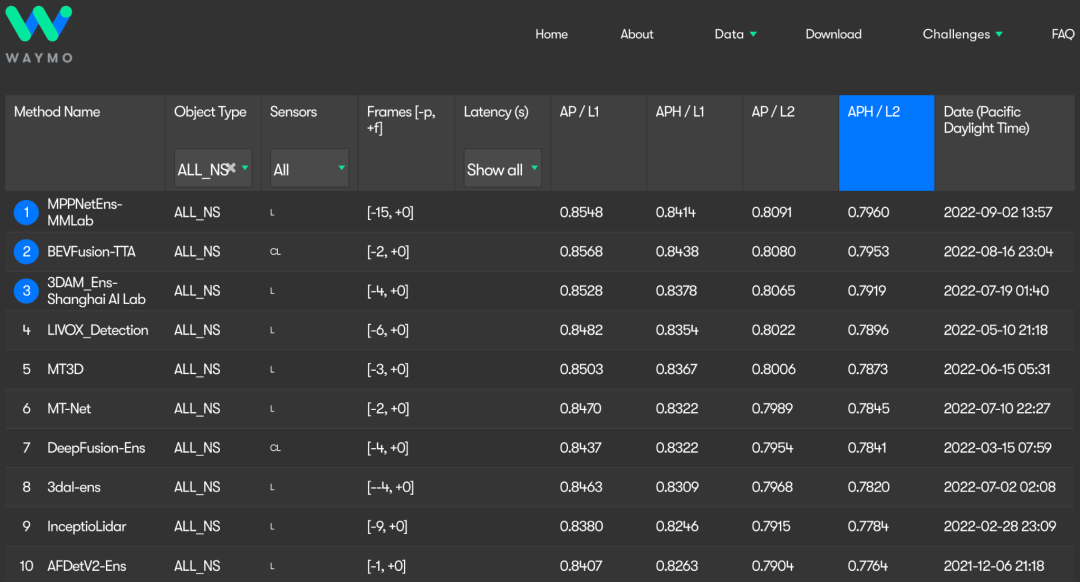
从雷达点云中检测三维物体是自动驾驶场景感知的一项重要任务。但是激光雷达每次只能捕捉场景的一个局部视图,导致单帧点云里物体点的分布总是不完整的。在自动驾驶场景中,随着车辆的移动,传感器会不断生成包含同一物体的点云序列。因此,充分利用多帧点云序列可以得到更为完整的物体结构和位置信息,进而得到更为精准的检测结果。将多帧点云直接拼接是利用时序信息的最简单策略,目前的研究已表明该策略可以提高检测器的性能,但是仅适用于非常短的序列(如2-4帧)。当输入序列变长时,检测器性能相对于短序列反而下降,表1 展示了CenterPoint算法在Waymo验证集上直接拼接不同长度输入序列的检测性能。

表1:CenterPoint以不同长度的拼接序列作为输入,在Waymo验证数据集上的性能
如上表所示,相对于单帧输入,CenterPoint在4帧拼接序列下检测性能有明显的提升。但是继续增加拼接序列的长度,其性能反而会逐渐下降。本文作者认为,在长序列拼接点云中,由于物体移动导致的长尾拖影的多样性和复杂性会影响网络对物体位置的精准感知,如下图所示。
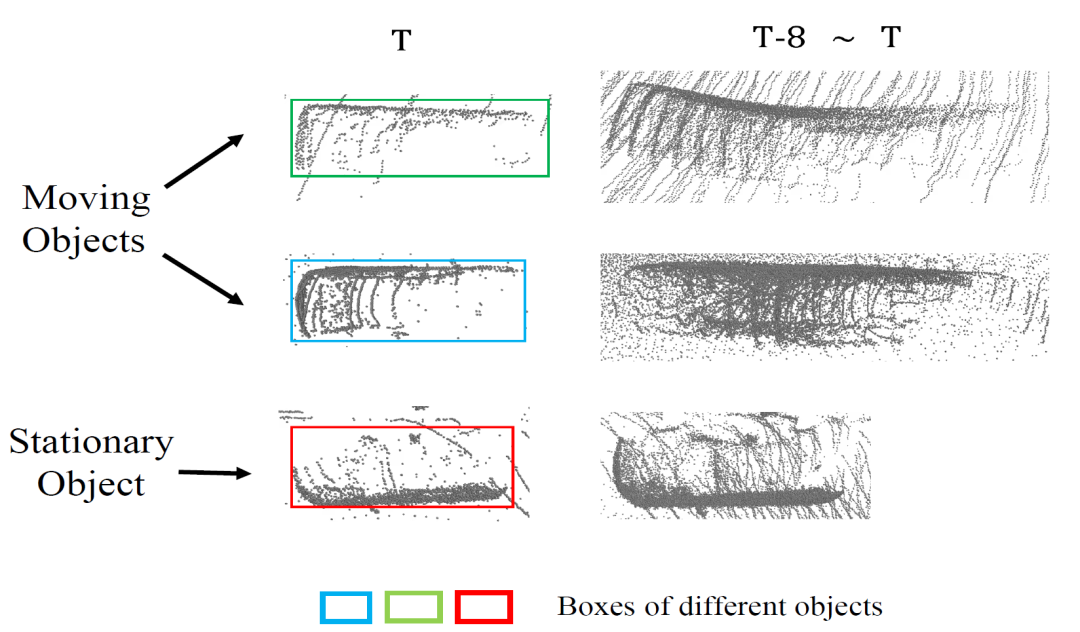
图1:拼接的8帧点云序列中不同物体点的分布
因此,如何更有效的利用多帧点云的时序信息,提高多帧点云3D检测器的性能是本文要解决的主要挑战。
2. 方法
MPPNet的网络整体框架如图2所示。作为一个通用的二阶段时序检测器, MPPNet首先通过一阶段的RPN网络得到初始的逐帧proposal,利用IoU匹配得到在过往时段的运动轨迹(3D Proposal Trajectory),并利用得到的轨迹,从原始多帧点云里扣取感兴趣的前景点,即物体点云序列(Object Point Sequrnce),二者即为MPPNet的输入。
为了有效地利用输入数据的时序信息,MPPNet提出在三个层级上,即单帧层级、组内层级以及组间层级,进行特征融合。具体来说,单帧层级(Per-Frame Feature Encoding)主要用于对逐帧几何结构以及运动轨迹进行编码。在得到每帧的特征后,为了减小多帧融合的计算和显存代价,长序列被分成了若干组。组内层级 (Intra-group Feature Mixing) 用于负责融合每个组内的点云信息,而组间层级(Inter-group Feature Attnetion)致力于对整个序列,即所有组之间进行信息传递和整合。得益于作者提出的三层级特征融合策略,MPPNet可以充分利用输入序列的时序信息,得到比单帧检测器更为精确的结果。下面对每个层级进行更详细的介绍。
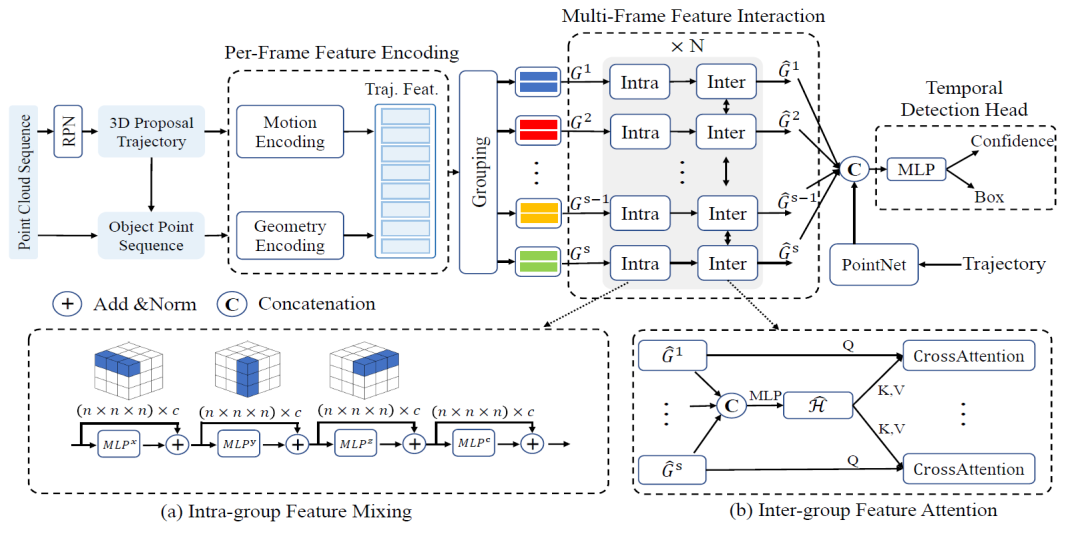
图2:MPPNet 整体框架图
单帧层级(Per-Frame Feature Encoding)特征编码。由于雷达的物理特性,一个物体在不同帧的点云的数量是变化的且没有确定的跨帧对应关系,不利于高效地进行时序信息交互。为了解决该问题,作者提出了使用一系列代理点(Proxy Point),其是放置在物体的每帧边界框内相对固定位置,且均匀分布的一系列虚拟点。代理点的特征会自动地对齐物体在多帧上的相对位置,为后续的时序特征融合提供了便利。基于代理点还可以将特征进一步解耦为几何特征和运动特征(如图3所示),几何特征用来编码物体在该时刻的点云结构信息,运动特征则用来编码同一物体在不同时刻的运动轨迹。

图3:解耦合的候选框序列中点云几何特征和运动特征编码
此时,如果直接对整个序列的代理点进行特征融合,会面临计算量以及GPU显存消耗,随着输入序列长度增加而成比例增加的问题,极大的限制了网络对长序列的处理能力。
为了解决该问题,作者提出一种分组策略,将长序列均匀分成若干组,每组包含一个无交叠的短序列。在特征融合的过程中,先在组内代理点之间进行特征交互(intra-group fusion),再在不同组之间的代理点进行信息传递(inter-group fusion),通过交替地进行组内与组间特征融合,可以有效地编码长序列中丰富的时序信息。
在组内层级(Intra-group Feature Mixing), MPPNet通过一个简单的MLP对组内的代理点特征进行压缩。接着网络使用了3D MLP Mixer,在XYZ和特征通道四个维度,依次使用不同的MLP在对应维度上进行特征融合,实现组内不同代理点之间进行特征融合,具体设计如下图所示。
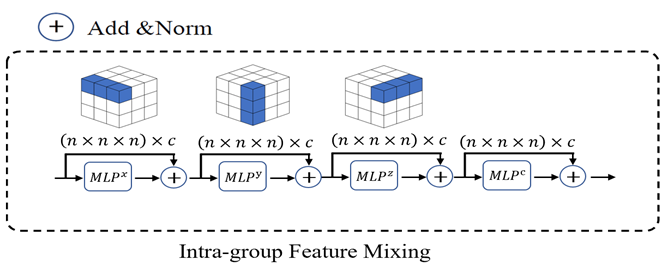
图4:组内特征融合模块
对于组间层级(Inter-group Feature Attnetion),前述组内特征交互使得每个代理点都融合了该物体在组内短序列中的结构和运动信息,为了进一步整合整个序列的时序信息,MPPNet提出了基于跨注意力的组间特征融合模块,如图5所示。
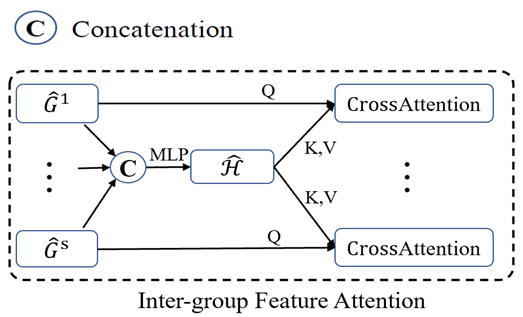
图5:组间特征融合模块
为了减小组间特征融合时的计算代价,该模块用MLP将所有的组特征融合为一个全局共享的Key和Value特征,然后每组特征均作为Query,通过注意力机制,从全局共享的Key和Value特征中筛选有用的信息,以更新组内特征。MPPNet通过交替地进行组内和组间特征融合,有效的利用了时序点云特征来获取物体更精确和全面的信息,提升3D物体检测。
最后,MPPNet 使用基于Transformer的时序检测头来预测最终的边界框。其使用一个从零初始化的向量作为Query,通过注意力机制来聚合每个组内所有代理点的特征,并将所有组聚合后的特征向量连同轨迹分支提取的向量在通道维度进行拼接,得到物体在该序列下的总表征,进而得到最终的检测结果。
3. 实验结果
3.1 Waymo 数据集性能
MPPNet在Waymo Open Dataset 训练集上进行训练,在其验证集和测试集上的性能如下表所示。
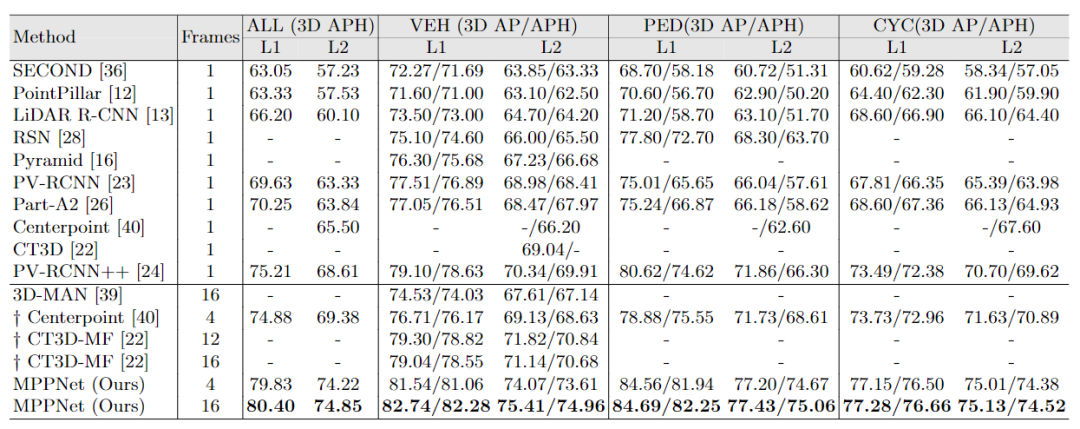
表2: 不同方法在Waymo 验证集上的性能比较
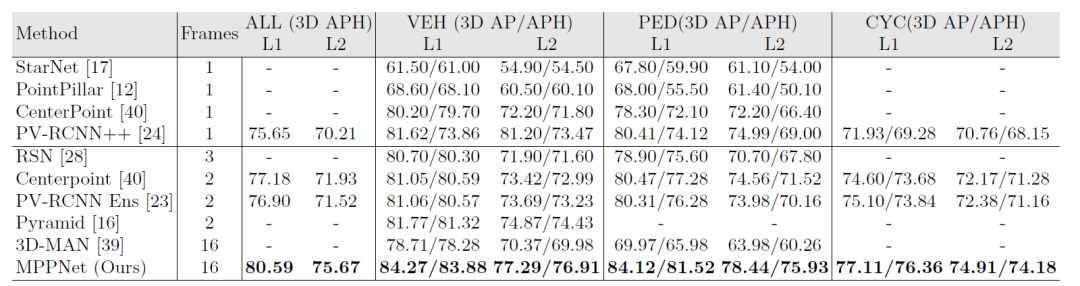
表3:不同方法在Waymo测试集上的性能比较
从表中结果可以看出,无论是和单帧还是多帧的基线方法比较,MPPNet都取得了明显的性能涨幅。(注:表2和表3中MPPNet的结果均未使用TTA(test-time-augment)以及模型集成(model ensemble))
3.2 消融实验
1)时序长度
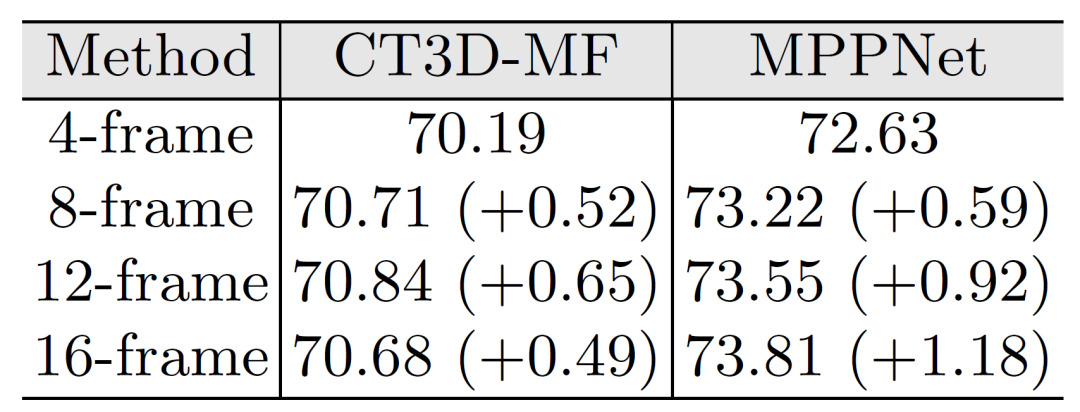
表4:不同输入长度对MPPNet的性能影响
为了验证MPPNet对时序信息融合的有效性,该文以不同长度的输入序列进行了消融实验。如表4所示,其中CT3D-MF是作者基于CT3D拓展,能够处理多帧点云的二阶段检测器。为了公平比较,二者均采用相同的RPN网络,相比于单阶段的CenterPoint,CT3D处理长序列的能力有所提升(最高性能在12帧),但是继续增加序列长度,其性能依旧会下降。而MPPNet则更有效的利用了多帧时序信息,其性能随着4帧-16帧输入序列的增加而逐步提升。
2)模块增益
表5展示了每个模块更为详细的消融实验结果,可以看到文中采用的模块均对性能有增益,每个模块的具体分析可以参见论文。
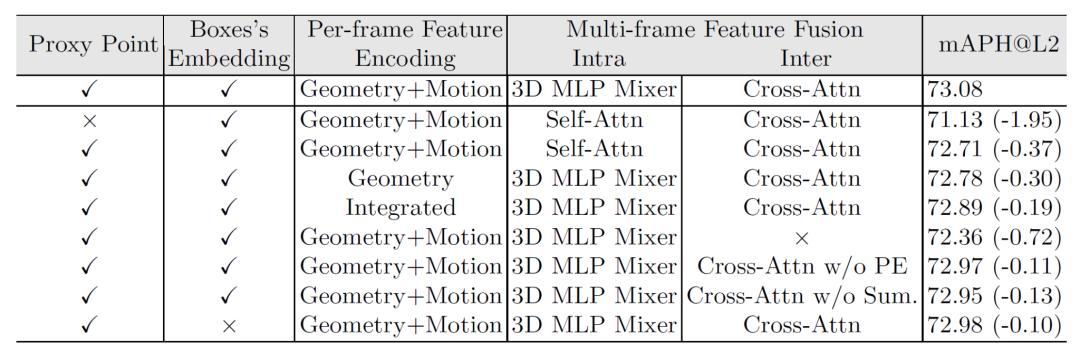
表5:MPPNet各个模块的详细消融实验
最后,采用TTA以及model ensemble策略,MPPNet成功登顶Waymo Open Dataset 3D检测榜榜首,其代码已开源,代码链接见文首。
4. 参考文献
[1] CenterPoint: Center-based 3D Object Detection and Tracking
[2] CT3D: Improving 3D Object Detection with Channel-wise Transformer
MPPNet 论文和代码下载
后台回复:MPPNet,即可下载上面论文和代码
3D目标检测交流群成立
扫描下方二维码,或者添加微信:CVer222,即可添加CVer小助手微信,便可申请加入CVer-目标检测或者Transformer 微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer等。
一定要备注:研究方向+地点+学校/公司+昵称(如3D目标检测+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲扫码或加微信号: CVer222,进交流群
CVer学术交流群(知识星球)来了!想要了解最新最快最好的CV/DL/ML论文速递、优质开源项目、学习教程和实战训练等资料,欢迎扫描下方二维码,加入CVer学术交流群,已汇集数千人!
▲扫码进群
▲点击上方卡片,关注CVer公众号整理不易,请点赞和在看