文章对于初次接触Action Detection的人来说有一定理解难度,例如在网络结构的讲解方面,如果不了解S3D或者没有对文章结构以及网络图进行全局把我可能会出现一些不好理解的地方。因此做了一个详细、通俗的文章梳理。有了一个整体的理解后,在一些次要的细节方面可以再去原文中对应出找出。
paper:
ECCV 2018 Open Access Repository
在看这篇文章之前最好先去读一下S3D网络和Faster-RCNN的文章或者相关博客。
1. Introduction
文章的出发点是很多动作时空定位网络只在actor的proposal region中做分类,这导致一个问题,有些动作例如像球类运动,即便是人类在不通过视频背景(context information)综合分析也不好给出判断。因此作者希望给出一个actor和视频背景的推理网络,也相当于是加入了全局信息。
下图最左边的两幅图就是一些不利用背景单纯使用proposal region分类的情况,可以看到动作相似并且难以和跳跃运动区分。为此在引入和背景的relation network之后可以看到最右侧,网络构建了actor和object之间的关联性,达到更好的分类效果。

2. Action detection with actor-centric relation network
2.1 Action Detection
下面直接从网络结构入手,下图是文章给出的一个网络结构的overview,初看这个图中众多的连接线可能会有点晕,所以我在图中用红色箭头对网络进行了一个抽象标注,在一开始我们可以不看红色方框里的部分。红色箭头可以说是整个网络的backbone,先理解网络的主干部分然后再去看各分支细节。并且这一节中我们也暂时不用去管actor和context information之间的关系。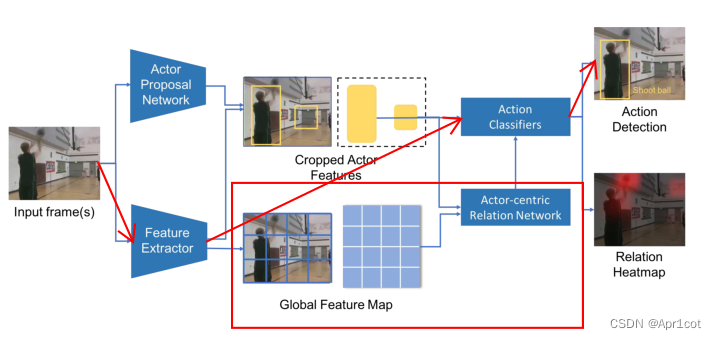
首先在这一节里我们不看红色方框里的部分,网络结构就变得清洗了很多。先只看标注的红色箭头,这一部分可以直接先理解为一个S3D网络(通过网络维度膨胀以及top-heavy的深度分离卷积处理优化后的Inception Net,文中也直接用InceptionNet中的block命名方法如Mixed4d等,若对这部分不清楚的可以去看InceptionNet中的各层结构和命名),网络的输入是关键帧和其时间维度上的一些相邻帧(Feature Extractor为3D网络),输入网络后对其特征进行提取并做出分类。
文章在Architecture Detail中还给出了对于S3D的一些细节修改,比如2D和3D卷积的位置,使用光流情况下所fusion的位置,以及RPN、classificaion等具体结构的位置,可以去
不同的是,S3D网络只用于分类任务,而ACRN网络需要实现动作的时空定位,因此引入了一个Actor Proposal Network,这里实际上用的就是Faster R-CNN中提出的region proposal network(RPN),把RPN网络接在一个2D的特征提取网络(文章用的ResNet50)后面。Actor Proposal Network的输入只有单帧关键帧,不需要引入前后时间信息,因此这一步是个2D的卷积。

但因此出现一个问题就是2D的ROI和3D的feature map维度不匹配的问题,文章中先将3D的feature map通过一个时间维度的卷积核t×1×1进行展平,展平后通过ROIPooling之后得到各ROI区域的feature map然后再将2D的feature map膨胀为3D以便输入3D网络。
到此为止我们就大致厘清了这个网络的整体脉络,这些内容已经可以构成一个完整的时空动作提取网络,并在作者的实验中取得了不错的效果。那么再看这个网络结构的overview,还剩下红色方框内的部分也就是Actor-centric Relations没有讲解。
2.2 Actor-centric Relations
Actor-centric Relations也是文章的一个核心点,通过这个网络实现了actor和context information 的一个全局交互,提升了网络精度,同时也是这篇文章的一个重要出发点。
首先这部分需要得到目标和背景之间的关系,目标由RPN网络已经给出,但显然不能用RPN把背景中的object全部提取一遍然后再去计算他们之间的关联。再者由Token的思想,自然而然会想到可以直接将feature map分块处理再去计算他们之间的关联。可以回顾上面overview中红色方框内的分块操作。

具体的计算而言,可以看到上图中的(b),我们把RPN得到的ROI feature map(在上图中为最左侧的蓝色半透明框,后面的淡蓝色为整张图的feature map,可以看到已经被分块处理)通过ROI Pooling和Average Pooling之后得到一个1×1×1024的特征向量f,用于和feature map背景中的每一块分别计算relation。背景中每一块也提前通过卷积运算得到1×1×832的特征向量F。
为了方便计算,我们把ROI特征向量f复制得到h×w×1024再和背景向量h×w×832通过一个一维卷积实现其关联运算,最后再通过一个3×3的卷积(这个卷积可以使得relation获取领域信息,取得更好的效果)和average pooling得到一个1×1×1024的关系向量。
那么最后也就是把relation network的输出和ROI feature map的输出f进行结合,这里用的concatenate,也就是得到一个1×1×2048的向量,最后再送到classifier和bboxs回归器中得到最终的输出结果。
上述为对文章大致原理的一个解读,主要是帮助初学者更好的理解文章思路和网络结构,若要对网络进行复现,需要去文章或者源码中看一看网络搭建的细节。如有错误之处,欢迎指正讨论。