1 导包
import time
import pickle
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
from collections import Counter
from sklearn.datasets import load_diabetes
from sklearn.linear_model import LinearRegression, Ridge, Lasso
from sklearn.neighbors import KNeighborsRegressor
from sklearn.tree import DecisionTreeRegressor
from sklearn.naive_bayes import MultinomialNB, GaussianNB, BernoulliNB
from sklearn.svm import SVR
from sklearn.neighbors import KNeighborsRegressor
from sklearn.cluster import KMeans, DBSCAN
from sklearn.ensemble import BaggingRegressor, RandomForestRegressor, ExtraTreesRegressor, AdaBoostRegressor, GradientBoostingRegressor, VotingRegressor
from sklearn.neural_network import MLPRegressor
from sklearn.decomposition import PCA
from sklearn.metrics import r2_score, mean_squared_error, mean_absolute_error
from sklearn.preprocessing import StandardScaler, MinMaxScaler, PolynomialFeatures
from sklearn.model_selection import train_test_split, GridSearchCV
from xgboost import XGBRegressor
from lightgbm import LGBMRegressor
from catboost import CatBoostRegressor
from mlxtend.regressor import StackingRegressor
from mlxtend.plotting import plot_decision_regions
2 数据准备
# Pandas设置
pd.set_option("display.max_columns", None) # 设置显示完整的列
pd.set_option("display.max_rows", None) # 设置显示完整的行
pd.set_option("display.expand_frame_repr", False) # 设置不折叠数据
pd.set_option("display.max_colwidth", 100) # 设置列的最大宽度
# matplotlib设置
plt.rcParams['font.sans-serif'] = 'SimHei'
# 加载数据集
dataset = load_diabetes()
X, y = dataset.data, dataset.target
df = pd.DataFrame(data=X, columns=dataset.feature_names)
df = pd.concat((df, pd.Series(data=y, name='target')), axis=1)
df.head(10)

3 数据处理
# 数据处理
scaler = MinMaxScaler()
X = scaler.fit_transform(X)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, shuffle=True)
print(X_train.shape, X_test.shape, y_train.shape, y_test.shape)
4 模型训练
包括18种模型:线性回归、岭回归、Lasso回归、KNN、SVR、决策树、Bagging、随机森林、极限树、AdaBoost、GBDT、XGBoost、LightGBM、CatBoost、Voting、Stacking、MLP
# 训练
def multi_train(X_train, y_train, X_test, y_test, clf_names, clfs):
results_df = pd.DataFrame(columns=['model_name', 'mse', 'mae', 'rmse', 'r^2', 'cost_time'])
count = 0
for name, clf in zip(clf_names, clfs):
t1 = time.time()
print(name)
if name == '多项式回归': # 对多项式回归额外处理
x_train_poly = clf.fit_transform(X_train)
x_test_poly = clf.fit_transform(X_test)
X_train = x_train_poly
X_test = x_test_poly
clf = LinearRegression()
clf.fit(X_train, y_train) # 训练
y_predict = clf.predict(X_test) # 预测值
loss1 = mean_squared_error(y_test, y_predict) # MSE
loss2 = mean_absolute_error(y_test, y_predict) # MAE
loss3 = np.sqrt(loss1) # RMSE
r2 = r2_score(y_test, y_predict) # 决定系数
t2 = time.time()
series = pd.Series({
"model_name": name,
"mse": loss1,
"mae": loss2,
"rmse": loss3,
"r^2": r2,
"cost_time": t2 - t1})
# 添加新行
results_df.loc[count] = series
count += 1
return results_df
clf_names = [
'线性回归', '岭回归', 'Lasso回归', '多项式回归', 'KNN', 'SVR', '决策树', 'Bagging', '随机森林', '极限树', 'AdaBoost',
'GBDT', 'XGBoost', 'LightGBM', 'CatBoost', 'Voting', 'Stacking', 'MLP'
]
clfs = [
LinearRegression(),
Ridge(),
Lasso(),
PolynomialFeatures(degree=2),
KNeighborsRegressor(),
SVR(kernel='linear'),
DecisionTreeRegressor(),
BaggingRegressor(),
RandomForestRegressor(),
ExtraTreesRegressor(),
AdaBoostRegressor(),
GradientBoostingRegressor(),
XGBRegressor(),
LGBMRegressor(),
CatBoostRegressor(silent=True),
VotingRegressor(estimators=[('Linear', LinearRegression()), ('ExtraTree', ExtraTreesRegressor())], weights=[1, 1]),
StackingRegressor(regressors=[XGBRegressor(), KNeighborsRegressor()], meta_regressor=LinearRegression()),
MLPRegressor(hidden_layer_sizes=(100, 10), activation='relu', solver='adam', max_iter=2000)
]
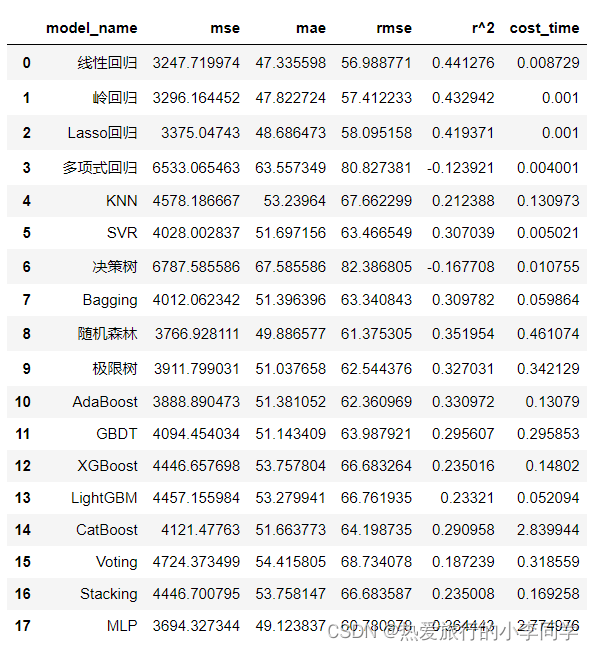
results_df = multi_train(X_train, y_train, X_test, y_test, clf_names, clfs)
results_df
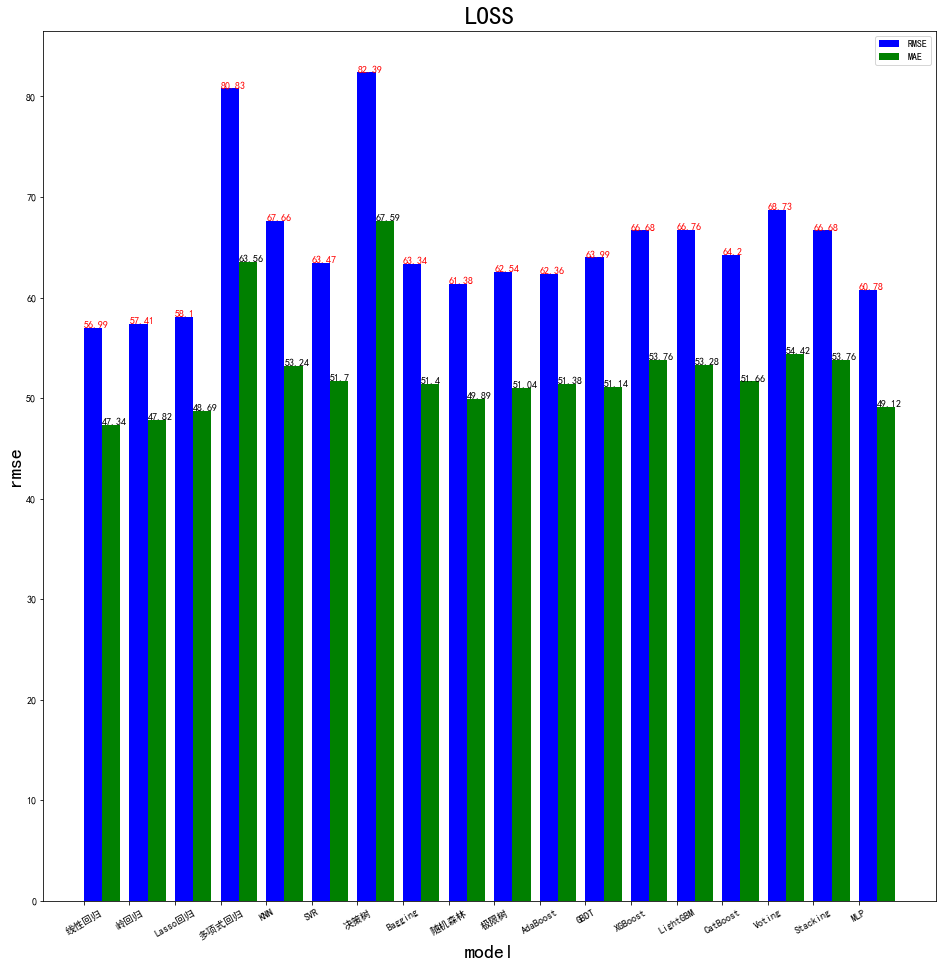
5 模型评估
# 可视化
plt.figure(figsize=(16, 16))
plt.bar(x=[i for i in range(18)], height=results_df['rmse'], width=0.4, color='b', label='RMSE')
plt.bar(x=[i + 0.4 for i in range(18)], height=results_df['mae'], width=0.4, color='g', label='MAE')
for i, name in enumerate(results_df['model_name']):
plt.text(x=i - 0.2, y=results_df.loc[i, 'rmse'], s=round(results_df.loc[i, 'rmse'], 2), color='r')
plt.text(x=i + 0.2, y=results_df.loc[i, 'mae'], s=round(results_df.loc[i, 'mae'], 2), color='k')
plt.xlabel('model', fontdict={
"fontsize": 20})
plt.ylabel('rmse', fontdict={
"fontsize": 20})
plt.xticks(ticks=[i - 0.2 for i in range(18)], labels=results_df['model_name'], rotation=30)
plt.title('LOSS', fontdict={
"fontsize": 25})
plt.legend()
plt.show()