目录
1. 作者介绍
姚同钰,女,西安工程大学电子信息学院,2021级硕士研究生
研究方向:深度学习与图像去噪
电子邮件:[email protected]
孟莉苹,女,西安工程大学电子信息学院,2021级硕士研究生,张宏伟人工智能课题组
研究方向:机器视觉与人工智能
电子邮件:[email protected]
2. KNN网络简介(K- Nearest Neighbor)
最近邻算法或者说KNN(K- Nearest Neighbor)算法,是一种基本的分类与回归方法,是数据挖掘技术中最简单的技术之一。Cover和Hart在1968年提出了最初的邻近算法,它的输入是基于实例的学习(instance-based learning),属于懒惰学习(lazy learning)即KNN是一种非显示学习过程,也就是没有训练阶段,对新样本直接与训练集做分类或者回归预测。
该方法的思路:所谓最邻近,就是首先选取一个阈值为K,对在阈值范围内离测试样本最近的点进行投票,票数多的类别就是这个测试样本的类别,这是分类问题。那么回归问题也同理,对在阈值范围内离测试样本最近的点取均值,那么这个值就是这个样本点的预测值。
2.1 基于最邻近算法的分类
基于最邻近算法的分类是基于实例的学习,它不尝试构建通用的内部模型,而只是存储训练数据的实例。分类的原理是根据数据点的最邻近数据的类型的多数来预测该数据点的类型,类似于投票,如果一个数据点附近的数据点的类型大部分都是“A”,那么模型预测该数据点的类型也是“A”。
scikit-learn实现两个不同的最近邻居分类器:
KNeighborsClassifier基于每个查询点的k个最近邻居来实现预测,其中,k是指定的整数值。
RadiusNeighborsClassifier基于每个训练点的固定半径内的邻居数来实现学习,其中,r是指定的浮点值。
分类器的定义如下,该定义只列出最重要的参数,详细参数请参考sicikit-learn官网:
sklearn.neighbors.RadiusNeighborsClassifier(radius=1.0, weights='uniform', algorithm='auto', metric='minkowski',...)
sklearn.neighbors.KNeighborsClassifier(n_neighbors=5, weights='uniform', algorithm='auto', metric='minkowski',...)
参数注释:
radius:寻找最邻近数据点的半径。
n_neighbors:最邻近的邻居数量。
algorithm:寻找最邻近的数据点的算法,
有效值是[‘auto’,‘ball_tree’,‘kd_tree’,‘brute’]。
metric:计算距离的度量。
weights:权重,默认值 weights =‘uniform’,为每个邻居分配统一的权重。 weights ='distance’分配的权重与距查询点的距离成反比。用于也可以提供定义函数来计算权重。在某些情况下,最好对邻居加权,以使较近的邻居对拟合的贡献更大,这可以通过weights关键字完成。
2.2 基于最邻近算法的回归
基于最邻近算法的回归,本质上是对离散的数据标签进行预测,实际上,最邻近算法也可以用于对连续的数据标签进行预测,这种方法叫做基于最邻近数据的回归,预测的值(即数据的标签)是连续值,通过计算数据点最临近数据点平均值而获得预测值。
scikit-learn实现了两个不同的最邻近回归模型:
KNeighborsRegressor:根据每个查询点的最邻近的k个数据点的均值作为预测值,其中,k是用户指定的整数。
RadiusNeighborsRegressor:基于查询点的固定半径内的数据点的均值作为预测值,其中r是用户指定的浮点值。
回归拟合器的定义如下,该定义只列出最重要的参数,详细参数请参考sicikit-learn官网:
sklearn.neighbors.KNeighborsRegressor(n_neighbors=5, weights='uniform', algorithm='auto', metric='minkowski',...)
sklearn.neighbors.RadiusNeighborsRegressor(radius=1.0, weights='uniform', algorithm='auto', metric='minkowski',...)
最基本的最邻近回归使用统一的权重,也就是说,在特定范围中的每个数据点对查询点的分类(回归)的作用是相同的。在某些情况下,对权重点进行加权可能会比较有利,以使邻近的点比远离的点对回归的贡献更大,这可以通过weights关键字完成。默认值weights =‘uniform’,为所有点分配相等的权重。weights ='distance’分配的权重与距查询点的距离成反比。
3. 实验相关
3.1 实验环境
Pytorch 1.10.1
torchvision 0.11.2
Python 3.7
Win10+Pycharm
这里需要安装matplotlib、numpy、pandas、seaborn、sklearn等库,安装步骤都很简单,只需输入pip3 install xxx(库名)即可。
3.2 数据集介绍
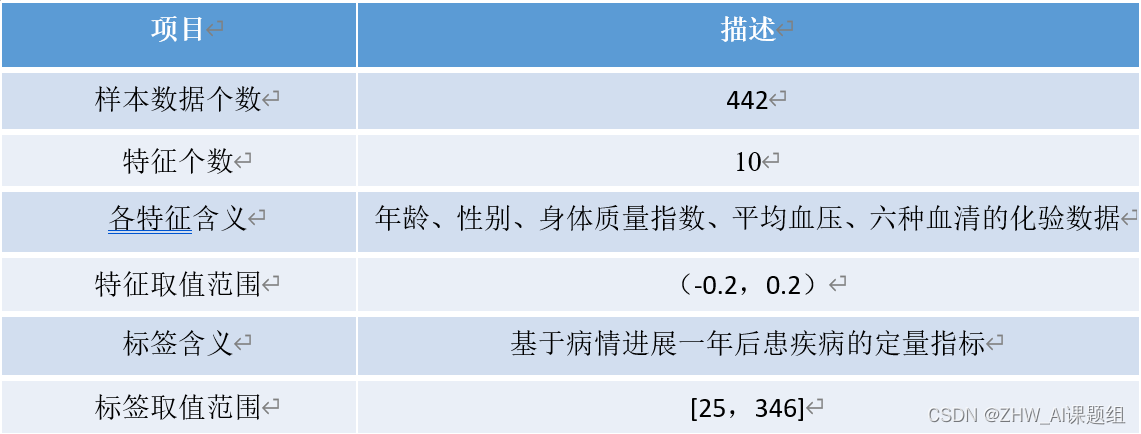
项目描述:
样本数据个数 442;
特征个数 10;
各特征含义 年龄、性别、身体质量指数、平均血压、六种血清的化验数据
特征取值范围 (-0.2,0.2);
标签含义 基于病情进展一年后患疾病的定量指标;
标签取值范围 [25,346];
数据集Diabetes:共442个样本,每个样本有十个特征,分别是 [‘age’, ‘sex’, ‘bmi’, ‘bp’, ‘s1’, ‘s2’, ‘s3’, ‘s4’, ‘s5’, ‘s6’],对应年龄、性别、身体质量指数、平均血压、S1~S6为六种血清的化验数据。10个特征变量数据均已进行规范化,Target为一年后患疾病的定量指标,值在25到346之间。适用于回归任务。
糖尿病数据格式如下:


3.3 数据可视化及其分析
首先导入数据集,对数据进行分析:
import pandas as pd
import numpy as np
from sklearn.datasets import load_diabetes #导入数据集
import matplotlib.pyplot as plt
from matplotlib.pyplot import MultipleLocator
diabetes = load_diabetes()
print(diabetes.feature_names) #查看diabetes数据集特征变量
print(diabetes.data.shape) #分析数据集样本总数,特征变量总数
v_bos = pd.DataFrame(diabetes.data) #查看糖尿病数据集前5条数据,查看这10个变量数据情况
print(v_bos.head(5))
根据程序输出结果,查看数据集数据样本总数,与特征变量个数;以及通过数据集前5条数据,查看10个特征变量数据情况。
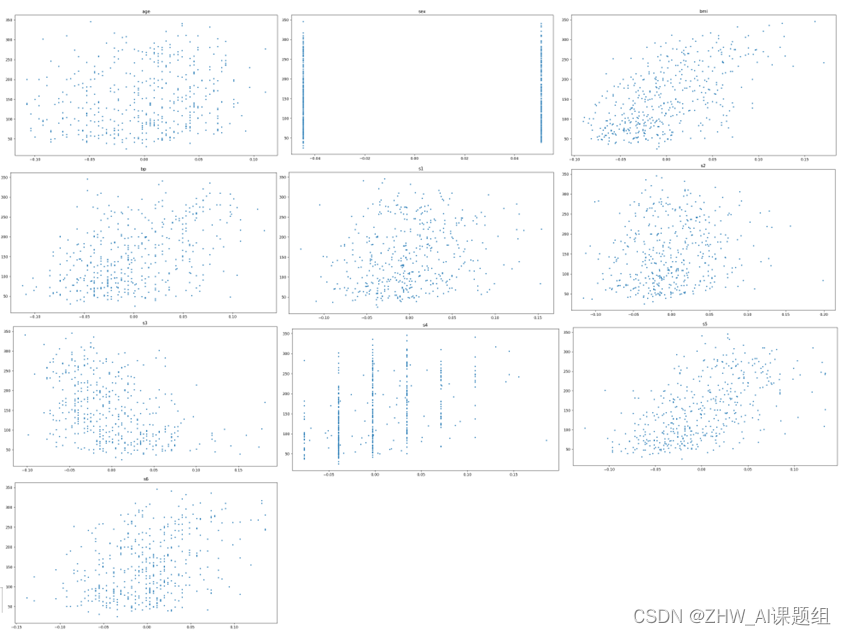
接下来,可视化特征信息值(共11幅散点图):
1. 可视化各个特征信息散点图:
x = diabetes['data'] #导入特征变量
y = diabetes['target'] #导入目标变量"一年后患疾病的定量指标"
name = diabetes['feature_names']
for i in range(10):
plt.figure(figsize=(13, 7))
#plt.grid()
plt.scatter(x[:, i], y, s=5) # 横纵坐标和点的大小
plt.title(name[i])
print(name[i], np.corrcoef(x[:i]), y)
plt.show()
输出结果:
2. 可视化“一年后患疾病的定量指标”特征信息图:
plt.figure(figsize=(20, 15))
y_major_locator = MultipleLocator(10) #把y轴的刻度间隔设置为10,并存在变量里
ax = plt.gca() #ax为两条坐标轴的实例
ax.yaxis.set_major_locator(y_major_locator) #把y轴的主刻度设置为5的倍数
#plt.grid()
for i in range(len(y)):
plt.scatter(i, y[i], s=10)
plt.title('target')
plt.show()
输出结果:

之后,对自变量进行特征分析,分析特征变量与目标变量之间的相关性。
import pandas as pd
import matplotlib.pyplot as plt #可视化
import seaborn as sns #可视化
df = pd.read_csv('diabetes.csv') #读取数据
_, ax = plt.subplots(figsize=(12, 10)) #分辨率1200×1000
corr = df.corr(method='pearson') #使用皮尔逊系数计算列与列的相关性
cmap = sns.diverging_palette(220, 10, as_cmap=True) #在两种HUSL颜色之间制作不同的调色板。图的正负色彩范围为220、10,结果为真则返回matplotlib的colormap对象
_ = sns.heatmap(
corr, #使用Pandas DataFrame数据,索引/列信息用于标记列和行
cmap=cmap, #数据值到颜色空间的映射
square=True, #每个单元格都是正方形
cbar_kws={
'shrink': .9}, #`fig.colorbar`的关键字参数
ax=ax, #绘制图的轴
annot=True, #在单元格中标注数据值
annot_kws={
'fontsize': 12}) #热图,将矩形数据绘制为颜色编码矩阵
plt.show()
sns.heatmap()用于绘制热力图,热力图表示的是两个数据之间的相关性,数值范围是-1到1之间,大于0表示两个数据之间是正相关的,小于0表示两个数据之间是负相关的,等于0就是不相关。
输出结果:
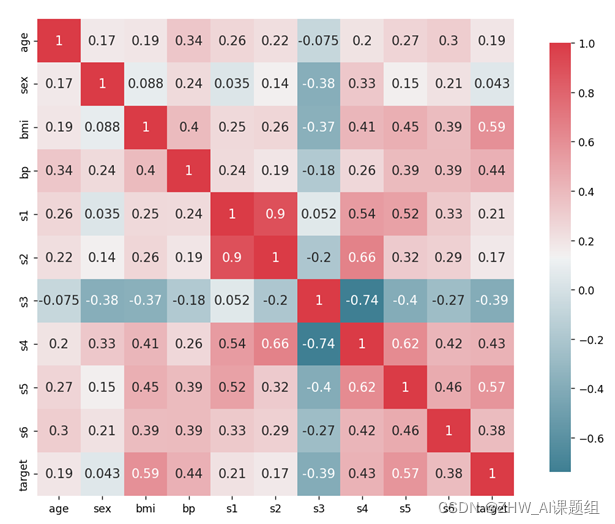
从上述热力图可以看出一些明显的特征,如一年后患疾病的定量指标target和身体质量指数bmi正相关系数比较大,说明身体质量指数测试值如果高于正常值(18.5-23.9)的话,一年后患疾病的可能性就越大。同理,平均血压bp与一年后患疾病的定量指标target之间的相关性也比较强。
根据热力图,可以看到有些特征信息与一年后患疾病的的定量指标target相关性比较大,有些特征信息与房价的相关性很小,因此可以将不相关特征信息进行剔除,只选取与一年后患疾病的的定量指标target相关性较大的特征信息进行回归预测。
3.4 导入KNN回归模型进行回归预测
首先,加载相关模块库;
import numpy as np
import matplotlib.pyplot as plt #可视化
from sklearn.datasets import load_diabetes #导入数据集
from sklearn.neighbors import KNeighborsRegressor #导入KNN模型
from sklearn.model_selection import train_test_split #导入数据集划分模块
from sklearn.metrics import r2_score #使用r2_score对模型评估
接下来,导入糖尿病数据集;
diabetes = load_diabetes() #导入糖尿病数据集
x = diabetes.data #影响一年后患疾病定量指标的特征信息数据
y = diabetes.target #一年后患疾病的定量指标数据
name = diabetes['feature_names'] #特征信息名称
之后,对数据集进行数据处理(如果使用所有特征进行回归,则不需要),这里选取bmi, bp, s4, s5四个相关性强的特征进行回归预测;
#数据处理
unsF = [] #次要特征下标
for i in range(len(name)):
if name[i] == 'age'or name[i] == 'sex' or name[i] == 's4' or name[i] == 's2' or name[i] == 's3'or name[i] == 's6':
continue
unsF.append(i)
x = np.delete(x, unsF, axis=1) #删除次要特征
然后,对糖尿病数据集进行数据分割,这里设置test_size=0.3;
#将数据进行拆分,一份用于训练,一份用于测试和验证
#测试集大小为30%,防止过拟合
#这里的random_state就是为了保证程序每次运行都分割一样的训练集和测试集。
X_train,x_test,y_train,y_test = train_test_split(x,y,test_size=0.3,random_state=0)
接下来,训练训练KNN回归模型,这里设置超参数n_neighbors=13;
#knn回归模型
knn = KNeighborsRegressor(n_neighbors=13)
knn.fit(X_train,y_train) #训练数据,学习模型参数
y_predict = knn.predict(x_test) #进行预测
对于超参数n_neigbors(邻居数)的选取,可以通过K折交叉验证法来获取最合适的n_neigbors值;如下列程序所示:
#使用网格来搜索候选值
from sklearn.model_selection import GridSearchCV #通过网络方式来获取参数
from sklearn.datasets import load_diabetes
from sklearn.neighbors import KNeighborsRegressor
from sklearn.model_selection import train_test_split #导入数据集划分模块
diabetes = load_diabetes() #导入糖尿病数据集
X = diabetes['data']
y = diabetes['target']
X_train,x_test,y_train,y_test = train_test_split(X,y,test_size=0.3,random_state=0)
#设置需要搜索的K值,'n_neightbors'是sklearn中KNN的参数
parameter = {
'n_neighbors':[1,3,5,7,9,11,13,15,17,19,21,23,25,27,29,31]}
knn = KNeighborsRegressor() #注意:这里不用指定参数
#通过GridSearchCV来搜索最好的K值。这个模块的内部其实就是对每一个K值进行评估
clf = GridSearchCV(knn,parameter,cv=5) #5折
clf.fit(X_train,y_train)
print(f'评估最合适的K值为:{(clf.best_params_)["n_neighbors"]}',"其准确率为:%.2f"%clf.best_score_)

最后,与验证值比较并可视化显示真实值与预测值。
#与验证值作比较
score = r2_score(y_test, y_predict).round(5) #确定系数
print("Test set R^2:{}".format(score))
#可视化显示
plt.plot(y_test,label='true')
plt.plot(y_predict,label='knn_predict')
plt.legend()
plt.show()
3.5 实验结果分析与总结

r2_score()函数可以表示特征模型对特征样本预测的好坏,即确定系数,也称为拟合优度。拟合优度越大,自变量对因变量的解释程度越高,自变量引起的变动占总变动的百分比越高。
如上图所示,利用所有特征回归预测的R^2值为0.35263,说明利用所有特征可以解释一年后患疾病的的定量指标的35.263%;选取部分特征(bmi, bp, s4, s5)回归预测的R^2值为0.14957,说明bmi, bp, s4, s5四个特征可以解释一年后患疾病的的定量指标的14.957%。相较而言,利用所有特征对一年后患疾病的的定量指标进行回归预测的拟合度较高。
最近邻算法使用的模型实际上对应于特征空间的划分,KNN算法优缺点:
优点:简单好用,容易理解,精度高,理论成熟,既可以用来做分类也可以用来做回归;可用于数值型数据和离散型数据;训练时间复杂度为O(n);无数据输入假定;对异常值不敏感。
缺点:计算复杂性高;空间复杂性高;样本不平衡问题(即有些类别的样本数量很多,而其它样本的数量很少);一般数值很大的时候不用这个,计算量太大。但是单个样本又不能太少,否则容易发生误分。最大的缺点是无法给出数据的内在含义。
附完整代码(5部分)
第一部分:选取最优超参数K值
# 使用网格来搜索候选值
from sklearn.model_selection import GridSearchCV #通过网络方式来获取参数
from sklearn.datasets import load_diabetes
from sklearn.neighbors import KNeighborsRegressor
from sklearn.model_selection import train_test_split # 导入数据集划分模块
diabetes = load_diabetes() #导入糖尿病数据集
X = diabetes['data']
y = diabetes['target']
X_train,x_test,y_train,y_test = train_test_split(X,y,test_size=0.3,random_state=0)
# 设置需要搜索的K值,'n_neightbors'是sklearn中KNN的参数
parameter = {
'n_neighbors':[1,3,5,7,9,11,13,15,17,19,21,23,25,27,29,31]}
knn = KNeighborsRegressor() #注意:这里不用指定参数
# 通过GridSearchCV来搜索最好的K值。这个模块的内部其实就是对每一个K值进行评估
clf = GridSearchCV(knn,parameter,cv=5) #5折
clf.fit(X_train,y_train)
print(f'评估最合适的K值为:{(clf.best_params_)["n_neighbors"]}',"其准确率为:%.2f"%clf.best_score_)
第二部分:用所有特征进行预测
mport matplotlib.pyplot as plt # 可视化
from sklearn.datasets import load_diabetes # 导入数据集
from sklearn.neighbors import KNeighborsRegressor # 导入KNN回归模型
from sklearn.model_selection import train_test_split # 导入数据集划分模块
from sklearn.metrics import r2_score # 使用r2_score对模型评估
diabetes = load_diabetes() #导入糖尿病数据集
x = diabetes.data # 影响一年后患疾病定量指标的特征信息数据
y = diabetes.target #一年后患疾病的定量指标数据
# 将数据进行拆分,一份用于训练,一份用于测试和验证
# 测试集大小为30%,防止过拟合
# 这里的random_state就是为了保证程序每次运行都分割一样的训练集和测试集。
X_train,x_test,y_train,y_test = train_test_split(x,y,test_size=0.3,random_state=0)
# knn回归模型
knn = KNeighborsRegressor(n_neighbors=13)
knn.fit(X_train,y_train) # 训练数据,学习模型参数
y_predict = knn.predict(x_test) # 进行预测
# 与验证值作比较
score = r2_score(y_test, y_predict).round(5) # 相关系数
print("Test set R^2:{}".format(score))
#可视化显示
plt.plot(y_test,label='true')
plt.plot(y_predict,label='knn_predict')
plt.legend()
plt.show()
第三部分:选取部分特征进行回归预测
import numpy as np
import matplotlib.pyplot as plt # 可视化
from sklearn.datasets import load_diabetes # 导入数据集
from sklearn.neighbors import KNeighborsRegressor # 导入KNN模型
from sklearn.model_selection import train_test_split # 导入数据集划分模块
from sklearn.metrics import r2_score # 使用r2_score对模型评估
diabetes = load_diabetes() #导入糖尿病数据集
x = diabetes.data # 影响一年后患疾病定量指标的特征信息数据
y = diabetes.target #一年后患疾病的定量指标数据
name = diabetes['feature_names'] # 特征信息名称
# 数据处理
unsF = [] # 次要特征下标
for i in range(len(name)):
if name[i] == 'age'or name[i] == 'sex' or name[i] == 's4' or name[i] == 's2' or name[i] == 's3'or name[i] == 's6':
continue
unsF.append(i)
x = np.delete(x, unsF, axis=1) # 删除次要特征
# 将数据进行拆分,一份用于训练,一份用于测试和验证
# 测试集大小为30%,防止过拟合
# 这里的random_state就是为了保证程序每次运行都分割一样的训练集和测试集。
X_train,x_test,y_train,y_test = train_test_split(x,y,test_size=0.3,random_state=0)
# knn回归模型
knn = KNeighborsRegressor(n_neighbors=13)
knn.fit(X_train,y_train) # 训练数据,学习模型参数
y_predict = knn.predict(x_test) # 进行预测
# 与验证值作比较
score = r2_score(y_test, y_predict).round(5) # 确定系数
print("Test set R^2:{}".format(score))
#可视化显示
plt.plot(y_test,label='true')
plt.plot(y_predict,label='knn_predict')
plt.legend()
plt.show()
第四部分:对每一个特征进行分析
import pandas as pd
import numpy as np
from sklearn.datasets import load_diabetes # 导入数据集
import matplotlib.pyplot as plt
from matplotlib.pyplot import MultipleLocator
"""
第一步:首先认识糖尿病数据集,分析查看数据集样本总数,特征变量总数。
第二步:然后画出糖尿病数据集所有特征变量的散点图,并分析特征变量与"一年后患疾病的定量指标"的影响关系。
"""
diabetes = load_diabetes()
print(diabetes.feature_names) # 查看diabetes数据集特征变量
print(diabetes.data.shape) # 分析数据集样本总数,特征变量总数
v_bos = pd.DataFrame(diabetes.data) # 查看糖尿病数据集前5条数据,查看这10个变量数据情况
print(v_bos.head(5))
x = diabetes['data'] # 导入特征变量
y = diabetes['target'] # 导入目标变量"一年后患疾病的定量指标"
student = input('一年后患疾病的定量指标特征信息图--0;各个特征信息图--1: ') # 输入0代表查看影响一年后患疾病的定量指标特征信息图,输入1代表查看各个特征信息图
if str.isdigit(student):
b = int(student)
if (b <= 1):
print('开始画图咯...', end='\t')
if (b == 0):
plt.figure(figsize=(20, 15))
y_major_locator = MultipleLocator(10) # 把y轴的刻度间隔设置为10,并存在变量里
ax = plt.gca() # ax为两条坐标轴的实例
ax.yaxis.set_major_locator(y_major_locator) # 把y轴的主刻度设置为5的倍数
#plt.grid()
for i in range(len(y)):
plt.scatter(i, y[i], s=10)
plt.title('target')
plt.show()
else:
name = diabetes['feature_names']
for i in range(10):
plt.figure(figsize=(13, 7))
#plt.grid()
plt.scatter(x[:, i], y, s=5) # 横纵坐标和点的大小
plt.title(name[i])
print(name[i], np.corrcoef(x[:i]), y)
plt.show()
else:
print('同学请选择0或者1')
else:
print('同学请选择0或者1')
第五部分:两两特征的相关性分析,主要是看预测的目标和每个特征的相关性
import pandas as pd
import matplotlib.pyplot as plt # 可视化
import seaborn as sns # 可视化
df = pd.read_csv('diabetes.csv') # 读取数据
_, ax = plt.subplots(figsize=(12, 10)) # 分辨率1200×1000
corr = df.corr(method='pearson') # 使用皮尔逊系数计算列与列的相关性
cmap = sns.diverging_palette(220, 10, as_cmap=True) # 在两种HUSL颜色之间制作不同的调色板。图的正负色彩范围为220、10,结果为真则返回matplotlib的colormap对象
_ = sns.heatmap(
corr, # 使用Pandas DataFrame数据,索引/列信息用于标记列和行
cmap=cmap, # 数据值到颜色空间的映射
square=True, # 每个单元格都是正方形
cbar_kws={
'shrink': .9}, # `fig.colorbar`的关键字参数
ax=ax, # 绘制图的轴
annot=True, # 在单元格中标注数据值
annot_kws={
'fontsize': 12}) # 热图,将矩形数据绘制为颜色编码矩阵
plt.show()
注:以上程序均已分享至百度网盘,需要的可以自取。
链接:https://pan.baidu.com/s/1AuaXoPiL0VdJshr9BaB9ow 提取码:r2fv
3.参考链接
原文链接:https://blog.csdn.net/ch1209498273/article/details/78440276
原文链接:https://blog.csdn.net/upluck/article/details/116969406